目录
五、孤儿进程
六、进程优先级
6.1、基本概念
6.2、查看时实系统进程
6.3、PRI and NI
七、其他概念
四、X 状态:死亡状态
所谓进程处于 X 状态(死亡状态)代表的就是该进程已经死亡了,即操作系统可以随时回收它的资源(操作系统也可以立马回收其资源,一般情况下就是立马回收其资源,因为操作系统的运行速度很快),所谓回收其资源指的就是操作系统将该进程对应在内存中的可执行程序(代码和数据)释放掉,其次再把描述该进程所创建的进程控制块也释放掉、
死亡状态指的就是从该进程死亡开始(死亡指的就是该进程的退出信息被读取完毕后)直到该进程的资源被操作系统回收完毕为止,这一时间段该进程所处的状态,当该进程的资源被操作系统回收完毕后,该进程就不再存在了,由于操作系统的运行速度非常快,所以导致死亡状态存在的时间会非常短,因此当我们查看时实进程时,若该进程已经死亡了,一般情况下就看不到该进程的实时信息了,更看不到该进程对应的死亡状态了、
当某一个进程的退出信息被读取完毕后,该进程会由僵尸状态进入死亡状态,此时,操作系统可以随时回收该进程的资源,当操作系统回收完毕该进程的资源后,该进程也就不存在了、
五、Z 状态:僵尸状态
该状态是 Linux 操作系统下特有的进程状态,当 Linux 操作系统中的某一个进程退出(结束)时,该进程一般情况下不会直接进入 X 状态(死亡状态),而是先进入 Z 状态(僵尸状态),然后再进入 X 状态(死亡状态),这是为什么呢?
因为创建某一个进程的目的就是为了让其执行一些任务,所以当该进程退出(结束)时,我们必须要知道该进程的退出信息(包括该进程所执行的任务的完成情况),则一般需要将该进程的退出信息(包括该进程所执行的任务的完成情况)告诉其对应的父进程或者是直接告诉给操作系统(有时告诉给其对应的父进程,有时会直接告诉操作系统,若某一个进程的退出信息需要直接告诉给操作系统的话,我们不需要手动去使得操作系统读取该进程的退出信息,因为操作系统会自动读取,若某一个进程的退出信息需要告诉给其原始父进程,并且该进程的原始父进程是 bash 进程的话,我们也不需要手动的去使得 bash 进程读取该进程的退出信息,因为 bash 进程也会自动读取其子进程的退出信息,若某一个进程的退出信息需要告诉给其原始父进程的话,并且该进程的原始父进程不是 bash 进程的话,此时我们必须要通过手动的使得该进程的原始父进程读取该进程的退出信息)以此来做第二次决策、
注意:当某一个进程退出(结束)时,如果该进程的父进程还在运行,那么该子进程的退出信息是会被该子进程的父进程读取的,若当某一个进程退出(结束)时,该进程的父进程已经提前退出(结束)了,那么该子进程的退出信息是会被 PID 为1的进程(就是操作系统)读取的,还可以理解为,当某一个进程结束(退出)时,该进程一定会有与其对应的父进程,这是因为当该进程的原始父进程提前退出(结束)时,操作系统(PID为1的进程)会临时充当该子进程的父进程,所以可以理解为,当该子进程退出(结束)时,该子进程的退出信息一定会被他的父进程读取(此处所谓的父进程可能是该子进程的原始父进程,也可能是新的父进程)、
因此,Z 状态(僵尸状态)存在的原因就是为了让父进程或者是操作系统通过进程等待来读取某一个进程(该进程处于Z状态)的退出信息(包括该进程执行任务的结果),在该状态下,该进程对应在内存中的可执行程序(代码和数据)可以被释放掉了,但是描述该进程所创建的进程控制块不能被释放,这是因为进程的退出信息(包括该进程执行任务的结果)是保存在描述该进程所创建的进程控制块(在 Linux 操作系统中指的就是 task_struct 结构体)中的、
进程退出(结束)的情况有哪些?怎么退出(结束)进程?,在后期讲解进程控制时再进行具体的阐述、
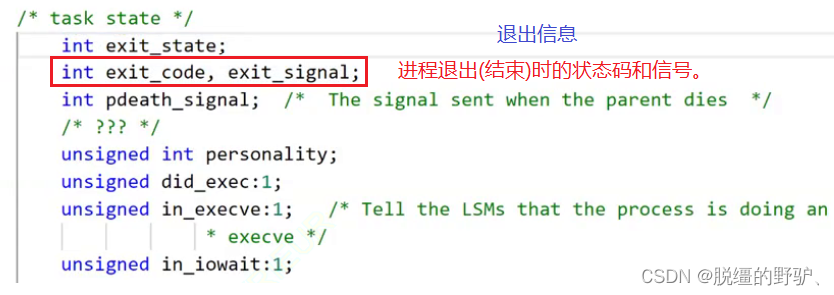
注意:main 函数的返回值本质上就是上图中所示的状态码,该返回值就会被返回到描述该进程所创建的进程控制块中的 exit_code 中、
进程退出(结束)的情况有哪些,如何退出(结束)进程,这些问题会在后期的进程控制中进行具体阐述,其次,操作系统能够读取某一个进程的退出信息,因为描述进程所创建的进程控制块都是由操作系统创建的,所以操作系统一定能够读取某一个进程的退出信息,所以当某一个进程的退出信息(包括该进程执行任务的结果)直接告诉给操作系统的话,操作系统会自动的读取该进程的退出信息,不需要我们手动的去操作,但是,如果某一个进程的退出信息(包括该进程执行任务的结果)是需要告诉给其原始父进程(该原始父进程不是 bash 进程)的话,那么该原始父进程是如何读取子进程的退出信息的呢,包括原始父进程如何将子进程的状态由 Z 状态变为 X 状态的问题,也会在后面的进程控制里的进程等待中再进行具体阐述、
总结:当进程退出(结束)时,一般情况下会先进入 Z 状态(僵尸状态),在此状态下,该进程的资源不会被操作系统回收(由于描述该进程所创建的进程控制块未被释放,所以不能说该进程的资源被操作系统回收),当进程从 Z 状态(僵尸状态)变为 X 状态(死亡状态)后,该进程的资源随时(一般指立马)能够被操作系统回收、
如何模拟僵尸进程?
通过 Linux 操作系统所提供的系统调用接口 fork 直接创建出来的某一个进程的子进程,该子进程退出(结束)了,但是其父进程不退出(结束),所以该子进程的退出信息需要由该子进程的原始父进程读取,而该原始父进程又不是 bash 进程,所以需要我们手动的使得该原始父进程来读取其子进程的退出信息,具体方法在后期进行阐述,否则该子进程就会变成僵尸进程,由下述可知,在该例子中,该子进程的退出信息是由该子进程的父进程(原始父进程,并且不是 bash 进程)进程读取的、
[HJM@hjmlcc ~]$ man 3 exit
EXIT(3) Linux Programmer's Manual EXIT(3)
NAME
exit - cause normal process termination
SYNOPSIS
#include <stdlib.h>
void exit(int status);
DESCRIPTION
The exit() function causes normal process termination and the value of status & 0377 is returned to the parent (see
wait(2)).
All functions registered with atexit(3) and on_exit(3) are called, in the reverse order of their registration. (It is
possible for one of these functions to use atexit(3) or on_exit(3) to register an additional function to be executed
during exit processing; the new registration is added to the front of the list of functions that remain to be called.)
If one of these functions does not return (e.g., it calls _exit(2), or kills itself with a signal), then none of the
remaining functions is called, and further exit processing (in particular, flushing of stdio(3) streams) is abandoned.
If a function has been registered multiple times using atexit(3) or on_exit(3), then it is called as many times as it
was registered.
All open stdio(3) streams are flushed and closed. Files created by tmpfile(3) are removed.
The C standard specifies two constants, EXIT_SUCCESS and EXIT_FAILURE, that may be passed to exit() to indicate suc‐
cessful or unsuccessful termination, respectively.
RETURN VALUE
The exit() function does not return.
Manual page exit(3) line 1 (press h for help or q to quit)q通过以下监控脚本,每隔一秒对进程的信息进行时实检测、
while :; do ps ajx | head -1 && ps ajx | grep process | grep -v grep; sleep 1; echo "—————————————————————————————————————————————————————————————————"; done//新建会话0:
[LCC@hjmlcc ~]$ ls
a.out process.c
[LCC@hjmlcc ~]$ cat process.c
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//child
int cnt=5;
while(cnt)
{
printf("我是子进程,我还剩下: %d S\n", cnt--);
sleep(1);
}
printf("我是子进程,我已经是僵尸了,等待我的父进程读取我的退出信息\n");
exit(0);
}
else
{
//father
while(1)
{
sleep(1);
}
}
return 0;
}
[LCC@hjmlcc ~]$
//新建会话1:
[LCC@hjmlcc ~]$ while :; do ps ajx | head -1 && ps ajx | grep a.out rep; sleep 1; echo "——————————————————————————————————————————————————————"; done
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
—————————————————————————————————————————————————————————————————
...
...
//新建会话0:
[LCC@hjmlcc ~]$ ./a.out
我是子进程,我还剩下: 5 S
我是子进程,我还剩下: 4 S
我是子进程,我还剩下: 3 S
我是子进程,我还剩下: 2 S
我是子进程,我还剩下: 1 S
我是子进程,我已经僵尸了,等待父进程读取我的退出信息
...
...
^C
[LCC@hjmlcc ~]$
//新建会话1:
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
17213 18645 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out //父
18645 18646 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out //子
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
17213 18645 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
18645 18646 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
17213 18645 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
18645 18646 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
17213 18645 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
18645 18646 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
17213 18645 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
18645 18646 18645 17213 pts/1 18645 Z+ 1003 0:00 [a.out] <defunct>
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
17213 18645 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
18645 18646 18645 17213 pts/1 18645 Z+ 1003 0:00 [a.out] <defunct>
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
17213 18645 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
18645 18646 18645 17213 pts/1 18645 Z+ 1003 0:00 [a.out] <defunct>
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
17213 18645 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
18645 18646 18645 17213 pts/1 18645 Z+ 1003 0:00 [a.out] <defunct>
—————————————————————————————————————————————————————————————————
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
17213 18645 18645 17213 pts/1 18645 S+ 1003 0:00 ./a.out
18645 18646 18645 17213 pts/1 18645 Z+ 1003 0:00 [a.out] <defunct>
//僵尸状态,Z状态、
//虽然子进程变成了僵尸状态,但是父子进程之间的父子关系仍然没有改变、
^C
[LCC@hjmlcc ~]$ 若某一个进程一直处于僵尸状态(处于僵尸状态的进程我们称之为僵尸进程),则该进程的相关资源(主要指的是其进程控制块)就不会被释放,会造成内存资源的浪费,就会造成内存泄漏,这是从操作系统层面上而言的内存泄漏,所以,如果通过 Linux 操作系统所提供的系统调用接口 fork 直接创建出来的某一个进程的子进程,该子进程退出(结束)后,其原始父进程(不是 bash 进程)必须通过手动的方式对其进行资源回收,也就是其原始父进程(不是 bash 进程)必须要读取它的退出信息,否则就会造成内存泄漏、
若某一个进程已经处于僵尸状态,那么此时是不能再通过 Kill 指令将其杀掉的,该状态下的进程是不可被杀掉的(所谓的杀掉进程,指的就是让进程退出(结束),而僵尸状态下的进程已经退出(结束)了,所以不能再被杀掉了),所以如果原始父进程(不是 bash 进程)不对该子进程通过手动的方式进行资源回收的话,一般而言,内存泄漏问题就会一直存在、
僵尸状态(Zombies)是一个比较特殊的状态,当子进程退出(结束),其父进程不退出(结束),并且原始父进程没有读取到子进程的退出信息(具体方法在后期进行阐述:使用 wait() 系统调用等)时,就会产生僵死(尸)进程,僵死进程会以终止状态保持在时实进程表中,并且会一直在等待其父进程读取其退出信息,所以,只要子进程退出(结束),父进程还在运行,但原始父进程没有读取子进程的退出信息,此时,子进程进入 Z 状态、
如何避免产生僵尸进程,会在后期进程阐述、
Ptrace 详解 - tangr206 - 博客园 (cnblogs.com)ptrace系统调用追踪进程运行:
Ptrace 详解 - tangr206 - 博客园 (cnblogs.com)
五、孤儿进程
[LCC@hjmlcc ~]$ ls process.c [LCC@hjmlcc ~]$ cat process.c #include<stdio.h> #include<stdlib.h> #include<unistd.h> int main() { pid_t id = fork(); if(id == 0) { //child while(1) { printf("我是子进程,我永远不退出\n"); sleep(1); } } else { //father int cnt=3; while(cnt) { printf("我是父进程,我还剩下 %d S\n",cnt--); sleep(1); } exit(0); } return 0; } [LCC@hjmlcc ~]$
当父进程退出(结束)的时候,该父进程也是别的进程( bash 进程)的子进程,而 bash 进程一直在运行,所以该父进程的退出信息需要被 bash 进程读取,我们并没有手动的使得此父进程的父进程来读取该父进程的退出信息,那么该父进程为什么没有保持僵尸状态呢?
这是因为,该父进程的父进程是 bash 进程,而 bash 进程会自动的读取其子进程的退出信息,所以该父进程在退出(结束)时,该父进程的父进程( bash 进程)已经自动读取了该父进程的退出信息,所以该父进程停留僵尸状态的时间很短,紧接着就变成了死亡状态,再紧接着就让操作系统回收了、
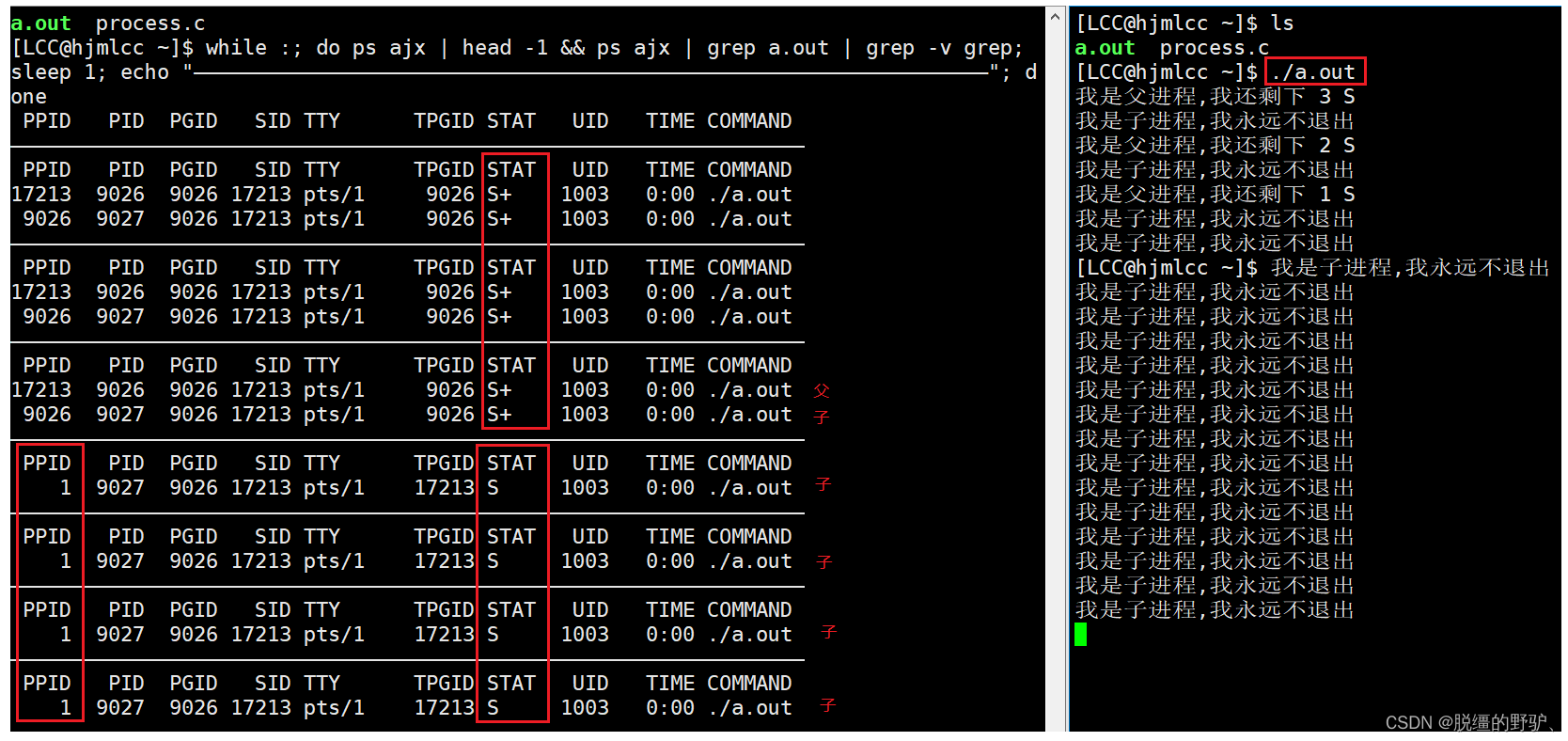
在上图中,父进程先退出(结束)了,而子进程并没有退出(结束),当该子进程退出(结束)时,该子进程的父进程已经退出(结束)了,那么该子进程的退出信息会由谁来读取呢,此时,操作系统会临时作为该子进程的父进程(新父进程)来读取该子进程的退出信息,操作系统就是PID为1的进程,此时,该子进程就被称为孤儿进程、
top指令:查看时实进程的相关信息、
注意:此时通过 ctrl+c 是无法杀掉该孤儿进程的,只能通过 kill -9 PID 指令来将其杀掉,并且该孤儿进程的状态是S,而不是S+,若进程的状态后面有+,则说明该进程是前排进程,前排进程可以通过ctrl+c 来杀掉,若进程的状态后面没有+,则说明该进程是后排进程,后排进程不可以通过 ctrl+c 的方式来杀掉、
六、进程优先级
6.1、基本概念
排队的本质就是确定优先级,进程优先级是进程获取资源的先后顺序(假设进程一定能够申请到资源,只不过是获取资源先后顺序的问题)、
优先级(包括进程优先级)存在的根本原因是因为资源不足,在操作系统中,永远都是进程占大多数,而资源只占少数,这就导致进程竞争资源是常态,只要有竞争,就一定需要确定优先级,比如:一般 CPU 只有一个(可能会存在两个或多个,但通常情况下只有一个,即使存在两个或多个 CPU,也比不上进程的数量多,因此也避免不了会存在进程竞争 CPU 资源的问题)、
总结:
1、CPU 资源分配的先后顺序,就是指进程的优先权(priority)、
2、优先权高的进程有优先执行权利,配置进程优先权对多任务环境的 Linux 很有用,可以改善系统性能、
3、还可以把进程运行到指定的 CPU 上,这样一来,把不重要的进程安排到某个 CPU,可以大大改善系统整体性能、
6.2、查看时实系统进程
在 Linux 或者 Unix 系统中,使用 ps –l 命令则会类似输出以下几个内容:
[HJM@hjmlcc ~]$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 R 1002 7880 13469 0 80 0 - 38587 - pts/1 00:00:00 ps
0 S 1002 13469 10296 0 80 0 - 29543 do_wai pts/1 00:00:00 bash
[HJM@hjmlcc ~]$
我们很容易注意到其中的几个重要信息,如下:
- UID : 代表执行者的身份、
- PID : 代表这个进程的代号、
- PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号、
- PRI :代表这个进程可被执行的优先级,其值越小,优先级越高,越早被执行、
- NI :代表这个进程的 nice 值、
使用 ps –la 或 ps -al 命令,除了可以查看时实系统进程之外,还可以查看我们自己创建的时实进程信息,如下所示:
//新建会话0:
[HJM@hjmlcc ~]$ clear
[HJM@hjmlcc ~]$ ls
Makefile process process.c
[HJM@hjmlcc ~]$ vim process.c
[HJM@hjmlcc ~]$ clear
[HJM@hjmlcc ~]$ ls
Makefile process process.c
[HJM@hjmlcc ~]$ cat Makefile
process:process.c
gcc process.c -o process
.PHONY:clean
clean:
rm -f process
[HJM@hjmlcc ~]$ cat process.c
#include<stdio.h>
#include<unistd.h>
int main()
{
while(1)
{
printf("Hello,Lcc!\n");
sleep(1);
}
return 0;
}
[HJM@hjmlcc ~]$ make
gcc process.c -o process
[HJM@hjmlcc ~]$ ls
Makefile process process.c
[HJM@hjmlcc ~]$ ./process
Hello,Lcc!
Hello,Lcc!
Hello,Lcc!
Hello,Lcc!
Hello,Lcc!
Hello,Lcc!
...
...
//新建会话1:
[HJM@hjmlcc ~]$ ps -al
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 1002 8923 10297 0 80 0 - 1833 hrtime pts/0 00:00:00 process
0 R 1002 8936 13469 0 80 0 - 38595 - pts/1 00:00:00 ps
[HJM@hjmlcc ~]$ 6.3、PRI and NI
在 Linux 操作系统下,进程的优先级 PRI(priority) 取决于 PRI_OLD(priority_old) 和 NI(nice) ,某一个进程的优先级信息也存在于描述该进程所创建的进程控制块中,进程的优先级本质上也是一个int 类型的整数,在 Linux 操作系统下,进程的优先级默认值是80、
在 Linux 操作系统下,更改进程的优先级:
需要通过更改 NI 的值从而达到间接更改进程优先级 PRI 的值,其中,NI 代表的是进程优先级的修正数据,即:PRI = PRI_OLD + NI 、
在 Linux 操作系统下,调整已存在的时实进程或新启动进程的优先级本质上就是调整其 NI 值、
注意:
当每次修改进程优先级时,此处的参数 PRI_OLD 都会被重置为80,其次,NI 的取值范围是:[-20,19],小于 -20 的当做 -20 处理,大于 19 的当做 19 处理,再加上由于每次修改进程优先级时,参数 PRI_OLD 都会被重置为80,因此,进程优先级 PRI 的取值范围就是:[60,99] ,共40个级别、
操作系统分为时实操作系统和分时操作系统,我们使用的一般是分时(类似于进程的时间片这样的概念,后面再进行具体阐述)操作系统,实际上,在 Linux 系统中,进程一共有140个优先级,但是在分时 Linux 操作系统下,其中有很多进程优先级并不能用于我们自己创建的普通进程,普通进程的优先级一般是 [60,99] ,其他100个进程优先级我们暂时不考虑,暂时也不考虑时实 Linux 系统下进程的优先级的级别、
在 Linux 操作系统中,存在指令 nice 和 renice ,前者可以在新启动进程时,为该进程指定 NI 值,但不能修改(设置)已存在的时实进程的 NI 值,后者可以修改(设置)已存在的时实进程的 NI 值,在此不过多阐述,可以通过指令:man nice 或 man 1 nice 和 man renice 或 man 1 renice 查看具体用法、
使用 top 命令更改已经存在的时实进程的 NI 值:
要注意,在普通用户下直接使用 top 指令没有办法更改已存在的时实进程的 NI 值,如下所示:

因此,需要将普通用户切换到 root 用户再使用 top 指令,或者通过指令 sudo top 来操作,以前者为例,如下所示:
新建会话0:
[HJM@hjmlcc ~]$ ls
Makefile process process.c
[HJM@hjmlcc ~]$ ./process
Hello,Lcc!
Hello,Lcc!
Hello,Lcc!
Hello,Lcc!
Hello,Lcc!
...
...
新建会话1:
[HJM@hjmlcc ~]$ ls
Makefile process process.c
[HJM@hjmlcc ~]$ su -
Password:
Last login: Wed Jan 4 13:01:53 CST 2023 on pts/1
[root@hjmlcc ~]# pwd
/root
[root@hjmlcc ~]# top //敲回车进入 top 模式,然后输入 r,再输入要更改的已经存在的时实进程对应的PID
//敲回车,再输入该已存在的时实进程想要设定的 NI 值(-100),然后敲回车,再输入 q 退出 top 模式,再从
//root 用户切换到普通用户,此时该已存在的时实进程的 NI 值就已经设定完毕(-20),因此,该已存在的时
//实进程的进程优先级也设置完毕(60)、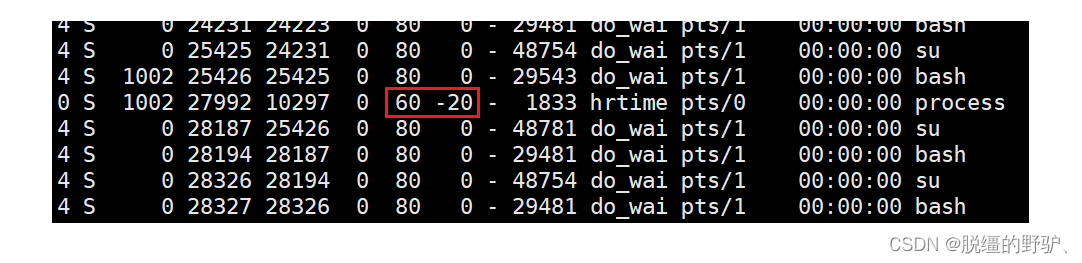 由上可知,此时该进程的进程优先级由原来的80变为了60,说明优先级变高了、
由上可知,此时该进程的进程优先级由原来的80变为了60,说明优先级变高了、
一般情况下不要随便修改进程的优先级,会打破调度器平衡,除非该进程比较特殊(此时可以使用系统调用接口来修改该进程的优先级,也可以按照如上所示进行修改)、
注意:进程的状态和进程的优先级都存在于描述该进程所创建的进程控制块中、
七、其他概念
描述某一个进程所创建的进程控制块中一般包括:该进程对应的 PID,当前路径,该进程对应的优先级,该进程的状态以及内存指针(指向该进程控制块对应的该进程的代码和数据)这样的字段、
1、竞争性:在操作系统中,进程数目众多,而 CPU 资源只有少量,甚至1个,所以进程之间是具有竞争属性的,为了高效完成任务,更合理竞争相关资源,便具有了优先级。排队只是竞争方式的一种,竞争方式有很多,在后期再进行阐述。一般来说,某种资源不能同时申请给多个进程,只能先申请给一个进程,等该进程使用完毕后,再申请给另外一个进程,比如:CPU 不能同时运行多个进程,进程只能一个个的被 CPU 运行,其他资源也是如此,几乎所有的外设与 CPU 资源都是如此、
2、独立性:进程运行具有独立性,多进程运行(包括并发性和并行性),需要独享各种资源,多进程运行期间互不干扰。进程由内核结构和自己的代码和数据构成,在操作系统内,若进程有自己独立的一套内核结构和自己独立的代码和数据,则该进程在运行时就具有独立性。进程运行具有独立性主要体现在,每个进程都有自己独立的一套内核结构和自己独立的的代码和数据,但是,fork 父子进程怎么做到父子进程在运行时具有独立性的呢?我们知道,该父子进程都有一套属于他们自己各自独立的内核结构,并且两者的数据是独立的,但是,由于子进程使用的是父进程的代码,即,父子进程共同一份代码(不独立),那么,父子进程是如何做到在运行时具有独立性的呢,即操作系统做到每个进程运行时具有独立性的问题在后期进程地址空间中会进行具体阐述、
3、并行性:假设计算机存在多个 CPU,操作系统会为每一个 CPU 都维护一个运行调度队列,多个进程在多个 CPU 下分别同时运行,这称之为并行、
4、并发性:多个进程在同一个 CPU 下采用进程切换的方式,在一段时间之内,让多个进程的代码都得以推进,称之为并发,即使计算机中存在多个 CPU,但每一个 CPU 中都是按照并发性进行设置的、
下面具体解释并发性:
以单 CPU 为例,多个进程在系统中运行不等于多个进程在系统中同时运行,一个进程不是一旦占用了 CPU,就会一直执行到结束,然后释放 CPU 资源,我们遇到的大部分操作系统都是分时的!所谓的分时就是操作系统会给每一个进程,在一次调度周期中,赋予一个时间片的概念,每个进程对应的时间片应该是相同时长的、
如图:假设进程1进入 CPU 运行,假设调度器(操作系统中的一个软件模块)给它分配10ms(该时长也是由调度器决定的)的时间,如果10ms到了,无论结果如何都不会再让进程1继续运行了,调度器会把进程1从 CPU 上剥离下来,并拿去运行队列队尾继续排队,然后再调度运行进程2……假设往后每个进程都是分配10ms,1s = 1000ms,那么在1s内,这5个进程平均每个都要被 CPU 运行20次、
由上可知,我们看到的微信,QQ,cctalk 等多个进程 "同时" 运行的原因是因为,由于时间片的存在,使得多个进程在同一个 CPU 下采用进程切换的方式,在一段时间之内,让多个进程的代码都得以推进,再由于时间片很短,使得我们人眼看起来好像多个进程在同时运行,其实本质上并不是在同时运行多个进程、
补充1:抢占式内核
在操作系统中,进程对应的进程控制块就是简单的根据队列来进行先后调度,从而使得该进程控制块对应的进程被 CPU 运行的吗?其实并不是这样,比如:有可能突然来了一个比正在被 CPU 运行的进程的优先级更高的进程,此时调度器会直接把该正在被 CPU 运行的进程从 CPU 中剥离出来,不管这个进程的时间片是否结束,都会直接从 CPU 中剥离出来,并将其对应的进程控制块拿到队尾继续排队,且把该优先级更高的进程放入 CPU 中进行运行,还有另外一种情况就是,如果突然来了一个优先级比在 CPU 运行队列中等待的某一个进程控制块对应的进程的优先级更高的进程,则调度器会直接把该更高优先级的进程对应的进程控制块直接放到该在 CPU 运行队列中这个正在等待的优先级较低的进程对应的进程控制块的前面等待被 CPU 调度,以上两种情况都属于进程抢占,目前,主流的操作系统(包括Linux操作系统)都是基于抢占式内核进行设计的、
补充2:进程的 优先级 | 队列
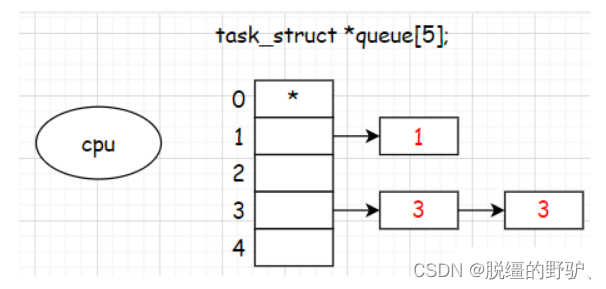
以 Linux 内核2.6.32为例,虽然在操作系统中会存在各种优先级不同的进程,但是大部分情况下,各个进程的优先级都是一样的,在操作系统内部,是允许存在不同优先级进程的,且相同优先级的进程可能存在多个。其次如果存在进程抢占现象的话,我们原来的 CPU 运行队列是没有办法完成进程抢占的,这是因为,队列的性质要求先进先出,如果出现进程抢占现象的话,就违背了队列的性质,所以并不是只使用一个简单的运行队列就能解决问题的。因此,在 Linux 操作系统中,可能会存在多条 CPU 运行队列,而不是只有简单的一条运行队列,假设整个 Linux 操作系统中只有5种不同优先级的进程,首先,定义一个指针数组,即:task_struct *queue[5],优先级分别是:0,1,2,3,4,再借用 hash,即可解决问题,如下所示:
总结:
Linux 内核是根据不同的优先级,将特定的进程对应的进程控制块放入不同的运行队列中,而 CPU 就很自然的从指针数组的优先级最高的地方开始寻找进程对应的进程控制块、
具体的O(1)复杂度的调度算法见视频:2022-8-12:00:40:30
补充3:进程间是如何进行切换的?
CPU 是一个组件,其内部存在各种各样的具有0,1序列的一套寄存器,这些寄存器是由一堆存储器(比如:触发器等等)构成的,有32byte,64byte和128byte等类型,一般而言,数据存储在冯诺依曼体系结构里的内存中,所有的数据都需要从内存加载到 CPU 中进行计算,再把计算结果写回内存,内存相当于外设的一个大缓存,但也要知道,CPU 中的寄存器里也可以临时的存储少量但比较重要的临时数据、
CPU 内部的寄存器分为:可见寄存器(能够被我们使用的,比如:eax,ebx,ecx,edx 等通用寄存器以及ebp,exp,eap,栈顶,栈底等都称为可见寄存器)和不可见寄存器(权限寄存器(Linux下通常称为:cl3),状态寄存器等等给操作系统使用的寄存器都称为不可见寄存器)、
当一个进程在 CPU 中运行时,若时间片结束了,则该进程会被调度器从 CPU 中剥离下来并将其对应的进程控制块拿到队尾继续排队,在时间片这一过程中,一定会存在大量的临时数据被临时的保存在了 CPU 中的寄存器里,这些临时数据也会被打包拿走,等到下一次该进程再被 CPU 运行时,这些临时数据再恢复到 CPU 中的寄存器里,如果这些临时数据不跟随其对应的进程一起离开的话,当 CPU 运行下一个进程时,新进程也会把一些临时数据暂时存储在 CPU 的寄存器中,这样就会把之前的进程的一些没有拿走的临时数据覆盖掉,当下一次,这个之前的进程再被 CPU 运行时,就找不到它的临时数据了,就会出现问题,这些暂存于寄存器中的临时数据被称为硬件上下文数据,当进程被调度器从 CPU 中剥离或者是进程主动从 CPU 出让时,需要将暂存于寄存器中的临时数据保存起来(即需要进行上下文数据保护),当下次进程再被 CPU 运行时,需要将这些保存起来的临时数据再次恢复到 CPU 中的寄存器里(即需要进行上下文数据恢复)、
这些暂存于寄存器中的临时数据,一小部分会被保存在该进程对应的进程控制块中的上下文数据字段中,另外一大部分会被保存在操作系统层面上全局的数据区中,详细请查看局部段描述符和全局段描述符的概念,但是在此,我们就笼统的认为这些暂存于寄存器中的临时数据全部被保存在该进程对应的进程控制块中的上下文数据字段中、