本章主要介绍ES的基础操作,具体包括索引、映射和文档的相关操作。其中,在文档操作中将分别介绍单条操作和批量操作。在生产实践中经常会通过程序对文档进行操作,因此在介绍文档操作时会分别介绍DSL请求形式和Java的高级REST编码形式。
1 索引操作
本节主要介绍索引的相关操作,涉及创建、删除、关闭和打开索引,以及索引别名的操作。其中,索引别名的操作在生产环境中使用比较广泛,可以和关闭或删除索引配合使用。在生产环境中使用索引时,一定要慎重操作,因为稍有不慎就会导致数据的丢失或异常。
1.1 创建索引
使用ES构建搜索引擎的第一步是创建索引。在创建索引时,可以按照实际需求对索引进行主分片和副分片设置。ES创建索引的请求类型为PUT,其请求形式如下:
PUT /${index_name}
{ "settings":{
…
}
"mappings":{
…
}
}
其中:变量index_name就是创建的目标索引名称;可以在settings子句内部填写索引相关的设置项,如主分片个数和副分片个数等;可以在mappings子句内部填写数据组织结构,即数据映射。
在第1章中曾介绍过创建索引hotel的语句,但是当时的主分片个数使用的是系统默认值(默认值为5),并且没有使用副分片个数(默认值为0)。假设设置主分片个数为15,副分片个数为2,则相应的DSL如下:
PUT /hotel
{
"settings" : {
"number_of_shards" : 15, //指定主分片个数
"number_of_replicas" : 2 //指定副分片个数
},
"mappings":{
"properties":{
…
}
}
}
1.2 删除索引
ES中删除索引的请求类型是DELETE,其请求形式如下:
DELETE /${index_name}
其中,${index_name}就是将要被删除的索引的名称,例如执行下面的删除命令:
DELETE /hotel
系统返回信息如下:
{
"acknowledged" : true //操作成功,通知信息
}
通过返回信息可知,目标索引hotel已经被删除。
1.3 关闭索引
在有些场景下,某个索引暂时不使用,但是后期可能又会使用,这里的使用是指数据写入和数据搜索。这个索引在某一时间段内属于冷数据或者归档数据,这时可以使用索引的关闭功能。索引关闭时,只能通过ES的API或者监控工具看到索引的元数据信息,但是此时该索引不能写入和搜索数据,待该索引被打开后,才能写入和搜索数据。先把索引hotel关闭,请求形式如下:
POST /hotel/_close
此时可以尝试进行数据写入:
POST /hotel/_doc/002
{
"title":"阳光夏日酒店",
"city":"北京",
"price":788.00
} "
ES返回信息如下:
{
"error" : {
"root_cause" : [
{
"type" : "index_closed_exception", //提示异常类型为索引已经关闭
"reason" : "closed",
"index_uuid" : "TIYkM2N5SCKlnmCOXuJPmg",
"index" : "hotel" //当前索引名称
}
],
"type" : "index_closed_exception",
"reason" : "closed",
"index_uuid" : "TIYkM2N5SCKlnmCOXuJPmg",
"index" : "hotel"
},
"status" : 400
}
根据上面的信息可知,索引关闭时写入数据将会报错。下面可以尝试进行数据搜索:
GET /hotel/_search
{
"query": {
"match": { //使用match搜索
"title": "再来"
}
}
}
ES返回的信息和进行写入请求时的返回信息是一样的,印证了索引在关闭时不能提供搜索服务的规定。
1.4 打开索引
索引关闭后,需要开启读写服务时可以将其设置为打开状态。下面的示例是把处于关闭状态的hotel索引设置为打开状态。
POST /hotel/_open
1.5 索引别名
顾名思义,别名是指给一个或者多个索引定义另外一个名称,使索引别名和索引之间可以建立某种逻辑关系。
可以用别名表示别名和索引之间的包含关系。例如,我们建立了1月、2月、3月的用户入住酒店的日志索引,假设当前日期是4月1日,需要搜索过去的3个月的日志索引,如果分别去3个索引中进行搜索,这种编码方案比较低效。此时可以创建一个别名last_three_month,设置前面的3个索引的别名为last_three_month,然后在last_three_month中进行搜索即可。如图3.1所示,last_three_month包含january_log、february_log和march_log3个索引,用户请求在last_three_month中进行搜索时,ES会在上述3个索引中进行搜索。
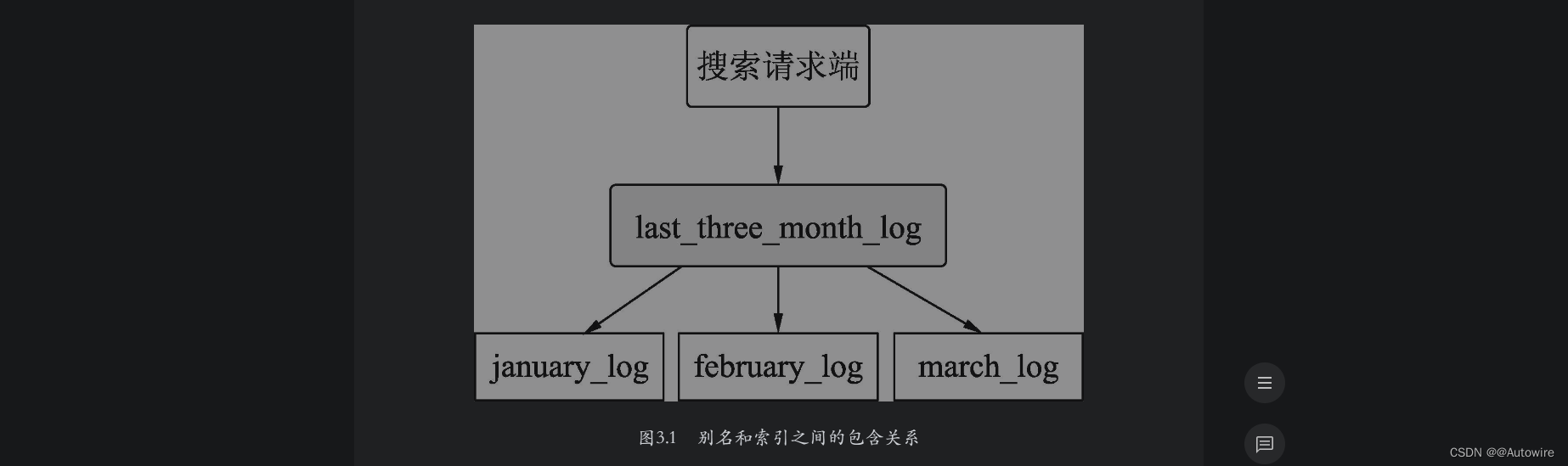
下面进行演示,首先依次建立january_log、february_log和march_log3个索引。创建索引january_log的DSL如下:
PUT /january_log
{
"mappings":{
"properties":{
"uid":{ //用户ID字段
"type":"keyword"
},
"hotel_id":{ //酒店ID字段
"type":"keyword"
},
"check_in_date":{ //入住日期字段
"type":"keyword"
}
}
}
}
因为这3个索引除了索引名称不一样,其他的参数都是一样的,所以创建索引february_log和march_log的DSL不再赘述。
下面分别在3个索引中写入同一用户在不同月份的入住记录。
在索引january_log中写入记录的DSL如下:
POST /january_log/_doc/001
{ //写入的文档数据
"uid":"001",
"hotel_id":"92772",
"check_in_date":"2021-01-05"
}
在索引february_log中写入记录的DSL如下:
POST /february_log/_doc/001
{ //写入的文档数据
"uid":"001",
"hotel_id":"33224",
"check_in_date":"2021-02-23"
}
在索引march_log中写入记录的DSL如下:
POST /march_log/_doc/001
{ //写入的文档数据
"uid":"001",
"hotel_id":"92772",
"check_in_date":"2021-03-28"
}
现在建立别名last_three_month,设置上面3个索引的别名为last_three_month,请求的DSL如下:
POST /_aliases
{
"actions": [
{
"add": { //为索引january_log建立别名last_three_month
"index": "january_log",
"alias": "last_three_month"
}
},
{
"add": { //为索引february_log建立别名last_three_month
"index": "february_log",
"alias": "last_three_month"
}
},
{
"add": { //为索引march_log建立别名last_three_month
"index": "march_log",
"alias": "last_three_month"
}
}
]
}
此时,请求在索引last_three_month中搜索uid为001的用户的入住记录,搜索的DSL如下:
GET /last_three_month/_search
{
"query": {
"term": { //搜索uid为001的文档
"uid": "001"
}
}
}
搜索结果返回的数据如下:
{
…
"hits" : {
…
"hits" : [
{ //索引february_log中命中的文档信息
"_index" : "february_log",
"_type" : "_doc",
"_id" : "001",
"_score" : 0.2876821,
"_source" : {
"uid" : "001",
"hotel_id" : "33224",
"check_in_date" : "2021-02-23"
}
},
{ //索引january_log中命中的文档信息
"_index" : "january_log",
"_type" : "_doc",
"_id" : "001",
"_score" : 0.2876821,
"_source" : {
"uid" : "001",
"hotel_id" : "92772",
"check_in_date" : "2021-01-05"
}
},
{ //索引march_log中命中的文档信息
"_index" : "march_log",
"_type" : "_doc",
"_id" : "001",
"_score" : 0.2876821,
"_source" : {
"uid" : "001",
"hotel_id" : "92772",
"check_in_date" : "2021-03-28"
}
}
]
}
}
由上面的结果可知,当请求搜索last_three_month的数据时,ES将请求转发到了january_log、february_log和march_log3个索引中。
需要指出的是,在默认情况下,当一个别名只指向一个索引时,写入数据的请求可以指向这个别名,如果这个别名指向多个索引(就像上面的例子),则写入数据的请求是不可以指向这个别名的。例如,向last_three_month中写入一条数据:
POST /last_three_month/_doc/002
{ //向别名索引last_three_month中写入数据
"uid":"002",
"hotel_id":"92772",
"check_in_date":"2021-01-28"
}
ES返回的报错信息如下:
{
"error" : {
"root_cause" : [
{ //无法写入数据的报错信息
"type" : "illegal_argument_exception",
"reason" : "no write index is defined for alias [last_three_month].
The write index may be explicitly disabled using is_write_index=false or
the alias points to multiple indices without one being designated as a write
index"
}
],
//无法写入数据的报错信息
"type" : "illegal_argument_exception",
"reason" : "no write index is defined for alias [last_three_month]. The
write index may be explicitly disabled using is_write_index=false or the
alias points to multiple indices without one being designated as a write
index"
},
"status" : 400 //返回状态码
}
根据上面的报错信息可知,在默认情况下,ES不能确定向last_three_month写入数据时的转发对象。这种情况需要在别名设置时,将目标索引的is_write_index属性值设置为true来指定该索引可用于执行数据写入操作。例如设置january_log为数据写入转发对象,对应的DSL如下:
POST /_aliases
{
"actions": [
{
"add": { //设置january_log为索引别名last_three_month的数据写入转发对象
"index": "january_log",
"alias": "last_three_month",
"is_write_index":true
}
}
]
}
此时可以再向last_three_month中写入上面的数据,不再赘述。
ES返回的结果如下:
{
"_index" : "january_log", //实际被写入的索引名称
"_type" : "_doc",
"_id" : "002", //文档ID
"_version" : 1, //文档版本
"result" : "created", //写入成功标识
"_shards" : {
"total" : 2,
"successful" : 1, //写入成功状态码
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
根据上面的结果可知,将索引别名last_three_month的数据写入转发对象设置为索引january_log之后,再向last_three_month发起写入数据的请求时,ES会将该请求转发到索引january_log中。
引入别名之后,还可以用别名表示索引之间的替代关系。这种关系一般是在某个索引被创建后,有些参数是不能更改的(如主分片的个数),但随着业务发展,索引中的数据增多,需要更改索引参数进行优化。我们需要平滑地解决该问题,既要更改索引的设置,又不能改变索引名称,这时就可以使用索引别名。
假设一个酒店的搜索别名设置为hotel,初期创建索引hotel_1时,主分片个数设置为5,然后设置hotel_1的别名为hotel。此时客户端使用索引别名hotel进行搜索请求,该请求会转发到索引hotel_1中。假设此时酒店索引中的新增数据急剧增长,索引分片需要扩展,需要将其扩展成为10个分片的索引。但是一个索引在创建后,主分片个数已经不能更改,因此只能考虑使用索引替换来完成索引的扩展。这时可以创建一个索引hotel_2,除了将其主分片个数设置为10外,其他设置与hotel_1相同。当hotel_2的索引数据准备好后,删除hotel_1的别名hotel,同时,置hotel_2的别名为hotel。此时客户端不用进行任何改动,继续使用hotel进行搜索请求时,该请求会转发给索引hotel_2。如果服务稳定,最后将hotel_1删除即可。此时借助别名就完成了一次索引替换工作。
如图3.2所示,在左图中,hotel索引别名暂时指向hotel_1,hotel_2做好了数据准备;在右图中,hotel索引别名指向hotel_2,完成了索引的扩展切换。
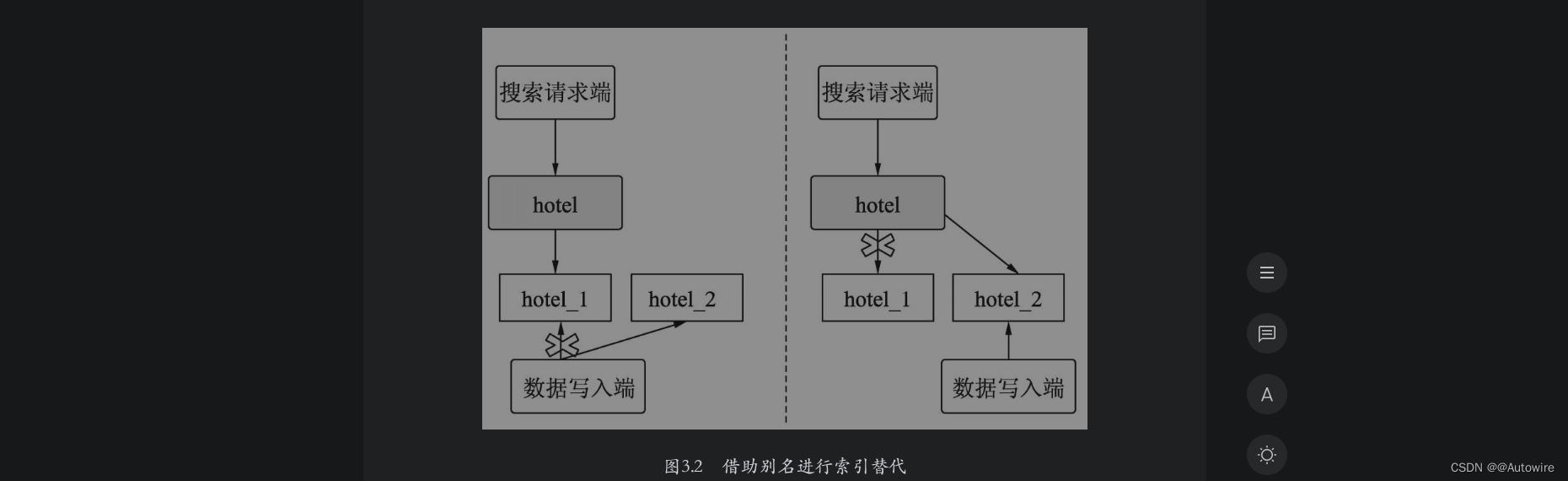
下面进行演示。首先建立索引hotel_1,设置其主分片个数为5,其他信息与创建索引时保持一致。
PUT /hotel_1
{
"settings": {
"number_of_shards" : 5, //设置主分片个数为5
"number_of_replicas" : 2 //设置副分片个数为2
},
"mappings":{…}
}
在数据写入端向hotel_1写入搜索数据,请求的DSL如下:
POST /hotel_1/_doc/001
{ //写入的文档数据
"title":"好再来酒店",
"city":"青岛",
"price":578.23
}
建立别名hotel,请求的DSL如下:
POST /_aliases
{
"actions": [
{
"add": { //为索引hotel_1建立别名hotel
"index": "hotel_1",
"alias": "hotel"
}
}
]
}
在搜索请求端使用hotel进行搜索,假设在title字段中搜索“再来”,搜索的DSL如下:
GET /hotel/_search
{
"query": { //在hotel中搜索
"match": {
"title": "再来"
}
}
}
ES返回的数据如下:
{
…
"hits" : {
…
"hits" : [ //命中的文档信息
{
"_index" : "hotel_1", //索引hotel_1上命中的文档
"_type" : "_doc",
"_id" : "001",
"_score" : 0.5753642,
"_source" : { //具体的文档信息
"title" : "好再来酒店",
"city" : "青岛",
"price" : 578.23
}
}
]
}
}
通过搜索结果可以看出,因为只有索引hotel_1的别名为hotel,所以向索引别名hotel发起搜索请求时ES会将搜索请求全部转发给索引hotel_1。
假设过一段时间后酒店索引的分片需要扩展。通过变更索引的方式可以完成扩展。建立索引hotel_2,并设置主分片个数为10,设置副分片个数为2,请求的DSL如下:
PUT /hotel_2
{
"settings": {
"number_of_shards" : 10, //设置主分片数为10
"number_of_replicas" : 2 //设置副分片数为2
},
"mappings":{…}
}
在数据写入端向索引hotel_2中写入搜索数据,请求的DSL如下:
POST /hotel_2/_doc/001
{ //向索引hotel_2中写入的文档数据
"title":"好再来酒店",
"city":"青岛",
"price":578.23
}
此时hotel_2中的数据已经准备完毕,现在变更别名设置,删除hotel_1的索引别名,设置索引hotel_2的别名为hotel2,请求的DSL如下:
POST /_aliases
{
"actions": [
{
"remove": { //删除索引hotel_1的别名hotel
"index": "hotel_1",
"alias": "hotel"
}
},
{
"add": { //增加索引hotel_2的别名hotel
"index": "hotel_2",
"alias": "hotel"
}
}
]
}
再执行前面的搜索,返回结果如下:
{
…
"hits" : {
…
"hits" : [
{ //命中索引hotel_2中的文档
"_index" : "hotel_2",
"_type" : "_doc",
"_id" : "001",
"_score" : 0.5753642,
"_source" : {
"title" : "好再来酒店",
"city" : "青岛",
"price" : 578.23
}
}
]
}
}
通过搜索结果可以看出,请求hotel索引进行搜索时,搜索已经从转发给hotel_1变更为转发给hotel_2。因此,索引别名在这种需要变更索引的情况下,搜索端不需要任何变更即可完成切换,这在实际的生产环境中是非常方便的。
2 映射操作
在使用数据之前,需要构建数据的组织结构。这种组织结构在关系型数据库中叫作表结构,在ES中叫作映射。作为无模式搜索引擎,ES可以在数据写入时猜测数据类型,从而自动创建映射。但有时ES创建的映射中的数据类型和目标类型可能不一致。当需要严格控制数据类型时,还是需要用户手动创建映射。
本节首先介绍映射的创建、查看和修改操作,然后详细介绍ES中的基本数据类型和复杂的数据类型,并且会对常用的类型用法进行示范,最后介绍映射的常用参数和动态映射的使用。
2.1 查看映射
在ES中写入文档请求的类型是GET,其请求形式如下:
GET /${index_name}/_mapping
上面的index_name就是索引名称。查看索引hotel的mappings,请求的DSL如下:
GET /hotel/_mapping
ES的返回结果如下:
{
"hotel" : {
"mappings" : {
"properties" : {
"city" : { //定义city字段类型为keyword
"type" : "keyword"
},
"price" : { //定义price字段类型为double
"type" : "double"
},
"title" : { //定义title字段类型为text
"type" : "text"
}
}
}
}
}
通过返回信息可见,查看索引hotel的mappings时,返回的信息和建立该索引时的信息是一致的。
2.2 扩展映射
可能有的读者看到标题时会有疑问:映射不能修改吗?为什么是扩展呢?答案是,映射中的字段类型是不可以修改的,但是字段可以扩展。最常见的扩展方式是增加字段和为object(对象)类型的数据新增属性。下面的DSL示例为扩展hotel索引,并增加tag字段。
POST /hotel/_mapping
{
"properties": {
"tag": { //索引中新增字段tag,类型为keyword
"type": "keyword"
}
}
}
查看索引hotel的mappings,返回结果如下:
{
"hotel" : {
"mappings" : {
"properties" : {
"city" : { //原有的city字段,类型为keyword
"type" : "keyword"
},
"price" : { //原有的price字段,类型为double
"type" : "double"
},
"tag" : { //新增tag字段,类型为keyword
"type" : "keyword"
},
"title" : { //原有的title字段,类型为text
"type" : "text"
}
}
}
}
}
由返回结果可知,tag字段已经被添加到索引hotel中。
2.3 基本的数据类型
1 keyword类型
keyword类型是不进行切分的字符串类型。这里的“不进行切分”指的是:在索引时,对keyword类型的数据不进行切分,直接构建倒排索引;在搜索时,对该类型的查询字符串不进行切分后的部分匹配。keyword类型数据一般用于对文档的过滤、排序和聚合。
在现实场景中,keyword经常用于描述姓名、产品类型、用户ID、URL和状态码等。keyword类型数据一般用于比较字符串是否相等,不对数据进行部分匹配,因此一般查询这种类型的数据时使用term查询。
例如,建立一个人名索引,可以设定姓名字段为keyword字段:
PUT /user
{
"mappings": {
"properties": {
"user_name":{ //定义user_name字段类型为keyword
"type": "keyword"
}
}
}
}
现在写入一条数据,请求的DSL如下:
POST /user/_doc/001
{ //写入数据
"user_name":"张三"
}
下面查询刚刚写入的数据,请求的DSL如下:
GET /user/_search
{
"query": {
"term": { //term查询
"user_name": {
"value": "张三"
}
}
}
}
返回的结果信息如下:
{
…
"hits" : [
{ //返回命中的文档
"_index" : "user",
"_type" : "_doc",
"_id" : "001",
"_score" : 0.2876821,
"_source" : {
"user_name" : "张三"
}
}
]
}
}
由搜索结果可以看出,使用term进行全字符串匹配“张三”可以搜索到命中文档。
下面的DSL使用match搜索姓名中带有“张”的记录:
GET /user/_search
{
"query": {
"match": { //使用match搜索
"user_name": "张"
}
}
}
返回结果如下:
{
…
"hits" : {
"total" : { //没有命中文档
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ] //命中文档的集合为空
}
}
由搜索结果可见,对keyword类型使用match搜索进行匹配是不会命中文档的。
2 text类型
text类型是可进行切分的字符串类型。这里的“可切分”指的是:在索引时,可按照相应的切词算法对文本内容进行切分,然后构建倒排索引;在搜索时,对该类型的查询字符串按照用户的切词算法进行切分,然后对切分后的部分匹配打分。
例如,一个酒店搜索项目,我们希望可以根据酒店名称即title字段进行模糊匹配,因此可以设定title字段为text字段,建立酒店索引的DSL如下:
PUT /hotel
{
"mappings":{
"properties":{
"title":{ //定义title字段类型为text
"type":"text"
}
…
}
}
}
现在写入一条数据:
POST /hotel/_doc/001
{ //写入数据
"title":"文雅酒店"
}
下面先按照普通的term进行搜索,观察能否搜索到刚刚写入的文档,请求的DSL如下:
GET /hotel/_search
{
"query": {
"term": { //使用term搜索
"title": {
"value": "文雅酒店"
}
}
}
}
返回结果如下:
{
…
"hits" : {
"total" : { //使用term搜索text类型数据时没有命中文档
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ] //命中的文档集合为空
}
}
根据返回结果可知,上面的请求并没有搜索到文档。term搜索用于搜索值和文档对应的字段是否完全相等,而对于text类型的数据,在建立索引时ES已经进行了切分并建立了倒排索引,因此使用term没有搜索到数据。一般情况下,搜索text类型的数据时应使用match搜索。关于match搜索的具体使用,后面的章节会详细介绍,本节仅进行简单的使用:
GET /hotel/_search
{
"query": {
"match": { //使用match搜索
"title": "文雅"
}
}
}
返回结果如下:
{
…
"hits" : {
"total" : {
"value" : 1, //有一个文档被命中
"relation" : "eq"
},
"max_score" : 0.5753642,
"hits" : [ //命中的文档数据
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 0.5753642,
"_source" : {
"title" : "文雅酒店"
}
}
]
}
}
3 数值类型
ES支持的数值类型有long、integer、short、byte、double、float、half_float、scaled_float和unsigned_long等。各类型所表达的数值范围可以参考官方文档,网址为https://www.elastic.co/guide/en/elasticsearch/reference/current/number.html。为节约存储空间并提升搜索和索引的效率,在实际应用中,在满足需求的情况下应尽可能选择范围小的数据类型。比如,年龄字段的取值最大值不会超过200,因此选择byte类型即可。数值类型的数据也可用于对文档进行过滤、排序和聚合。以酒店搜索为例,酒店的索引除了包含酒店名称和城市之外,还需要定义价格、星级和评论数等,创建索引的DSL如下:
PUT /hotel
{
"mappings":{
"properties":{
"title":{
"type":"text"
},
"city":{
"type":"keyword"
},
"price":{ //定义价格字段,类型为double
"type":"double"
},
"star":{ //定义星级字段,类型为byte
"type":"byte"
},
"comment_count":{ //定义评论数字段,类型为integer
"type":"integer"
}
}
}
}
对于数值型数据,一般使用term搜索或者范围搜索。例如,搜索价格为350~400(包含350和400)元的酒店,搜索的DSL如下:
GET /hotel/_search
{
"query": {
"range": { //定义range查询
"price": {
"gte": 350,
"lte": 400
}
}
}
}
4 布尔类型
布尔类型使用boolean定义,用于业务中的二值表示,如商品是否售罄,房屋是否已租,酒店房间是否满房等。写入或者查询该类型的数据时,其值可以使用true和false,或者使用字符串形式的"true"和"false"。下面的DSL定义索引中“是否满房”的字段为布尔类型:
PUT /hotel
{
"mappings":{
"properties":{
"title":{
"type":"text"
},
"city":{
"type":"keyword"
},
"price":{
"type":"double"
},
"full_room":{ //定义是否满房的字段,类型为boolean
"type": "boolean"
}
}
}
}
下面的DSL将查询满房的酒店:
GET /hotel/_search
{
"query": {
"term": {
"full_room": { //使用term查询boolean类型的数据
"value": "true"
}
}
}
}
5 日期类型
在ES中,日期类型的名称为date。ES中存储的日期是标准的UTC格式。下面定义索引hotel,该索引有一个create_time字段,现在把它定义成date类型。定义date类型请求的DSL如下:
PUT /hotel
{
"mappings":{
"properties":{
"title":{
"type":"text"
},
"city":{
"type":"keyword"
},
"price":{
"type":"double"
},
"create_time":{ //定义create_time字段,类型为date
"type":"date"
}
}
}
}
一般使用如下形式表示日期类型数据:
- 格式化的日期字符串。
- 毫秒级的长整型,表示从1970年1月1日0点到现在的毫秒数。
- 秒级别的整型,表示从1970年1月1日0点到现在的秒数。
日期类型的默认格式为strict_date_optional_time||epoch_millis。其中,strict_date_optional_time的含义是严格的时间类型,支持yyyy-MM-dd、yyyyMMdd、yyyyMMddHHmmss、yyyy-MM-ddTHH:mm:ss、yyyy-MM-ddTHH:mm:ss.SSS和yyyy-MM-ddTHH:mm:ss.SSSZ等格式,epoch_millis的含义是从1970年1月1日0点到现在的毫秒数。
下面写入索引的文档中有一个create_time字段是日期格式的字符串,请求的DSL如下:
POST /hotel/_doc/001
{ //写入数据
"title":"好再来酒店",
"city":"青岛",
"price":578.23,
"create_time":"20210115"
}
搜索日期型数据时,一般使用ranges查询。例如,搜索创建日期为2015年的酒店,请求的DSL如下:
GET /hotel/_search
{
"query": {
"range": { //使用range搜索日期型数据
"create_time": {
"gte": "20150101",
"lt": "20160101"
}
}
}
}
日期类型默认不支持yyyy-MM-dd HH:mm:ss格式,如果经常使用这种格式,可以在索引的mapping中设置日期字段的format属性为自定义格式。下面的示例将设置create_time字段的格式为yyyy-MM-dd HH:mm:ss:
PUT /hotel
{
"mappings":{
"properties":{
"title":{
"type":"text"
},
"city":{
"type":"keyword"
},
"price":{
"type":"double"
},
"create_time":{ //指定日期型字段的格式
"type":"date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
此时如果再写入以前的数据,系统将报错。报错信息如下:
{
"error" : {
"root_cause" : [
{ //日期格式解析异常
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [create_time] of type [date] in
document with id '001'. Preview of field's value: '20210115'"
}
],
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [create_time] of type [date] in document
with id '001'. Preview of field's value: '20210115'", //日期格式解析异常
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "failed to parse date field [20210115] with format [yyyy-
MM-dd HH:mm:ss]",
"caused_by" : {
"type" : "date_time_parse_exception",
"reason" : "Text '20210115' could not be parsed at index 0"
}
}
},
"status" : 400
}
根据错误信息可知,错误的原因是写入的数据格式和定义的数据格式不同。此时需要写入的格式为yyyy-MM-dd HH:mm:ss的文档,请求的DSL如下:
POST /hotel/_doc/001
{ //写入数据
"title":"好再来酒店",
"city":"青岛",
"price":578.23,
"create_time":"2021-01-15 01:23:30" //写入符合自定义格式的日期数据
}
2.4 复杂的数据类型
1 数组类型
ES数组没有定义方式,其使用方式是开箱即用的,即无须事先声明,在写入时把数据用中括号[]括起来,由ES对该字段完成定义。当然,如果事先已经定义了字段类型,在写数据时以数组形式写入,ES也会将该类型转为数组。例如,为hotel索引增加一个标签字段,名称为tag,请求的DSL如下:
PUT /hotel/_mapping
{
"properties": {
"tag": { //增加tag字段,类型为keyword
"type": "keyword"
}
}
}
查看一下索引hotel的mapping:
{
"hotel" : {
"mappings" : {
"properties" : {
"city" : { //原有的city字段,类型为keyword
"type" : "keyword"
},
"price" : { //原有的price字段,类型为double
"type" : "double"
},
"tag" : { //增加tag字段,类型为keyword
"type" : "keyword"
},
"title" : { //原有的title字段,类型为text
"type" : "text"
}
}
}
}
}
通过返回的mapping信息来看,新增的tag字段与普通的keyword类型字段没什么区别,现在写入一条数据:
POST /hotel/_doc/001
{ //写入数据
"title":"好再来酒店",
"city":"青岛",
"price":578.23,
"tag":["有车位","免费WIFI"] //写入字符串数组数据
}
查看一下写入的数据,ES返回的信息如下:
{
…
"_source" : {
"title" : "好再来酒店",
"city" : "青岛",
"price" : 578.23,
"tag" : [ //tag字段自动转换为字符串数组类型
"有车位",
"免费WIFI"
]
}
}
通过以上信息可以看到,写入的数据的tag字段已经是数组类型了。那么,数组类型的数据如何搜索呢?
数组类型的字段适用于元素类型的搜索方式,也就是说,数组元素适用于什么搜索,数组字段就适用于什么搜索。例如,在上面的示例中,数组元素类型是keyword,该类型可以适用于term搜索,则tag字段也可以适用于term搜索,搜索的DSL如下:
GET /hotel/_search
{
"query": {
"term": { //使用term搜索数组类型的数据
"tag": {
"value": "有车位"
}
}
}
}
ES中的空数组可以作为missing field,即没有值的字段,下面的DSL将插入一条tag为空的数组:
POST /hotel/_doc/002
{
"title":"环球酒店",
"city":"青岛",
"price":530.00,
"tag":[] //写入空数组
}
2 对象类型
在实际业务中,一个文档需要包含其他内部对象。例如,在酒店搜索需求中,用户希望酒店信息中包含评论数据。评论数据分为好评数量和差评数量。为了支持这种业务,在ES中可以使用对象类型。和数组类型一样,对象类型也不用事先定义,在写入文档的时候ES会自动识别并转换为对象类型。
下面将在hotel索引中添加一条记录,请求的DSL如下:
POST /hotel/_doc/001
{ //写入数据
"title": "好再来酒店",
"city": "青岛",
"price": 578.23,
"comment_info": { //评论数据
"properties": {
"favourable_comment":199, //好评数据
"negative_comment": 68 //差评数据
}
}
}
执行以上DSL后,索引hotel增加了一个字段comment_info,它有两个属性,分别是favourable_comment和negative_comment,二者的类型都是long。下面查看mapping进行验证:
{
"hotel" : {
"mappings" : {
"properties" : {
"city" : {
"type" : "keyword"
},
"comment_info" : { //评论数据
"properties" : {
"properties" : {
"properties" : {
"favourable_comment" : { //好评数据,类型为long
"type" : "long"
},
"negative_comment" : { //差评数据,类型为long
"type" : "long"
}
}
}
}
},
"create_time" : {
"type" : "date",
"format" : "yyyy-MM-dd HH"
},
"price" : {
"type" : "double"
},
"title" : {
"type" : "text"
}
}
}
}
}
根据对象类型中的属性进行搜索,可以直接用“.”操作符进行指向。例如,搜索hotel索引中好评数大于200的文档,请求的DSL如下:
GET /hotel/_search
{
"query": {
"range": { //使用range搜索对象类型数据
"comment_info.properties.favourable_comment": {
"gte": 209
}
}
}
}
当然,对象内部还可以包含对象。例如,评论信息字段comment_info可以增加前3条好评数据,请求的DSL如下:
POST /hotel/_doc/001
{ //写入数据
"title": "好再来酒店",
"city": "青岛",
"price": 578.23,
"comment_info": {
"properties": {
"favourable_comment": 199,
"negative_comment": 68,
"top3_favourable_comment": { //新增字段
"top1": { //增加的第一条评论数据
"content": "干净整洁的一家酒店",
"score": 87
},
"top2": { //增加的第二条评论数据
"content": "服务周到,停车方便",
"score": 89
},
"top3": { //增加的第三条评论数据
"content": "闹中取静,环境优美",
"score": 90
}
}
}
}
}
以上请求,对文档的comment_info字段增加了前3条评论的内容和评分数据。
3 地理类型
在移动互联网时代,用户借助移动设备产生的消费也越来越多。例如,用户需要根据某个地理位置来搜索酒店,此时可以把酒店的经纬度数据设置为地理数据类型。该类型的定义需要在mapping中指定目标字段的数据类型为geo_point类型,示例如下:
PUT /hotel
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"city": {
"type": "keyword"
},
"price": {
"type": "double"
},
"create_time": {
"type": "date"
},
"location": { //定义字段location,类型为geo_point
"type": "geo_point"
}
}
}
}
其中,location字段定义为地理类型,现在向索引中写入一条酒店文档,DSL如下:
POST /hotel/_doc/001
{
"title": "文雅酒店",
"city": "北京",
"price": 556,
"create_time": "2021-01-15",
"location": { //写入geo_point类型数据,lat为纬度,lon为经度
"lat": 40.012134,
"lon": 116.497553
}
}
2.5 动态映射
当字段没有定义时,ES可以根据写入的数据自动定义该字段的类型,这种机制叫作动态映射。其实,在前面的章节中我们已经用到了ES的动态映射机制。在介绍数组类型和对象类型时提到,这两种类型都不需要用户提前定义,ES将根据写入的数据自动创建mapping中对应的字段并指定类型。对于基本类型,如果字段没有定义,ES在将数据存储到索引时会进行自动映射,如表3.1所示为自动映射时的JSON类型和索引数据类型的对应关系。

在一般情况下,如果使用基本类型数据,最好先把数据类型定义好,因为ES的动态映射生成的字段类型可能会与用户的预期有差别。例如,写入数据时,由于ES对于未定义的字段没有类型约束,如果同一字段的数据形式不同(有的是字符型,有的是数值型),则ES动态映射生成的字段类型和用户的预期可能会有偏差。提前定义好数据类型并将索引创建语句纳入SVN或Git管理范围是良好的编程习惯,同时还能增强项目代码的连贯性和可读性。
2.6 多字段
针对同一个字段,有时需要不同的数据类型,这通常表现在为了不同的目的以不同的方式索引相同的字段。例如,在订单搜索系统中,既希望能够按照用户姓名进行搜索,又希望按照姓氏进行排列,可以在mapping定义中将姓名字段先后定义为text类型和keyword类型,其中,keyword类型的字段叫作子字段,这样ES在建立索引时会将姓名字段建立两份索引,即text类型的索引和keyword类型的索引。订单搜索索引的定义如下:
PUT /hotel_order
{
"mappings": {
"properties": {
"order_id": { //定义order_id字段类型为keyword
"type": "keyword"
},
"user_id": { //定义user_id字段类型为keyword
"type": "keyword"
},
"user_name": { //定义user_name字段类型为text
"type": "text",
"fields": { //定义user_name多字段
//定义user_name字段的子字段user_name_keyword,并定义其类型为keyword
"user_name_keyword": {
"type": "keyword"
}
}
},
"hotel_id": { //定义hotel_id字段类型为keyword
"type": "keyword"
}
}
}
}
可以看出,正常定义user_name字段之后,使用fields定义其子字段的定义方式和普通字段的定义方式相同。
为方便演示,写入如下数据:
POST /_bulk
{"index":{"_index":"hotel_order","_id":"001"}}
{"order_id":"001","user_id":"user_00x","user_name":"Michael Jordan","hotel_id":"h001"}
{"index":{"_index":"hotel_order","_id":"002"}}
{"order_id":"002","user_id":"user_00a","user_name":"Stephen Jordan","hotel_id":"h0500"}
{"index":{"_index":"hotel_order","_id":"003"}}
{"order_id":"003","user_id":"user_30e","user_name":"Tim Jordan","hotel_id":"h0520"}
{"index":{"_index":"hotel_order","_id":"004"}}
{"order_id":"004","user_id":"user_430","user_name":"Kobe Jordan","hotel_id":"h0600"}
可以在普通搜索中使用user_name字段,DSL如下:
GET /hotel_order/_search
{
"query": {
"match": { //match搜索使用text类型的字段
"user_name": "Jordan"
}
},
"sort": { //排序使用子字段
"user_name.user_name_keyword": "asc"
}
}
搜索结果如下:
{
…
"hits" : {
…
"max_score" : null,
"hits" : [ //命中文档列表
{
…
"_id" : "004",
"_score" : null,
"_source" : {
…
"user_name" : "Kobe Jordan"
},
"sort" : [ //按照姓名全称排序
"Kobe Jordan"
]
},
{
"_index" : "hotel_order",
"_type" : "_doc",
"_id" : "001",
"_score" : null,
"_source" : {
…
"user_name" : "Michael Jordan"
},
"sort" : [ //按照姓名全称排序
"Michael Jordan"
]
},
{
"_index" : "hotel_order",
"_type" : "_doc",
"_id" : "002",
"_score" : null,
"_source" : {
…
"user_name" : "Stephen Jordan"
},
"sort" : [ //按照姓名全称排序
"Stephen Jordan"
]
},
…
]
}
}
根据以上结果可知,搜索Jordan之后,添加的4个文档都命中并且排序时是按照用户姓名的全称进行排序的。
3 文档操作
使用ES构建搜索引擎时需要经常对文档进行操作。除了简单的单条文档操作,有时还需要进行批量操作。本节将介绍文档的各种日常操作。此外,在生产环境中,对文档的批量操作一般需要借助编程语言来完成,因此在介绍DSL的同时本节还将演示Java客户端的使用。
3.1 单条写入文档
在ES中写入文档请求的类型是POST,其请求形式如下:
POST /${index_name}/_doc/${_id}
{ //写入的文档数据
…
}
上面的_id就是ES中的文档_id,这种请求方式是用户直接定义_id值,不使用ES生成的_id。请求的数据体即为写入的文档数据,格式是JSON形式。例如,在目标索引中写入下面数据:
POST /hotel/_doc/001
{ //写入的文档数据在URL中已经指定_id,因此在数据中需要指定_id
"title":"好再来酒店",
"city":"青岛",
"price":578.23
}
ES返回的结果如下:
{
"_index" : "hotel", //当前文档对应的索引
"_type" : "_doc",
"_id" : "001", //文档的_id
"_version" : 1,
"result" : "created",
"_shards" : { //写入影响的分片信息
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 9
}
由以上结果可知,向hotel索引中写入文档成功。另外,ES在返回结果中还会显示文档的版本,这里因为文档刚刚建立,所以当前值为1。
当然,用户也可以不指定文档_id,该_id值将由ES自动生成,其请求形式如下:
POST /${index_name}/_doc
{ //写入的文档数据
…
}
例如,写入上面的文档时不指定文档_id,请求的DSL如下:
POST /hotel/_doc
{ //写入的文档数据,url中不指定_id
"title":"好再来酒店",
"city":"青岛",
"price":578.23
}
在Java高级REST客户端中,单条写入文档需要创建IndexRequest对象并设置对应的索引和_id字段名称,执行时调用客户端的index()方法并把IndexRequest对象传入即可。index()方法返回IndexResponse对象,通过该对象可以获取当前请求的索引名称、文档_id和版本等。下面的代码演示了向索引中添加单条文档的方法。
public void singleIndexDoc(Map<String, Object> dataMap, String
indexName, String indexId) {
IndexRequest indexRequest = new IndexRequest(indexName).id(indexId).
source(dataMap); //构建IndexRequest对象并设置对应的索引和_id字段名称
try {
IndexResponse indexResponse = client.index(indexRequest,
RequestOptions.DEFAULT); //执行写入
//通过IndexResponse获取索引名称
String index = indexResponse.getIndex();
String id = indexResponse.getId();//通过IndexResponse获取文档ID
//通过IndexResponse获取文档版本
Long version = indexResponse.getVersion();
System.out.println("index=" + index + ",id=" + id + ",version="
+ version );
} catch (Exception e) {
e.printStackTrace();
}
}
3.2 批量写入文档
在ES中批量写入文档请求的类型是POST,其请求形式如下:
POST /_bulk //批量请求
{"index":{"_index":"${index_name}"}} //指定批量写入的索引
{…} //设定写入的文档内容
{"index":{"_index":"${index_name}"}}
{…} //设定写入的文档内容
请求体的第一行表示写入的第一条文档对应的元数据,其中,index_name表示写入的目标索引,第2行表示数据体,第3行表示写入的第二条文档对应的元数据,第4行表示数据体。以此类推,在一次请求里可以写入多条数据。下面将向hotel索引中批量写入两条酒店数据:
POST /_bulk //批量请求
{"index":{"_index":"hotel"}} //指定批量请求的索引,不指定文档_id
{"title": "文雅酒店","city": "北京","price": 556.00} //写入的数据
{"index":{"_index":"hotel"}} //指定批量请求的索引,不指定文档_id
{"title": "嘉怡假日酒店","city": "北京","price": 337.00} //写入的数据
上面的DSL写入索引中的文档_id是ES自动生成的。如果需要指定_id,则应该在元数据中添加_id。例如,下面的DSL将向酒店索引中添加文档_id为001和002两条文档:
POST /_bulk //批量请求
{"index":{"_index":"hotel","_id":"001"}} //指定批量请求的索引
{"title": "文雅酒店","city": "北京","price": 556.00} //写入的数据,指定文档_id
{"index":{"_index":"hotel","_id":"002"}} //指定批量请求的索引
//写入的数据,指定文档_id
{"title": "嘉怡假日酒店","city": "北京","price": 337.00}
在实际使用过程中需要批量写入的文档比较多,有时甚至上千条或者上万条,这时如果使用Kibana的请求页面就很不方便了。一般使用Linux系统中的curl命令进行数据的批量写入。curl命令支持上传文件,用户可以将批量写入的JSON数据保存到文件中,然后使用curl命令进行提交。
在ES单机环境下登录服务器,然后执行curl命令将上述两个文档批量写入hotel索引中:
curl -s –XPOST '127.0.0.1:9200/_bulk?preety' --data-binary "@bulk_doc.json"
其中,bulk_doc.json是文件名称,文件内容如下:
{"index":{"_index":"hotel","_id":"001"}} //指定批量请求的索引
{"title": "文雅酒店","city": "北京","price": 556.00} //写入的数据,指定文档_id
{"index":{"_index":"hotel","_id":"002"}} //指定批量请求的索引
//写入的数据,指定文档_id
{"title": "嘉怡假日酒店","city": "北京","price": 337.00}
在Java高级REST客户端中,批量写入文档需要创建BulkRequest对象并设置对应的索引名称。对于多条预写入的文档,可构建多个IndexRequest对象并调用BulkRequest.add()方法添加这些IndexRequest对象,执行时调用客户端的bulk()方法并把BulkRequest对象传入即可。bulk()方法返回BulkResponse对象,通过该对象可以获取当前请求的状态。以下代码演示了向索引中批量添加文档的方法:
public void bulkIndexDoc(String indexName, String docIdKey, List<Map<String, Object>> recordMapList) {
//构建批量操作BulkRequest对象
BulkRequest bulkRequest = new BulkRequest(indexName);
for (Map<String, Object> dataMap : recordMapList) { //遍历数据
//获取主键作为ES索引的主键
String docId = dataMap.get(docIdKey).toString();
IndexRequest indexRequest = new IndexRequest().id(docId).source(dataMap); //构建IndexRequest对象
bulkRequest.add(indexRequest); //添加IndexRequest
}
bulkRequest.timeout(TimeValue.timeValueSeconds(5)); //设置超时时间
try {
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT); //执行批量写入
if (bulkResponse.hasFailures()) { //判断执行状态
System.out.println("bulk fail,message:" + bulkResponse.buildFailureMessage());
}
} catch (IOException e) {
e.printStackTrace();
}
}
@GetMapping("/bulkIndex")
public void bulkIndex() {
String indexName = "hotel_oder_1";
String docIdKey = "id";
List<Map<String, Object>> list = Lists.newArrayList();
Map<String, Object> r_map = Maps.newHashMap();
r_map.put("id", "001");
r_map.put("title", "如家酒店");
r_map.put("price", 10000);
r_map.put("address", "济南");
list.add(r_map);
Map<String, Object> bj_map = Maps.newHashMap();
bj_map.put("id", "002");
bj_map.put("title", "如家酒店");
bj_map.put("price", 10000);
bj_map.put("address", "北京");
list.add(bj_map);
esService.bulkIndexDoc(indexName, docIdKey, list);
}
3.3 更新单条文档
在ES中更新索引的请求类型是POST,其请求形式如下:
POST /${index_name}/_update/${_id}
{ //需要更新的数据,在URL中指定文档_id
…
}
上面的_id就是将要修改的ES文档中的_id,修改后的字段和值将会填写到大括号中,其格式是JSON形式。例如把_id为001的文档修改成下面的数据:
POST /hotel/_update/001
{//需要更新的数据,在url中指定文档_id
"doc": { //更新后的数据
"title": "好再来酒店",
"city": "北京",
"price": 659.45
}
}
执行上述命令后,ES返回的结果如下:
{
"_index" : "hotel", //更新的索引名称
"_type" : "_doc",
"_id" : "001", //更新的文档_id
"_version" : 2,
"result" : "updated", //更新成功信息
"_shards" : { //更新影响的分片信息
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 9
}
通过结果可知,已经成功更新文档信息,并且本次修改后文档的版本变为2。下面根据_id搜索文档的命令进行验证:
GET /hotel/_doc/001
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 9,
"found" : true,
"_source" : {
"title" : "好再来酒店",
"city" : "北京",
"price" : 659.45
}
}
通过返回的结果可知,文档001的对应字段已经被修改成目标数据,并且文档的版本已经更新为2。
在Java高级REST客户端中,更新单条文档需要创建UpdateRequest对象并设置对应的索引和_id字段名称,执行时,调用客户端的update()方法并把UpdateRequest对象传入即可。index()方法返回UpdateResponse对象,通过该对象可以获取当前请求的索引名称、文档_id和版本等。以下代码演示了向索引中添加单条文档的方法:
public void singleUpdate(String indexName, String docIdKey, Map<String,
Object> recordMap) {
UpdateRequest updateRequest = new UpdateRequest(indexName, docIdKey);
updateRequest.doc(recordMap);
try {
UpdateResponse updateResponse=client.update(updateRequest,
RequestOptions.DEFAULT);
//通过IndexResponse获取索引名称
String index = updateResponse.getIndex();
//通过IndexResponse获取文档ID
String id = updateResponse.getId();
//通过IndexResponse获取文档版本
Long version = updateResponse.getVersion();
System.out.println("index=" + index + ",id=" + id + ",version="
+version);
} catch (IOException e) {
e.printStackTrace();
}
}
@GetMapping("/singleUpdate")
public void singleUpdate() {
String indexName = "hotel_oder_1";
String docIdKey = "001";
Map<String, Object> recordMap = Maps.newHashMap();
recordMap.put("title", "_如家酒店");
esService.singleUpdate(indexName, docIdKey, recordMap);
}
除了普通的update功能,ES还提供了upsert。upsert即是update和insert的合体字,表示更新/插入数据。如果目标文档存在,则执行更新逻辑;否则执行插入逻辑。以下DSL演示了upsert的应用:
POST /hotel/_update/001
{
"doc": {
"title": "好再来酒店",
"city": "北京",
"price": 659.45
},
"upsert": {
"title": "好再来酒店",
"city": "北京",
"price": 659.45
}
}
执行以上DSL后,如果文档001存在,则执行更新逻辑,将doc内容更新到文档中;否则执行插入逻辑,将upsert的内容写入文档中。
编写Java代码时执行upsert的逻辑和update相似,不同的是构建完成后需调用UpdateRequest.upsert()将插入的对象传入。下面的代码演示了使用upsert向索引中更新/插入数据的方法。
public void singleUpsert(String index, String docIdKey, Map<String,
Object> recordMap,Map<String, Object> upRecordMap) {
//构建UpdateRequest
UpdateRequest updateRequest = new UpdateRequest(index, docIdKey);
updateRequest.doc(recordMap); //设置更新逻辑
updateRequest.upsert(upRecordMap); //设置插入逻辑
try {
//执行upsert命令
client.update(updateRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
}
3.4 批量更新文档
与批量写入文档相似,批量更新文档的请求形式如下:
POST /_bulk //批量请求
//指定批量更新的索引和文档_id
{"update":{"_index":"${index_name}","_id":"${_id}"}}
{"doc":{ …}#JSON数据} //设定更新的文档内容
//指定批量更新的索引和文档_id
{"update":{"_index":"${index_name}","_id":"${_id}"}}
{"doc":{ …}#JSON数据} //设定更新的文档内容
注意,与批量写入文档不同的是,批量更新文档必须在元数据中填写需要更新的文档_id。下面的DSL将批量更新_id为001和002的文档:
POST /_bulk //批量请求
//指定批量更新的索引和文档_id
{"update":{"_index":"hotel","_id":"001"}}
//设定更新的文档内容
{"doc":{"title": "文雅豪情酒店","city": "北京","price": 556.00}}
{"update":{"_index":"hotel","_id":"002"}} //指定批量更新的索引和文档_id
//设定更新的文档内容
{"doc":{"title": "嘉怡七天酒店","city": "北京","price": 337.00}}
在Java客户端接口中,批量更新文档需要创建BulkRequest对象并设置对应的索引名称。对于多条需要更新的文档,可构建多个UpdateRequest对象并调用BulkRequest.add()方法添加这些UpdateRequest对象,执行时,调用客户端的bulk()方法并把BulkRequest对象传入即可。以下代码演示了向索引中批量更新文档的方法:
public void bulkUpdate(String index, String docIdKey, List<Map<String,
Object>> recordMapList) {
BulkRequest bulkRequest = new BulkRequest();//构建BulkRequest对象
for (Map<String, Object> dataMap : recordMapList) {//遍历数据列表
String docId = dataMap.get(docIdKey).toString();
dataMap.remove(docId); //将ID字段从map中删除
//创建UpdateRequest对象
bulkRequest.add(new UpdateRequest(index, docId).doc(dataMap));
}
try {
BulkResponse bulkResponse = client.bulk(bulkRequest, Request
Options.DEFAULT); //执行批量更新
if (bulkResponse.hasFailures()) { //判断状态
System.out.println("bulk fail,message:" + bulkResponse.
buildFailureMessage());
}
} catch (Exception e) {
e.printStackTrace();
}
}
@GetMapping("/bulkUpdate")
public void bulkUpdate() {
String indexName = "hotel_order";
String docIdKey = "id";
List<Map<String, Object>> recordMapList = Lists.newArrayList();
Map<String, Object> r_recordMap = Maps.newHashMap();
r_recordMap.put("user_name", "_如家酒店");
r_recordMap.put("id", "001");
Map<String, Object> bj_recordMap = Maps.newHashMap();
bj_recordMap.put("user_name", "__如家酒店");
bj_recordMap.put("id", "002");
recordMapList.add(r_recordMap);
recordMapList.add(bj_recordMap);
esService.bulkUpdate(indexName, docIdKey, recordMapList);
}
3.5 根据条件更新文档
在索引数据的更新操作中,有些场景需要根据某些条件同时更新多条数据,类似于在RDBMS中使用update table table_name set…where…更新一批数据。为了满足这样的需求,ES为用户提供了_update_by_query功能,其请求形式如下:
POST /${index_name}/_update_by_query
{
"query": { //条件更新的查询条件
…
},
"script": { //条件更新的具体更新脚本代码
…
}
}
上面的query用于指定更新数据的匹配条件,相当于SQL中的where语句;script用于指定具体的更新操作,相当于SQL的set内容。script的知识点将在后面的章节中进行介绍,这里仅简单应用一下,请求的DSL如下:
POST /hotel/_update_by_query
{
"query": { //更新文档的查询条件:城市为北京的文档
"term": {
"city": {
"value": "北京"
}
}
},
"script": { //条件更新的更新脚本,将城市改为“上海”
"source": "ctx._source['city']='上海'",
"lang": "painless"
}
}
执行以上DSL后,ES将先搜索城市为“北京”的酒店,然后把这些酒店的城市字段的值改为“上海”。
在Java高级REST客户端中,执行根据条件更新文档,需要创建UpdateByQueryRequest对象并设置对应的索引名称,类似于DSL中的query子句,通过调用UpdateByQuery Request.setQuery()方法设置查询逻辑,script子句通过调用UpdateByQueryRequest.setScript()方法设置更新逻辑,然后执行客户端的updateByQuery()方法并把UpdateByQueryRequest对象传入即可。以下代码演示了根据城市字段查找文档然后更新城市字段的方法:
public void updateCityByQuery(String index,String oldCity,String
newCity) {
UpdateByQueryRequest updateByQueryRequest=new UpdateByQueryRequest
(index); //构建UpdateByQueryRequest对象
//设置按照城市查找文档的query
updateByQueryRequest.setQuery(new TermQueryBuilder("city",oldCity));
updateByQueryRequest.setScript(new Script("ctx._source['city']=
'"+newCity+"';")); //设置更新城市字段的脚本逻辑
try {
client.updateByQuery(updateByQueryRequest,RequestOptions.
DEFAULT); //执行更新
} catch (IOException e) {
e.printStackTrace();
}
}
@GetMapping("/updateHotelByQuery")
public void updateHotelByQuery() {
String indexName = "hotel_order";
esService.updateHotelByQuery(indexName, "001", "_BJ如家酒店");
}
如果更新所有文档中的某个字段应该如何操作呢?其实,_update_by_query中的query子句可以不定义,这种情况下ES会选中所有的文档执行script中的内容。以下为修改所有酒店中城市为“上海”的DSL:
POST /hotel/_update_by_query
{
"script": { //更新所有文档中的城市为“上海”
"source": "ctx._source['city']='上海'",
"lang": "painless"
}
}
3.6删除单条文档
在ES中删除文档的请求的类型是DELETE,其请求形式如下:
DELETE /${index_name}/_doc/${_id}
上面的_id就是将要删除的ES文档的_id。执行下面的删除命令:
DELETE /hotel/_doc/001
返回的结果如下:
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001", //删除的文档_id
"_version" : 1,
"result" : "deleted", //删除成功
"_shards" : { //删除请求影响的分片信息
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 9
}
在Java高级REST客户端中,执行删除文档需要创建DeleteRequest对象并设置对应的索引名称与删除文档的_id,然后执行客户端的delete()方法并把DeleteRequest对象传入即可。以下代码演示了根据_id删除文档的方法:
public void singleDelete(String index, String docId) {
//构建删除请求
DeleteRequest deleteRequest=new DeleteRequest(index,docId);
try {
client.delete(deleteRequest, RequestOptions.DEFAULT);//执行删除
} catch (IOException e) {
e.printStackTrace();
}
}
3.7 批量删除文档
与批量写入和更新文档不同的是,批量删除文档不需要提供JSON数据,其请求形式如下:
POST /_bulk
//批量删除文档,指定文档_id
{"delete":{"_index":"${index_name}","_id":"${_id}"}}
//批量删除文档,指定文档_id
{"update":{"_index":"${index_name}","_id":"${_id}"}}
例如,下面的DSL将批量删除_id为001和002的文档:
POST /_bulk
{"delete":{"_index":"hotel","_id":"001"}} //批量删除文档,指定文档_id为“001”
{" delete ":{"_index":"hotel","_id":"002"}} //批量删除文档,指定文档_id为“002”
和批量写入文档相似,在Java客户端接口中,批量删除文档需要创建BulkRequest对象并设置对应的索引名称。对于多条需要删除的文档,可构建多个DeleteRequest对象并调用BulkRequest.add()方法添加这些DeleteRequest对象,执行时,调用客户端的bulk()方法并把BulkRequest对象传入即可。示例如下:
public void bulkDelete(String index, String docIdKey, List<String>
docIdList) {
BulkRequest bulkRequest = new BulkRequest(); //构建BulkRequest对象
for (String docId : docIdList) { //遍历文档_id列表
//构建删除请求
DeleteRequest deleteRequest=new DeleteRequest(index,docId);
bulkRequest.add(deleteRequest); //创建UpdateRequest对象
}
try {
BulkResponse bulkResponse = client.bulk(bulkRequest,RequestOptions.
DEFAULT); //执行批量删除
if (bulkResponse.hasFailures()) { //判断状态
System.out.println("bulk fail,message:" + bulkResponse.build
FailureMessage());
}
} catch (Exception e) {
e.printStackTrace();
}
}
3.8 根据条件删除文档
和条件更新操作类似,有些场景需要根据某些条件同时删除多条数据,类似于在RDBMS中使用delete table_name where…删除一批数据。为了满足这样的需求,ES为用户提供了_delete_by_query功能,其请求形式如下:
POST /${index_name}/_delete_by_query
{ //删除文档的查询条件
"query": {
…
}
}
query子句用于指定删除数据的匹配条件,相当于SQL中的where语句。下面的DSL将把city为北京的文档删除
POST /hotel/_delete_by_query
{
"query": { //条件删除文档的查询条件:城市为“北京”的文档
"term": {
"city": {
"value": "北京"
}
}
}
}
在Java高级REST客户端中,执行条件删除文档需要创建DeleteByQueryRequest对象并设置对应的索引名称类似于DSL中的query子句,通过调用DeleteByQueryRequest.setQuery()方法设置查询逻辑,然后执行客户端的deleteByQuery()方法并把DeleteByQueryRequest对象传入即可。以下代码演示了根据城市删除文档的方法:
public void deleteByQuery(String index,String city) {
//构建DeleteByQueryRequest对象
DeleteByQueryRequest deleteByQueryRequest=new DeleteByQueryRequest(index);
//设置按照城市查找文档的query
deleteByQueryRequest.setQuery(new TermQueryBuilder("city",city));
try {
//执行删除命令
client.deleteByQuery(deleteByQueryRequest,RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
}