文章目录
- 前言
- 一、性能监控概述
- 二、CPUID information
- 三、架构性能监控
- 3.1 架构性能监控 Version 1
- 3.1.1 架构性能监控 Version 1 Facilities
- 3.1.2 预定义的体系结构性能事件
- 3.1.3 cmask demo测试
- 参考资料
前言
Intel 64 和 IA-32 架构提供了 PMU(Performance Monitoring Unit:性能监控单元)设施用来监控性能。PMU 是内置于处理器内部的硬件,用于测量其性能参数,例如指令周期、高速缓存命中、高速缓存未命中、分支未命中等。性能监控事件提供了描述编程指令序列和微体系结构子系统之间交互的工具。
一些性能分析工具使用性能监控事件,它提供了基于事件的采样微架构分析类型,以了解代码如何有效地使用硬件资源,并推荐相关的优化技术。
intel_pmu插件收集由Linux perf接口提供的信息,perf接口提供了丰富的针对特定硬件功能的通用抽象。所有事件都是在每个核心基础上报告的。
性能计数器是CPU硬件寄存器,它计算硬件事件,如执行的指令、缓存丢失或分支预测错误。它们构成了分析应用程序跟踪动态控制流和识别热点的基础。
一、性能监控概述
Pentium处理器引入了性能监控通过一组 model-specific 的性能监控计数器MSRs,这些计数器允许选择要监视和测量的处理器性能参数,从这些计数器获得的信息可用于调优系统和编译器性能。
在 Intel P6 系列处理器中,性能监控机制得到了增强,允许监控更广泛的事件选择,并允许监控更多的控制事件。 接下来,基于 Intel NetBurst 微架构的 Intel 处理器引入了一种分布式的性能监控机制和性能事件。
为Pentium、P6系列和基于Intel NetBurst微架构的Intel处理器定义的性能监视机制和性能事件不是架构性的。它们都是特定于模型的(在处理器家族之间不兼容)。英特尔酷睿Solo和酷睿Duo处理器支持一组架构性能事件和一组非架构性能事件。新一代的Intel处理器支持增强的架构性能事件和非架构性能事件。
从英特尔酷睿Solo和酷睿Duo处理器开始,有两类性能监控功能:
第一个类支持使用计数或基于中断的事件抽样使用来监控性能的事件。这些事件是非体系结构的,并且因处理器模型的不同而不同。它们类似于Pentium M处理器中的那些。这些非体系结构性能监视事件特定于微体系结构,并可能随着增强而改变。
第二类性能监视功能称为体系结构性能监视。这个类支持相同的计数和基于中断的事件采样用法,使用更小的可用事件集。架构性能事件的可见行为在处理器实现中是一致的。架构性能监视功能的可用性是使用CPUID.0AH枚举的。这些事件将在第二节中讨论。
二、CPUID information
CPUID.EAX = 0AH (* Returns Architectural Performance Monitoring leaf. *)
当 CPUID 在 EAX 设置为 0AH 的情况下执行时,处理器会返回有关支持架构性能监视功能的信息。 version ID大于0 支持架构性能监控:

对于架构性能监控功能的每个版本,软件必须枚举 leaf 以发现处理器中可用的编程工具和架构性能事件。
三、架构性能监控
当性能监视事件跨微架构表现一致时,它们就是架构性的。英特尔酷睿Solo和酷睿Duo处理器引入了架构性能监控。该特性为软件提供了枚举性能事件的机制,并为事件提供了配置和计数功能。
架构性能监视确实允许跨处理器实现的增强。The CPUID.0AH leaf 为每个增强提供版本号。英特尔酷睿Solo和酷睿Duo处理器支持版本号为1的基本功能。基于Intel Core微架构的处理器,至少支持底层架构的性能监控功能。英特尔酷睿2双核处理器t7700和基于英特尔酷睿微架构的新处理器都支持基本功能和增强的架构性能监控(版本号为2)。
45 nm和32 nm Intel Atom处理器以及基于Silvermont微架构的Intel Atom处理器支持versionID 1、2和3所提供的功能;CPUID.0AH:EAX[7:0]报告versionID = 3,表示体系结构性能监控能力的总和。基于Airmont微架构的Intel Atom处理器支持与基于Silvermont微架构的处理器相同的性能监控能力。基于Goldmont和Goldmont Plus微架构的Intel Atom处理器支持versionID 4。从基于Tremont微架构的处理器开始的英特尔Atom处理器支持versionID 5。
基于Nehalem through Broadwell微架构的Intel Core处理器和相关的Intel Xeon处理器家族支持ID 3版本。基于Skylake到Coffee Lake微架构的英特尔处理器支持versionID 4。从基于Ice Lake微架构的处理器开始的英特尔处理器支持versionID 5
我这里只介绍英特尔处理器支持版本号为1的基本功能。
3.1 架构性能监控 Version 1
配置体系结构性能监视事件涉及编程性能事件选择寄存器。性能事件选择MSRs的数量有限(IA32_PERFEVTSELx MSRs)。性能监控事件的结果在性能监控指标(IA32_PMCx MSR)中上报。性能监视计数器与性能监视选择寄存器配对。
性能监控选择寄存器和计数器在以下方面具有架构性:
(1)IA32_PERFEVTSELx的位域布局在微架构中是一致的。
(2)在微架构中,IA32_PERFEVTSELx msr的地址保持不变。
(3)在微架构中,IA32_PMC msr的地址保持不变。
(4)每个逻辑处理器都有自己的一组IA32_PERFEVTSELx和IA32_PMCx msr。共享处理器核心的逻辑处理器之间不共享配置工具和计数器。
架构性能监控提供了一种 CPUID 机制,用于枚举以下信息:
(1) 逻辑处理器中软件可用的性能监控计数器的数量(每个 IA32_PERFEVTSELx MSR 与相应的 IA32_PMCx MSR 配对)。
(2)每个 IA32_PMCx 支持的位数。
(3) 逻辑处理器中支持的架构性能监控事件的数量。
软件可以使用 CPUID 来发现架构性能监控可用性 (CPUID.0AH)。 架构性能监控叶提供与处理器中可用的架构性能监控的版本号相对应的标识符。
在架构性能监控的初始实施中; 软件可以确定每个内核支持多少 IA32_PERFEVTSELx/ IA32_PMCx MSR 对、PMC 的位宽以及可用的架构性能监控事件的数量。
3.1.1 架构性能监控 Version 1 Facilities
架构性能监控工具包括一组性能监控计数器和性能事件选择寄存器。 这些 MSR 具有以下属性:
(1)IA32_PMCx MSR 从地址 0C1H 开始,占用 MSR 地址空间的连续块; 使用 CPUID.0AH:EAX[15:8] 报告每个逻辑处理器的 MSR 数量。 请注意,这可能与硬件上存在的物理计数器的数量不同,因为以更高权限级别(例如,VMM)运行的代理可能不会公开所有计数器。
(2)IA32_PERFEVTSELx MSR 从地址 186H 开始并占用 MSR 地址空间的一个连续块。 每个性能事件选择寄存器都与 0C1H 地址块中的相应性能计数器配对。请注意,IA32_PERFEVTSELx MSR 的数量可能与硬件上存在的物理计数器的数量不同,因为以更高权限级别(例如,VMM)运行的代理可能不会公开所有计数器。
(3)IA32_PMCx MSR 的位宽使用 CPUID.0AH:EAX[23:16] 报告。 这是读取操作的有效位数。 在写操作中,MSR 的低 32 位可以写入任意值,高位从第 31 位的值进行符号扩展。
(4)IA32_PERFEVTSELx MSR 的位域布局是在架构上定义的。
有关 IA32_PERFEVTSELx MSR 的位域布局,请参考下图。 位字段是:
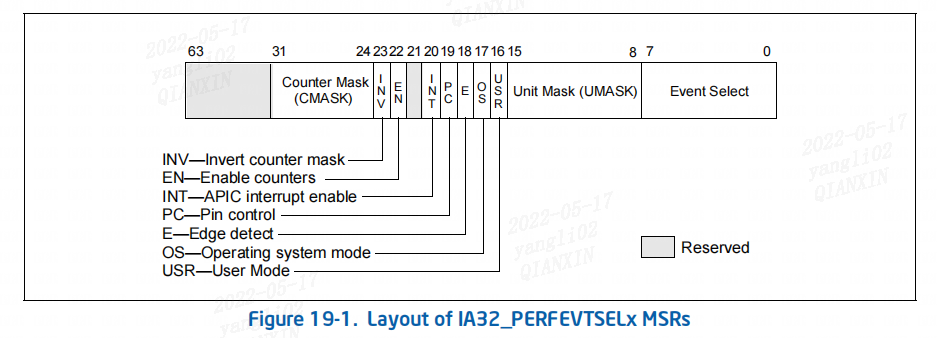
(1)Event select field (bits 0 through 7):选择用于检测微体系结构条件的事件逻辑单元。 该字段的值集是在架构上定义的; 每个值对应一个事件逻辑单元,用于架构性能事件。 使用 CPUID.0AH:EAX 查询架构事件的数量。 处理器可能仅支持预定义值的子集。
(2)Unit mask (UMASK) field (bits 8 through 15):这些位限定所选事件逻辑单元检测到的条件。 每个事件逻辑单元的有效 UMASK 值特定于该单元。 对于每个架构性能事件,其对应的 UMASK 值定义了特定的微架构条件。
(3)USR (user mode) flag (bit 16):指定当逻辑处理器以特权级别 1、2 或 3 运行时计算选定的微体系结构条件。此标志可与 OS 标志一起使用。
(4)OS (operating system mode) flag (bit 17):指定当逻辑处理器以特权级别 0 运行时计算选定的微体系结构条件。此标志可与 USR 标志一起使用。
(5)E (edge detect) flag (bit 18):启用(设置时)所选微架构条件的边缘检测。对于可以由其他字段表示的任何条件,逻辑处理器计算 deasserted to asserted 转换的次数。该机制不允许区分 back-to-back assertions。
这种机制使软件不仅可以测量在特定状态下花费的时间比例,还可以测量在这种状态下花费的平均时间长度(例如,等待中断服务所花费的时间)。
(6)PC (pin control) flag (bit 19):从 Sandy Bridge 微架构开始,该位被保留(不可写)。 在基于先前微架构的处理器上,逻辑处理器切换 PMi 引脚并在性能监控事件发生时递增计数器; 当清零时,处理器在计数器溢出时切换 PMi 引脚。引脚的切换定义为对单个总线时钟的引脚assertion,然后 deassertion。
(7)INT (APIC interrupt enable) flag (bit 20):设置后,逻辑处理器在计数器溢出时通过其本地 APIC 生成异常。
(8)EN (Enable Counters) Flag (bit 22):设置后,在相应的性能监控计数器中启用性能计数; 当清零时,相应的计数器被禁用。 在写入 IA32_PMCx 之前,必须通过设置 IA32_PERFEVTSELx[bit 22] = 0 来禁用 UMASK 的事件逻辑单元。
(9)INV (invert) flag (bit 23):设置后,反转 counter-mask (CMASK) 比较,以便可以进行大于或等于和小于比较(0:大于或等于;1:小于)。 请注意,如果 counter-mask被编程为零,则忽略 INV 标志。
(10)Counter mask (CMASK) field (bits 24 through 31):当此字段不为零时,逻辑处理器将此掩码与在单个周期内检测到的微体系结构条件的事件计数进行比较。 如果事件计数大于或等于此掩码,则计数器加一。 否则计数器不会增加。
此掩码旨在用于软件来描述可以计算每个周期多次出现的微架构条件(例如,每个时钟退出两条或更多条指令;或总线队列占用)如果counter-mask字段为 0,则计数器在每个周期增加与多次发生相关的事件计数。
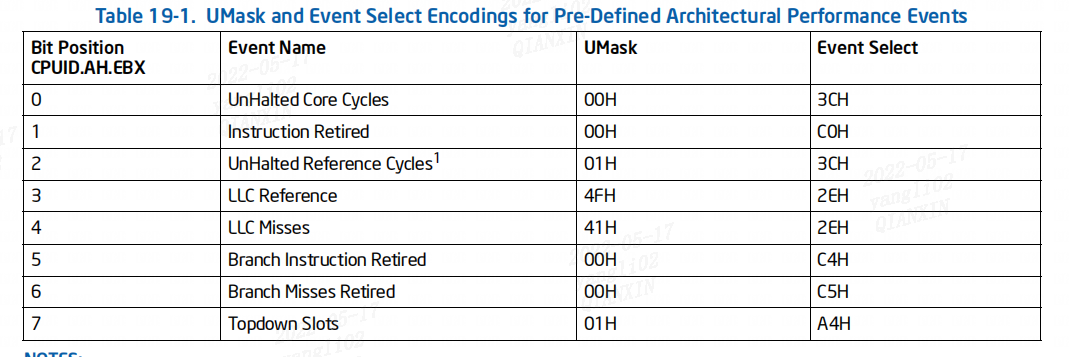
3.1.2 预定义的体系结构性能事件
下表列出了架构定义的事件:
[root@localhost ~]# cat /sys/devices/cpu/events/
branch-instructions bus-cycles cache-references instructions mem-stores
branch-misses cache-misses cpu-cycles mem-loads ref-cycles
[root@localhost ~]# cat /sys/devices/cpu/events/cpu-cycles
event=0x3c
[root@localhost ~]# cat /sys/devices/cpu/events/branch-misses
event=0xc5
[root@localhost ~]# cat /sys/devices/cpu/events/branch-instructions
event=0xc4
支持架构性能监控的处理器可能不支持所有预定义的架构性能事件,架构事件的数量通过CPUID.0AH:EAX[31:24] 说明,而 CPUID.0AH:EBX 中的非零位表示任何不可用的架构事件。每个体系结构性能事件的行为预计在支持该事件的所有处理器上都是一致的。
所涉及名词解释:
retired :消耗(指令的消耗数目),对于包含多个微操作(micro-op)的指令,其只对最后一个微操作的指令引退进行计数,即只计数一次。
at retirement (指令)引退。
微架构之间的细微差异如下所示:
(1)UnHalted Core Cycles — Event select 3CH, Umask 00H
当特定内核上的时钟信号正在运行(未停止)时,此事件计算内核时钟周期。 在以下情况下,计数器不会前进:
— an ACPI C-state other than C0 for normal operation
— HLT
— STPCLK# pin asserted
— being throttled by TM1
— during the frequency switching phase of a performance state transition (see Chapter 14, “Power and
Thermal Management”)
此事件的性能计数器计算使用不同内核时钟频率的性能状态转换。
(2)Instructions Retired — Event select C0H, Umask 00H
此事件计算指令引退时的指令数。 对于由多个微操作组成的指令,此事件计算指令的最后一个微操作的退出。 带有 REP 前缀的指令算作一条指令(不是每次迭代)。 多操作指令的最后一个微操作退出之前的故障不计算在内。
此事件在 VM 退出条件下不会增加。 计数器在硬件中断、陷阱和内部中断处理程序期间继续计数
(3)UnHalted Reference Cycles — Event select 3CH, Umask 01H
此事件在内核上的时钟信号运行时以固定频率计算参考时钟周期。 事件以固定频率计数,与性能状态转换导致的核心频率变化无关。 处理器可能会以不同的方式实现此行为。 当前的实现使用核心晶体时钟、TSC 或总线时钟。 由于实现之间的速率可能不同,因此软件应将其校准为具有已知频率的时间源。
(4)Last Level Cache References — Event select 2EH, Umask 4FH
此事件对源自内核的请求计数,这些请求引用最后一级片上高速缓存中的高速缓存行。 事件计数包括由于一级缓存硬件预取器导致的推测和缓存行填充,但可能不包括由于其他硬件预取器导致的缓存行填充。
因为缓存层次结构、缓存大小和其他特定于实现的特性; 不建议通过值比较来估计性能差异。
(5)Last Level Cache Misses — Event select 2EH, Umask 41H
此事件计算对最后一级片上缓存的引用的每个缓存未命中情况。 事件计数可能包括由于一级缓存硬件预取器导致的推测和缓存行填充,但可能不包括由于其他硬件预取器导致的缓存行填充。
因为缓存层次结构、缓存大小和其他特定于实现的特性; 不建议通过值比较来估计性能差异。
(6)Branch Instructions Retired — Event select C4H, Umask 00H
此事件计算指令引退时的分支指令。 它计算分支指令的最后一个微操作的退出。
(7)All Branch Mispredict Retired — Event select C5H, Umask 00H
此事件在指令引退时计算错误预测的分支指令,它计算架构执行路径中分支指令的最后一个微操作的退出以及在分支预测硬件中经历的错误预测。
分支预测硬件在微架构中是特定于实现的; 不建议通过值比较来估计性能差异。
(8)Topdown Slots — Event select A4H, Umask 01H
此事件计算未暂停逻辑处理器的可用插槽( slots)总数。
自顶向下微体系结构分析方法(Top-down Microarchitecture Analysis method)所采用的 the narrowest pipeline 的机器宽度增加事件。该计数分布在支持英特尔超线程技术的处理器中共享相同物理核心的未停止逻辑处理器(超线程)之间。
软件可以将此事件用作自顶向下微体系结构分析方法的顶级指标的统计基准(denominator)。
其中各个事件的值计算在Linux内核源码中的计算:
#define ARCH_PERFMON_EVENTSEL_EVENT 0x000000FFULL
#define ARCH_PERFMON_EVENTSEL_UMASK 0x0000FF00ULL
#define ARCH_PERFMON_EVENTSEL_USR (1ULL << 16)
#define ARCH_PERFMON_EVENTSEL_OS (1ULL << 17)
#define ARCH_PERFMON_EVENTSEL_EDGE (1ULL << 18)
#define ARCH_PERFMON_EVENTSEL_PIN_CONTROL (1ULL << 19)
#define ARCH_PERFMON_EVENTSEL_INT (1ULL << 20)
#define ARCH_PERFMON_EVENTSEL_ANY (1ULL << 21)
#define ARCH_PERFMON_EVENTSEL_ENABLE (1ULL << 22)
#define ARCH_PERFMON_EVENTSEL_INV (1ULL << 23)
#define ARCH_PERFMON_EVENTSEL_CMASK 0xFF000000ULL
#define X86_RAW_EVENT_MASK \
(ARCH_PERFMON_EVENTSEL_EVENT | \
ARCH_PERFMON_EVENTSEL_UMASK | \
ARCH_PERFMON_EVENTSEL_EDGE | \
ARCH_PERFMON_EVENTSEL_INV | \
ARCH_PERFMON_EVENTSEL_CMASK)
ssize_t x86_event_sysfs_show(char *page, u64 config, u64 event)
{
u64 umask = (config & ARCH_PERFMON_EVENTSEL_UMASK) >> 8;
u64 cmask = (config & ARCH_PERFMON_EVENTSEL_CMASK) >> 24;
bool edge = (config & ARCH_PERFMON_EVENTSEL_EDGE);
bool pc = (config & ARCH_PERFMON_EVENTSEL_PIN_CONTROL);
bool any = (config & ARCH_PERFMON_EVENTSEL_ANY);
bool inv = (config & ARCH_PERFMON_EVENTSEL_INV);
......
}
PMU_FORMAT_ATTR(event, "config:0-7" );
PMU_FORMAT_ATTR(umask, "config:8-15" );
PMU_FORMAT_ATTR(edge, "config:18" );
PMU_FORMAT_ATTR(pc, "config:19" );
PMU_FORMAT_ATTR(any, "config:21" ); /* v3 + */
PMU_FORMAT_ATTR(inv, "config:23" );
PMU_FORMAT_ATTR(cmask, "config:24-31" );
static struct attribute *intel_arch_formats_attr[] = {
&format_attr_event.attr,
&format_attr_umask.attr,
&format_attr_edge.attr,
&format_attr_pc.attr,
&format_attr_inv.attr,
&format_attr_cmask.attr,
NULL,
};
3.1.3 cmask demo测试
写一个内核模块测试一台intel处理器所预定义的架构性能事件数目:
#include <linux/kernel.h>
#include <linux/module.h>
unsigned int pmu_mask(unsigned int sig)
{
unsigned int mask;
mask = (sig >> 24) & 0xff;
return mask;
}
//内核模块初始化函数
static int __init lkm_init(void)
{
unsigned int eax = 0;
unsigned int ebx = 0;
unsigned int ecx = 0;
unsigned int edx = 0;
unsigned int cmask = 0;
cpuid(0x0a, &eax, &ebx, &ecx, &edx);
cmask = pmu_mask(eax);
printk("cmask = %d\n", cmask);
return 0;
}
//内核模块退出函数
static void __exit lkm_exit(void)
{
printk(KERN_DEBUG "exit\n");
}
module_init(lkm_init);
module_exit(lkm_exit);
MODULE_LICENSE("GPL");
root@localhost intel_pmu]# dmesg -c
[13670.361813] cmask = 7
虽然有很多PMC,但Intel选择了七个作为“架构集”(这里没有包括Topdown Slots架构性能事件),这些架构集提供了一些核心功能的高级概述。
参考资料
Linux 3.10.0
intel v3