文章目录
- 前言
- SIMD & NEON
- NEON intrinsics
- NEON intrinsics 学习资料
- 寄存器
- 向量数据类型
- NENO intrinsics 命名方式
- NEON Intrinsics 查询
- 三种处理方式:Long/Wide/Narrow
- NENO intrinsics 手册
- Addition 向量加法
- Vector add: vadd{q}_type. Vr[i]:=Va[i]+Vb[i]
- Vector long add: vaddl_type. Vr[i]:=Va[i]+Vb[i]
- Vector wide add: vaddw_type. Vr[i]:=Va[i]+Vb[i]
- Vector halving add: vhadd{q}_type. Vr[i]:=(Va[i]+Vb[i])>>1
- Vector rounding halving add: vrhadd{q}_type. Vr[i]:=(Va[i]+Vb[i]+1)>>1
- VQADD: Vector saturating add
- Vector add high half: vaddhn_type.Vr[i]:=Va[i]+Vb[i]
- Vector rounding add high half: vraddhn_type.
- Multiplication 向量乘法
- Vector multiply: vmul{q}_type. Vr[i] := Va[i] * Vb[i]
- Vector multiply accumulate: vmla{q}_type. Vr[i] := Va[i] + Vb[i] * Vc[i]
- Vector multiply accumulate long: vmlal_type. Vr[i] := Va[i] + Vb[i] * Vc[i]
- Vector multiply subtract: vmls{q}_type. Vr[i] := Va[i] - Vb[i] * Vc[i]
- Vector multiply subtract long
- Vector saturating doubling multiply high
- Vector saturating rounding doubling multiply high
- Vector saturating doubling multiply accumulate long
- Vector saturating doubling multiply subtract long
- Vector long multiply
- Vector saturating doubling long multiply
- Subtraction 向量减法
- Vector subtract
- Vector long subtract: vsubl_type. Vr[i]:=Va[i]-Vb[i]
- Vector wide subtract: vsubw_type. Vr[i]:=Va[i]-Vb[i]
- Vector saturating subtract
- Vector halving subtract
- Vector subtract high half
- Vector rounding subtract high half
- Comparison 向量比较
- [Absolute difference](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Absolute-difference?lang=en) 绝对差值
- Absolute difference between the arguments: vabd{q}_type. Vr[i] = | Va[i] - Vb[i] |
- Absolute difference and accumulate: vaba{q}_type. Vr[i] = Va[i] + | Vb[i] - Vc[i] |
- Max/Min 向量最大/最小
- vmax{q}_type. Vr[i] := (Va[i] >= Vb[i]) ? Va[i] : Vb[i]
- vmin{q}_type. Vr[i] := (Va[i] >= Vb[i]) ? Vb[i] : Va[i]
- [Pairwise addition](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Pairwise-addition?lang=en) 成对的加法
- Pairwise add
- Long pairwise add and accumulate
- [Folding maximum](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Folding-maximum?lang=en)
- [Folding minimum](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Folding-minimum?lang=en)
- Reciprocal/Sqrt
- [Shifts by signed variable](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Shifts-by-signed-variable?lang=en) 根据变量值移位
- Vector shift left: vshl{q}_type. Vr[i] := Va[i] << Vb[i] (negative values shift right)
- [Shifts by a constant](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Shifts-by-a-constant?lang=en) 常数移位
- Vector shift right by constant
- Vector shift left by constant
- Vector shift right by constant and accumulate
- [Shifts with insert](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Shifts-with-insert?lang=en) 移位且插入
- Vector shift right and insert
- [Loads of a single vector or lane](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Loads-of-a-single-vector-or-lane?lang=en) 向量加载与存储
- Load a single vector from memory
- Load a single lane from memory
- Load all lanes of vector with same value from memory
- [Store a single vector or lane](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Store-a-single-vector-or-lane?lang=en)
- Store a single vector into memory
- Store a lane of a vector into memory
- [Loads of an N-element structure](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Loads-of-an-N-element-structure?lang=en)
- Load N-element structure from memory
- Load all lanes of N-element structure with same value from memory
- Load a single lane of N-element structure from memory
- Store N-element structure to memory
- Store a single lane of N-element structure to memory
- [Extract lanes from a vector and put into a register](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Extract-lanes-from-a-vector-and-put-into-a-register?lang=en)
- [Load a single lane of a vector from a literal](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Load-a-single-lane-of-a-vector-from-a-literal?lang=en)
- [Initialize a vector from a literal bit pattern](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Initialize-a-vector-from-a-literal-bit-pattern?lang=en)
- [Set all lanes to same value](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Set-all-lanes-to-same-value?lang=en)
- Load all lanes of vector to the same literal value
- Load all lanes of the vector to the value of a lane of a vector
- [Combining vectors](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Combining-vectors?lang=en) 合并向量
- [Splitting vectors](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Splitting-vectors?lang=en) 分解向量
- [Converting vectors](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Converting-vectors?lang=en) 向量类型转换
- [Table look up](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Table-look-up?lang=en) 查表
- [Operations with a scalar value](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Operations-with-a-scalar-value?lang=en)
- Vector multiply accumulate with scalar
- Vector multiply by scalar
- Vector multiply subtract with scalar
- [Vector extract](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Vector-extract?lang=en) 向量提取
- [Reverse vector elements (swap endianness)](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Reverse-vector-elements--swap-endianness-?lang=en)
- [Other single operand arithmetic](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Other-single-operand-arithmetic?lang=en)
- Absolute: vabs{q}_type. Vd[i] = |Va[i]|
- Negate: vneg{q}_type. Vd[i] = - Va[i]
- Count leading sign bits
- Count leading zeros
- Count number of set bits
- Reciprocal estimate
- Reciprocal square root estimate
- [Logical operations](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Logical-operations?lang=en) 逻辑操作
- Bitwise not
- Bitwise and
- Bitwise or
- Bitwise exclusive or (EOR or XOR)
- Bit Clear
- Bitwise OR complement
- [Transposition operations](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Transposition-operations?lang=en)
- Transpose elements
- Interleave elements
- De-Interleave elements
- [Vector reinterpret cast operations](https://developer.arm.com/documentation/dui0491/i/Using-NEON-Support/Vector-reinterpret-cast-operations?lang=en)
- 总结
- 参考
前言
本文旨在向 NEON 新手提供入门指导,以便能够快速入门 NEON。NEON 作为一种底层的技术,学习曲线相当陡峭,本教程将扫平你在入门期间的各类疑问,并结合大量习题让你能够真正的入门 NEON。
SIMD & NEON
SIMD(Single Instruction,Multiple Data)即单指令多数据。简而言之,它是对指令集的一种扩展,可以对多个数值进行相同操作。
NEON 是指适用于 Arm Cortex-A系列处理器的一种高级 SIMD(单指令多数据)扩展指令集。
我为什么要学习 NEON,原因有:
- 本人熟悉的音频 DSP 算法,可以通过 SIMD 技术进行加速,使其性能提升
- ARM 架构在移动端(Android/iOS 等)设备上已经是统治级别,如果想让这些算法在移动端上有更好的表现,那么就必须学习 NEON
- SIMD 技术很酷,通过 NEON 我可以了解到 SIMD 的编程范式。学习一样新东西,本身就很有趣。
NEON intrinsics
那么我们如何才能使用上 NEON 呢?你可以在 C/C++ 代码中嵌入 NEON 汇编代码,这种方式难度非常高,你需要对寄存器、汇编等技术很熟悉,对于新手简直是劝退。幸运的是,你还有 NEON intrinsics 可以选择。
NEON intrinsics 其实就是一组 c 函数,你可以通过调用它们来实现 SIMD,让你的算法更加高效。作为新手,我们以 NEON intrinsics 为入口,一起来窥探 SIMD 奇妙的世界是非常合适的。
经过对 NEON intrinsics 一段时间的学习,大致掌握了 NEON intrinsics 一些基本使用,于是乎赶紧总结一下,防止日后忘记,同时也给各位看官作为学习的参考。
NEON intrinsics 学习资料
推荐几个自己在学习过程中找到的不错的资料。
- Learn the architecture - Optimizing C code with Neon intrinsics,推荐第一个读它,内容较少,语言精练。如果你对其中一些知识点不太清楚,没有关系,通读我这篇博客,相信能够轻松解决你的疑问。
- Learn the architecture - Neon programmers’ guide,在「Introduction」部分对 SIMD&NEON 原理做了很详细的介绍,对寄存器也做了说明;「NEON Intrinsics」章节介绍了很多 NEON Intrinsics 用法;中文翻译版本在 NEON码农指导 Chapter 1 : Introduction
- ARM Compiler toolchain Compiler Reference Version 5.03,其中 「Using NEON Support」非常详细,对 NEON Intrinsics 做了详细的分类和总结,推荐阅读。
- ARM NEON for C++ Developers,相当详细地介绍了 NEON Intrinsics 各种用法。
- neon-guide,简要的 neon 教程,内容简练。
寄存器
SIMD 提速的原理在于寄存器,在 Introducing NEON Development Article 中提到:
一些现代软件,尤其是多媒体编解码软件和图形加速软件,有大量的少于机器字长的数据参与运算。例如,在音频应用中16位以内数据是频繁的,在图形与视频领域8位以内数据是频繁的。
当在32位微处理器上执行这些操作时,相当一部分计算单元没有被利用,但是依然消耗着计算资源。为了更好的利用这部分闲置的资源,SIMD技术使用一个单指令来并行地在同样类型和大小的多个数据元素上执行相同的操作。通过这种方法,硬件可以在同样时间消耗内用并行的4个8位数值加法运算来替代通常的两个32位数值加法运算。
在 Arm NEON programming quick reference 和 Learn the architecture - Neon programmers’ guide 中对 ARM 架构的寄存器做了较为详细的介绍。总结起来为:
- Armv7-A/AArch32
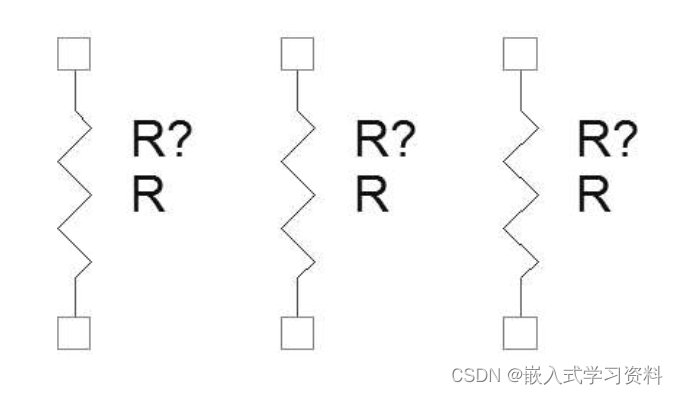
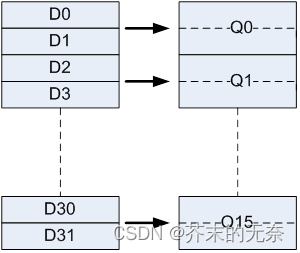
- 有 16 个 32bit 的通用寄存器(R0-R15)
- 有 32 个 64bit 的 NEON 寄存器(D0-D31);它们也可以被看成是 16 个 128bit NEON 寄存器(Q0-Q15);每个 Q 寄存器对应两个 D 寄存器,匹配关系如下图
- Armv8/AArch64
- 有 31 个 64bit 的通用寄存器(X0-X30);此外还有上一个特殊的寄存器,该寄存器的名字取决于当前运行环境
- 有 32 个 128bit 的 NEON 寄存器(V0-V31);它们也可以被看成是 32bit 的 Sn 寄存器或者 64bit 的 Dn 寄存器

向量数据类型
在 NEON 中有非常多向量数据类型,具体的列表你可以在 Vector data types 中找到。
它们有着统一的命名范式规则:
<type><size>x<number of lanes>_t
- type,向量中存放数据的类型,包括:
- int,有符号整形
- uint,无符号整形
- float,浮点
- poly,关于这种类型的介绍,请参考 这里
- size,即 type 的 bit 长度,例如 float32,表示 32 bit 的 float 类型、int64 表示 64bit 的 int,以此类推
- number of lanes,通道数,即有多少个数据,例如 float32x4_t,有 4 个 float32
其实这些向量数据类型,你可以认为就是一个数组,类比到 c++ 中的std::array,例如
int16x8_t < == > std::array<int16_t, 8>
uint64x2_t < == > std::array<int64_t, 2>
float32x4_t < == > std::array<float, 4>
这些数据类型是为了填满一个寄存器的,所以它们总的 bit 长度要么是 64 或者 128。假设一个 float32x4_t 的向量,其值为 {0, 1, 2, 3},那么它们在寄存器总存放的顺序如下图:

你可以像获取数组中的值一样来获取这些向量里的值,例如:
float32x4_t a{1.0, 2.0, 3.0f, 4.0};
printf("%lf %lf %lf %lf\n", a[0], a[1], a[2], a[3]);
至于 Lanes ,我们可以理解为数组下标,在后面的 NEON intrinsics 函数介绍中你经常会看到 lanes 这个词。
NENO intrinsics 命名方式
前面提到 NENO intrinsics 其实就是一堆的 C 函数,作为新手,我第一次看到这些函数的时候是有点懵的,因为它们的命名方式过于抽象了,需要经过一些查询才能大致得知其意思。其大致符合这样的规则:
<opname><flags>_<type>
举几个例子:
- vmul_s16,将两个 s16 的向量相乘
- vaddl_u8,将两个 u8 的向量相加
在 Program-conventions 介绍了更加详细的规则,令人眼花缭乱。了解命名规则有助于我们快速理解 intrinsic 的含义,但作为新人我觉得不必要过于纠结,我们完全可以通过对 intrinsics doc 进行查询,快速的掌握这些神奇函数的性质。至于命名规则,你用熟了、看多了,自然也能猜到一二。
NEON Intrinsics 查询
你可以登入 Intrinsics 进行查询。那么如何看懂查询的结果呢?这里说一下自己的经验。
对于一个函数,我们在意的内容包括:
- 输入是什么?即参数有哪些。
- 输出时什么?即返回的数据类型是怎么样的。
- 函数的行为是怎样的?即函数做了哪些操作。
以 vaddq_f32 为例,查询结果如下图。我们对照着该图做

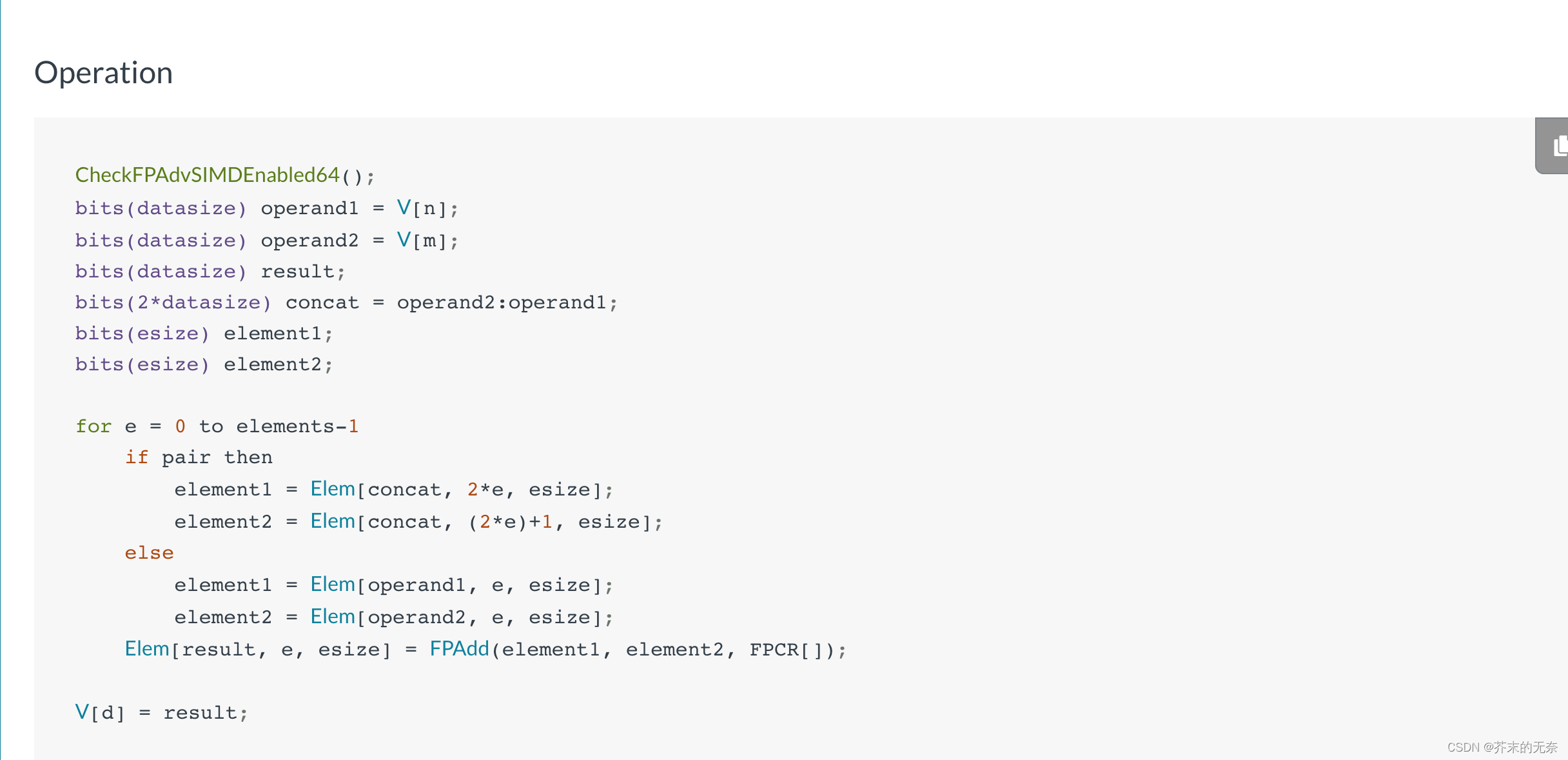
- Arguments,参数是两个
float32x4_t,分别是a和b - Return Type,返回一个
float32x4_t - Description,描述了该函数的行为:“Floating-point Add (vector). 这条指令将两个源SIMD&FP寄存器中相应的向量元素相加,将结果写入向量中,并将向量写入目标SIMD&FP寄存器。这条指令中所有的值都是浮点值。”
- Instruction Group,所属类别
- This intrinsic compiles to the following instructions,该函数将被编译成如下指令:
FADD Vd.4S,Vn.4S,Vm.4S。即对 Vm 和 Vn 寄存器中 4 个 float 做 FADD 操作,然后将结果存放在 Vd 中 - Argument Preparation,参数
a放在 Vn 寄存器,参数b放在 Vm 寄存器中 - Architectures,该函数在 v7、A32、A64 架构下可用
- Operation,即该指令的具体操作,你通过这部分内容可以大致的了解指令的算法流程,它类似伪代码,并不难理解。在遇到一些奇怪的指令时,仅仅通过 Description 可能无法知晓它的作用,这时候你可以来看 Operation。
三种处理方式:Long/Wide/Narrow
NEON 指令通常有 Normal、Long、Wide 和 Narrow 之分。
- Normal,指令的输入与输出数据有相同 bit 宽度,例如
vaddq_f32,结果为float32x4_t,输出为float32x4_t,都是 128-bit。 - Long,指令对 64-bit 数据进行操作,产生 128-bit 向量结果,结果宽度是输入的两倍,并且类型相同。此类指令在 NEON Intrinsics 中通过 “l” 来标识,例如
vaddl_s32,输入为int32x2_t,输出为int64x2_t。 - Wide,指令对一个 128-bit 向量和一个 64-bit 向量进行操作,产生一个 128-bit 向量结果。结果和第一输入向量是第二输入向量的两倍宽度。此类指令在 NEON Intrinsics 中通过 “w” 来标识,例如
vaddw_s32,输入为int64x2_t和int32x2_t,输出为int64x2_t。 - Narrow,指令对 128-bit 向量进行操作,产生一个 64-bit 的结果,结果宽度是输入的一半。此类指令在 NEON Intrinsics 中通过 “n” 来标识,例如
vaddhn_s32,输入为int32x4_t,输出为int16x4_t。
NENO intrinsics 手册
在 ARM Compiler toolchain Compiler Reference Version 5.03 中对 intrinsic 做了详细的分类。本章将对各个类别的函数举例说明,帮助大家理解。
所有代码你可以直接在 Compiler Explorer 在线编辑器中运行,选择 ‘arm64’ 编译器且引入 <arm_neon.h> 即可。
Addition 向量加法
Vector add: vadd{q}_type. Vr[i]:=Va[i]+Vb[i]
c = a + b
- vaddq_f32
float32x4_t a{1.0, 2.0, 3.0f, 4.0};
float32x4_t b{1.0, 2.0, 3.0f, 4.0};
float32x4_t c = vaddq_f32(a, b); // c: {2, 4, 6, 8}
- vadd_u64
uint64x1_t a{1};
uint64x1_t b{2};
uint64x1_t c = vadd_u64(a, b); // c: {3}
Vector long add: vaddl_type. Vr[i]:=Va[i]+Vb[i]
Long 方式处理。Va, Vb 的通道数相同, 返回值时一个输入的两倍宽向量
- vaddl_s32
int32x2_t a{1, 2};
int32x2_t b{1, 2};
int64x2_t c = vaddl_s32(a, b); // c: {2, 4}
Vector wide add: vaddw_type. Vr[i]:=Va[i]+Vb[i]
Wide 方式处理。Va,Vb 的通道数相同,Va 是 Vb 的两倍宽,返回值宽度与 Va 相同
- vaddw_s32
int64x2_t a{1, 2};
int32x2_t b{1, 2};
int64x2_t c = vaddw_s32(a, b);
Vector halving add: vhadd{q}_type. Vr[i]:=(Va[i]+Vb[i])>>1
Va 与 Vb 相加,并将结果右移一位(相当于整数除 2),即 c = (a + b) >> 1
- vhadd_s32
int32x2_t a{1, 2};
int32x2_t b{2, 3};
// a + b = {3, 5}
// (a + b)/2 = {1, 2}
int32x2_t c = vhadd_s32(a, b);
Vector rounding halving add: vrhadd{q}_type. Vr[i]:=(Va[i]+Vb[i]+1)>>1
Va 与 Vb 相加,并加上 1,然后右移一位。即整数除以 2 并向上取整,即 c = (a + b + 1) >> 1
- vrhadd_s32
int32x2_t a{1, 2};
int32x2_t b{2, 3};
int32x2_t c = vrhadd_s32(a, b);
VQADD: Vector saturating add
向量饱和加法,当计算结果可表示的最大值或者小于表示的最小值时,计算结果取值为这个最大值或最小值。
- vqadd_s8
int8x8_t a{127, 127};
int8x8_t b{0, 1};
int8x8_t c = vqadd_s8(a, b); // c{127, 127, ....}
int8x8_t e{-128, -128};
int8x8_t d{0, -1};
int8x8_t f = vqadd_s8(e, d); // f{-128, -128, ....}
Vector add high half: vaddhn_type.Vr[i]:=Va[i]+Vb[i]
Narrow 方式处理。Va 与 Vb 向量相加,去结果的高位存放在 Vr 中
int32x4_t a{0x7ffffffe, 0x7ffffffe, 0, 0};
int32x4_t b{0x00000001, 0x00000002, 0, 0};
// 0x7ffffffe + 0x00000001 = 0x7fffffff => 取高位 => 0x7fff
// 0x7ffffffe + 0x00000002 = 0x80000000 => 取高位 => 0x8000
int16x4_t c = vaddhn_s32(a, b);//c{32767 -32768 0 0}
Vector rounding add high half: vraddhn_type.
向量相加,取最高位的一半作为结果,并做四舍五入
int32x4_t a{0x7ffffffe, 0x7ffffffe, 0, 0};
int32x4_t b{0x00000001, 0x00000002, 0, 0};
// 0x7ffffffe + 0x00000001 + 0x00008000 = 0x80007fff => 取高位 => 0x8000
// 0x7ffffffe + 0x00000002 + 0x00008000 = 0x80008000 => 取高位 => 0x8000
int16x4_t c = vraddhn_s32(a, b);//c{-32768 -32768 0 0}
Multiplication 向量乘法
Vector multiply: vmul{q}_type. Vr[i] := Va[i] * Vb[i]
向量相乘,c = a*b
- vmul_f32
float32x2_t a{1.0f, 2.0f};
float32x2_t b{2.0f, 3.0f};
float32x2_t c = vmul_f32(a, b); // c{3.0f, 6.0f}
Vector multiply accumulate: vmla{q}_type. Vr[i] := Va[i] + Vb[i] * Vc[i]
向量乘加,即 d = a + b*c
- vmla_f32
float32x2_t a{1.0f, 2.0f};
float32x2_t b{2.0f, 3.0f};
float32x2_t c{4.0f, 5.0f};
float32x2_t d = vmla_f32(a, b, c); //c{9, 17}
Vector multiply accumulate long: vmlal_type. Vr[i] := Va[i] + Vb[i] * Vc[i]
Long 方式处理,Va 是 Vb/Vc 两倍宽,输出宽度与 Va 一致
- vmlal_s32
int64x2_t a{1, 2};
int32x2_t b{2, 3};
int32x2_t c{4, 5};
int64x2_t d = vmlal_s32(a, b, c); //c{9, 17}
Vector multiply subtract: vmls{q}_type. Vr[i] := Va[i] - Vb[i] * Vc[i]
向量乘减,即 d = a - b*c
- vmls_f32
float32x2_t a{1.0f, 2.0f};
float32x2_t b{2.0f, 3.0f};
float32x2_t c{4.0f, 5.0f};
float32x2_t d = vmls_f32(a, b, c);// c{-7, -13}
Vector multiply subtract long
向量乘减,Long 方式处理
- vmlsl_s32
int64x2_t a{1, 2};
int32x2_t b{2, 3};
int32x2_t c{4, 5};
int64x2_t d = vmlsl_s32(a, b, c);// c{-7, -13}
Vector saturating doubling multiply high
a 与 b 的相乘,将结果加倍(*2),将最终结果的最高位一半放入向量中,并将向量写入目标寄存器。
- vqdmulh_s32
int32x2_t a{0x00020000, 0x00035000};
int32x2_t b{0x00010000, 0x00015000};
// (0x00020000 * 0x00010000)*2 = 0x400000000, >> 32 = 0x00000004
// (0x00035000 * 0x00015000)*2 = 0x8b2000000, >> 32 = 0x00000008
int32x2_t c = vqdmulh_s32(a, b); // c{4, 8}
Vector saturating rounding doubling multiply high
- vqrdmulh_s32,其中
0x80000000为1<<31,这个值怎么来的,请参考 vqrdmulh_s32 的 Operation 部分。
int32x2_t a{0x00010000, 0x00035000};
int32x2_t b{0x00020000, 0x00015000};
// (0x00020000 * 0x00010000)*2 + 0x80000000 = 0x480000000, >> 32 = 0x00000004
// (0x00035000 * 0x00015000)*2 + 0x80000000 = 0x932000000, >> 32 = 0x00000009
int32x2_t c = vqrdmulh_s32(a, b); // c{4, 9}
Vector saturating doubling multiply accumulate long
即 d = a + (b*c*2) ,Long 方式处理
- vqdmlal_s32
int64x2_t a{1, 2};
int32x2_t b{3, 4};
int32x2_t c{5, 6};
int64x2_t d = vqdmlal_s32(a, b, c); // c{31,50}
Vector saturating doubling multiply subtract long
即 d = a - (b*c*2) ,Long 方式处理
- vqdmlsl_s32
int64x2_t a{1, 2};
int32x2_t b{3, 4};
int32x2_t c{5, 6};
int64x2_t d = vqdmlsl_s32(a, b, c); // c{-29,-46}
Vector long multiply
即 c = a*b,Long 方式处理
- vmull_s32
int32x2_t a{1, 2};
int32x2_t b{3, 4};
int64x2_t c = vmull_s32(a, b);// c{3, 8}
Vector saturating doubling long multiply
即 c = 2*a*b,Long 方式处理
- vqdmull_s32
int32x2_t a{1, 2};
int32x2_t b{3, 4};
int64x2_t c = vqdmull_s32(a, b);
Subtraction 向量减法
通过对 Addition 和 Multiplication 指令学习,你会发现有很多很多指令是在某个基础指令上的变种,这些变种指令操作与基础指令大同小异,后面将不再对变种指令做讲解,让我们把注意力放在更重要的指令上。
Vector subtract
向量相减,即 c = a - b
- vsubq_f32
float32x4_t a{4,3,2,1};
float32x4_t b{1,2,3,4};
float32x4_t c = vsubq_f32(a, b); //c{3, 1, -1, -3}
Vector long subtract: vsubl_type. Vr[i]:=Va[i]-Vb[i]
向量相减,Long 方式处理。
- vsubl_s32
int32x2_t a{4, 3};
int32x2_t b{1, 2};
int64x2_t c= vsubl_s32(a, b);//c{3,1}
Vector wide subtract: vsubw_type. Vr[i]:=Va[i]-Vb[i]
向量相减,Wide 方式处理
- vsubw_s32
int64x2_t a{4,3};
int32x2_t b{1, 2};
int64x2_t c= vsubw_s32(a, b);//c{3,1}
Vector saturating subtract
向量饱和减法
- vqsub_s32
int32x2_t a{0x7fffffff, 0x7fffffff};
int32x2_t b{-1, 1};
int32x2_t c = vqsub_s32(a, b); // c{0x7fffffff,0x7ffffffe}
Vector halving subtract
向量相减后除以2,即 c = (a-b)/2
- vhsubq_s32
int32x4_t a{4,3,2,1};
int32x4_t b{0,1,2,3};
int32x4_t c = vhsubq_s32(a, b);//c{2 1 0 -1}
Vector subtract high half
向量相减,取最高位的一半作为结果
- vsubhn_s64
int32x4_t a{0x7fffffff, 0x7fffeeee, 0,0};
int32x4_t b{0x7fff0000, 0x0000000f, 0,0};
// 0x7fffeeee - 0x0000000f = 7fffeedf => 取高位一半 = 0x7fff(32767)
int16x4_t c = vsubhn_s32(a, b);//c{0 32767 0 0}
Vector rounding subtract high half
向量相减,取最高位的一半作为结果,并做四舍五入
- vrsubhn_s32
int32x4_t a{0x7fffffff, 0x7fffeeee, 0,0};
int32x4_t b{0x7fff0000, 0x0000000f, 0,0};
// 0x7fffffff - 0x7fff0000 + 0x00008000 = 0x00017fff => 取高位 => 0x0001
// 0x7fffeeee - 0x0000000f + 0x00008000 = 0x80006edf => 取高位 => 0x8000
int16x4_t c = vrsubhn_s32(a, b);//c{1 -32768 0 0}
Comparison 向量比较
NEON 中提供了非常多向量的比较,包括 ==、>=、<=、>,< 等等。这部分挑几个有意思的函数进行说明下
- vceq_s32,判断向量相等。如果对应通道的值相同,那么返回全部是 bit 上全是 1 的值,如果不相等,返回 0。
int32x2_t a{1, 2};
int32x2_t b{1, 0};
uint32x2_t c = vceq_s32(a, b); //c{0xffffffff 0}
- vcage_f32,浮点型的绝对值判断是否 >=。
float32x2_t a{1.0, 2.0f};
float32x2_t b{-1.0, -3.0f};
uint32x2_t c = vcage_f32(a, b); //c{0xffffffff 0}
- vtst_s8,即
a AND b操作,逐 bit 进行 AND
int8x8_t a{0b00011111, 0b00010000};
int8x8_t b{0b00010000, 0b00000000};
uint8x8_t c = vtst_s8(a, b); //c{0xff 0}
Absolute difference 绝对差值
Absolute difference between the arguments: vabd{q}_type. Vr[i] = | Va[i] - Vb[i] |
向量差的绝对值,即 c = abs(a - b)
- vabd_f32
float32x2_t a{1.0, 2.0f};
float32x2_t b{2.0, 1.0f};
float32x2_t c = vabd_f32(a, b);c{1.000000 1.000000}
Absolute difference and accumulate: vaba{q}_type. Vr[i] = Va[i] + | Vb[i] - Vc[i] |
即 d = a + abs(b - c)
- vaba_s32
int32x2_t a{1,1};
int32x2_t b{1,2};
int32x2_t c{2,1};
int32x2_t d= vaba_s32(a, b, c);//c{2 2}
Max/Min 向量最大/最小
vmax{q}_type. Vr[i] := (Va[i] >= Vb[i]) ? Va[i] : Vb[i]
两个向量比较取大的那个
- vmax_f32
float32x2_t a{1.0, -2.0f};
float32x2_t b{2.0, 1.0f};
float32x2_t c = vmax_f32(a, b); //c{2.000000 1.000000}
vmin{q}_type. Vr[i] := (Va[i] >= Vb[i]) ? Vb[i] : Va[i]
向量比较取小的那个
- vmin_f32
float32x2_t a{1.0, -2.0f};
float32x2_t b{2.0, 1.0f};
float32x2_t c = vmin_f32(a, b);//c{1.000000 -2.000000}
Pairwise addition 成对的加法
Pairwise add
向量求和,即 c = { sum(a), sum(b) }
- vpadd_s32
int32x2_t a{3,4};
int32x2_t b{1,2};
int32x2_t c = vpadd_s32(a, b); //c{7 3}
Long pairwise add and accumulate
即 c={a[0] + sum(c[0:1]), a[1]+sum(2:3)}
- vpadal_s16
int32x2_t a{3,4};
int16x4_t b{1,2,3,4};
int32x2_t c = vpadal_s16(a, b);//c{6 11}
Folding maximum
取向量 a 和 向量 b 中的最大值,即 c={ max(a), max(b) }
- vpmax_s32
int32x2_t a{1,2};
int32x2_t b{-1,0};
int32x2_t c = vpmax_s32(a, b);//c{2 0}
Folding minimum
取向量 a 和 向量 b 中的最小值,即 c={ min(a), min(b) }
- vpmin_s32
int32x2_t a{1, 2};
int32x2_t b{-1, 0};
int32x2_t c = vpmin_s32(a, b);//c{1 -1}
Reciprocal/Sqrt
这些内在函数在牛顿-拉弗森方法的迭代中执行两个步骤中的第一个步骤,以收敛到倒数或平方根
- vrecps_f32,即
c = 2.0 - a*b
float32x2_t a{2, 4};
float32x2_t b{1, 3};
float32x2_t c= vrecps_f32(a, b);//c{0.000000 -10.000000}
- vrsqrts_f32,即
c = (3.0 - a*b)/2
float32x2_t a{2, 4};
float32x2_t b{1, 3};
float32x2_t c= vrsqrts_f32(a, b);//c{0.500000 -4.500000}
Shifts by signed variable 根据变量值移位
这部分函数提供有符号变量的移位能力
Vector shift left: vshl{q}_type. Vr[i] := Va[i] << Vb[i] (negative values shift right)
即 a 向量根据 b 向量中的值进行向左移位,如果 b 中值是负数那么向左移动
- vshl_s16
int16x4_t a{1, 8, -1, -8};
int16x4_t b{2, -2, 2, -2};
int16x4_t c = vshl_s16(a, b);//c{4 2 -4 -2}
Shifts by a constant 常数移位
Vector shift right by constant
向量向右移位
int32x2_t a{8, 16};
int32x2_t c = vshr_n_s32(a, 2);//c{2 4}
Vector shift left by constant
向量向左移位
int32x2_t a{2, 4};
int32x2_t c = vshl_n_s32(a, 2);//c{8 16}
Vector shift right by constant and accumulate
即 d = (b >> n) + a
int32x2_t a{8, 4};
int32x2_t b{4, 2};
const int c = 1;
int32x2_t d = vsra_n_s32(a, b, c);//c{10 5}
Shifts with insert 移位且插入
Vector shift right and insert
这个操作比较神奇,以 vsri_n_s32 示例,我用大白话来描述一下:
- 因为
c = 6,所以保留 a 的前 6 bit,得0x0c000000 - b 向右位移 6 位,得
0x00000400 - 两个结果 OR 一下,得
0x0c0000400
- vsri_n_s32
int32x2_t a{0x0fffffff, 0x0fffffff};
int32x2_t b{0x00010000, 1};
const int c = 6;
int32x2_t d = vsri_n_s32(a, b, c);//c{0x0c0000400 0x0c0000000}
Loads of a single vector or lane 向量加载与存储
Load a single vector from memory
从内存中加载向量
- vld1q_f32
float a[4] = {1,2,3,4};
float32x4_t b = vld1q_f32(a);//{1.000000 2.000000 3.000000 4.000000}
Load a single lane from memory
从内存中加载到向量指定位置,下面的例子中,将从 src 加载向量,且从 src[2] 开始导入 prt 加载向量的值,即 c[0:lane] = src[0:lane], c[lane:end] = ptr[0:lane]
- vld1q_lane_s32
int32_t ptr[] = {1, 2, 3, 4};
int32x4_t src{0, 1, 2, 3};
const int lane = 2;
int32x4_t c = vld1q_lane_s32(ptr, src, lane);//c{0 1 1 3}
Load all lanes of vector with same value from memory
从一个内存变量中加载向量,向量中的值都为该值
- vld1q_dup_s32
const int32_t a{10};
int32x4_t b = vld1q_dup_s32(&a); //{10 10 10 10}
Store a single vector or lane
读取向量值到内存中
Store a single vector into memory
读取一整个向量到内存中
int32x4_t a{0,1,2,3};
int32_t ptr[4];
vst1q_s32(ptr, a);//ptr{0 1 2 3}
Store a lane of a vector into memory
读取向量一个通道的值到内存中
- vst1q_lane_s32
int32x4_t a{0,1,2,3};
int32_t a0, a1;
vst1q_lane_s32(&a0, a, 0);// 0
vst1q_lane_s32(&a1, a, 3);// 3
Loads of an N-element structure
一次性加载多个向量
Load N-element structure from memory
从内存中加载多个向量,去交织存放
- vld2q_f32
float32_t ptr[] = {0,1,2,3,4,5,6,7,8};
float32x4x2_t a = vld2q_f32(ptr);
// a.val[0] = {0.000000 2.000000 4.000000 6.000000}
// a.val[1] = {1.000000 3.000000 5.000000 7.000000}
Load all lanes of N-element structure with same value from memory
即 a[0, :] = ptr[0], a[1, :] = ptr[1]
- vld2_dup_f32
float32_t ptr[] = {0, 1};
float32x2x2_t a = vld2_dup_f32(ptr);
// a.val[0] = {0.000000 0.000000}
// a.val[1] = {0.000000 0.000000}
Load a single lane of N-element structure from memory
即 c[:, lane] = ptr,也就是把 src 中的第 lane 列替换为 ptr 中的值
float32_t ptr[] = {10, 20};
float32x4x2_t src = {
float32x4_t{1, 1, 1, 1},
float32x4_t{2, 2, 2, 2}};
float32x4x2_t c = vld2q_lane_f32(ptr, src, 1);
// c.val[0] = {1.000000 10.000000 1.000000 1.000000}
// c.val[1] = {2.000000 20.000000 2.000000 2.000000}
Store N-element structure to memory
一次性读取多个向量,交织读取
- vst2q_s32
int32_t ptr[8];
int32x4x2_t val{
int32x4_t{0,1,2,3},
int32x4_t{4,5,6,7},
};
vst2q_s32(ptr, val);
//ptr = {0 4 1 5 2 6 3 7 }
Store a single lane of N-element structure to memory
读取多个向量中的某个通道,即取某一列
int32_t ptr[2];
int32x4x2_t val{
int32x4_t{0,1,2,3},
int32x4_t{4,5,6,7},
};
const int lane = 2;
vst2q_lane_s32(ptr, val, lane);
// ptr = {2 6}
Extract lanes from a vector and put into a register
读取向量中指定通道的值
- vgetq_lane_f32
float32x4_t a{0, 1, 2, 3};
const int lane = 2;
float32_t b = vgetq_lane_f32(a, lane);
Load a single lane of a vector from a literal
设置向量指定通道的值
- vsetq_lane_f32
float32x4_t a{0, 1, 2, 3};
float32_t new_val = 10;
const int lane = 2;
float32x4_t b = vsetq_lane_f32(new_val, a, lane);//c{0.000000 1.000000 10.000000 3.000000}
Initialize a vector from a literal bit pattern
从一个 uint64_t 变量中创建向量,
uint64_t a = 0x0000000100000002;
int32x2_t b = vcreate_s32(a);//{2 1}
Set all lanes to same value
Load all lanes of vector to the same literal value
将向量所有通道设置成同一个值
- vdupq_n_f32
float32x4_t a = vdupq_n_f32(10);//{10.000000 10.000000 10.000000 10.000000}
- vmovq_n_f32
float32x4_t a = vmovq_n_f32(10);//{10.000000 10.000000 10.000000 10.000000}
Load all lanes of the vector to the value of a lane of a vector
从 a 向量中取出一个通道的值,用这个值创建一个向量
- vdupq_lane_f32
float32x2_t a{0, 1};
const int lane = 1;
float32x4_t b = vdupq_lane_f32(a, lane);//{1.000000 1.000000 1.000000 1.000000}
Combining vectors 合并向量
将两个 64bit 向量合并成一个 128bit 的向量
- vcombine_f32
float32x2_t low{0, 1};
float32x2_t high{2, 3};
float32x4_t c = vcombine_f32(low, high);
Splitting vectors 分解向量
- vget_high_f32
float32x4_t a{0,1,2,3};
float32x2_t b = vget_high_f32(a);//{2.000000 3.000000}
- vget_high_f32
float32x4_t a{0,1,2,3};
float32x2_t b = vget_high_f32(a);
float32x2_t c = vget_low_f32(a);//{0.000000 1.000000}
Converting vectors 向量类型转换
- vcvt_s32_f32
float32x2_t a{1, 2};
int32x2_t b = vcvt_s32_f32(a);//{1 2}
Table look up 查表
- vtbl2_s8
int8x8x2_t a{
int8x8_t{0,1,3,5,7,9,11,13},
int8x8_t{2,4,6,8,10,12,14,16}};
int8x8_t b{0,1,2,3,12,13,14,15};
int8x8_t c = vtbl2_s8(a, b);//{0 1 3 5 10 12 14 16}
- vtbx1_s8
int8x8_t a{0,1,3,5,7,9,11,13};
int8x8_t b{2,4,6,8,10,12,14,16};
int8x8_t c{0,1,2,3,12,13,14,15};
int8x8_t d = vtbx1_s8(a,b,c);//{2 4 6 8 7 9 11 13 }
Operations with a scalar value
向量与标量的一些操作
Vector multiply accumulate with scalar
即 d = a + (b * c[lane])
- vmla_lane_f32
float32x2_t a{1, 2};
float32x2_t b{1, 2};
float32x2_t c{2, 4};
const int lane = 0;
float32x2_t d = vmla_lane_f32(a, b, c, lane);//{3.000000 6.000000}
Vector multiply by scalar
向量与标量相乘
- vmulq_n_f32
float32x4_t a{0, 1, 2, 3};
float32_t b = 2;
float32x4_t c = vmulq_n_f32(a, b);//{0.000000 2.000000 4.000000 6.000000}
Vector multiply subtract with scalar
即 d = a - (b * c)
float32x2_t a{1, 2};
float32x2_t b{1, 2};
float32_t c = 2.0f;
float32x2_t d = vmls_n_f32(a, b, c);//{-1.000000 -2.000000}
Vector extract 向量提取
用下面例子说明,想将 a 和 b 合并成一个向量,然后从 lane 下标开始取向量的值
int16x4_t a{0,2,4,6};
int16x4_t b{1,3,5,7};
// a:b => {0,2,4,6,1,3,5,6} => get starts index 3 => {6 1 3 5}
const int lane = 3;
int16x4_t c = vext_s16(a, b, lane);//{6 1 3 5}
Reverse vector elements (swap endianness)
向量元素翻转
- vrev64q_f32
float32x4_t a{0, 1, 2, 3};
float32x4_t b = vrev64q_f32(a);//{1.000000 0.000000 3.000000 2.000000}
Other single operand arithmetic
Absolute: vabs{q}_type. Vd[i] = |Va[i]|
取绝对值
- vabsq_f32
float32x4_t a{0, 1, -2, -3};
float32x4_t b = vabsq_f32(a);//{0.000000 1.000000 2.000000 3.000000}
Negate: vneg{q}_type. Vd[i] = - Va[i]
取反
- vnegq_f32
float32x4_t a{0, 1, -2, -3};
float32x4_t b = vnegq_f32(a);//{-0.000000 -1.000000 2.000000 3.000000
}
Count leading sign bits
最高位后,连续与最高位相同的 bit 值的个数
- vcls_s8
int8x8_t a{0b00000001, 0b00110000};
int8x8_t b = vcls_s8(a);
printf("%d %d\n", b[0], b[1]);//{6 1}
Count leading zeros
最高位开始,连续 0 的个数
- vclz_s8
int8x8_t a{0b00000001, 0b01110000};
int8x8_t b = vclz_s8(a);
printf("%d %d\n", b[0], b[1]);//{7 1}
Count number of set bits
计算 bit 为 1 的个数
- vcnt_s8
int8x8_t a{0b00000001, 0b01110000};
int8x8_t b = vcnt_s8(a);
printf("%d %d\n", b[0], b[1]);//{1 3}
Reciprocal estimate
倒数估计,近似值
- vrecpe_f32
float32x2_t a{1, 3};
float32x2_t b = vrecpe_f32(a);//{0.998047 0.333008}
Reciprocal square root estimate
即 b = 1 / sqrt(a),近似值
- vrsqrte_f32
float32x2_t a{1, 4};
float32x2_t b = vrsqrte_f32(a);//{0.998047 0.499023}
Logical operations 逻辑操作
Bitwise not
按位非
- vmvn_s32
int32x2_t a{0x0000ffff, 0x0000000};
int32x2_t b = vmvn_s32(a);
printf("%x %x\n", b[0], b[1]); //{ffff0000 ffffffff}
Bitwise and
按位与
- vand_s32
int32x2_t a{0x00000ff0, 0x00000ff};
int32x2_t b{0x0000ffff, 0x00000ff};
int32x2_t c = vand_s32(a, b);//{ff0 ff}
Bitwise or
按位或
- vorr_s32
int32x2_t a{0x00000ff0, 0x00000ff};
int32x2_t b{0x0000ffff, 0x00000ff};
int32x2_t c = vorr_s32(a, b);//{ffff ff}
Bitwise exclusive or (EOR or XOR)
按位异或
- veor_s32
int32x2_t a{0x00000ff0, 0x00000ff};
int32x2_t b{0x0000ffff, 0x00000ff};
int32x2_t c = veor_s32(a, b);//{f00f 0}
Bit Clear
似乎是 c = a & !b
- vbic_s32
int32x2_t a{0x7fffffff, 0x000000ff};
int32x2_t b{0x0000ffff, 0x7fffffff};
int32x2_t c = vbic_s32(a, b);//{7fff0000 f0}
Bitwise OR complement
即 c = a || !b
- vorn_s32
int32x2_t a{0x7fffffff, 0x000000ff};
int32x2_t b{0x0000ffff, 0x7fffffff};
int32x2_t c = vorn_s32(a, b);//{ffffffff 800000ff}
Transposition operations
向量转置的一些操作
Transpose elements
- vtrn_s32
int32x2_t a{0, 1};
int32x2_t b{2, 3};
int32x2x2_t c = vtrn_s32(a, b);
/**
0 2
1 3
**/
Interleave elements
- vzip_s8
int8x8_t a{0,2,4,6,8,10,12,14};
int8x8_t b{1,3,5,7,9,11,13,15};
int8x8x2_t c = vzip_s8(a, b);
/**
0 1 2 3 4 5 6 7
8 9 10 11 12 13 14 15
**/
De-Interleave elements
- vuzp_s8
int8x8_t a{0,2,4,6,8,10,12,14};
int8x8_t b{1,3,5,7,9,11,13,15};
int8x8x2_t c = vuzp_s8(a, b);
/**
0 4 8 12 1 5 9 13
2 6 10 14 3 7 11 15
**/
Vector reinterpret cast operations
在某些情况下,你可能想把一个向量视为具有不同的类型,而不改变它的值。NEON 提供了一组函数来执行这种类型的转换。
这类函数有着相同的语法
vreinterpret{q}_dsttype_srctype
其中:
q,指定转换在128位向量上进行。如果它不存在,转换将在64位向量上进行。- dsttype,即目标类型
- srctype,即源数据类型
以 vreinterpretq_s8_f32 为例
int16x4_t a{0, 1, 2, 3};
uint16x4_t b = vreinterpret_u16_s16(a);//{0 1 2 3}
总结
本文介绍 NEON intrinsics 的基本使用概念和基本使用方式,并且列举了海量的 NEON 函数的使用示例,旨在帮助入门 NEON 不再困难。后面还将列举一些 NEON 指令的实际使用例子,帮助大家理解 NEON 在实际应用场景中是如何被使用的。
参考
- Learn the architecture - Optimizing C code with Neon intrinsics
- Learn the architecture - Neon programmers’ guide
- NEON码农指导 Chapter 1 : Introduction
- ARM Compiler toolchain Compiler Reference Version 5.03
- ARM NEON for C++ Developers
- neon-guide