缓存 以及 缓存击穿、缓存穿透、缓存雪崩
- 1. 缓存
- 1.1 缓存的作用
- 1.2 缓存的应用场景
- 1.3 引入缓存后的执行流程
- 1.4 缓存的优点
- 2. 缓存穿透
- 2.1 场景
- 2.2 解决策略
- 1. 参数校验
- 2. 缓存空值
- 3. 缓存击穿
- 3.1 场景
- 3.2 解决策略
- 4. 缓存雪崩
- 4.1 场景
- 4.2 解决策略
- 5. 上面三者的区别
1. 缓存
1.1 缓存的作用
缓存就是一块内存,它用于存储高速交换的数据,它的使用能够提高数据交换的效率。
1.2 缓存的应用场景
当没有缓存时,程序的调用流程时这样的:

此时,对数据库来说,压力时非常大的,因为每次的查询数据都要查询数据库。那么有没有办法来减缓数据库的压力呢?肯定是有的,那就是引入缓存。
当有缓存时,程序的调用流程时这样的:
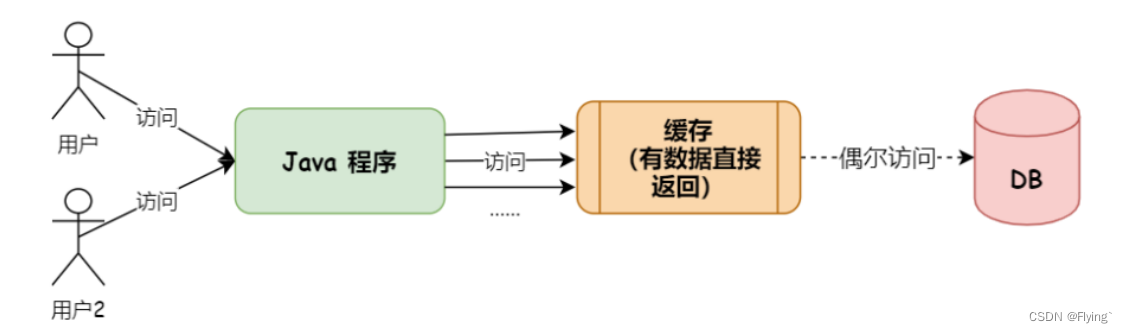
这样改造之后,程序就不会直接去查询数据库,而是先访问缓存,当缓存中没有需要的数据时,才会去查询数据库。这样的话,数据库的压力就大大减小了。
1.3 引入缓存后的执行流程
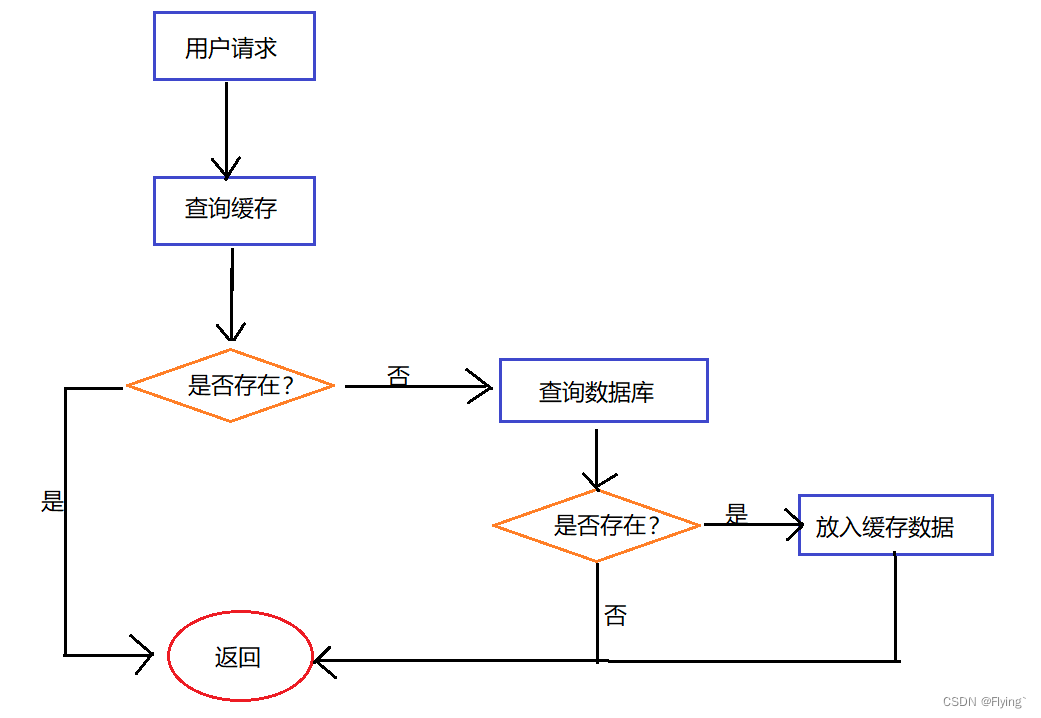
1.4 缓存的优点
- 缓存一般都是 key-value 查询数据的,因为不像数据库一样还有查询的条件等因素,所以查询的性能一般会比数据库高;
- 缓存的数据是存储在内存中的,而数据库的数据是存储在磁盘中的,因为内存的操作性能远远大于磁盘,因此缓存的查询效率会高很多;
- 缓存更容易做分布式部署(当一台服务器变成多台相连的服务器集群),而数据库一般比较难实现分布式部署,因此缓存的负载和性能更容易平行扩展和增加。
2. 缓存穿透
2.1 场景
场景1:用户请求的id不存在
场景2:用户伪造不存在的id发起请求
上面两种场景就会导致,每次都在缓存中拿不到数据,每次需要查询数据库,并且在数据库中也查不到数据。
这种场景就好像缓存被穿透了一样,每次都会访问数据库。此时就会到导致数据库的压力非常大,容易使数据库挂掉。
2.2 解决策略
1. 参数校验
对用户传送过来的数据进行校验,不符合规定,就直接将相互请求拦截掉。
-
当数据比较少时,就可将数据库中的数据全部放入内存的一个map当中。
-
当数据量比较大时,全部放入内存就不可取,此时就得使用布隆过滤器,它底层使用bit数据,数据默认值都为0
关于布隆过滤器:
- 它底层使用bit数据,数据默认值都为0
- 它在第一次初始化的时候,会把数据库中已存的key,经过一些hash的哈希算法,每个key都会计算出多个位置,然后将这些位置上的元素值设置为1。
- 之后,如果有用户请求的时候,就会使用相同的hash算法算出key对应的位置,如果多个位置中值都是1,就说明该key在数据库中存在,此时就允许后续的操作。如果有任意一个位置上的值不是1,那就说明该值在数据库中不存在,直接拒接请求
使用布隆过滤器的缺点;
- 存在误判的情况——产生hash冲突时
- 存在数据更新问题——数据库和布隆过滤器是异步同步的,当发生网络异常时,就可能导致数据不一致的问题。
2. 缓存空值
当某个key在缓存中查不到,在数据库中也查不到时,此时,将该key缓存起来,让它的value为null。当后面的请求又拿着相同的key时,就直接返回null了,无需再进行数据库的查询。
3. 缓存击穿
3.1 场景
当某一个热key到达过期时间失效后,使得大批的请求访问数据库
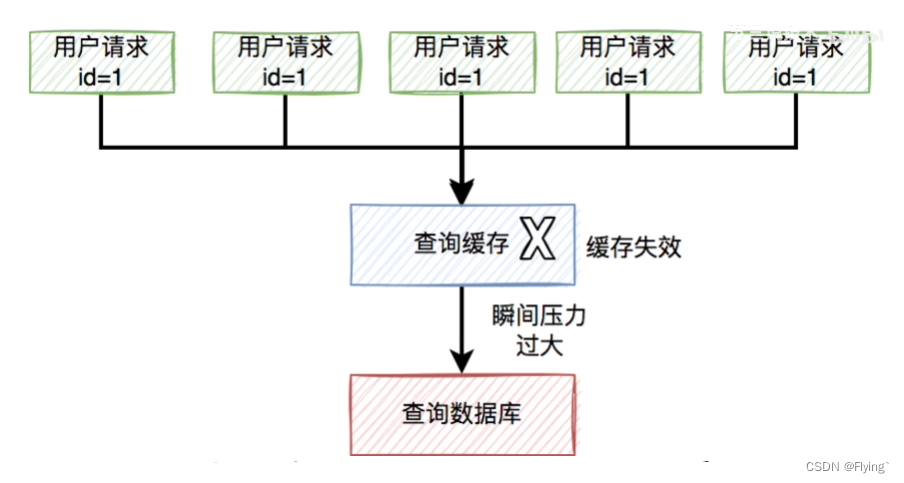
3.2 解决策略
- 通过加锁限制访问:对于同一个key,同一时刻只能有一个请求访问,访问成功后,将数据再次放入缓存当中。
- 单独设置一个job,给即将过期的热key自动续期

- 对于一些十分热的key,它的数量并不是很多,所以就可以给它们不设置过期时间,等使用完之后,手动删除掉这些热key即可
4. 缓存雪崩
4.1 场景
当某多个热key到达过期时间失效后,使得大批的请求访问数据库
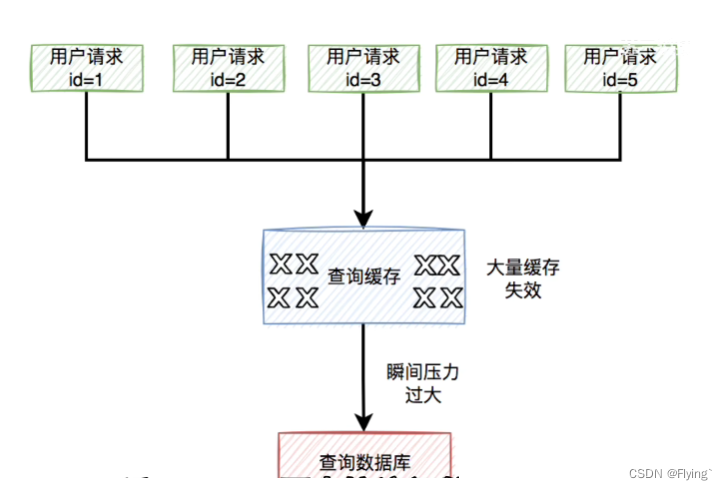
4.2 解决策略
要解决缓存雪崩,就要想办法为不同的key设置不用的过期时间
方法:在设计的过期时间的基础上加上一个160s的随机数,
即:时间过期时间 = 过期时间 + 160s的随机数
当有可能出现主机宕机的情况时:
- 如果使用的是redis,就可以使用哨兵模式或者集群模式,避免出现单节点故障而导致的整个redis拂去不可用
- 如果做了上面的处理,redis还是挂了,这是就需要做服务降级了。需要配置一些默认兜底的数据,程序中有一个默认的全局开关,比如有十个请求在最近一分钟内从redis中获取数据失败,则全局开关打开,后面的新请求就直接从配置中心获取默认的数据
5. 上面三者的区别
-
缓存穿透是说 查询不存在
-
缓存击穿、缓存雪崩是说 热key失效
-
缓存击穿是一个热key失效,缓存雪崩是多个热key失效