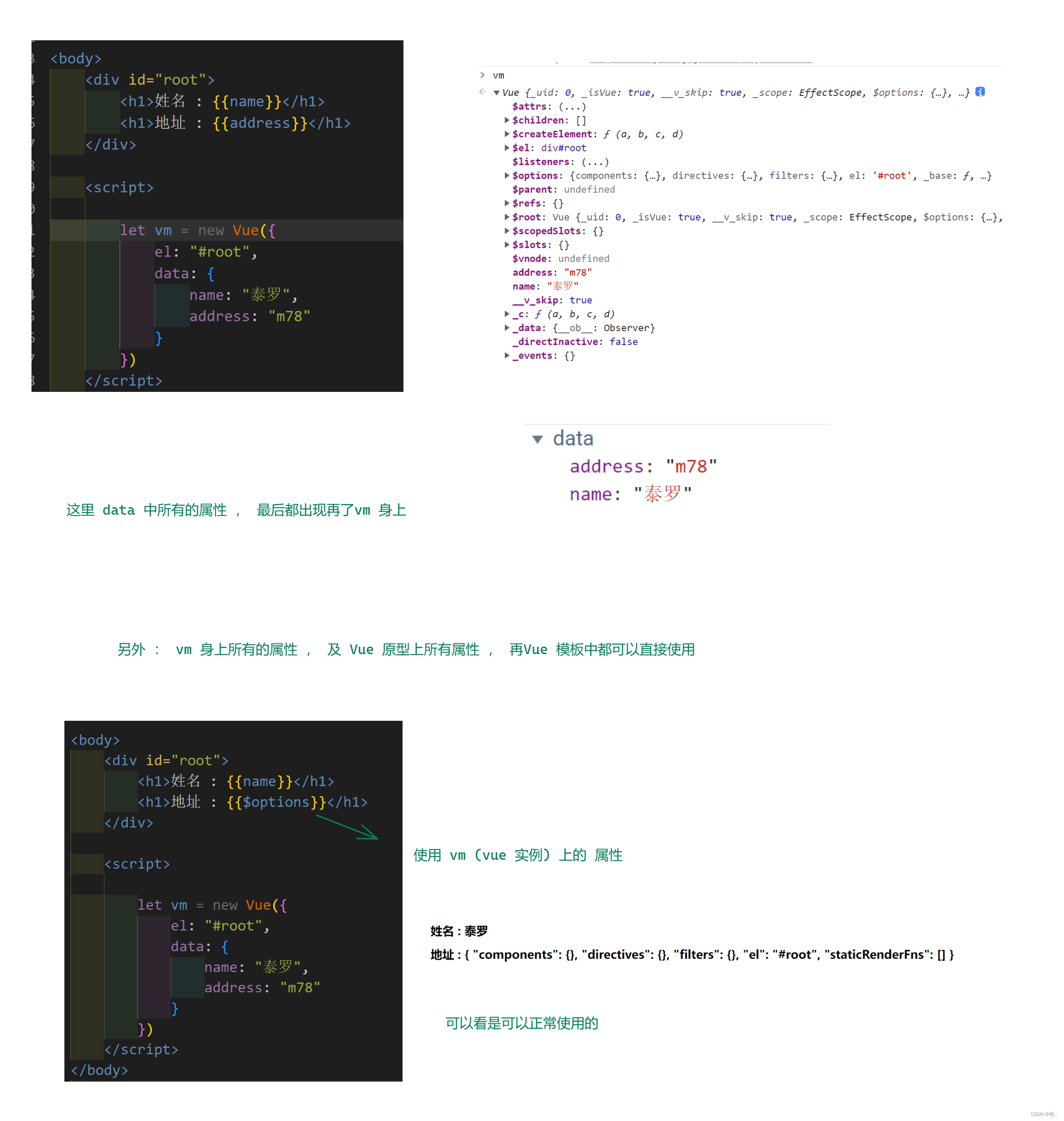
2021网络空间安全西湖学术论坛线上报告中介绍了差分隐私过去发展,目前现状以及未来研究方向。博主对这个报告进行了介绍与总结。总结中提到学习差分隐私最重要的环节是:
- 了解差分隐私的基本机制:拉普拉斯机制、指数机制和高斯机制
- 差分隐私的组合定理与一些性质
- 差分隐私的数学证明
本笔记按照这个思路进行学习。
目录
- 拉普拉斯机制
- 拉普拉斯分布
- 常见的 f f f函数
- 有关 Δ \Delta Δ
- 指数机制
- 有关 Δ μ \Delta_{\mu} Δμ
- 一个例子:定价
- 性质
- Utility
- 高斯机制
- 性质
- Post processing
- Group privacy
- Basic composition
- Advanced composition
拉普拉斯机制
拉普拉斯机制针对数值型查询进行隐私保护。即针对
f
:
D
→
R
d
f:D\rightarrow R^d
f:D→Rd的情况。其实现为
M
(
D
)
M(D)
M(D):
M
(
D
)
=
f
(
D
)
+
(
Y
1
,
Y
2
,
.
.
.
Y
d
)
M(D)=f(D)+(Y_1, Y_2,...Y_d)
M(D)=f(D)+(Y1,Y2,...Yd)即在数据的查询结果
f
(
D
)
f(D)
f(D)上添加服从拉普拉斯分布的噪声,从而做到保护数据的目的。
其中
Y
i
∼
L
a
p
(
Δ
/
ϵ
)
Y_i \sim Lap(\Delta/\epsilon)
Yi∼Lap(Δ/ϵ),
Δ
\Delta
Δ是全局敏感度。
使用拉普拉斯机制对数据进行保护满足
ϵ
\epsilon
ϵ差分隐私,证明如下:
p
r
[
M
(
D
)
=
t
]
p
r
[
M
(
D
′
)
=
t
]
=
p
r
[
Y
=
t
−
h
]
p
r
[
Y
=
t
−
h
′
]
=
1
2
λ
exp
(
−
∣
t
−
h
∣
λ
)
1
2
λ
exp
(
−
∣
t
−
h
′
∣
λ
)
=
exp
(
∣
t
−
h
′
∣
λ
−
∣
t
−
h
′
∣
λ
)
≤
exp
(
∣
h
−
h
′
∣
λ
)
=
exp
(
ϵ
)
\frac {pr[M(D)=t]} {pr[M(D')=t]}= \frac{pr[Y=t-h]}{pr[Y=t-h']}\\=\frac{\frac{1}{2\lambda}\exp(-\frac{|t-h|}{\lambda})}{\frac{1}{2\lambda}\exp(-\frac{|t-h'|}{\lambda})}\\=\exp({\frac{|t-h'|}{\lambda}}-{\frac{|t-h'|}{\lambda}})\\\le\exp(\frac{|h-h'|}{\lambda})\\=\exp(\epsilon)
pr[M(D′)=t]pr[M(D)=t]=pr[Y=t−h′]pr[Y=t−h]=2λ1exp(−λ∣t−h′∣)2λ1exp(−λ∣t−h∣)=exp(λ∣t−h′∣−λ∣t−h′∣)≤exp(λ∣h−h′∣)=exp(ϵ)
证明思路为:
- 将引入机制后的最终结果相等的概率比值按照拉普拉斯机制的定义转换成对噪声取值的要求
- 将噪音的概率引入到计算公式中
- 进行除法约分计算
- 利用距离公式
- 利用 Δ \Delta Δ的定义进行化简
拉普拉斯分布
当随机变量
Y
Y
Y满足其取值为
y
y
y的概率为
p
r
[
Y
=
y
]
=
1
2
λ
exp
(
−
∣
y
−
μ
∣
λ
)
pr[Y=y]=\frac{1}{2\lambda}\exp(-\frac{|y-\mu|}{\lambda})
pr[Y=y]=2λ1exp(−λ∣y−μ∣)
我们称随机变量
Y
Y
Y服从拉普拉斯分布
Y
∼
L
a
p
(
λ
)
Y \sim Lap(\lambda)
Y∼Lap(λ).
常见的 f f f函数
对于关系数据R,常见的 f f f函数包括:
- 计数
- 均值
- 中位数
- 直方图
有关 Δ \Delta Δ
对于不同的
f
f
f,
Δ
\Delta
Δ的取值不尽相同,例如对于计数函数,
Δ
=
1
\Delta=1
Δ=1;对于直方图函数,
Δ
=
2
\Delta=2
Δ=2.
指数机制
指数机制针对非数值查询进行隐私保护,这与拉普拉斯针对数值型查询进行隐私保护有着巨大的不同。以为数字产品做定价这个场景为例,假定存在 n = 3 n=3 n=3个买者,每个买者对于商品有自己的定价,定价分别为 ( 1 , 1 , 3.01 ) (1,1,3.01) (1,1,3.01),在这个设定下,当价格从1增加到1.1时,1号和2号买方不买,只有3号买方买,则总收益从3突然减小到1.01。在这个例子中我们知道价格的轻微变化会导致收益的剧烈变化。
考虑数据集 D ∈ x n D \in x^n D∈xn(可以理解为上述情景中每个用户的定价)给定范围 R R R(上述例子中定价的范围)效用函数 μ \mu μ(最终收益),指数机制保证以正比于 exp ( ϵ μ ( D , R ) 2 Δ μ ) \exp(\frac{\epsilon\mu(D,R)}{2\Delta_{\mu}}) exp(2Δμϵμ(D,R))的概率得到 r r r.即 p r [ M E ( x ) = r ] = exp ( ϵ μ ( x , r ) / 2 Δ μ ) ∑ r ′ ∈ R exp ( ϵ μ ( x , r ′ ) / 2 Δ μ ) pr[M_E(x)=r]=\frac{\exp(\epsilon \mu(x,r)/2\Delta_{\mu})}{\sum_{r' \in R}\exp(\epsilon \mu(x,r')/2\Delta_{\mu})} pr[ME(x)=r]=∑r′∈Rexp(ϵμ(x,r′)/2Δμ)exp(ϵμ(x,r)/2Δμ)
M E M_E ME满足 ϵ \epsilon ϵ差分隐私,其证明如下: p r [ M E ( x ) = r ] p r [ M E ( x ′ ) = r ] = exp ( ϵ μ ( x , r ) / 2 Δ μ ) exp ( ϵ μ ( x ′ , r ) / 2 Δ μ ) = exp ( ϵ ( μ ( x , r ) − μ ( x ′ , r ) ) 2 Δ μ ) ≤ exp ( ϵ × 2 Δ μ 2 Δ μ ) = exp ( ϵ ) \frac{pr[M_E(x)=r]}{pr[M_E(x')=r]}=\frac{\exp(\epsilon \mu(x,r)/2\Delta_\mu)}{\exp(\epsilon \mu(x',r)/2\Delta_\mu)}=\exp(\frac{\epsilon (\mu(x,r)-\mu(x',r))}{2\Delta_\mu})\leq\exp(\frac{\epsilon\times2\Delta_\mu}{2\Delta_\mu})=\exp(\epsilon) pr[ME(x′)=r]pr[ME(x)=r]=exp(ϵμ(x′,r)/2Δμ)exp(ϵμ(x,r)/2Δμ)=exp(2Δμϵ(μ(x,r)−μ(x′,r)))≤exp(2Δμϵ×2Δμ)=exp(ϵ)
有关 Δ μ \Delta_{\mu} Δμ
Δ μ \Delta_{\mu} Δμ衡量了效用函数的敏感度,其定义为 Δ μ = max r ∈ R max x , x ′ a r e n b r s ∣ μ ( x , r ) − μ ( x ′ , r ) ∣ \Delta_{\mu}=\max_{r\in R}\max_{x,x' are \ nbrs}|\mu(x,r)-\mu(x',r)| Δμ=r∈Rmaxx,x′are nbrsmax∣μ(x,r)−μ(x′,r)∣
一个例子:定价
数字产品定价场景中,假定产品的个数可以不受限制,整个市场有3个用户,每个用户对产品的心目定价为确定已知,用户1的定价为1,用户2的定价为1,用户3的定价为3.01,即用户定价向量为(1,1,3.01),下面考虑定价对总收益的影响。在定价小于1时,随着价格的增加,收益会增加;价格超过1后用户1和2停止购买,总收益会突然减小,然后随着价格上涨,3号用户一个人贡献的总收益逐渐增加;最后当价格超过3号用户心中的价格3.01后,整个市场无人购买,总收益变成0。

性质
Utility
令 O P T ( X ) = m a x r ∈ R μ ( x , r ) OPT(X)=max_{r\in R}\mu(x,r) OPT(X)=maxr∈Rμ(x,r)是最大效用函数, R ∗ R^* R∗是达到最大效用函数的目标集合,则有 p r [ μ ( M E ( x ) ≤ O P T ( X ) − 2 Δ μ ϵ ( ln ( ∣ R ∣ ∣ R ∗ ∣ ) + t ) ] ≤ exp ( − t ) pr[\mu(M_E(x)\leq OPT(X )-\frac{2\Delta_\mu}{\epsilon}(\ln(\frac{|R|}{|R^*|})+t)]\leq\exp(-t) pr[μ(ME(x)≤OPT(X)−ϵ2Δμ(ln(∣R∗∣∣R∣)+t)]≤exp(−t)其证明如下: p r [ s ( M E ( x ) ≤ c ] = ∑ r : μ ( x , r ) ≤ c exp ( ϵ μ ( x , r ) 2 Δ μ ) ∑ r ′ ∈ R exp ( ϵ μ ( x , r ′ ) 2 Δ μ ) ≤ ∣ R ∣ ∣ R ∗ ∣ exp ( ϵ 2 Δ μ ( c − O P T ( X ) ) ) pr[s(M_E(x)\leq c]=\sum_{r:\mu(x,r)\leq c}\frac{\exp(\frac{\epsilon \mu(x,r)}{2\Delta_\mu})}{\sum_{r'\in R}\exp(\frac{\epsilon \mu(x,r')}{2\Delta_\mu})}\leq \frac{|R|}{|R^*|}\exp(\frac{\epsilon}{2\Delta_\mu}(c-OPT(X))) pr[s(ME(x)≤c]=r:μ(x,r)≤c∑∑r′∈Rexp(2Δμϵμ(x,r′))exp(2Δμϵμ(x,r))≤∣R∗∣∣R∣exp(2Δμϵ(c−OPT(X)))为了找到上界,应该找到分子的上界和分母的下界,这里使用到效用函数的范围:对于分子而言效用函数小于等于 c c c,因此分子中的效用函数可以被 c c c限定住,求和则涉及到满足效用函数小于 c c c的个数,其最大不会超过整个范围空间 R R R,因此分子小于等于 ∣ R ∣ exp ( ϵ c 2 Δ μ ) |R|\exp(\frac{\epsilon c}{2\Delta_\mu}) ∣R∣exp(2Δμϵc);对于分母我们要找其大于什么,由效用函数的最大值为 O P T ( X ) OPT(X) OPT(X)我们可以得到分母大于等于效用函数取值为 O P T ( X ) OPT(X) OPT(X)的项之和,即分母大于等于 ∣ R ∗ ∣ exp ( ϵ O P T ( X ) 2 Δ μ ) |R^*|\exp(\frac{\epsilon OPT(X)}{2\Delta_\mu}) ∣R∗∣exp(2ΔμϵOPT(X)).令 c = O P T ( X ) − 2 Δ μ ϵ ( ln ( ∣ R ∣ ∣ R ∗ ∣ ) + t ) c=OPT(X )-\frac{2\Delta_\mu}{\epsilon}(\ln(\frac{|R|}{|R^*|})+t) c=OPT(X)−ϵ2Δμ(ln(∣R∗∣∣R∣)+t)则可以得证。
高斯机制
高斯机制与拉普拉斯机制类似,均通过在响应结果上加噪音达到隐私保护的效果,只不过与拉普拉斯机制不同,高斯机制加的噪音服从高斯分布。
M
(
D
)
=
f
(
D
)
+
(
Y
1
,
Y
2
,
.
.
.
Y
d
)
M(D)=f(D)+(Y_1, Y_2,...Y_d)
M(D)=f(D)+(Y1,Y2,...Yd)其中
Y
i
∼
N
(
0
,
σ
2
)
Y_i \sim N(0,\sigma^2)
Yi∼N(0,σ2)
σ
2
=
(
Δ
2
ϵ
log
(
1
/
λ
)
)
2
\sigma^2=(\frac{\Delta_2}{\epsilon}\sqrt{\log(1/\lambda)})^2
σ2=(ϵΔ2log(1/λ))2.
高斯机制无法确保 ϵ \epsilon ϵ差分隐私,而是退而求其次达到了 ( ϵ , δ ) (\epsilon,\delta) (ϵ,δ)差分隐私,这里的 δ \delta δ是松弛项,表示隐私保护做得不好的范围。可以证明高斯机制实现了 ( ϵ , δ ) (\epsilon,\delta) (ϵ,δ)差分隐私,证明如下:
首先证明 L M ( D ) ∣ ∣ M ( D ′ ) ∼ N ( ∣ ∣ f ( D ) − f ( D ′ ) ∣ ∣ 2 2 2 σ 2 , ∣ ∣ f ( D ) − f ( D ′ ) ∣ ∣ 2 2 σ 2 ) L_{M(D)||M(D')}\sim N(\frac{||f(D)-f(D')||_2^2}{2\sigma ^2},\frac{||f(D)-f(D')||_2^2}{\sigma ^2} ) LM(D)∣∣M(D′)∼N(2σ2∣∣f(D)−f(D′)∣∣22,σ2∣∣f(D)−f(D′)∣∣22)然后利用分布的特点,计算出 L M ( D ) ∣ ∣ M ( D ′ ) L_{M(D)||M(D')} LM(D)∣∣M(D′)小于 ϵ \epsilon ϵ的概率是 1 − δ 1-\delta 1−δ.
- 证明
L
M
(
D
)
∣
∣
M
(
D
′
)
∼
N
(
∣
∣
f
(
D
)
−
f
(
D
′
)
∣
∣
2
2
2
σ
2
,
∣
∣
f
(
D
)
−
f
(
D
′
)
∣
∣
2
2
σ
2
)
L_{M(D)||M(D')}\sim N(\frac{||f(D)-f(D')||_2^2}{2\sigma ^2},\frac{||f(D)-f(D')||_2^2}{\sigma ^2})
LM(D)∣∣M(D′)∼N(2σ2∣∣f(D)−f(D′)∣∣22,σ2∣∣f(D)−f(D′)∣∣22)
令 f ( x ) − f ( x ′ ) = v f(x)-f(x')=v f(x)−f(x′)=v,则有 L M ( D ) ∣ ∣ M ( D ′ ) = ln ( p r [ M ( D ) = f ( D ) + x ] p r [ M ( D ′ ) = f ( D ) + x ] ) = ln ( exp ( − ∣ ∣ x ∣ ∣ 2 2 / 2 δ 2 ) exp ( − ∣ ∣ x + v ∣ ∣ 2 2 / 2 δ 2 ) ) = 1 2 σ 2 ( ∣ ∣ x + v ∣ ∣ 2 2 − ∣ ∣ x ∣ ∣ 2 2 ) = 1 2 σ 2 ( ∑ i k ( v i 2 + 2 x i v i ) ) L_{M(D)||M(D')}=\ln(\frac{pr[M(D)=f(D)+x]}{pr[M(D')=f(D)+x]})\\=\ln(\frac{{\exp(-||x||_2^2}/{2\delta^2})}{{\exp(-||x+v||_2^2}/{2\delta^2})})\\=\frac{1}{2\sigma^2}(||x+v||_2^2-||x||_2^2)\\=\frac{1}{2\sigma^2}(\sum_i^k(v_i^2+2x_iv_i)) LM(D)∣∣M(D′)=ln(pr[M(D′)=f(D)+x]pr[M(D)=f(D)+x])=ln(exp(−∣∣x+v∣∣22/2δ2)exp(−∣∣x∣∣22/2δ2))=2σ21(∣∣x+v∣∣22−∣∣x∣∣22)=2σ21(i∑k(vi2+2xivi))可以发现 L M ( D ) ∣ ∣ M ( D ′ ) L_{M(D)||M(D')} LM(D)∣∣M(D′)的计算结果中 x i x_i xi服从正态分布, v i v_i vi是 v v v的分量。由于正态分布满足线性关系,可以知道 L M ( D ) ∣ ∣ M ( D ′ ) L_{M(D)||M(D')} LM(D)∣∣M(D′)服从正态分布,并且其均值为 ∣ ∣ v ∣ ∣ 2 2 2 σ 2 \frac{||v||_2^2}{2\sigma^2} 2σ2∣∣v∣∣22,方差为 ∣ ∣ v ∣ ∣ 2 2 σ 2 \frac{||v||_2^2}{\sigma^2} σ2∣∣v∣∣22。 - 计算出
L
M
(
D
)
∣
∣
M
(
D
′
)
L_{M(D)||M(D')}
LM(D)∣∣M(D′)小于
ϵ
\epsilon
ϵ的概率是
1
−
δ
1-\delta
1−δ
由第1步可知 L M ( D ) ∣ ∣ M ( D ′ ) L_{M(D)||M(D')} LM(D)∣∣M(D′)是服从均值为 ∣ ∣ v ∣ ∣ 2 2 2 σ 2 \frac{||v||_2^2}{2\sigma^2} 2σ2∣∣v∣∣22,方差为 ∣ ∣ v ∣ ∣ 2 2 σ 2 \frac{||v||_2^2}{\sigma^2} σ2∣∣v∣∣22的正态分布,因此我们可以写成: L M ( D ) ∣ ∣ M ( D ′ ) = ∣ ∣ v ∣ ∣ 2 σ 2 z + ∣ ∣ v ∣ ∣ 2 2 2 σ 2 L_{M(D)||M(D')}=\frac{||v||_2}{\sigma^2}z+\frac{||v||_2^2}{2\sigma^2} LM(D)∣∣M(D′)=σ2∣∣v∣∣2z+2σ2∣∣v∣∣22,其中 z ∼ N ( 0 , 1 ) z\sim N(0,1) z∼N(0,1), p r [ L M ( D ) ∣ ∣ M ( D ′ ) ≥ ϵ ] = p r [ ∣ z ∣ ≥ ϵ δ ∣ ∣ v ∣ ∣ 2 − ∣ ∣ v ∣ ∣ 2 2 σ ] pr[L_{M(D)||M(D')}\geq\epsilon]=pr[|z|\geq\frac{\epsilon\delta}{||v||_2}-\frac{||v||_2}{2\sigma}] pr[LM(D)∣∣M(D′)≥ϵ]=pr[∣z∣≥∣∣v∣∣2ϵδ−2σ∣∣v∣∣2],令 σ = Δ 2 t ϵ \sigma=\frac{\Delta_2t}{\epsilon} σ=ϵΔ2t,则有 p r [ ∣ z ∣ ≥ ϵ δ ∣ ∣ v ∣ ∣ 2 − ∣ ∣ v ∣ ∣ 2 2 σ ] ≤ p r [ ∣ z ∣ ≥ t − ϵ 2 t ] ≈ p r [ ∣ z ∣ ≥ t ] pr[|z|\geq\frac{\epsilon\delta}{||v||_2}-\frac{||v||_2}{2\sigma}]\leq pr[|z|\geq t-\frac{\epsilon}{2t}]\approx pr[|z|\geq t] pr[∣z∣≥∣∣v∣∣2ϵδ−2σ∣∣v∣∣2]≤pr[∣z∣≥t−2tϵ]≈pr[∣z∣≥t]根据正态分布满足 p r [ z ≥ v ] ≤ exp ( − v 2 / 2 ) pr[z\geq v]\leq \exp(-v^2/2) pr[z≥v]≤exp(−v2/2)则可以得出 σ = Δ 2 2 l o g ( 2 / δ ) ϵ \sigma=\frac{\Delta_2\sqrt{2log(2/\delta})}{\epsilon} σ=ϵΔ22log(2/δ)
有关 Δ 2 \Delta_2 Δ2
Δ 2 \Delta_2 Δ2衡量了l2-敏感度,其定义如下: f : x n → R k f:x^n\rightarrow R^k f:xn→Rk Δ 2 ( f ) = m a x x , x ′ ∣ ∣ f ( x ) − f ( x ′ ) ∣ ∣ 2 \Delta_2^{(f)}=max_{x, x'}||f(x)-f(x')||_2 Δ2(f)=maxx,x′∣∣f(x)−f(x′)∣∣2,其中 x , x ′ x,x' x,x′是邻居数据。
性质
Post processing
如果
M
:
x
n
→
y
M:x^n\rightarrow y
M:xn→y是
ϵ
\epsilon
ϵ差分隐私的,
F
:
y
→
z
F:y\rightarrow z
F:y→z是任意随机映射,那么
F
∘
M
F\circ M
F∘M满足
ϵ
\epsilon
ϵ差分隐私。证明如下:
p
r
[
F
(
M
(
x
)
)
=
t
]
p
r
[
F
(
M
(
x
′
)
)
=
t
]
=
p
r
[
M
(
x
)
∈
F
−
1
(
t
)
]
p
r
[
M
(
x
′
)
∈
F
−
1
(
t
)
]
=
∑
y
∈
F
−
1
(
t
)
p
r
[
M
(
x
)
=
y
]
∑
y
∈
F
−
1
(
t
)
p
r
[
M
(
x
′
)
=
y
]
≤
e
ϵ
\frac{pr[F(M(x))=t]}{pr[F(M(x'))=t]}=\frac{pr[M(x)\in F^{-1}(t)]}{pr[M(x')\in F^{-1}(t)]}=\frac{\sum_{y\in F^{-1}(t)} pr[M(x)=y]}{\sum_{y\in F^{-1}(t)} pr[M(x')=y]}\leq e^\epsilon
pr[F(M(x′))=t]pr[F(M(x))=t]=pr[M(x′)∈F−1(t)]pr[M(x)∈F−1(t)]=∑y∈F−1(t)pr[M(x′)=y]∑y∈F−1(t)pr[M(x)=y]≤eϵ
Group privacy
如果
M
:
x
n
→
y
M:x^n\rightarrow y
M:xn→y是
ϵ
\epsilon
ϵ差分隐私,
x
x
x和
x
′
x'
x′在第k个位置不同,那么对于所有
T
⊂
y
T\subset y
T⊂y有
p
r
[
M
(
D
)
∈
T
]
≤
exp
(
k
ϵ
)
p
r
[
M
(
D
′
)
∈
T
]
pr[M(D)\in T]\leq\exp(k\epsilon)pr[M(D')\in T]
pr[M(D)∈T]≤exp(kϵ)pr[M(D′)∈T]其证明如下:
构建一个邻居数据序列:
x
0
,
x
1
,
.
.
.
x
k
x_0,x_1,...x_k
x0,x1,...xk,依据
ϵ
\epsilon
ϵ差分隐私的性质,有:
p
r
[
M
(
x
0
)
∈
T
]
≤
p
r
[
M
(
x
1
)
∈
T
]
p
r
[
M
(
x
1
)
∈
T
]
≤
p
r
[
M
(
x
2
)
∈
T
]
.
.
.
pr[M(x_0)\in T]\leq pr[M(x_1) \in T]\\pr[M(x_1)\in T]\leq pr[M(x_2) \in T]\\...
pr[M(x0)∈T]≤pr[M(x1)∈T]pr[M(x1)∈T]≤pr[M(x2)∈T]...
连乘后得到结论
p
r
[
M
(
D
)
∈
T
]
≤
exp
(
k
ϵ
)
p
r
[
M
(
D
′
)
∈
T
]
pr[M(D)\in T]\leq\exp(k\epsilon)pr[M(D')\in T]
pr[M(D)∈T]≤exp(kϵ)pr[M(D′)∈T]
Basic composition
如果
M
M
M是一系列符合
ϵ
\epsilon
ϵ差分隐私的函数叠加,即
M
=
M
k
(
M
k
−
1
(
.
.
.
(
M
1
(
x
)
.
.
.
)
)
M=M_k(M_{k-1}(...(M_1(x)...))
M=Mk(Mk−1(...(M1(x)...))则
M
M
M满足
k
ϵ
k\epsilon
kϵ差分隐私,证明如下:
p
r
[
M
(
x
)
=
y
]
p
r
[
N
(
x
′
)
=
y
]
=
∑
y
1
+
y
2
+
.
.
.
y
k
=
y
−
h
M
(
x
)
~
∑
y
1
+
y
2
+
.
.
.
y
k
=
y
−
h
′
M
(
x
′
)
~
≤
(
e
ϵ
)
k
=
e
ϵ
k
\frac{pr[M(x)=y]}{pr[N(x')=y]}=\frac{\sum_{y_1+y_2+...y_k=y-h}\widetilde{M(x)}}{\sum_{y_1+y_2+...y_k=y-h'}\widetilde{M(x')}} \leq (e^\epsilon)^k=e^\epsilon k
pr[N(x′)=y]pr[M(x)=y]=∑y1+y2+...yk=y−h′M(x′)
∑y1+y2+...yk=y−hM(x)
≤(eϵ)k=eϵk
其中 M ( x ) ~ = p r [ M k ( y k − 1 ) = y k ∣ M k − 1 ( x ) = y k − 1 . . . ] . . . p r [ M 3 ( y 2 ) = y 3 ∣ M 2 ( y 1 ) = y 2 , M 1 ( x ) = y 1 ] p r [ M 2 ( y 1 ) = y 2 ∣ M 1 ( x ) = y 1 ] p r [ M 1 ( x ) = y 1 ] \widetilde{M(x)}=pr[M_k(y_{k-1})=y_k|M_{k-1}(x)=y_{k-1}...]...pr[M_3(y_2)=y_3|M_2(y_1)=y_2, M_1(x)=y_1]pr[M_2(y_1)=y_2|M_1(x)=y_1]pr[M_1(x)=y_1] M(x) =pr[Mk(yk−1)=yk∣Mk−1(x)=yk−1...]...pr[M3(y2)=y3∣M2(y1)=y2,M1(x)=y1]pr[M2(y1)=y2∣M1(x)=y1]pr[M1(x)=y1]
Advanced composition
从Basic composition引申,进一步缩小 ϵ \epsilon ϵ的范围,可以发现M满足 ( ϵ δ k log ( 1 / δ ) , k δ + δ ) (\epsilon\sqrt{\delta k \log(1/\delta)}, k\delta+\delta) (ϵδklog(1/δ),kδ+δ)差分隐私,即 ( ϵ k , k δ ) (\epsilon\sqrt k,k\delta) (ϵk,kδ)差分隐私
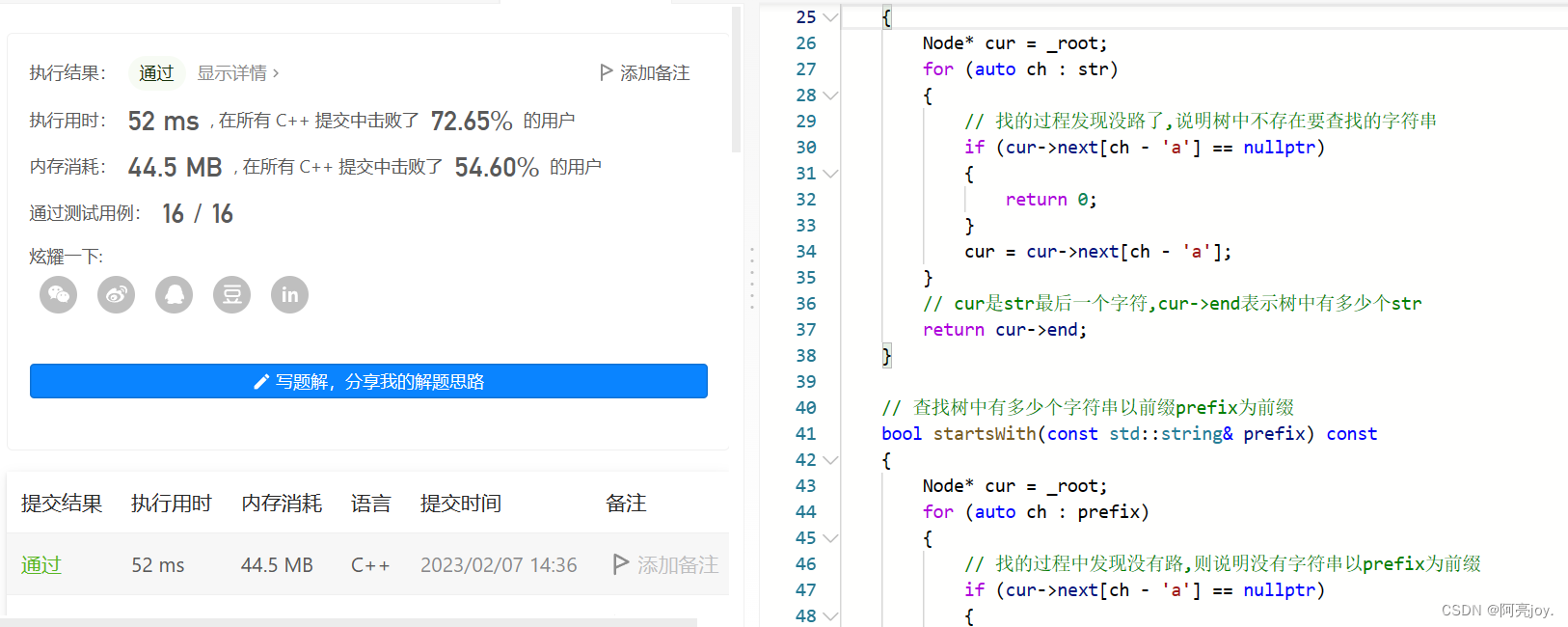



![[多线程进阶] 常见锁策略](https://img-blog.csdnimg.cn/e61a5be559734a7b805f4af11dff154e.png)