说实话,我非常希望自己能早点看到本篇文章,大学那个时候懵懵懂懂,跟着网上的免费教程做了一个购物商城就屁颠屁颠往简历上写。
至今我仍清晰地记得,那个电商教程是怎么定义接口的:
管它是增加、修改、删除、带参查询,全是 POST 请求一把梭,比如下面这样:
修改用户的收货地址
POST /xxx-mall/cart/update_address
现在看来,全部用 POST 请求估计是为了传参方便吧。
那个时候自己也没有一个 API 接口需要设计 的意识,跟学过类似教程的朋友应该懂的,老师敲一行代码学生跟着敲一行。如果没人提这个事情,正式工作进入团队后,是很容易出丑的......(作者亲身经历,捂脸)
本文就不用 PPT 教案上的那种官方腔介绍 API 接口是个什么概念了,比较希望用一种聊天的方式和大家分享下现有的一丁丁和 API 相关的小心得,文章会分为五小块:
-
初识 API 接口
-
关于 API 限流
-
关于 API 版本管理
-
关于 API 权限与安全
-
关于团队间的 API 互通
注:这是一篇会隐式罗列很多知识点的文章,您可以按需深度搜索进行更进一步的学习。当年渴望看到这样的文章的原因是:学习一个知识点其实只需要时间,对学生而言,时间不是问题,问题在于不知道该往哪些方向学 T_T 。本文希望通过串讲,梳理一下个人当前了解到的 API 知识体系,整理的同时也希望能对大家有一点点帮助。
1、初识 API 接口
记得在我初学 web 开发的时候,后端框架相关的教程基本都会教学生写渲染模版(不分语言),也就是说后端返回的是整个网页的数据,浏览器只负责渲染。
一般这类模版在后端都会对应一个路由,比如前端想登入一个看用户信息的页面,在 url 中输入的访问地址大概长这样:
https://ajun24.com/user
那个时候,我以为这样的路由地址就是 API 概念的全部了......
值得一提的是:绝大部分后端教程都会简单教一下前端,在前端的补充教程中有一个必学的知识点,叫:AJAX。
老师大概率会演示一下 AJAX 这个技术怎么使用,写个小 Demo,告诉大家可以这样在页面上发送异步请求。
这个技术请求的后端接口一般不会跳转或返回一个 html 页面,大概率会返回一份 json 数据。我一直对这样的接口和返回页面数据的接口有着迷之困惑。直到我实习后明白了什么叫前后端分离开发......
但是为了教学方便,完整项目大概率还是会用渲染模版的方式讲解,毕竟只在一套系统里写代码演示会方便很多。
当年就是这样学完了第一个项目,虽然对如何做一个软件系统有了整体的认识,但是对 API 设计的认识是非常弱的。
其实我在学 AJAX 这个知识点的时候就在想:有没有可能全部数据都通过类似 AJAX 这种方式获取?这样感觉会更方便一些。
后来实习的时候,前端同学告诉我:开发前需要先定义 API 哦。
当然,他还告诉我:删除一个东西不能用 POST 请求哦

(捂脸)
后来导师提醒我:你需要去了解一下如何设计 REST 风格的 API。
自从那次出丑后,我明白了一个事情,一定要敢于把自己的不足"暴露"给愿意指点你的人看。就好比我们读大学的时候最好要努力去找一份实习,每一次被拒以及每一份 offer 都会告诉我们,这个社会需要什么样的人才,什么样的技能可以帮助我们谋得一份工作。
在正式的面试场合下,或许我们更应该条理清晰地和面试官介绍什么是表现层状态转换,但是在这篇文章中,我想把 REST 风格的 API 称为更容易让人看懂的 API。
大家会发现符合 REST 风格的 API 能非常容易地让别人知道调用这个 API 能干什么,比如:
GET /users # 查询用户信息
PATCH /users/{user_id} # 根据 id 更新某个用户的信息,只部分更新客户端提交的数据
按约定写 API 就好比在 IT 领域说行话,大家只要看见你的 API,就知道你能提供什么样的服务。
有同学可能会好奇为什么要遵守规范?
假如,我们负责的系统仅联系到我们身边同事的系统,那约定 API 的时候只需要打个招呼,或在聊天工具上简单说明一下就可以了,甚至可以没有文档。
但在很多情况下,我们的系统是要被很多其他系统调用的,大家想象一下我们去调用云厂商 API 的场景:别人的工程师大概率不是我们的微信好友,大多数时候是没有人站在我们身边手把手告诉我们 API 怎么调用的。这个时候想调用对方提供的 API,就得看对方提供的 API 文档。如果对方的 API 不按照规范定义,那 API 文档绝对像天书一样难读。
看天书的痛苦,保证大家体会一次足以终生难忘。
良好的 API 文档一般会像工具手册,没有太多学习成本,否则别人下一次很有可能就不使用我们的服务了

所以先系统地学习 API 定义约规,再编写 API 文档,然后根据设计进行开发是一个比较好的研发流程。
接下来的问题是,在了解了 API 的规范后,如何写出良好的 API 文档呢?
众所周知,写文档对程序员来说是一件非常痛苦的事情,一想到学习写专业的 API 文档还需要学习成本,实在是劝退。这个时候我们可以通过一些自动化工具辅助我们完成一篇优秀的 API 文档,比如我们可以使用 swagger,它可以通过我们的代码自动生成 API 文档。
最近还看到不少基于 API 的研发测试一体化产品和平台,感觉一站式的、流水线式的研发管理是未来的趋势呀! 更多有关API信息欢迎来讨论
2. 关于 API 限流
API 写出来后会被调用,但由于计算机 & 网络系统的局限性,我们的 API 接口是不可以被无限制调用的。
大家可以随便到网上挑一个比较专业的 API 文档看,比如大家可以去看云厂商对外提供的 API,基本都会看到一个接口频率调用限制,比如:单用户调用频率为 30 次 / 秒。
所以当我们在设计 API 的时候,限流是一个不得不考虑的事情(内部自己弄着玩的不算哈,泛指面向用户的系统)
在设计限流之前,我们首先要知道自己系统的瓶颈。假设我们的 API 纯粹调用自家的技术组件,比如数据库,消息队列等中间件,这个时候我们可以通过压测得知一个接口的最大承受能力;假设我们的系统是一个中间系统,需要依赖其他系统的接口完成业务,那么这个时候基于木桶原理,我们接口的可访问频率就会受限于其他业务系统。
了解完自身项目的访问瓶颈后,需要考虑自身系统的架构,假设我们的系统是单体部署:
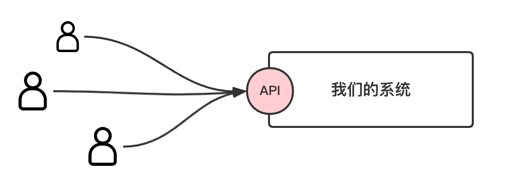
那这个时候我们只需要简单的令牌桶算法即可以完成限流,下面是一个极简的令牌桶算法实现 Demo:
"""
简单解释:
实现一个固定容量的桶,按一定的频率往桶内放令牌直至桶满,每当执行一个限频操作需要从桶中获取一个令牌才能继续操作,若桶中没有令牌,则进行等待
往令牌桶中放令牌的操作不便按照原概念实现,所以放令牌这步放到取令牌的时候进行。我们根据当前取令牌的时间减去上一次取令牌的时间差,就能得知这段时间内增加了多少个令牌。
"""
class TokenBucket(object):
# rate 是令牌桶生产令牌的速率,capacity 是令牌桶生产令牌的速率
def __init__(self, rate, capacity):
self._rate = rate
self._capacity = capacity
self._current_amount = 0
self._last_consume_time = int(time.time())
# token_amount 是执行一次操作需要的令牌数量
def consume(self, token_amount):
# 通过时间差乘速率,得到令牌的增量
increment = (int(time.time()) - self._last_consume_time) * self._rate
时间差乘速率,得到令牌的增量
self._current_amount = min(
increment + self._current_amount, self._capacity)
# 令牌数量不够则不允许操作
if token_amount > self._current_amount:
return False
# 更新最后一次操作时间
self._last_consume_time = int(time.time())
# 结算当前的令牌数量
self._current_amount -= token_amount
return True
但实际工作中,我们部署单体架构的机会不多,现在的大公司都构建有自己的云生态,业务部门上云后可快速进行扩缩容,所以我们的系统很有可能会进行集群部署,用户的请求通过代理层负载均衡至各个后端节点:
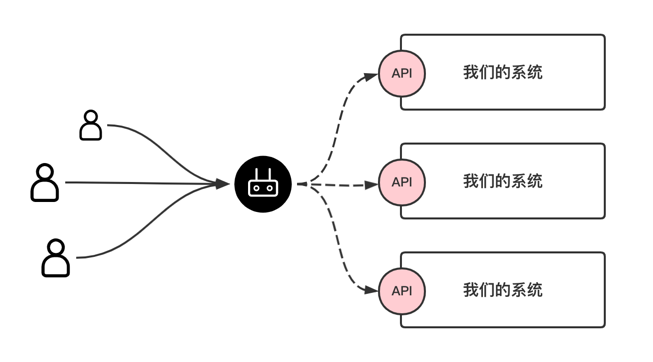
这个时候上面的 15 行代码显然就不符合我们的分布式系统架构,我们得考虑更复杂的限流算法实现了(这里不是指令牌桶算法不合适,是指令牌桶算法的实现方式需要改进),当然这个实现大概率会放在代理层了,而不是实现在我们的业务层。
大家可以上网看一下主流云厂商提供的云服务,很多都会提供 API 网关,对应着我们上面提到的代理层。
假如一个公司有统一的 API 网关服务,或有类似的代理服务,业务部门是可以在 API 限流这件事情上省下很大功夫的。我有时候想,当越来越多的中小企业基于巨无霸云厂商搭建业务,大家要考虑的技术性问题就会越来越少,越来越专注于业务,这到底是一件好事还是坏事呢?
3、关于 API 版本管理
介绍完 API 及限流的基本知识后,谈一下和业务比较相关的 API 的版本管理。
在没真正接触业务前,我以为只有软件需要做版本管理,为啥 API 也要做版本管理咧?
其实原理是一样的,软件会根据需求不断迭代版本,API 同样也会迭代版本,但秉承开闭原则,为了不影响之前的业务,我们最好不要改动原有的 API。
因此,我们设计 API 的时候可以指定版本号,比如上述的例子:
GET /users # 查询用户信息
我们可以统一定义成:
GET /api/v1/users # 查询用户信息
假设这个接口有了第二个版本,我们就可以通过版本号进行区分了:
GET /api/v2/users # 查询用户详细信息
换作两年前的我可能会对 API 版本管理无感,但大家尝试把自己代入以下场景就能明白了:
比如我们的产品让我们出一套新的查询用户 API,假设我们没有定义版本号,由于 /users 这条路由已经在用了,逼不得已,我们就会定义一个新的:
GET /get_user_info # 查询用户信息
新接口和老接口的意思差不多,如果我们一直负责这个系统,那还好说(心里有不同版本的区分)
但假如这个系统换了另一个接班人,当他面对大量意义接近的接口时,肯定会怀疑人生的......(屎山就是这样来的)
4. 关于 API 权限与安全
接着我们思考一下 API 的权限与安全问题。
还是回到初学的时候,那个时候我对 API 接口权限完全没有任何概念。老师为了快速教会我们开发系统,很多接口的设计是完全裸奔的。如果不了解一点点相关的知识,工作中会容易给别人一种考虑事情不周到的感觉。
在实际生产中,接口是不可以不做权限校验的,如果我们的系统暴露在公网,还没有权限校验的话,系统估计很快就挂了;内部涉及机密的系统,权限校验则更为严格。
关于权限校验,个人暂时分为三个维度,三个维度或许可以对应三种业务类型:
-
第一种是直接针对 IP 设置白名单,这种方式比较适用于客户端有限且固定的内部系统;
-
第二种则是设置权限校验流程,比如采用 Token 鉴权,较多用于 ToB 业务。大家在云厂商注册账号后基本都会得到一对密钥,后续的 API 调用一般都需要先根据密钥进行权限认证;
-
第三种是通过用户登陆判断权限,较多用于 ToC 业务,比如我们登陆京东,登陆淘宝需要账号,没有登陆就访问不了购物车等页面。
值得一提的是,权限设计是另一个维度的知识,除了第一个维度,后两者其实都可以单独成立一个系统的。比如公司的用户管理系统,中心化权限认证系统等等。
权限校验关乎着公司财产安全,所以不可忽视,很多时候我们甚至需要在 API 设计层面考虑安全问题。再次引用商城的例子,比如登陆后获取用户购物车的订单,API 大概率会设计成这样子:
GET /users/287435/orders
但直接暴露用户 id 或许不是一个明智的选择,有可能被不法分子利用,我们可以换种方式,比如用以下的方式替代:
GET /users/me/orders
总而言之,API 的设计除了参考规范外,还需要根据自身业务情况进行更进一步的安全考虑。
5、关于团队间的 API 互通
最后是一个延展性话题,相信大家都感受到了我们正身处于一个数据时代,我们的个人信息,包括各类行为喜好,都存放在各家互联网公司的数据仓库里,企业们可能比我们更了解我们自身,网上也有很多与数据资产有关的话题。
既然已经把数据比作资产了,而资产流动性又是一个经久不衰的话题,所以各类数据的开放性问题也倍受关注。而数据对外开放,必然就会涉及到 API 接口。
当然作为一只小码农,我的视野极其有限,很难从一个较高的层次去谈论企业的数据问题。但在工作中,当其他业务团队提出要调用自己负责的项目的 API 接口时,也是需要进行多方位考虑的。
本文列出的就是个人会从技术上考虑的点,总结成三句话就是:
-
你能看懂我的 API 嘛?
-
别把我的 API 打爆哦!
-
API 要经允许才能使用哦!
由于API 的这个概念实在是太大了,我能接触的也是一些些皮毛,但时不时总结整理一下还是大有裨益的。