这篇文章比较早,但是对于因果介绍的比较详细,很值得学习。
代码:https://github.com/Wangt-CN/VC-R-CNN
代码花了挺长时间总算跑通了,在 3080 上调真是错误不断,后来换到 2080 又是一顿调才好。这里跑通的主要环境为 ubuntu,2080,cuda 11.3, torch ‘1.10.1+cu113’ 。一些配置如下
- 安装 conda 后,conda create --name vc_rcnn python=3.7
- conda activate vc_rcnn pip install ninja yacs cython matplotlib tqdm opencv-python h5py lmdb -i https://pypi.mirrors.ustc.edu.cn/simple/
- pip install torch==1.10.1+cu113 torchvision==0.11.2+cu113 torchaudio==0.10.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113 -i https://pypi.mirrors.ustc.edu.cn/simple/ (高于 1.10版本的话安装 vc-r-cnn 会有问题)
- 参考代码里的 install.md 安装 coco 和 apex 以及 vc-rcnn 即可。
作者大大有个博客对于因果学习和这篇文章介绍的都很详细,见 https://zhuanlan.zhihu.com/p/111306353
因此这里具体的介绍就不多写了,可参考原始文章和博客。只说实现部分。
-
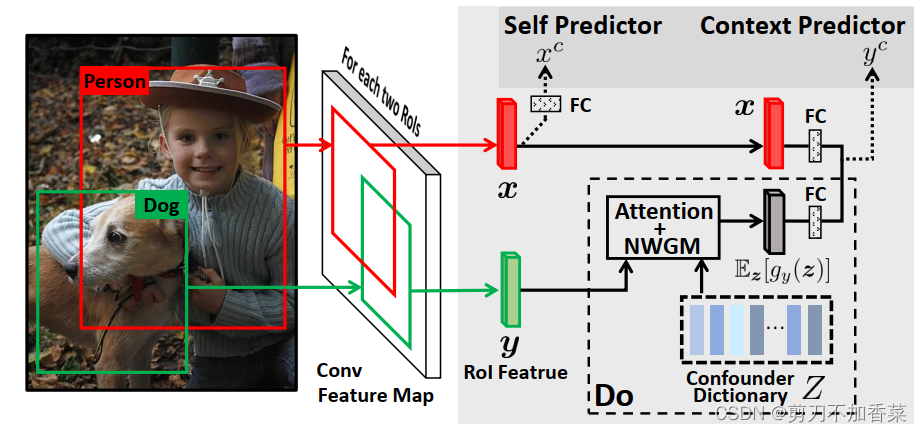
首先根据数据集构建 confounder Z Z Z 和先验数据分布 P ( z ) P(z) P(z)。 具体而言,confunder 指的是特定类别的固定表征,利用的是 gt 获得的,将特定类别的所有目标加一起取平均,对于coco而言获得 80 × 1024 80 \times 1024 80×1024 的 confounder,每个行都对应一个类别。而先验分布 P ( z ) P(z) P(z) 维度为 1 × 80 1 \times 80 1×80 ,表示特定类别出现的频率(所有值加一起和为1),应该是特定类别出现的频数除以总的目标个数得到。文章定义如下,是预先获得直接加载的。
self.dic = torch.tensor(np.load(cfg.DIC_FILE)[1:], dtype=torch.float) # [80,1024]
self.prior = torch.tensor(np.load(cfg.PRIOR_PROB), dtype=torch.float) # [80] -
模型使用的是 ResNet+FPN, 也会生成不止一个 proposals。之后就是设计两个分类器。Self Predictor 和一般使用的基本没什么区别,重点关注 Context Predict。公式如下,代码看后边。 80 × 1024 80 \times 1024 80×1024 的 confounder 首先和 ROI 特征 y y y 计算attention,具体先经过全连接,然后点乘,再通过 softmax,获得 4 × 80 4 \times 80 4×80 的attention (4 表示该样本有 4 个 proposals)。按照我们一般的思路,这个 attention 可以直接聚合对应的 80 个特征向量。然而这里再和 confounder 的先验分布 P ( z ) P(z) P(z) 相乘,很有意思,在 attention 中强行加入 confunder(即各个类别)的出现频率(ps,感觉那么像解决长尾分布的问题)。最后对这些特征聚合得到 4 × 1024 4 \times 1024 4×1024 的特征。这些特征和模型获得的 ROI 特征 x x x (公式是 x x x,但是代码中表示的应该就是前面所说的 y y y,是一样的 ROI 特征,不知道是不是表示错误还是我理解错误)进行拼接(公式里是相加,可能也表示拼接)。这样就能获得一个包含真实特征和 confounter 的特征。最后用 Context Predict (它的输入是Self Predictor 输入维度的两倍)进行预测。
q = W 3 y , K = W 4 Z T E z [ g y ( z ) ] = ∑ z [ Softmax ( q T K / σ ) ⊙ Z ] P ( z ) E z [ f y ( x , z ) ] = W 1 x + W 2 ⋅ E z [ g y ( z ) ] \boldsymbol{q}=\boldsymbol{W}_3 \boldsymbol{y}, \boldsymbol{K}=\boldsymbol{W}_4 \boldsymbol{Z}^T \\ \mathbb{E}_{\boldsymbol{z}}\left[g_y(\boldsymbol{z})\right]=\sum_z\left[\operatorname{Softmax}\left(\boldsymbol{q}^T \boldsymbol{K} / \sqrt{\sigma}\right) \odot \boldsymbol{Z}\right] P(\boldsymbol{z}) \\ \mathbb{E}_{\boldsymbol{z}}\left[f_y(\boldsymbol{x}, \boldsymbol{z})\right]=\boldsymbol{W}_1 \boldsymbol{x}+\boldsymbol{W}_2 \cdot \mathbb{E}_{\boldsymbol{z}}\left[g_y(\boldsymbol{z})\right] \\ q=W3y,K=W4ZTEz[gy(z)]=z∑[Softmax(qTK/σ)⊙Z]P(z)Ez[fy(x,z)]=W1x+W2⋅Ez[gy(z)] -
最后能让训练整个的特征提取器减少模型受这种这种 bias (共现的bias,位置的bias等)的干扰。
def z_dic(self, y, dic_z, prior):
"""
Please note that we computer the intervention in the whole batch rather than for one object in the main paper.
"""
length = y.size(0) # proposals 的数量 torch.Size([4, 1024])
if length == 1:
print('debug')
# torch.mm(self.Wy(y), self.Wz(dic_z).t()) --> torch.Size([4, 80])
attention = torch.mm(self.Wy(y), self.Wz(dic_z).t()) / (self.embedding_size ** 0.5)
attention = F.softmax(attention, 1)
z_hat = attention.unsqueeze(2) * dic_z.unsqueeze(0) # torch.Size([4, 80, 1024])
z = torch.matmul(prior.unsqueeze(0), z_hat).squeeze(1) # [1, 80], torch.Size([4, 80, 1024]) --> torch.Size([4, 1, 1024]) --> torch.Size([4, 1024])
xz = torch.cat((y.unsqueeze(1).repeat(1, length, 1), z.unsqueeze(0).repeat(length, 1, 1)), 2).view(-1, 2*y.size(1)) # y [4,1024]->[4,4,1024], z [4,1024]->[4,4,1024] => cat [4,4, 2048] ==> [16, 2048]
# detect if encounter nan
if torch.isnan(xz).sum():
print(xz)
return xz
总的来说,实现上很有意思的,不知道是先有了因果的思考才有的实现思路,还是先有实现的方法再有的因果的角度hh。张老师组这几年在因果学习上发表了相当多的文章,很多领域都有涉及,很有启发性,值得学习。