AI/ML for Network Security: The Emperor has no Clothes
CCS '22: Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security
https://dl.acm.org/doi/abs/10.1145/3548606.3560609
摘要
最近的一些研究工作提出了基于机器学习(ML)的解决方案,它可以针对广泛的网络安全问题检测网络流量中的复杂模式。然而,由于不了解这些黑箱模型是如何做出决定的,网络运营商就不愿意信任它们并在其生产设置中部署它们。这种不情愿的一个关键原因是,这些模型容易出现不规范的问题,这里定义为未能足够详细地指定模型。不是唯一的网络安全领域,这个问题表现在毫升模型表现出意外的不良行为时部署在现实世界设置,促使越来越多的兴趣开发可解释的毫升解决方案(例如,决策树)为人类人类解释如何给定的黑箱模型的决策。然而,综合这些可解释的模型,高保真地捕捉给定的黑箱模型的决策,同时也很实用(即体积足够小,让人类理解)是具有挑战性的。
在本文中,我们着重于综合高保真度和低复杂度的决策树,以帮助网络操作员确定他们的ML模型是否存在不规范的问题。为此,我们提出了一个Trustee框架,该框架以现有的ML模型和训练数据集作为输入,并生成一个高保真、易于解释的决策树和相关的信任报告作为输出。使用已发布的完全可重复的ML模型,我们展示了从业者如何使用受托人来识别模型不规范的三个常见实例;例如,快捷学习的证据,虚假相关性的存在,以及对分布外样本的脆弱性。
引言
在过去的几年中,我们目睹了网络安全社区的日益紧张的局势。最近的研究已经证明了人工智能(AI)和机器学习(ML)模型比更简单的基于规则的启发式模型在识别各种网络安全问题的复杂网络流量模式方面的好处(参见最近的调查文章,如[9,46,55,62])。与此同时,我们也看到网络安全研究人员和从业人员不愿意在生产设置中采用这些基于ML的研究工件(例如,参见[2,4,58])。这些提出的解决方案的黑盒性质是这种谨慎态度和整体犹豫的主要原因。更具体地说,与现有的更简单但通常不那么有效的基于规则的方法相比,由于无法解释这些模型是如何以及为什么要做出它们的决策的,这使得它们很难被推销出去。
这种紧张关系并不是网络安全问题所特有的,而是更普遍地适用于任何学习模式,特别是当它们的决策可能产生严重的社会影响时(例如,医疗保健、信用评级、就业申请和刑事司法系统)。与此同时,这种基本的紧张关系也推动了最近的努力来开放黑盒学习模型,解释它们为什么以及如何做出决定(例如,łinterpretable MLz [51],łexplainable AI(XAI)z [59],和łtrustworthy AIz [12])。然而,确保这些努力是实际应用领域的人工智能/毫升等网络安全是挑战,需要进一步的资格概念如(模型)可解释性或信任(模型)[40]也需要解决一些基础研究问题在这些新领域的人工智能/毫升
这里,不规范的问题在现代AI/ML是指确定训练模型的成功(例如,高精度)确实是由于其固有的能力编码一些基本结构的底层系统或数据或只是一些归纳偏见的结果,训练模型编码。在实践中,归纳偏差通常表现在捷径学习策略[28]、虚假相关性[3]的迹象或固有的分布失调(o.o.d.)。泛化(即,测试数据分布不同于训练数据分布)。这种归纳偏差的含义是,它们在训练过的AI/ML模型中的存在阻止了这些模型的可信度;也就是说,在部署场景中按照预期进行概括。因此,为了在本文所考虑的ML模型中建立特定类型的信任,能够识别这些归纳偏差是至关重要的,本文为实现这个雄心勃勃的目标迈出了第一步。
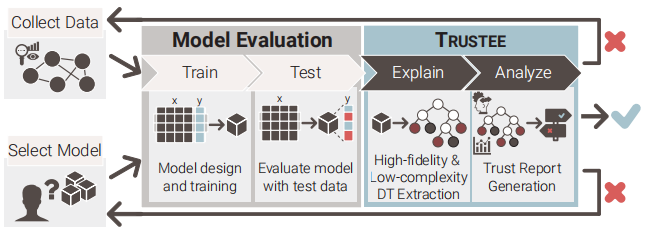
为了检测网络安全问题的学习模型中的不规范问题,我们开发了受托人(面向trust的决策TreE提取)。这个框架提供了一种方法,以仔细检查黑箱学习模型的存在归纳偏差。图1显示了受托人如何增强传统的ML管道,以检查一个给定的ML模型的可信度。专门考虑到网络安全应用领域开发的,受托人将给定的黑盒模型和用于将该模型训练的数据集作为输入,并以高质量决策树(DT)解释的形式输出łwhite-boxz模型
重要的是,在综合这种DT时,受托人的重点首先是确保它的实际使用,反过来,需要利用特定领域的观察来在模型保真度(即DT相对于黑盒模型的准确性)、模型复杂性和模型稳定性之间取得平衡。在这里,复杂性指的是DT的大小和树的分支的各个方面。特别是,当把树的分支看作是决策规则时,我们关心的是它们的明确性和可理解性;也就是说,我们要求这些规则易于被领域专家识别,并在很大程度上与专家的领域知识相一致。另一方面,模型的稳定性涉及决策规则的正确性、覆盖范围和稳定性;也就是说,我们要求他们正确地描述给定的黑箱模型如何做出大量的决策,并且希望它们影响对受托人在选择最终DT解释过程中使用的特定数据样本不敏感。
我们通过实现一种启发式方法来实现这种不敏感性或稳定性,该方法从许多不同的候选DTs中选择具有最高平均一致性的一个。在这里,两个不同的DTs之间的一致性是衡量两个DTs对相同的输入数据[30,60]做出相同决定的频率的一个指标。在实践中,实现这种启发式减少了受托人输出误导性的DT解释的可能性。受托人还输出一份与DT解释相关的信托报告,操作员可以咨询该报告,以确定是否有证据表明给定的黑箱模型存在规格不足的问题。如果发现了这样的证据,信任报告中提供的信息可以用于识别传统ML管道的组件(例如,训练数据和模型选择),这些组件需要进行修改,以努力改进受托人发现不值得信任的ML模型。
虽然我们的工作有助于关于模型可解释性的ML文献,并受到该领域正在进行的发展的启发,但我们的努力和目标在许多重要方面不同于现有的方法。首先,考虑到网络学习问题的固有复杂性,现有的方法用łwhite-boxz模型取代黑盒模型,首先可以解释(例如,决策树)通常是不切实际的。此外,局部可解释性方法[31,48,53]不适用于检查欠规范问题的各种实例。与此同时,尽管我们的努力是由先前关注全局可解释性[6,7,37]的研究推动的,但这些工作要么只适用于特定类别的学习模型(例如,强化学习),要么保真度较差。
通过各种案例研究,我们在第7节中说明了运营商如何使用受托人的dt和相关的信托报告来检测归纳偏差的存在。更具体地说,我们使用可重复的ML模型(即代码库和数据集公开)显示网络运营商如何使用受托人提供的信息来检测快捷学习策略的实例,获得过拟合的证据和/或模型是否依赖虚假相关性做出决定,或确定模型无法推广到分布外的数据。