咱们还是照图讨论,transformer结构图如下,本文主要讨论Encoder部分:
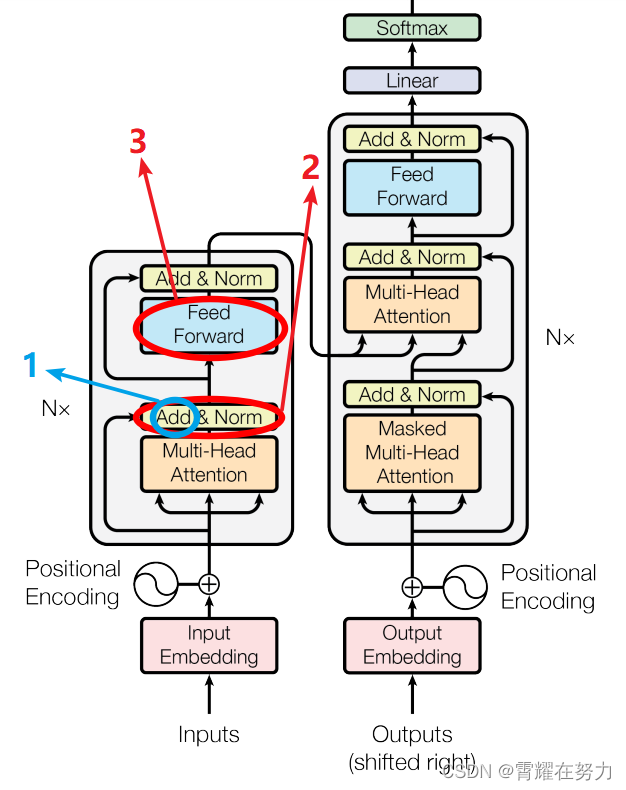
图一
一、首先说一下Encoder的输入部分:
在NLP领域,个人理解,这个inputs就是我们的句子分词之后的词语,比如“我,喜欢,吃,鱼”,然后Input Embedding就是对这些词语的向量化(词向量),之后加上这些词对应的位置信息(比如“喜欢”在“我喜欢吃鱼”中位置为2),两者结合作为Multi-Head Attention的输入。
二、途中标号部分讨论:
蓝色圆圈标注的“add”是什么呢?好像初始注意力机制(如下图)中并没有add呀??
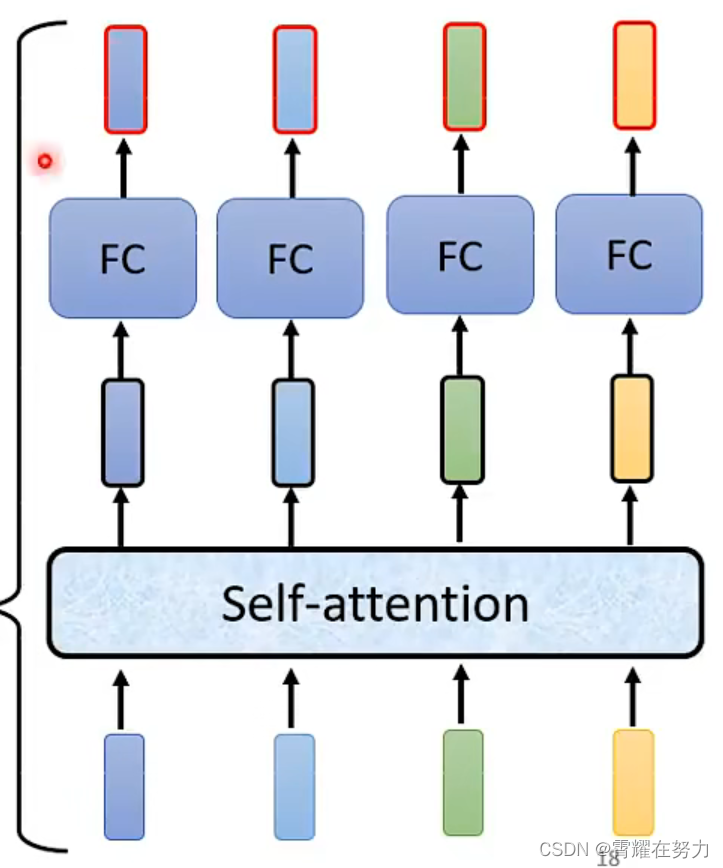
图二
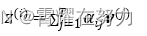
如图所示,初始架构中self-attention求出 z(i) 后直接将z放入全连接中,而transformer又经过了add&Norm步骤 ,这个add是什么呢???
其实add就是在Z的基础上加了一个残差块X,加入残差块X的目的是为了防止在深度神经网络训练中发生退化问题,退化的意思就是深度神经网络通过增加网络的层数,Loss逐渐减小,然后趋于稳定达到饱和,然后再继续增加网络层数,Loss反而增大。具体操作如下:其实就是将self-attention的output+input作为新的output,如下图:
图三
关于首图所标记的2,Add&Norm这一过程指什么呢?
就是指对新的output做标准化,也就是上图的,对a+b做标准化
FeedForward:FeedForward又是什么呢?好像图二(注意力机制)中这里应该是全连接层(FC)呀?❓❓❓
先说一下FeedForward是什么?其实FeedForward是由全连接层(FC)与激活ReLu组成的结构,其实和bp神经网络结构差不多,输入:Add&Norm的输出(记作:Z'(i) ), FC:全连接层
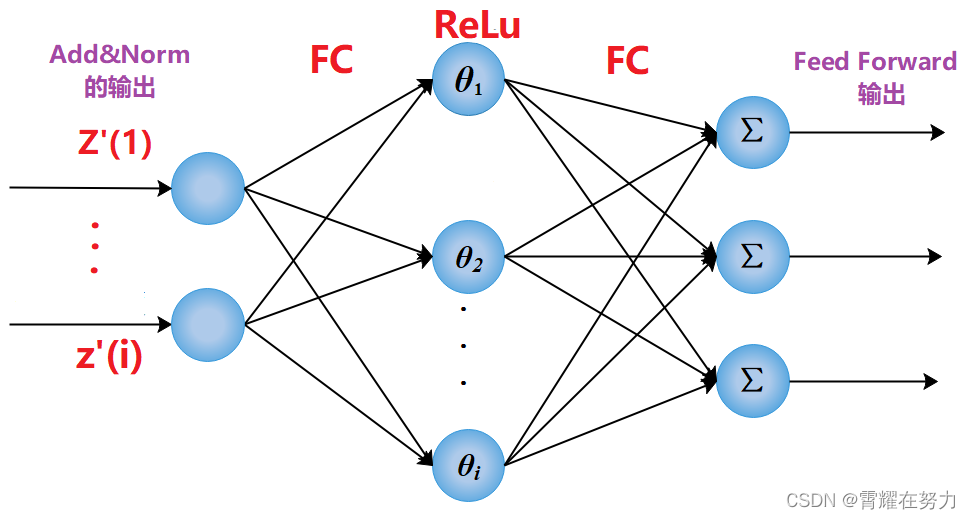
接下来再说一下为什么要用FeedForward呢?不用单纯的FC呢?
其实主要还是想提取更深层次的特征,在Multi-Head Attention中,主要是进行矩阵乘法,即都是线性变换,而线性变换的学习能力不如非线性变换的学习能力强,我们希望通过引入ReLu激活函数,使模型增加非线性成分,强化学习能力。