SSD 数据增强
- 前言
- 1、Compose
- 2、SSDCropping
- 3、Resize
- 4、ColorJitter
- 5、ToTensor
- 6、RandomHorizontalFlip
- 7、Normalization
- 8、AssignGTtoDefaultBox
前言
原论文

根据原论文,我们需要处理的有以下:
data_transform = {
"train": transforms.Compose([transforms.SSDCropping(),
transforms.Resize(),
transforms.ColorJitter(),
transforms.ToTensor(),
transforms.RandomHorizontalFlip(),
transforms.Normalization(),
transforms.AssignGTtoDefaultBox()]),
"val": transforms.Compose([transforms.Resize(),
transforms.ToTensor(),
transforms.Normalization()])
}
因为 torchvision.transforms 默认只处理图像,而我们在做图像翻转的时候,需要连 ground truth box 的坐标一并翻转。 所以我们需要重写 torchvision.transforms 那一套的操作。
(mac系统下,只要按住 command 键,再点击 torchvision.transforms ,就可以查看源码,在源码上修修改改就可以)
1、Compose
输入输出 带上 target
class Compose(object):
"""组合多个transform函数"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target=None):
for trans in self.transforms:
image, target = trans(image, target)
return image, target
2、SSDCropping
目的:从图像中裁剪出一部分,删除不在其中的 gt box 和 label,对于在其中的 gt box做相应的坐标调整。
To make the model more robust to various input object sizes and shapes, each training image is randomly sampled by one of the following options:
- Use the entire original input image.
- Sample a patch so that the minimum jaccard overlap with the objects is 0.1, 0.3, 0.5, 0.7, or 0.9
- Randomly sample a patch.
\The size of each sampled patch is [0.1, 1] of the original image size, and the aspect ratio is between 0.5 and 2.
We keep the overlapped part of the ground truth box if the center of it is in the sampled patch.
相关说明:
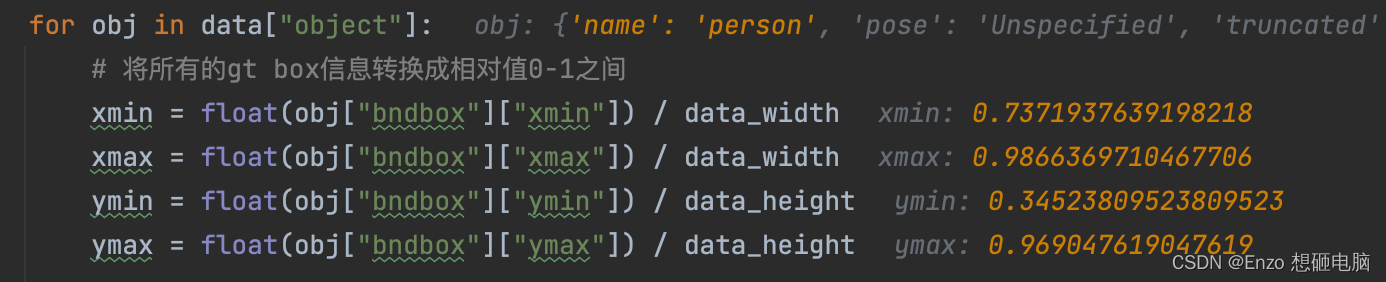
gt box 的坐标,在这之前 已经被处理为了 0 ~ 1 的相对位置
pseudo code
'''
图像尺寸:(1, 1)。 因为图像尺寸不一样,这里的计算按照比例, 后面的计算也都是按照图片比例进行计算
mode = (None, (0.1, None), (0.3, None), (0.5, None), (0.7, None), (0.9, None), (None, None))
mode,表示iou的阈值,其中:
-- None 表示:不做裁剪
-- (0.1, None), ... ,(0.9, None)表示: (min_iou, max_iou)
-- (None, None) 表示 无上限和下限,也就是iou的范围属于 [0, 1] 都可以
target 是一个字典,其中 包括 gt_box 的坐标, 及对应的 label
'''
while True:
1、随机挑选一个 mode
if mode is None, 不做随机裁剪处理
return image, target
else:
min_iou = mode[0],max_iou = mode[1] (None 表示无上限)
for _ in range(5):
2、创建一个 crop_box: 宽和高的范围都在 (0.3, 1.0)之间,需要保证crop_box的四个角都落在原图中, 且保证宽高比例在0.5-2之间
3、取图像的 gt_box 坐标
# 判断这个crop_box是不是能用的 条件一 : iou 要满足条件
4、计算 gt_box 和 crop_box 的 iou
if 有 iou 不在 (min_iou, max_iou) 范围之间:
continue
# 判断这个crop_box是不是能用的 条件二: 中心坐标要满足条件
5、计算 gt_box 的中心坐标
if 所有 gt_box 的中心都没落在 crop_box 中
continue
# 已经确定 crop_box 可用,做相关的坐标处理
6、筛选出 中心坐标落在 crop_box 中的 gt_box, 及对应的 labels
7、修改 gt_box 坐标, 防止出现越界的情况: 如果超出 crop_box 的边界,就截断到 crop_box 的边界
8、重新计算 crop_box 的坐标, 并在 原图 中截取出来, 记为 croped_image
9、重新计算 gt_box 在 croped_image 中的坐标位置, 记录 new_gt_box
return croped_image, new_gt_box
代码
# This function is from https://github.com/chauhan-utk/ssd.DomainAdaptation.
class SSDCropping(object):
"""
根据原文,对图像进行裁剪,该方法应放在ToTensor前
Cropping for SSD, according to original paper
Choose between following 3 conditions:
1. Preserve the original image
2. Random crop minimum IoU is among 0.1, 0.3, 0.5, 0.7, 0.9
3. Random crop
Reference to https://github.com/chauhan-utk/src.DomainAdaptation
"""
def __init__(self):
self.sample_options = (
# Do nothing
None,
# min IoU, max IoU
(0.1, None),
(0.3, None),
(0.5, None),
(0.7, None),
(0.9, None),
# no IoU requirements
(None, None),
)
self.dboxes = dboxes300_coco()
def __call__(self, image, target):
# Ensure always return cropped image
while True:
mode = random.choice(self.sample_options)
if mode is None: # 不做随机裁剪处理
return image, target
htot, wtot = target['height_width']
min_iou, max_iou = mode
min_iou = float('-inf') if min_iou is None else min_iou
max_iou = float('+inf') if max_iou is None else max_iou
# Implementation use 5 iteration to find possible candidate
for _ in range(5):
# 0.3*0.3 approx. 0.1
w = random.uniform(0.3, 1.0)
h = random.uniform(0.3, 1.0)
if w/h < 0.5 or w/h > 2: # 保证宽高比例在0.5-2之间
continue
# left 0 ~ wtot - w, top 0 ~ htot - h
left = random.uniform(0, 1.0 - w)
top = random.uniform(0, 1.0 - h)
right = left + w
bottom = top + h
# boxes的坐标是在0-1之间的
bboxes = target["boxes"]
ious = calc_iou_tensor(bboxes, torch.tensor([[left, top, right, bottom]]))
# tailor all the bboxes and return
# all(): Returns True if all elements in the tensor are True, False otherwise.
if not ((ious > min_iou) & (ious < max_iou)).all():
continue
# discard any bboxes whose center not in the cropped image
xc = 0.5 * (bboxes[:, 0] + bboxes[:, 2])
yc = 0.5 * (bboxes[:, 1] + bboxes[:, 3])
# 查找所有的gt box的中心点有没有在采样patch中的
masks = (xc > left) & (xc < right) & (yc > top) & (yc < bottom)
# if no such boxes, continue searching again
# 如果所有的gt box的中心点都不在采样的patch中,则重新找
if not masks.any():
continue
# 修改采样patch中的所有gt box的坐标(防止出现越界的情况)
bboxes[bboxes[:, 0] < left, 0] = left
bboxes[bboxes[:, 1] < top, 1] = top
bboxes[bboxes[:, 2] > right, 2] = right
bboxes[bboxes[:, 3] > bottom, 3] = bottom
# 虑除不在采样patch中的gt box
bboxes = bboxes[masks, :]
# 获取在采样patch中的gt box的标签
labels = target['labels']
labels = labels[masks]
# 裁剪patch
left_idx = int(left * wtot)
top_idx = int(top * htot)
right_idx = int(right * wtot)
bottom_idx = int(bottom * htot)
image = image.crop((left_idx, top_idx, right_idx, bottom_idx))
# 调整裁剪后的bboxes坐标信息
bboxes[:, 0] = (bboxes[:, 0] - left) / w
bboxes[:, 1] = (bboxes[:, 1] - top) / h
bboxes[:, 2] = (bboxes[:, 2] - left) / w
bboxes[:, 3] = (bboxes[:, 3] - top) / h
# 更新crop后的gt box坐标信息以及标签信息
target['boxes'] = bboxes
target['labels'] = labels
return image, target
3、Resize
因为 target 中的 gt box 的坐标已经被处理为了 在图像中的比例坐标,所以 Resize 中不用对 target 做处理。
class Resize(object):
"""对图像进行resize处理,该方法应放在ToTensor前"""
def __init__(self, size=(300, 300)):
self.resize = t.Resize(size)
def __call__(self, image, target):
image = self.resize(image)
return image, target
4、ColorJitter
class ColorJitter(object):
"""对图像颜色信息进行随机调整,该方法应放在ToTensor前"""
def __init__(self, brightness=0.125, contrast=0.5, saturation=0.5, hue=0.05):
self.trans = t.ColorJitter(brightness, contrast, saturation, hue)
def __call__(self, image, target):
image = self.trans(image)
return image, target
5、ToTensor
做了如下 3 个事情:
- 将 nump.ndarray 或 PIL.Image 转为 tensor,数据类型为 torch.FloatTensor
- 把灰度范围从0-255 变换到 0-1之间,其将每一个像素值归一化到 [0,1],其归一化方法比较简单,直接除以255即可
- 将shape 由 (H,W, C) 转为shape为 (C, H, W)
class ToTensor(object):
"""将PIL图像转为Tensor"""
def __call__(self, image, target):
image = F.to_tensor(image).contiguous()
return image, target
6、RandomHorizontalFlip
最重要的就是这里,将 gt box 一并做了翻转
class RandomHorizontalFlip(object):
"""随机水平翻转图像以及bboxes,该方法应放在ToTensor后"""
def __init__(self, prob=0.5):
self.prob = prob
def __call__(self, image, target):
if random.random() < self.prob:
# height, width = image.shape[-2:]
image = image.flip(-1) # 水平翻转图片
bbox = target["boxes"]
# bbox: xmin, ymin, xmax, ymax
# bbox[:, [0, 2]] = width - bbox[:, [2, 0]] # 翻转对应bbox坐标信息
bbox[:, [0, 2]] = 1.0 - bbox[:, [2, 0]] # 翻转对应bbox坐标信息
target["boxes"] = bbox
return image, target
7、Normalization
为什么不在自己的数据集上计算均值和方差,而是简单的使用 ImageNet 数据集的均值和方差呢?
(很多地方都是这么直接使用的)我理解的是 ImageNet 是一个超大型数据集,在其上计算得出的均值和方差,应该就是绝大部分图像所服从的分布了,是满足需求的,而且自己计算自己数据集的均值和方差的话,耗时耗资源。
class Normalization(object):
"""对图像标准化处理,该方法应放在ToTensor后"""
def __init__(self, mean=None, std=None):
if mean is None:
mean = [0.485, 0.456, 0.406]
if std is None:
std = [0.229, 0.224, 0.225]
self.normalize = t.Normalize(mean=mean, std=std)
def __call__(self, image, target):
image = self.normalize(image)
return image, target
8、AssignGTtoDefaultBox
这里的作用是生成 default box ,我们令起一片文章细说。
class AssignGTtoDefaultBox(object):
"""将DefaultBox与GT进行匹配"""
def __init__(self):
self.default_box = dboxes300_coco()
self.encoder = Encoder(self.default_box)
def __call__(self, image, target):
boxes = target['boxes']
labels = target["labels"]
# bboxes_out (Tensor 8732 x 4), labels_out (Tensor 8732)
bboxes_out, labels_out = self.encoder.encode(boxes, labels)
target['boxes'] = bboxes_out
target['labels'] = labels_out
return image, target