1 故障描述
2023年1月27日下午接到业务反馈数据库存在大量的锁表阻塞信息,并且业务的页面以及数据库的一些查询均处于阻塞状态,简单的查询sql也需要查询很长时间且未返回结果,数据库hang状态。
问题现象2
1 数据库进程无法杀除。
2 操作系统进程使用kill -9命令也无法进行删除,数据库无法进行重启,即使使用shutdown abort命令 也无法进行关闭数据库 。
3 ipcs -ma查看数据库共享内存段,发现状态为D但是无法杀除。
2 故障原因分析
2.1 数据库层面分析
接到业务反馈后,第一时间登录数据库使用如下语句查询数据库正在进行的事物以及会话select count(1) ,event from v$session group by event,发现大部分会话处于TX-INDEX CONTENTION,db file sequential read,read by Other session 等待状态,数据库处于hang状态无法进行事务处理,查询数据库alert日志未发现明显错误信息。
以下为对数据库等待的分析认知:
- TX-INDEX CONTENTION
enq: TX - index contention 常出现在高并发场景下,由于索引分裂产生的竞争等待。最常见的索引竞争一般发生在主键索引上,主键值从序列(sequence)中获取,每个事务都会生成一条新的记录,每条记录都要获得一个新的序列号,基于b tree 索引的右倾原则,操作基本都在最右边的叶节点上,都希望能够维护同一个内存内存,最典型的竞争形式。
索引 split 会导致 enq:TX-index contention 事件,经常性伴有 enq: TX - allocate ITL 等待,通过buffer busy waits 可确定是做 split 导致,因为在做 index split 时,会写 index 数据到 new buffer 里。
(数据库确实存在以sequence为主键的列作为主键的持续插入,但是将其调整为alter index index_name rebuild online reverse;也无法进行解决 )
常规的解决方案:
1)Hash(散列)分区索引,优先考虑这种方式。
2)将索引重新创建为反向索引,缺点是无法 RANGE SCAN。
3) 如果索引关键字是从序列(sequence)生成的,则增加序列的高速缓存大小,默认是20,一般都要设置为 1W。
4) 定期 rebuild 索引来减轻这样现象,表特别大时做 rebuild 要慎重,对空间要求比较多。
参考:Troubleshooting ‘enq: TX - index contention’ Waits (Doc ID 873243.1)
从上述分析中可以知道对于sequence的主键索引容易右边倾斜,导致索引叶节点繁忙出现大量的enq: TX - index contention。
- db file sequential read
db file sequential read 事件有三个参数:file#,first block#, block count, 在oracle 10g里,此等待事件在归于 User I/O wait class 下面的. 处理db file sequential read 事件要牢牢把握下面三个主要思想:
1)oracle 进程需要访问的block不能从SGA 中获取,因此oracle 进程会等待block从I/O读到SGA
2)两个重要参数TIME_WAITED,AVERAGE_WAIT,是以单个session获取的
3)影响较大的db file sequential read 一般很像应用程序问题
Common Causes, Diagnosis, and Actions
db file sequential read 等待事件被SQL 语句初始化,主要从index,rollback(or undo) segments, tables(通过rowid访问表),control files 和data file headers中进行single-block read.
访问数据对象(table,index)总是会产生Physical I/o需求,当出现db file sequential read等待事件时,并不意味着数据库产生系统问题,基至它大量出现都不是一件坏事.真正要引起注意的是像enqueue 和latch free等待事件,它们总是引起系统性题的根源.并且它们使single-block(单块读取)变得因难了.
初步分析数据库hang死原因为数据库出现TX-INDEX CONTENTION等待,主键索引分裂导致数据库出现大量的hang。
数据库大量出现 TX-INDEX CONTENTION等待从上述分析得知主键分裂索引导致,于是想将主键索引进行重建,将主键索引重建为反向键索引。
Alter index user.pk_gis_position rebuild reverse online;
由于需要在线重建而且存在大量的inert语句导致锁死,于是希望将所有的insert语句进行kill,但是在进行kill数据库session的过程中发现进程无法被删除并且使用操作系统命令kill -9也无法进行数据库进程清除。
数据库完全hang死且通过sqlplus /as sysdba的方式也无法进入数据库进行管理,于是和管理员商定将数据库进行重启。
sqlplus -prelim / as sysdba
shutdown abort
但是等待好久数据库值的local=no以及数据库的dbw0和dbw1进程均无法正常退出,使用kill -9命令也无法进行清除,使用ipcs –ma查询共享信息并且使用ipcrm 删除则提示共享内存已经不存在。重启数据库失败数据库根本无法进行停止 。
联系管理员只能在将主机进行重启,杀掉hang死的数据库进程,将主机重启后,使用HA命令手动进行挂在并启动数据库 ,发现 没过一会数据库继续hang死并进入了死循环,于是在启动数据库时未开启监听,将主键索引进行反向化,程序启动时TX等待消失,但是数据库还是存在大量的db file sequential read read by other session等待。
于是通过如下命令查询数据库等待的p1和p2参数,发现P1和P2参数一致未变化。表现在39号文件和33号文件对应的数据库目录为/oracle/oradata2/,此时数据库文件的单块读取一直hang死。
2.2 主机层面分析
在数据库层面已经无法进行处理问题,查询主机的相关信息errpt信息如下:
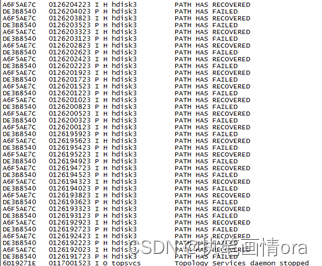
发现在hdisk3的盘出现了大量的 PH和IH错误,且通过分析HDISK3大部分都存在于oradata2.
且通过IOSTAT查询发现数据库的IO停滞 。
,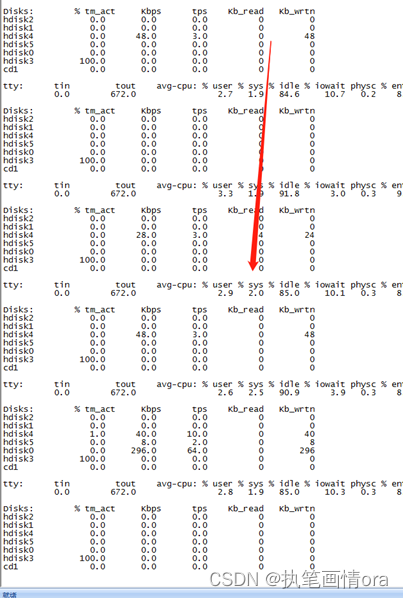
1 hdisk2磁盘使用率接近100%,但是不存在kb_read.
2 数据库大部分的io等待时间集中在39号文件和33号文件,而文件都集中存储在oradata2,正是hdisk3的主要分区。
3 数据库大部分等待均在IO,但是iostat确看不到IO流动 ,而且涉及到数据文件的进程全部hang死无法进行删除等操作。
数据库的读写io一直为0。很诧异。初步判断HDISK3对应的盘出现问题导致数据库数据文件39和33号文件单块读hang死。
验证判断:
在数据库关闭的条件下将39号数据文件cp到其他目录发现也是hang死。
3 故障处理过程
从上述分析原因可知存储单块读hang死,于是和管理员分析决定,建立新的存储避开hdisk3,并使用rman方式进行数据库应急恢复。
| 使用RMAN进行数据库恢复。并将数据文件更换到新的存储避开hdisk3 bplist -C appp2 -t 4 -l -R /|more bplist -C appp2 -t 4 -l -R /|more -rw-rw---- oracle oinstall 8388608 Jan 27 09:03 /cntrl_54244_1_1127206988 -rw-rw---- oracle oinstall 7002880K Jan 27 09:00 /al_54242_1_1127206828 -rw-rw---- oracle oinstall 6853632K Jan 27 09:00 /al_54243_1_1127206828 -rw-rw---- oracle oinstall 8388608 Jan 27 03:03 /cntrl_54241_1_1127185398 -rw-rw---- oracle oinstall 5498880K Jan 27 03:00 /al_54239_1_1127185227 -rw-rw---- oracle oinstall 4637440K Jan 27 03:00 /al_54240_1_1127185227 -rw-rw---- oracle oinstall 8388608 Jan 26 22:00 /cntrl_54238_1_1127167227--------------------1111 -rw-rw---- oracle oinstall 1018429440 Jan 26 21:59 /al_54236_1_1127167169 -rw-rw---- oracle oinstall 1009778688 Jan 26 21:59 /al_54237_1_1127167169 -rw-rw---- oracle oinstall 8388608 Jan 26 17:03 /cntrl_54235_1_1127149386 -rw-rw---- oracle oinstall 1018429440 Jan 26 17:02 /al_54233_1_1127149344 -rw-rw---- oracle oinstall 101187584 Jan 26 17:02 /al_54234_1_1127149344 RUN { ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE'; ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE'; SEND 'NB_ORA_SERV=NBU01,NB_ORA_CLIENT=appp2'; RESTORE CONTROLFILE FROM 'cntrl_54109_1_1126602188'; RELEASE CHANNEL ch00; RELEASE CHANNEL ch01; } RMAN> RUN { 2> ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE'; 3> ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE'; 4> SEND 'NB_ORA_SERV=NBU01,NB_ORA_CLIENT=appp2'; 5> RESTORE CONTROLFILE FROM 'cntrl_54109_1_1126602188'; 6> RELEASE CHANNEL ch00; 7> RELEASE CHANNEL ch01; 8> } using target database control file instead of recovery catalog allocated channel: ch00 channel ch00: sid=525 devtype=SBT_TAPE channel ch00: Veritas NetBackup for Oracle - Release 7.5 (2012020807) allocated channel: ch01 channel ch01: sid=524 devtype=SBT_TAPE channel ch01: Veritas NetBackup for Oracle - Release 7.5 (2012020807) sent command to channel: ch00 sent command to channel: ch01 Starting restore at 28-JAN-23 channel ch01: skipped, autobackup already found channel ch00: restoring control file channel ch00: restore complete, elapsed time: 00:00:44 output filename=/oracle/oradatadb/control01.ctl output filename=/oracle/oradatadb/control02.ctl output filename=/oracle/oradatadb/control03.ctl Finished restore at 28-JAN-23 released channel: ch00 released channel: ch01 RMAN> mount database; RUN { ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE'; ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE'; SEND 'NB_ORA_SERV=NBU01,NB_ORA_CLIENT=appp2'; RESTORE DATABASE; RELEASE CHANNEL ch00; RELEASE CHANNEL ch01; } RUN { ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE'; ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE'; SEND 'NB_ORA_SERV=NBU01,NB_ORA_CLIENT=appp2'; RESTORE CONTROLFILE FROM 'cntrl_54238_1_1127167227'; RELEASE CHANNEL ch00; RELEASE CHANNEL ch01; } 214723 2023/01/28 19:50恢复到20号 RUN { ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE'; ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE'; SEND 'NB_ORA_SERV=NBU01,NB_ORA_CLIENT=appp2'; RECOVER DATABASE UNTIL SEQUENCE 214723; RELEASE CHANNEL ch00; RELEASE CHANNEL ch01; } 2023/1/22 23:28:00 2023/1/22 23:42:18 214837 RUN { ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE'; ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE'; SEND 'NB_ORA_SERV=NBU01,NB_ORA_CLIENT=appp2'; RECOVER DATABASE UNTIL SEQUENCE 214838; RELEASE CHANNEL ch00; RELEASE CHANNEL ch01; } 2023/1/24 23:35:42 2023/1/24 23:51:54 214963 RUN { ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE'; ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE'; SEND 'NB_ORA_SERV=NBU01,NB_ORA_CLIENT=appp2'; RECOVER DATABASE UNTIL SEQUENCE 214964; RELEASE CHANNEL ch00; RELEASE CHANNEL ch01; } 2023/1/27 8:04:52 2023/1/27 9:00:25 215121 -rw-rw---- oracle oinstall 8388608 Jan 27 09:03 /cntrl_54244_1_1127206988 RUN { ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE'; ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE'; SEND 'NB_ORA_SERV=NBU01,NB_ORA_CLIENT=appp2'; RESTORE CONTROLFILE FROM 'cntrl_54244_1_1127206988'; RELEASE CHANNEL ch00; RELEASE CHANNEL ch01; } RUN { ALLOCATE CHANNEL ch00 TYPE 'SBT_TAPE'; ALLOCATE CHANNEL ch01 TYPE 'SBT_TAPE'; SEND 'NB_ORA_SERV=NBU01,NB_ORA_CLIENT=appp2'; RECOVER DATABASE UNTIL SEQUENCE 215122; RELEASE CHANNEL ch00; RELEASE CHANNEL ch01; } alter database open resetlogs; lsnrctl start listener_nmmpdb |
将数据库使用rman恢复完成后,数据库运行正常。
4 故障解决建议
通过上述对故障的分析,问题主要出现在hdisk3存储在进行数据库单块读时hang住,数据库进行随之hang死,建议对数据库存储进行检查分析。