原文链接:https://blog.csdn.net/mengxianglong123/article/details/126261479
1.1 Transformer的诞生
2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!
论文地址: https://arxiv.org/pdf/1810.04805.pdf
而在BERT中发挥重要作用的结构就是Transformer, 之后又相继出现XLNET,roBERT等模型击败了BERT,但是他们的核心没有变,仍然是:Transformer.
1.2 Transformer的优势
相比之前占领市场的LSTM和GRU模型,Transformer有两个显著的优势:
Transformer能够利用分布式GPU进行并行训练,提升模型训练效率.
在分析预测更长的文本时, 捕捉间隔较长的语义关联效果更好.
下面是一张在测评比较图:
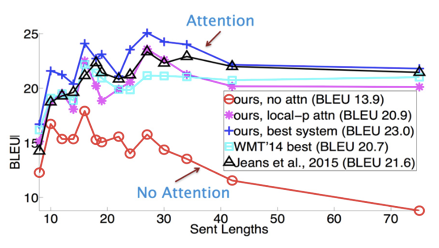
1.3 Transformer的市场
在著名的SOTA机器翻译榜单上, 几乎所有排名靠前的模型都使用Transformer,
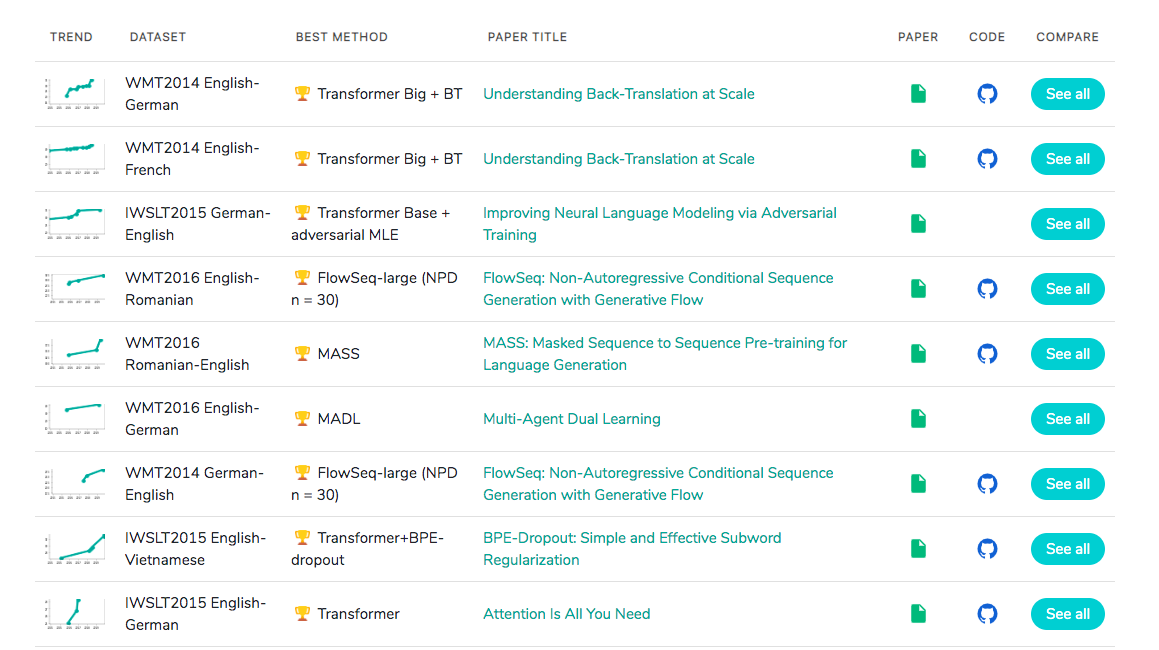
其基本上可以看作是工业界的风向标, 市场空间自然不必多说!
二、Transformer架构解析
2.1 认识Transformer架构
2.1.1 Transformer模型的作用
基于seq2seq架构的transformer模型可以完成NLP领域研究的典型任务, 如机器翻译, 文本生成等. 同时又可以构建预训练语言模型,用于不同任务的迁移学习.
声明:
在接下来的架构分析中, 我们将假设使用Transformer模型架构处理从一种语言文本到另一种语言文本的翻译工作, 因此很多命名方式遵循NLP中的规则. 比如: Embeddding层将称作文本嵌入层, Embedding层产生的张量称为词嵌入张量, 它的最后一维将称作词向量等.
2.1.2 Transformer总体架构图
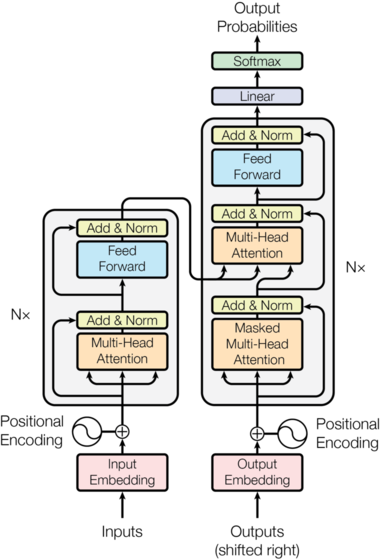
Transformer总体架构可分为四个部分:
输入部分
输出部分
编码器部分
解码器部分