HashMap中为什么要使用红黑树
1. 概述
从源码的结构方面讲述下为什么HashMap要使用红黑树。那没有红黑树的时候,底层是基于什么逻辑进行存储的。
2. 底层结构
如果忽略红黑树的话,HashMap底层的数据存储结构如下:
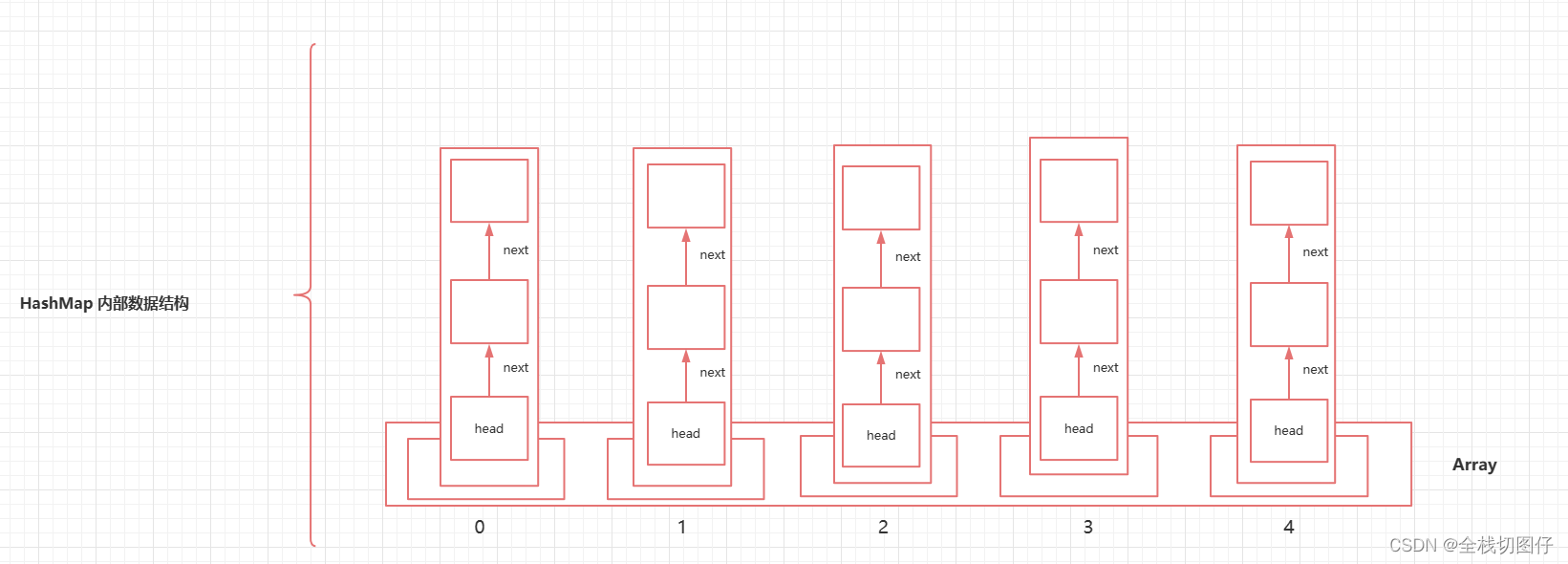
总体而言就是数组 + 链表的形式。我们可以通过hash函数来计算一个值,这个值就是数组中对应的下标。
所以HashMap的添加过程就是:
- 通过hash函数计算一个值,通过这个值结合数组的长度,按位与计算出对应数组的位置
- 如果此位置没有链表的话,直接添加节点为此链表的头节点
- 如果此位置有链表的话,比较 hash以及key,如果hash以及key保持一致,说明是更新,然后直接更新。反之继续添加到链表的尾部
这样做的目的是,能通过hash函数快速的计算数组的下标,然后遍历链表来查询。但是 链表的的时间复杂度为O(n). 最起码要遍历一遍才能找到对应的值。为什么从JDK1.8之后 引入了红黑树 呢??? 听我慢慢分解。
3. 二叉搜索树

上述的截图中就是二叉搜索树的基本特征。如果想在二叉搜索树中来寻找一个节点,时间复杂度为O(logn)。
如果将二叉搜索树的思想引入到HashMap呢??? 可以提高查询的效率,个人觉得这就是JDK1.8之后为什么引入红黑树的原理
4. 红黑树

为什么是红黑树呢,不是单纯的二叉搜索树呢???
首先我们要知道红黑树一定是一个二叉搜索树,但是如果只是二叉搜索树的话,有可能出现下面的问题:
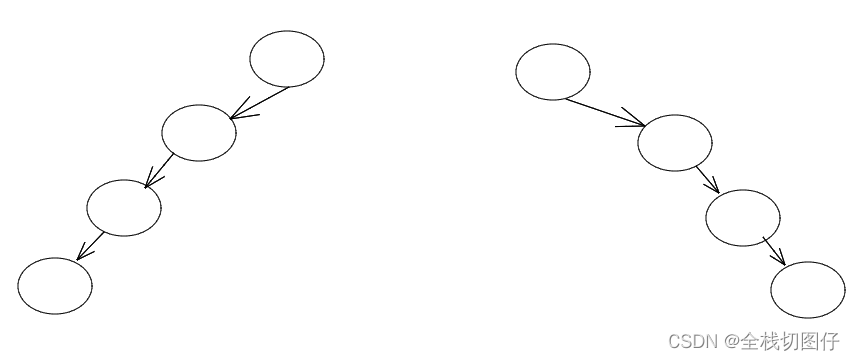
所有的节点有可能都会在一个方向。如果是这种结构的话,其实跟链表没啥区别。 所以引入了红黑树
红黑树的目的:为了让二叉树搜索树 相对平衡, 这样做可以尽最大的可能性提高查询/ 插入效率
5. 实现
在HashMap的源码中是去除链表直接使用二叉树吗??? no no no,并不是的。
下面的代码是HashMap源码中的一部分,可以看到代码中会对节点进行判断,如果是存在的节点个数 >= 7的话,才会开始转换二叉树,之前还是一直保持链表的形式。
// 一直循环添加节点
for (int binCount = 0; ; ++binCount) {
// 循环 到链表的下一个节点为null的情况
if ((e = p.next) == null) {
// 给链表的尾部 构建新的节点
p.next = newNode(hash, key, value, null);
// 如果节点个数 >= 7. 添加到第八个节点
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 此方法将链表转化为红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
本次的面试合集分享到此结束,欢迎看到的同学可以积极参加讨论,如果不对的,请即使指正。