文章目录
- 一、VIF公式和原理
- 对于R方
- 一般回归模型
- 皮尔逊相关系数中的方差
VIF原理:
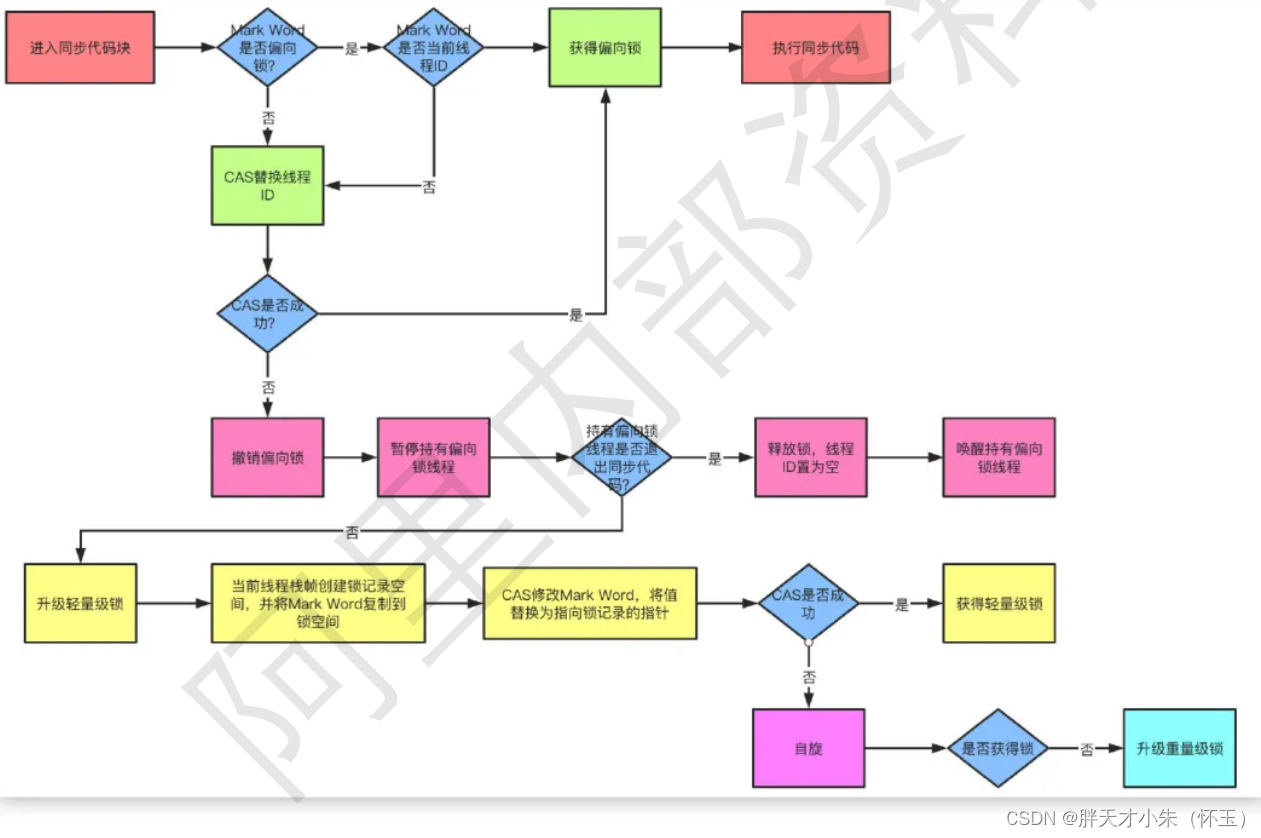
一、VIF公式和原理
所谓VIF方法,计算难度并不高。在线性回归方法里,应用最广泛的就是最小二乘法(OLS),只不过我们对每个因子,用其他N个因子进行回归解释。(n+1自变量)
其中有一个检验模型解释能力的检验统计指标为R2(样本可决系数),R2的大小决定了解释变量对因变量的解释能力。而为了检验因子之间的线性相关关系,我们可以通过OLS对单一因子和解释因子进行回归,然后如果其R^2较小,说明此因子被其他因子解释程度较低,线性相关程度较低。
注:之所以不使用协方差计算相关性是由于协方差难以应用在多元线性相关情况下。给出VIF计算方法:
V
I
F
=
1
/
(
1
−
R
2
)
VIF = 1/{}(1-R^2)
VIF=1/(1−R2)
(实际-平均/估计-实际) 10 5
从上文很容易看出,VIF越高解释变量和因变量之间线性相关性就越强。
(应该是一个偏离的程度)
R方的解释
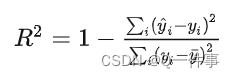
对应上面(10、5)的是,9/10(n变量越能解释1个变量) 4/5(n越大越)----(其他的变量能解释这个变量的90%)
估计-实际/实际-平均
参考:使用方差膨胀因子(Variance Inflation Factor)来特征选择
[1] VIF方法(方差膨胀因子)因子独立性检验 全流程解读
[2] vif: Variance Inflation Factors
[3]Computing Variance Inflation Factor VIF in R Studio
对于R方
一般回归模型
R方是统计学里常用的统计量,在不同任务模型下的解读和用途不一,有时候会出现误用情况。本文总结了对R方的理解和用法,遵循“从一般到特殊”的思路,先讲一般回归模型中的R方,再讲线性回归模型里的R方。"一般"回归模型包括线性模型,随机森林,神经网络等。
- R方的定义
R方的名字是coefficient of determination,另一个名字是Nash–Sutcliffe model efficiency coefficient。给定一系列真值 yi 和对应的预测值y^i,R方的定义为
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CSnx5f5I-1676030637238)(assets/image-20221201205758230.png)]](https://img-blog.csdnimg.cn/51ee490ba69e46ba87eb6a7771d174ee.png)
R方的含义是,预测值解释了 yi 变量的方差的多大比例,衡量的是预测值对于真值的拟合好坏程度。通俗理解,假定 yi 的方差为1个单位,则R方表示"使用该模型之后, yi 的残差的方差减少了多少"。比如R方等于0.8,则使用该模型之后残差的方差为原始 yi 值方差的20%。
- R方=1:最理想情况,所有的预测值等于真值。
- R方=0:一种可能情况是"简单预测所有y值等于y平均值",即所有 y^i 都等于y¯(即真实y值的平均数),但也有其他可能。
- R方<0:模型预测能力差,比"简单预测所有y值等于y平均值"的效果还差。这表示可能用了错误模型,或者模型假设不合理。
- R方的最小值没有下限,因为预测可以任意程度的差。因此,R方的范围是 (−∞,1] 。
- 注意:R方并不是某个数的平方,因此可以是负值。
参考文献:https://zhuanlan.zhihu.com/p/143132259
皮尔逊相关系数中的方差
对于不固定截距的简单线性模型(y = mx + b), R方等于x和y的pearson correlation coefficient的平方。因此,此处的R方范围是[0,1]。R方等于0,表示x和y的散点图完全随机,没有线性关系(或者说,线性相关关系等于0)。R方等于1,表示所有(x,y)散点落在一条直线上。
(ArcGIS Pro How Band Collection Statistics works)
The covariance matrix contains values of variances and covariances. The variance is a statistical measure showing how much variance there is from the mean. To calculate these variances, the squares of the differences between each cell value and the mean value of all cells are averaged. The variances for every layer can be read along the diagonal of the covariance matrix moving from the upper left to the lower right. The variances are expressed in cell-value units squared.
The remaining entries within the covariance matrix are the covariances between all pairs of input rasters. The following formula is used to determine the covariance between layers i and j:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jqG771li-1676030637239)(F:\BaiduSyncdisk\西安生态修复论文\221011分区\assets\GUID-F94265F1-70FD-4FF8-A7AE-9B87BC4EA47D-web.gif)]](https://img-blog.csdnimg.cn/3464e649521341d387456e632c3df602.png)
-
where:
Z - value of a cell
i, j - are layers of a stack
µ - is the mean of a layer
N - is the number of cells
k - denotes a particular cell
The covariance of two layers is the intersection of the appropriate row and column. The covariance between layers 2 and 3 is the same as the covariance between layers 3 and 2. The values of the covariance matrix are dependent on the value units, while the values of the correlation matrix are not.
The correlation matrix shows the values of the correlation coefficients that depict the relationship between two datasets. In the case of a set of raster layers, the correlation matrix presents the cell values from one raster layer as they relate to the cell values of another layer. The correlation between two layers is a measure of dependency between the layers. It is the ratio of the covariance between the two layers divided by the product of their standard deviations. Because it is a ratio, it is a unitless number. The equation to calculate the correlation is as follows:
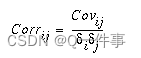
Correlation ranges from +1 to -1. A positive correlation indicates a direct relationship between two layers, such as when the cell values of one layer increase, the cell values of another layer are also likely to increase. A negative correlation means that one variable changes inversely to the other. A correlation of zero means that two layers are independent of one another.
The correlation matrix is symmetrical. Its diagonal from the upper left to lower right is 1.0000 since the correlation coefficient of identical layers is +1.(参考文献:)
这里的R方
R 平方,也称为决定系数,是一种统计量度,表示可从自变量预测的因变量方差的比例。 它是一个介于 0 到 1 之间的数字,用于评估回归模型的拟合优度。 在 Pearson 系数的背景下,R 平方提供了对两个变量之间线性关系强度的估计。
值为 0 表示模型没有解释因变量的任何变化,值为 1 表示模型完美地解释了因变量的变化。 R 平方的中间值表示因变量中由自变量解释的方差的比例。
总之,Pearson 系数的 R 平方值提供了有关回归模型对数据的拟合程度以及变量之间线性关系强度的信息。
参考文献:https://zhuanlan.zhihu.com/p/143132259
总之,Pearson 系数的 R 平方值提供了有关回归模型对数据的拟合程度以及变量之间线性关系强度的信息。
参考文献:https://zhuanlan.zhihu.com/p/143132259