关联函数
当两个RDD的数据类型为二元组Key/Value对时,可以依据Key进行关联Join。

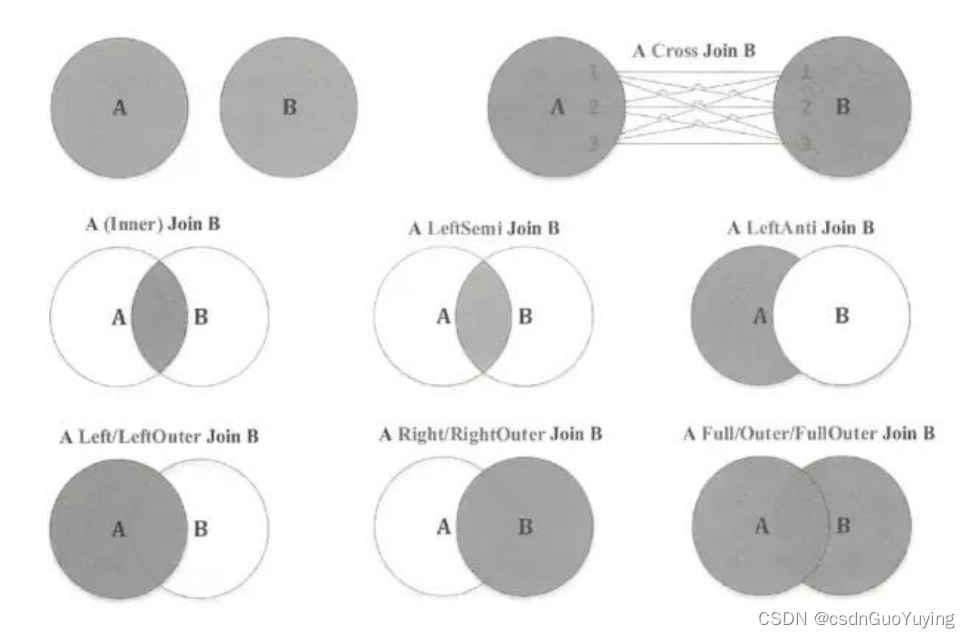
首先回顾一下SQL JOIN,用Venn图表示如下:
RDD中关联JOIN函数都在PairRDDFunctions中,具体截图如下:
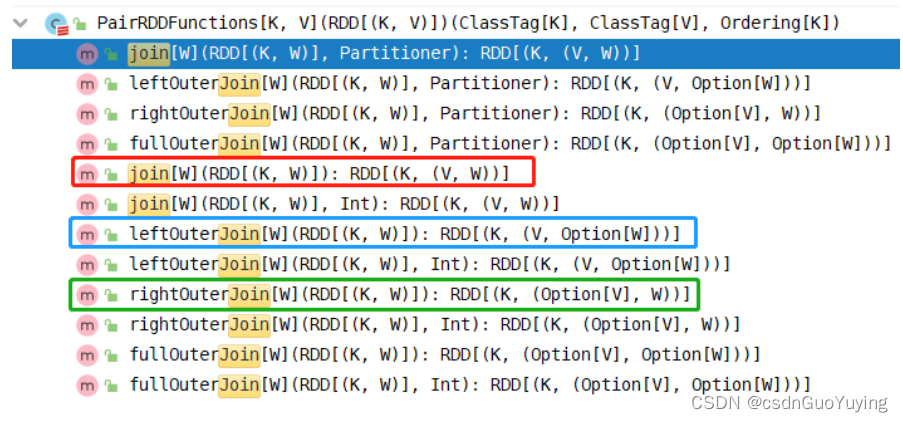
具体看一下join(等值连接)函数说明:

范例演示代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* RDD中关联函数Join,针对RDD中数据类型为Key/Value对
*/
object SparkJoinTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// 模拟数据集
val empRDD: RDD[(Int, String)] = sc.parallelize(
Seq((1001, "zhangsan"), (1002, "lisi"), (1003, "wangwu"), (1004, "zhangliu"))
)
val deptRDD: RDD[(Int, String)] = sc.parallelize(
Seq((1001, "sales"), (1002, "tech"))
)
/*
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
*/
val joinRDD: RDD[(Int, (String, String))] = empRDD.join(deptRDD)
println(joinRDD.collectAsMap())
/*
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
*/
val leftJoinRDD: RDD[(Int, (String, Option[String]))] = empRDD.leftOuterJoin(deptRDD)
println(leftJoinRDD.collectAsMap())
// 应用程序运行结束,关闭资源
sc.stop()
}
}
函数练习
RDD中的函数有很多,不同业务需求使用不同函数进行数据处理分析,下面仅仅展示出比较常用的函数使用,更多函数在实际中使用体会,多加练习理解。
map 函数
对RDD中的每一个元素进行操作并返回操作的结果。

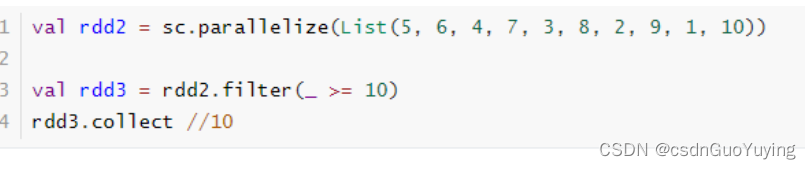
filter 函数
函数中返回True的被留下,返回False的被过滤掉。
flatMap 函数
对RDD中的每一个元素进行先map再压扁,最后返回操作的结果。

交集、并集、差集、笛卡尔积
数学集合中操作,类似Scala集合类Set中相关函数,注意类型要一致。

distinct 函数
对RDD中元素进行去重,与Scala集合中distinct类似。

first、take、top 函数
从RDD中获取某些元素,比如first为第一个元素,take为前N个元素,top为最大的N个元素。

keys、values 函数
针对RDD中数据类型为KeyValue对时,获取所有key和value的值,类似Scala中Map集合。

mapValues 函数
mapValues表示对RDD中的元素进行操作,Key不变,Value变为操作之后。

collectAsMap 函数
当RDD中数据类型为Key/Value对时,转换为Map集合。

mapPartitionsWithIndex 函数
取分区中对应的数据时,还可以将分区的编号取出来,这样就可以知道数据是属于哪个分区的