文章目录
- 一、Java集合框架
- 二、Java集合特性
- 三、各集合类的使用
- ArrayList
- LinkedList
- HashSet
- HashSet源码解析
- 对源码进行总结
- HashSet可同步
- HashSet的使用
- HashMap
- 四、Iterator迭代器
- 五、遍历集合元素的若干方式
参考文章:Hash详解
参考文章:深入浅出学Java——HashMap
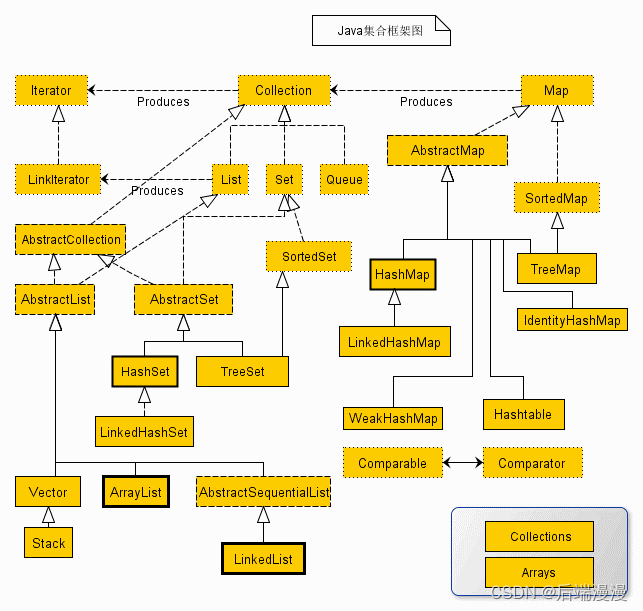
一、Java集合框架
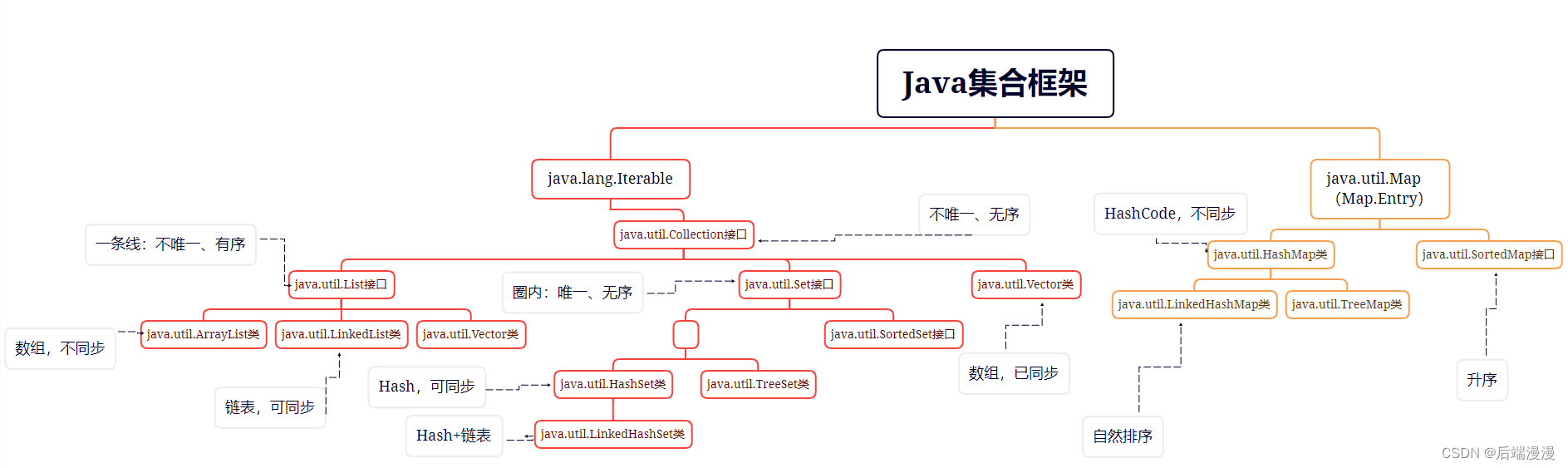
二、Java集合特性
三、各集合类的使用
ArrayList
ArrayList 中的元素实际上是对象,在以上实例中,数组列表元素都是字符串 String 类型。
如果我们要存储其他类型,而 只能为引用数据类型,这时我们就需要使用到基本类型的包装类。
ArrayList<Integer> sites=new Arraylist<>(); // 存放整数元素
ArrayList<Character> sites=new Arraylist<>(); // 存放字符元素
相关方法
//添加元素
sites.add("Google");
//获取第一个元素
sites.get(0);
//设置元素
sites.set(2,"Wiki");
//删除第四个元素
sites.remove(3);
//计算元素数量
sites.size();
//字母排序
Collections.sort(sites);
LinkedList
创建LinkedList
LinkedList<String> sites = new LinkedList<String>();
相关方法
//方式一:输出LinkedList
System.out.println(sites);
//方式二:输出LinkedList
for (int i = 0; i < sites.size(); i++)
System.out.println(sites.get(i));
//方式三:输出LinkedList
for (String i : sites)
System.out.println(i);
//添加元素
sites.add("Google");
//在头部操作元素
sites.addFirst("Wiki");
sites.removeFirst();
sites.getFirst();
//在尾部操作元素
sites.addLast("Wiki");
sites.removeLast();
sites.getLast()
HashSet
HashSet源码解析
package java.util;
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable,java.io.Serializable
{
/*
HashSet是通过map(HashMap对象)保存内容的,
因为HashMap是key-value键值对,而HashSet中只需要用到key,
所以向map中添加键值对时,键值对的值固定是PRESENT
*/
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<E,Object>(); // 调用HashMap的默认构造函数,创建map
}
public HashSet(Collection<? extends E> c) {
/*
HashMap的加载因子是0.75。当HashMap的“阈值”(阈值=HashMap总的大小*加载因子) <
“HashMap实际大小”时, 就需要将HashMap的容量翻倍。c.size()/0.75f + 1 来表示初始
化的值,这样使我们期望的大小值正好比扩容的阀值大1,就不会扩容。
HashMap的总的大小,必须是2的指数倍,这里指定为16是从性能考虑。
*/
map = new HashMap<E,Object>(Math.max ((int) (c.size()/0.75f)+1, 16) );
addAll(c); // 将集合(c)中的全部元素添加到HashSet中
}
// 指定HashSet初始容量和加载因子的构造函数
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
// 指定HashSet初始容量的构造函数
public HashSet(int initialCapacity) {
map = new HashMap<E,Object>(initialCapacity);
}
// 指定HashSet初始容量和加载因子的构造函数,dummy没有任何作用
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
}
// 返回HashSet的迭代器,实际上返回的是HashMap的“key集合的迭代器”
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}
// java.io.Serializable的写入函数
// 将HashSet的“总的容量,加载因子,实际容量,所有的元素”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException
{
s.defaultWriteObject(); // Write out any hidden serialization magic
s.writeInt(map.capacity()); // Write out HashMap capacity and load factor
s.writeFloat(map.loadFactor());
s.writeInt(map.size()); // Write out size
// Write out all elements in the proper order.
for (Iterator i=map.keySet().iterator(); i.hasNext(); )
s.writeObject(i.next());
}
// java.io.Serializable的读取函数
// 将HashSet的“总的容量,加载因子,实际容量,所有的元素”依次读出
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException
{
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in HashMap capacity and load factor and create backing HashMap
int capacity = s.readInt();
float loadFactor = s.readFloat();
map = (((HashSet)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i=; i<size; i++) {
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
}
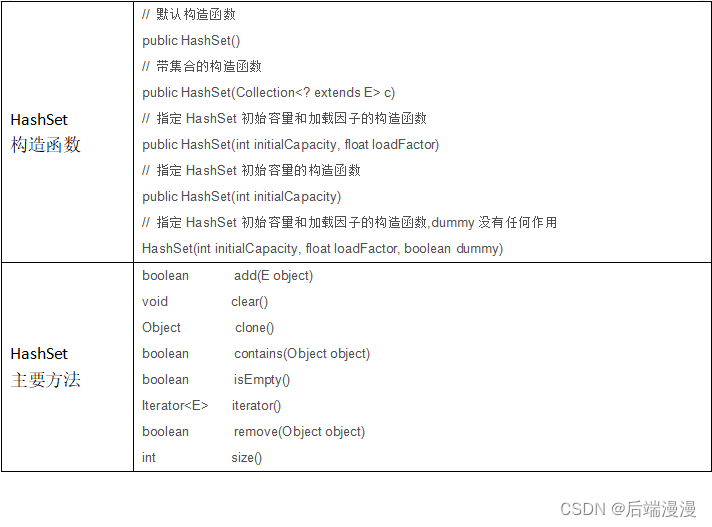
对源码进行总结
HashSet可同步
Set s = Collections.synchronizedSet(new HashSet(...));
HashSet的使用
//添加元素
set.add("a");
//计算元素个数
set.size();
//判断是否存在元素
set.contains("a");
//删除元素
set.remove("a");
//克隆一个newSet,跟set内容一模一样
HashSet newset = (HashSet)set.clone();
//“删除set中,属于newset的元素”,等于清空元素
set.removeAll(newset);
//“保留set中,属于newset的元素”,等于保留全部
set.retainAll(newset);
//判空
set.isEmpty();
HashMap
后续将链接放到这里
四、Iterator迭代器
输出第一个元素
import java.util.ArrayList;
import java.util.Iterator;
public class RunoobTest {
public static void main(String[] args) {
// 创建集合
ArrayList<String> sites = new ArrayList<String>();
sites.add("Google");
sites.add("Runoob");
sites.add("Taobao");
sites.add("Zhihu");
// 获取迭代器
Iterator<String> it = sites.iterator();
// 输出集合中的第一个元素
System.out.println(it.next());
}
}
循环集合元素
import java.util.ArrayList;
import java.util.Iterator;
public class RunoobTest {
public static void main(String[] args) {
// 创建集合
ArrayList<String> sites = new ArrayList<String>();
sites.add("Google");
sites.add("Runoob");
sites.add("Taobao");
sites.add("Zhihu");
// 获取迭代器
Iterator<String> it = sites.iterator();
// 输出集合中的所有元素
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
五、遍历集合元素的若干方式
//方式一
System.out.println(sites);
//方式二
for (int i = 0; i < sites.size(); i++)
System.out.println(sites.get(i));
//方式三
for (String i : sites)
System.out.println(i);
//方式四
Iterator<String> it = sites.iterator();
while(it.hasNext())
System.out.println(it.next());