哈喽,大家好。
今天看到Kaggle上有一个预测世界杯比赛结果的项目,截至目前 4 场比赛预测结果全中。
今天把源码研究了一下,做了中文注释,给大家分享下。
文章目录
- 技术提升
- 1. 获取数据集
- 2. 特征工程
- 3. 建模
- 4. 预测
技术提升
本文由技术群粉丝分享,项目源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:dkl88191,备注:来自CSDN +研究方向
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
1. 获取数据集
数据集使用 1872-2022年国际足球比赛数据和FIFA 1992-2022年球队排名数据。
比赛数据
排名数据
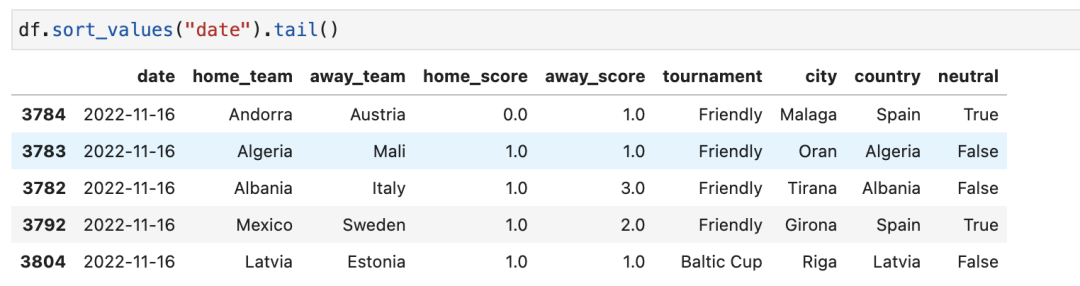
虽然有数据集很大,但作者只用了 2018-2022年的数据作为训练数据。
df = pd.read_csv("./kaggle/input/international-football-results-from-1872-to-2017/results.csv")
df = df[(df["date"] >= "2018-8-1")].reset_index(drop=True)
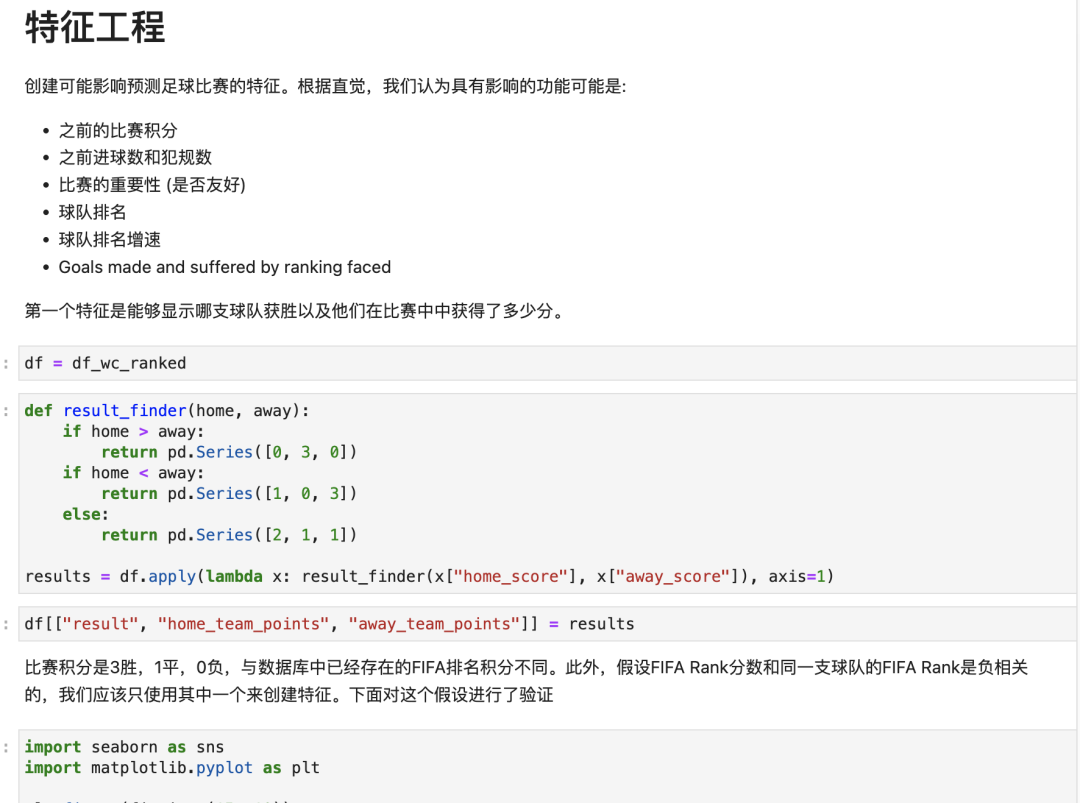
2. 特征工程
选取的特征要能够较好地反映预测结果,如:
-
世界杯球队的平均进球数
-
球队最近5场比赛的平均进球数
-
世界杯球队的平均犯规数
-
球队最近5场比赛的平均犯规数
-
球队在世界杯中 FIFA 平均排名
-
球队在最近5场比赛中 FIFA 平均排名
-
FIFA积分
-
最近5场FIFA积分
-
比赛得分
-
最近5场比赛积分
-
Mean game points by rank faced at the Cycle.
-
Mean game points by rank faced at last 5 games.
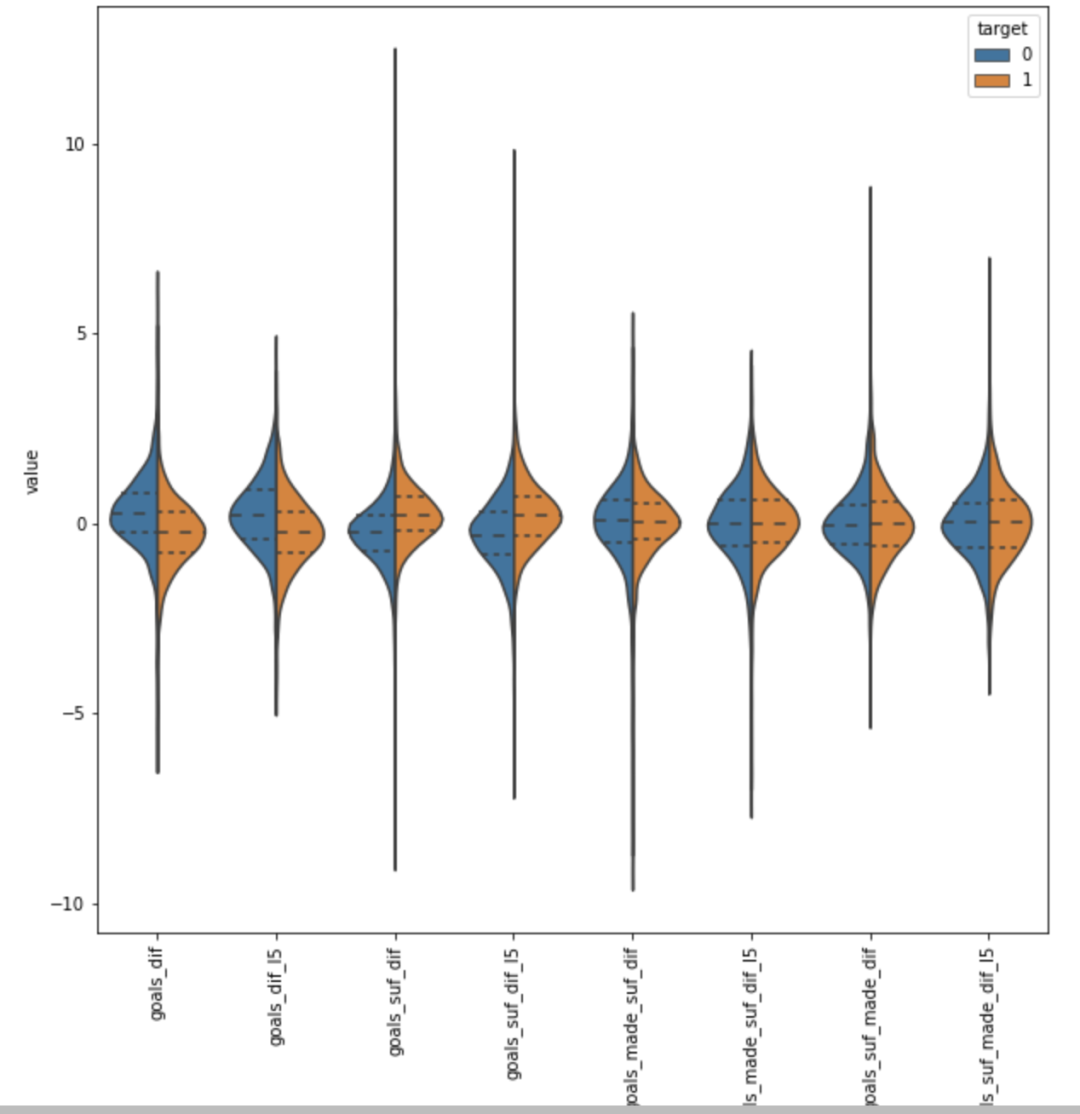
通过观察这些特征的小提琴图,筛选对预测结果又很强区分的特征。
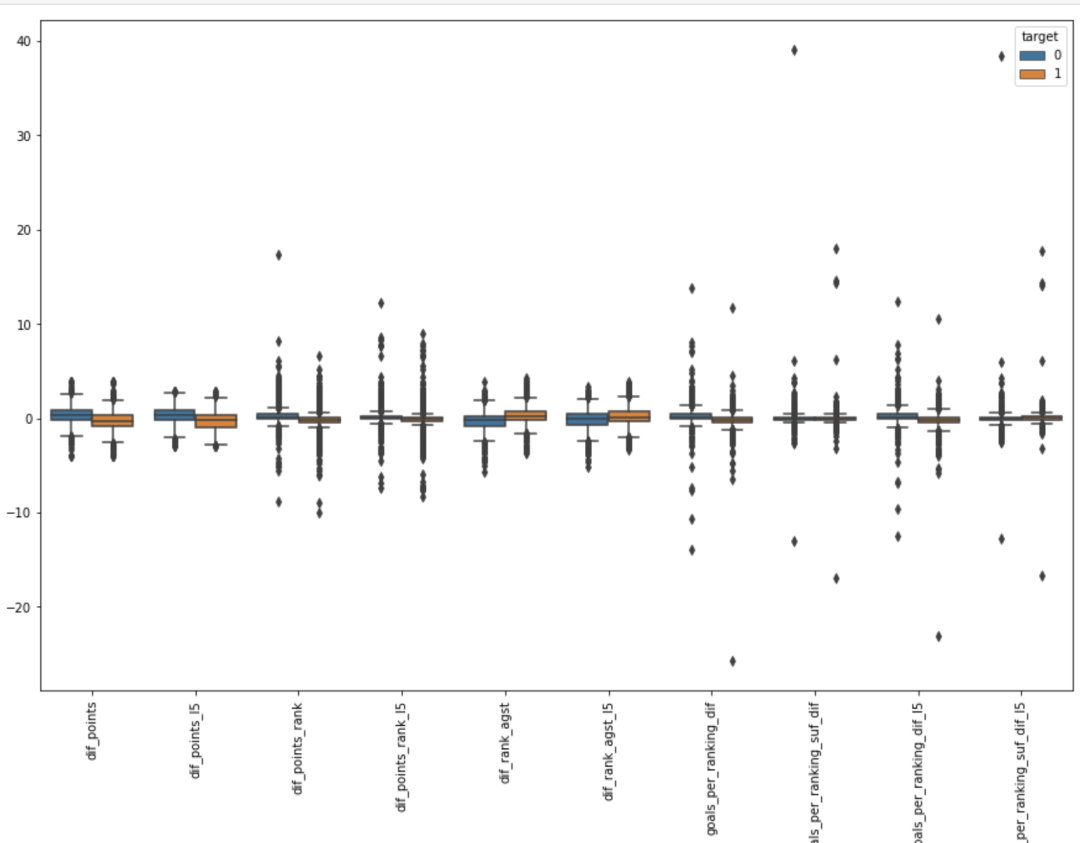
对于值比较小的特征,可以尝试用箱型图观察。
最终生成的特征为:
最终特征如下:
-
rank_dif
-
goals_dif
-
goals_dif_l5
-
goals_suf_dif
-
goals_suf_dif_l5
-
dif_rank_agst
-
dif_rank_agst_l5
-
goals_per_ranking_dif
-
dif_points_rank
-
dif_points_rank_l5
-
is_friendly
3. 建模
作者选择了随机森林和GradientBoosting模型进行训练,并对比他们的 AUC。
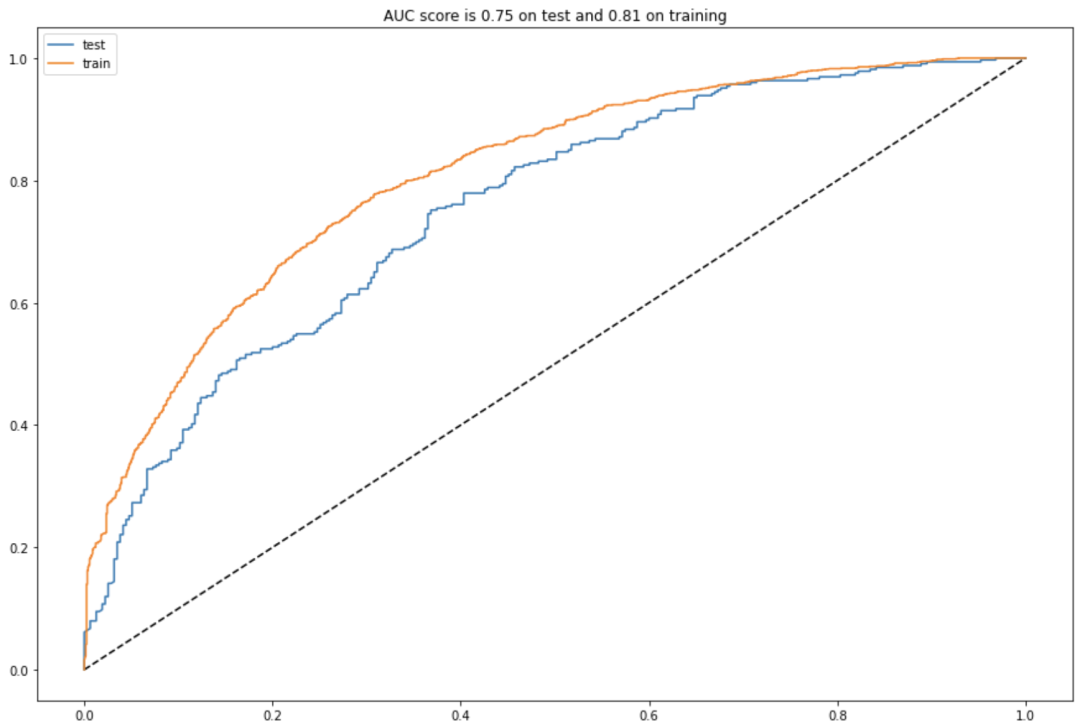
GradientBoosting
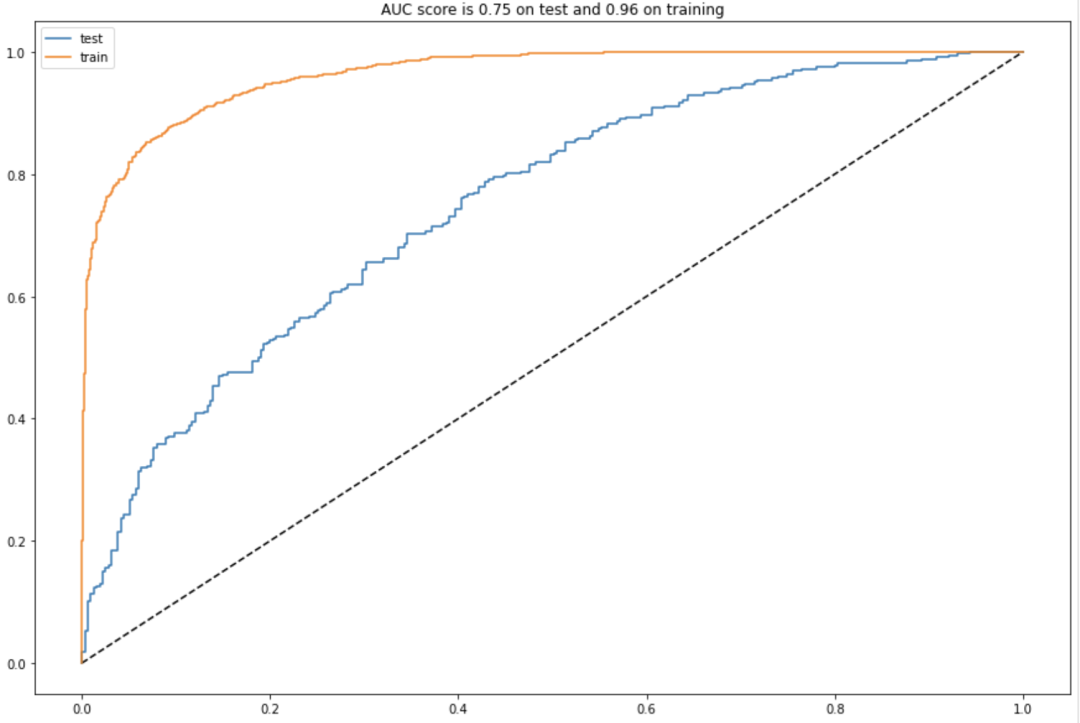
随机森林
最终选取GradientBoosting作为预测模型。
4. 预测
预测需要获取 2022 世界杯比赛数据。
作者通过爬取维基百科解析出比赛数据,考虑到国内很多朋友无法访问维基百科。源代码中我已经将比赛数据放在本地文件中。

kaggle地址:https://www.kaggle.com/code/sslp23/predicting-fifa-2022-world-cup-with-ml/notebook