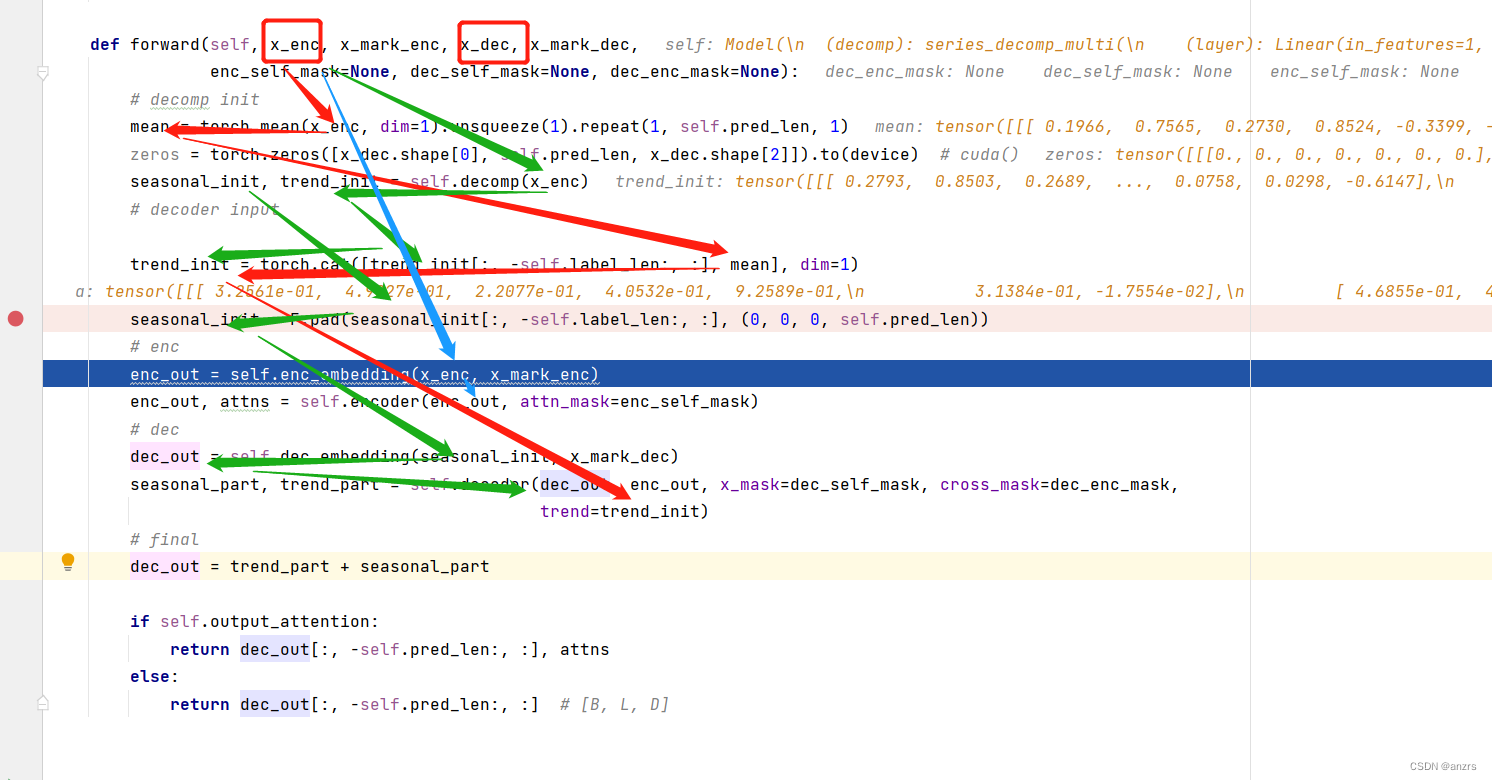
首先总结一下FEDformer里面这些这些东西,
mean的尺寸是:(1,96,7)
seasonal_init的尺寸是:(1,144,7)
trend_init的尺寸是:(1,144,7)
zeros的尺寸是:(1,96,7)
从上面的线可以看出来,和传统transformer不同的成分,也就是seasonal和trend之类的东西,他们都被输入进了decoder里面,而encoder里面的东西还是最原始的x_enc。
所以,从这个层面来看,看来decoder主要做的工作是辅助性的,他将原始的x_enc做了一些处理后,放进了decoder里面,而decoder又会和encoder进行交互。
x_enc的尺寸是:(1,96,7)
x_dec的尺寸是:(1,144,7)
x_mark_enc的尺寸是:(1,96,4)
x_mark_dec的尺寸是:(1,144,4)
然后经过了enc_embedding之后的enc_out就是(1,96,512的维度的),也就是说,他把后面的那个feature是7的做了一个embedding,不过能从7做到512不知道是怎么做的。来看看他是怎么做的。

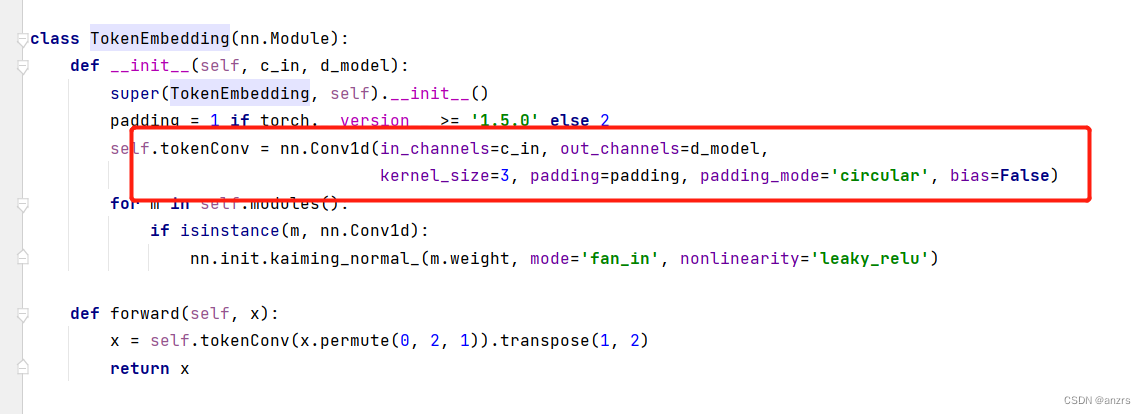
value_embedding是一个一维卷积。
temporal_embedding是一个时序embedding的方式。
也就是说,到了encoder这里的enc_out是经过了embedding的feature。
他的维度是(1,96,512)的维度的向量。
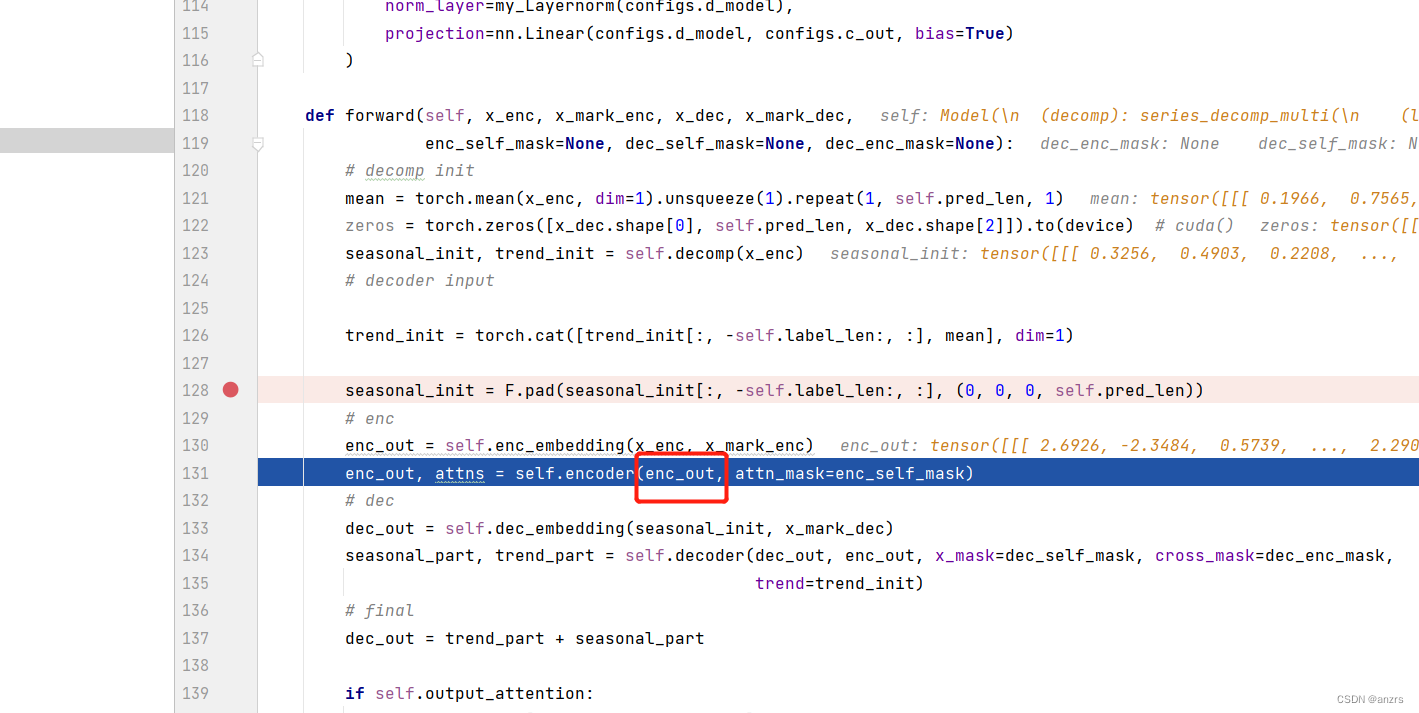
然后,我们进入encoder,来看一下这个encoder里面是有什么组成的。
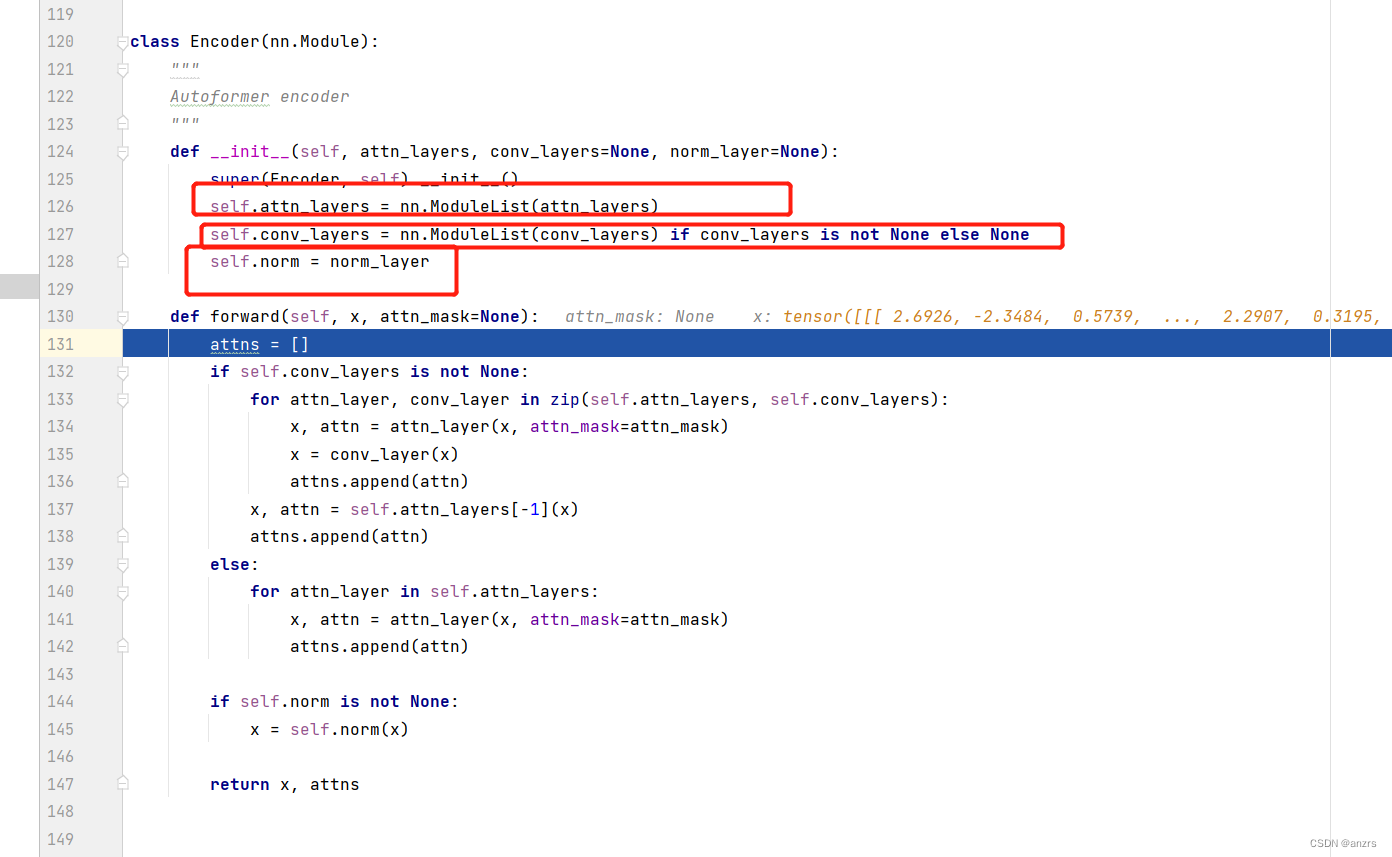
它是由三个部分组成的,
(1)attention
(2)conv
(3)norm
下图所示,大体由下面这些模块组成
红色的部分是,傅里叶block
绿色的是传统的transformer里面的attention的映射linear
黄色的是out_projection,看他的名字的意思是一个前馈层,一会再看看具体有啥特殊的用处没。
然后是两个一维卷积,先2048后变回来又变成了512的。
然后就是两个叫做decomp的模块,这两个模块的进出feature的dimension都是1,不知道在做啥的,一会仔细看看。
到encoder_layer这里的这个x,他还是实数,并不是复数,这里还没产生傅里叶变换。
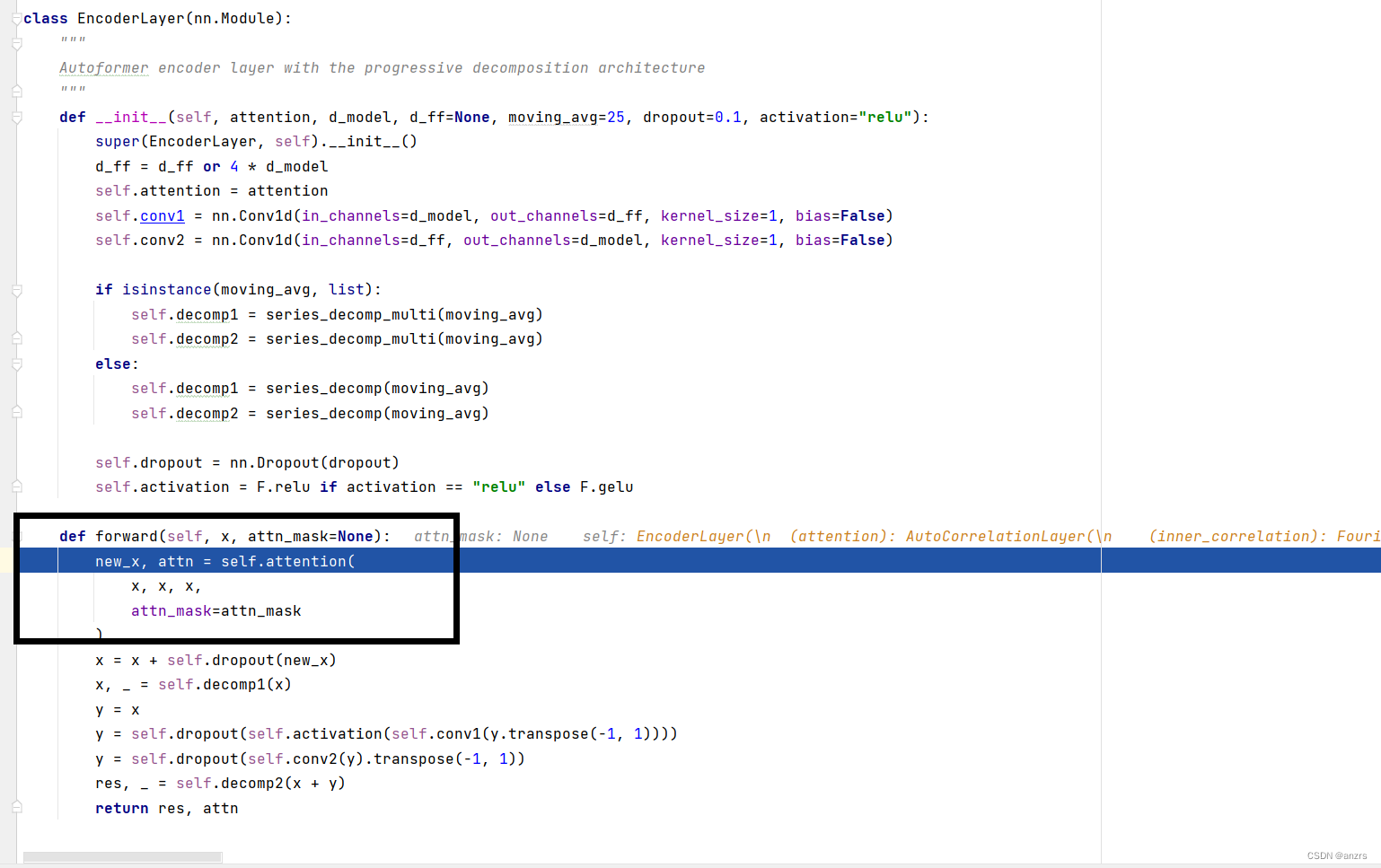
然后,他会进入这个Encoder_layer里面进行一个操作,这个黑色的就是注意力的计算模块,这个是主要的创新点。可以看到他的 attention,叫做inner_correlation这个操作,而不是各种attention的叫法。
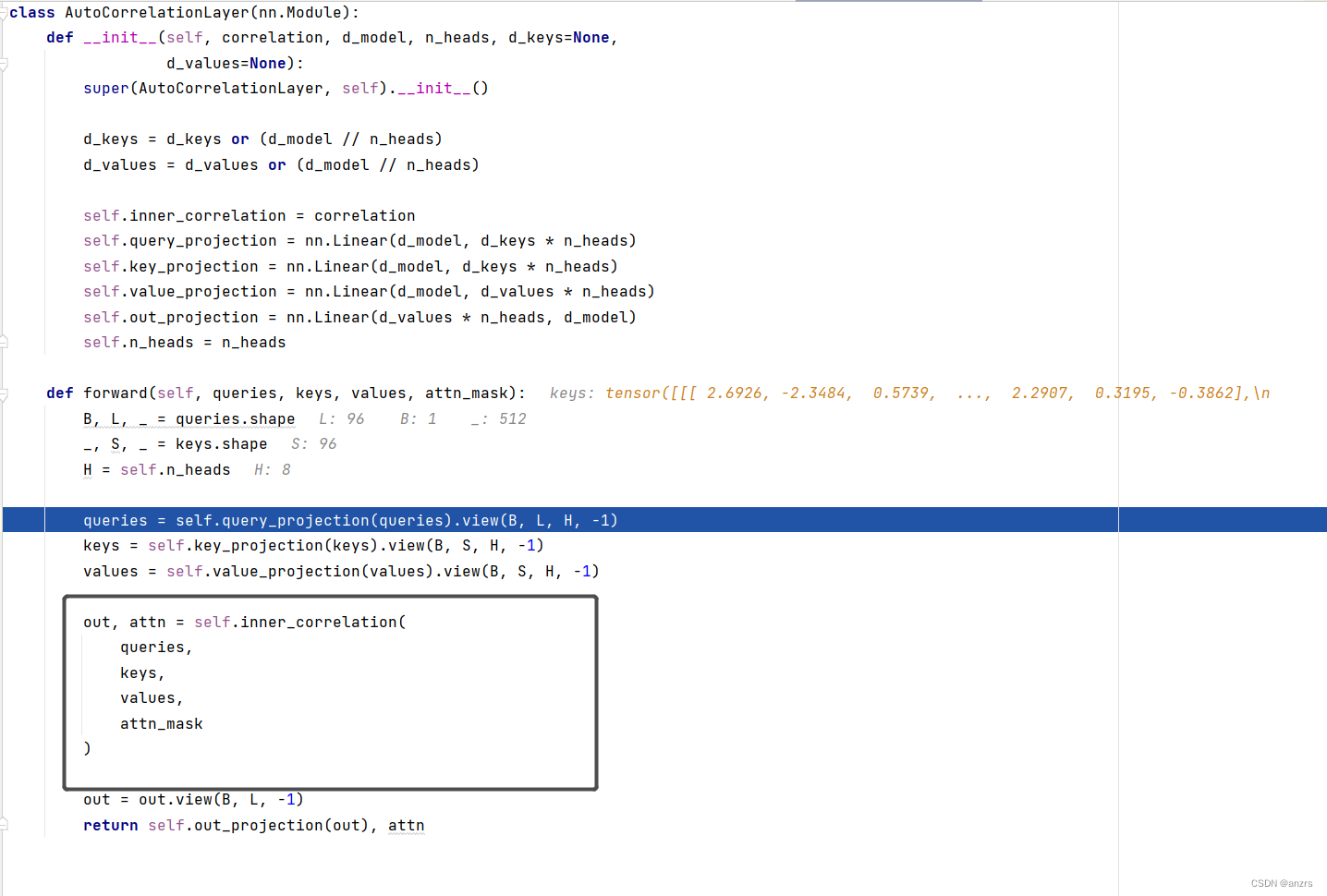
在进入这个黑色的框框之前的操作,也还和之前attention的准备操作是一样的,
他输入的queries,keys,values都是(batch_size,length,feature)这种维度的tensor,在这里的具体的维度就是(1,96,512)。
他具体的attention的计算是这个叫做,FourierBlock的东西,这个东西的注释也写的很清楚,他由三个部分组成,FFT快速傅里叶变换,linear transform线性的变化,还有Inverse FFT反傅里叶变化组成,也就是进入了频域后进行了linear transform? 详细研究一下。
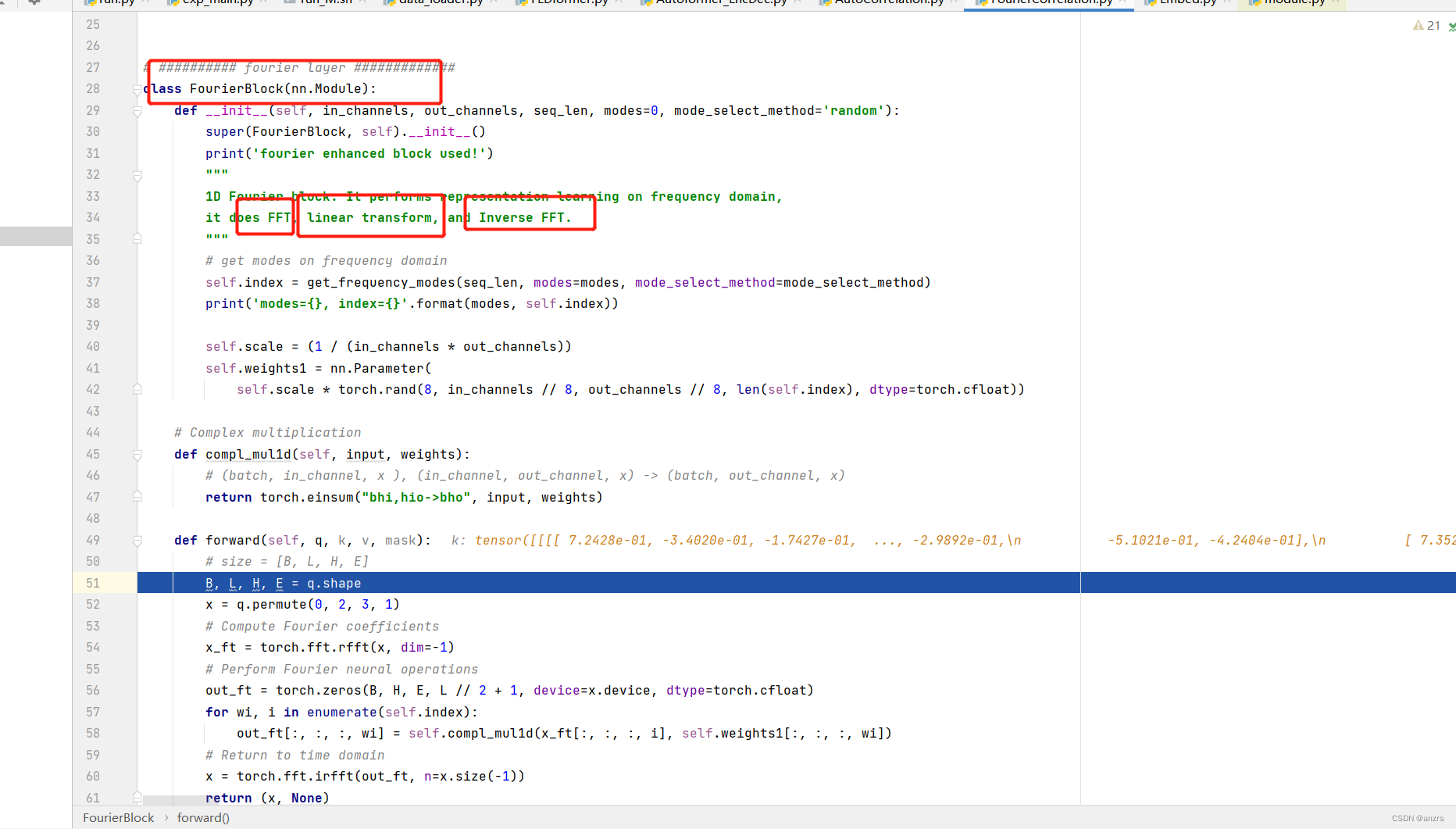
这个红色的部分是一个多头注意力的调整的操作,经过这个操作,这个x就是q的一个多头版本,他把8这个维度调整到了前面,也就是说原本是(1,96,8,64)的tensor,这个代表的意思是,输入的time_stamp的数量是96,然后他后面的那个feature的维度是512,分成了8,64。变成了这个x,这个x的维度是(1,8,64,96)。
也就是说,从(1,96,8,64)->(1,8,64,96) ;大概的意思是,(1,96,512)-》(1,512,96)。
用一个低维度的例子来看看,一个序列的长度是5,一共有8个time_stamp,每一个time_stamp的feature的维度是5。也就是说,每一个位置的1这个地方,都是他的第一个feature的值。
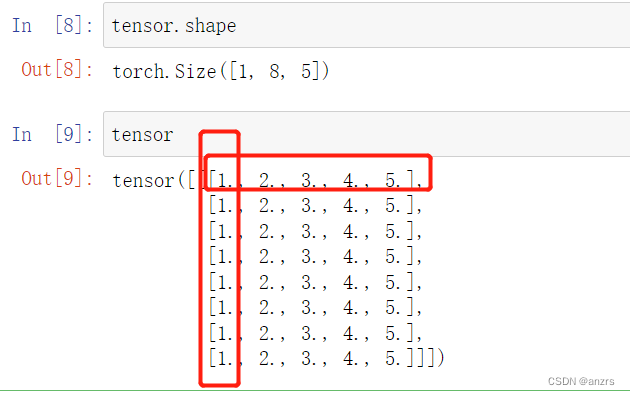
做了permute这个操作后,
这个tensor的最低维度的向量的组成就是,所有的timestamp的第一个,第二个,第三个,第四个,第五个feature的值了,比如像这样。
(1,8,5),变成了,(1,5,8),也就是说最里面有几个就是最揭示这个tensor的本质的东西。
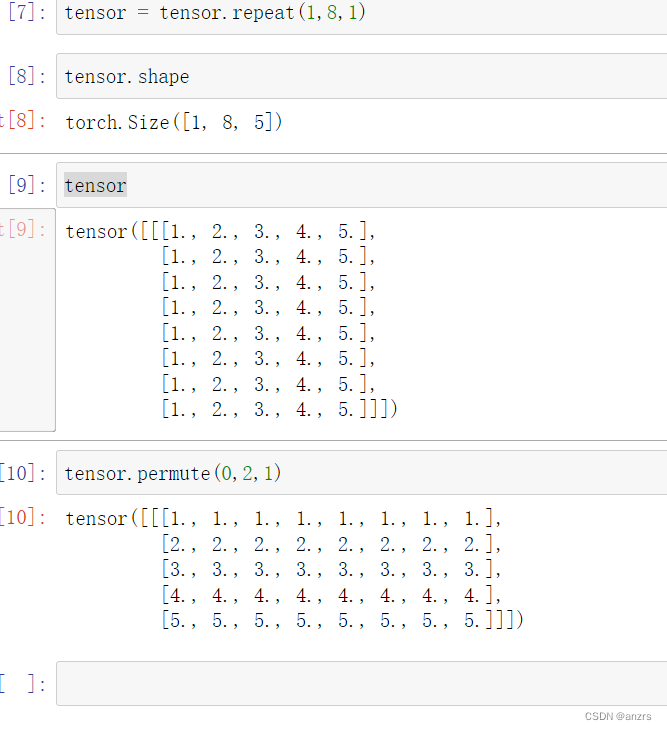
这个x的维度是,(1,8,64,96),所以,他最里面的feature的组成是time_stamp,也就是这96个点的一个维度的feature。

可以看到,下面两个红色的都是一个东西,但是因为多头注意力的存在,使得这里面的东西分成了两份,x也是有一样的意思,他分成了8份,然后64份,然后是96,也就是他最里面的基本的元素是96这个序列长度的每一个基本的单位,第一个里面是,所有的96的第一个单位,第二个里面是96里面的第二个单位这样。

x经过傅里叶变换后,变成了下面这样的。
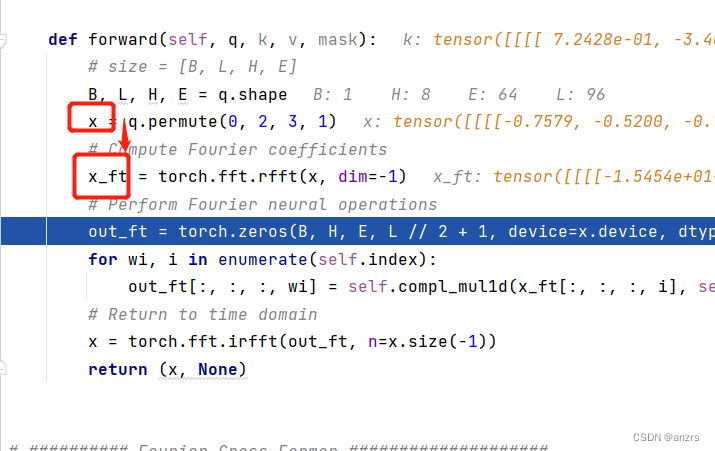
原本的x是(1,8,64,96)变成了(1,8,64,49)

傅里叶变换后的维度是原本的维度的一半+1。
可以看出来,下面这个操作是先生成一个空的和傅里叶变换后相同维度的tensor,然后利用抽样的频域来存储。
下面这个操作是对傅里叶域中的每一个频域都进行乘积,用这个torch.einsum这个操作,可以使得这个矩阵乘法变得更快。
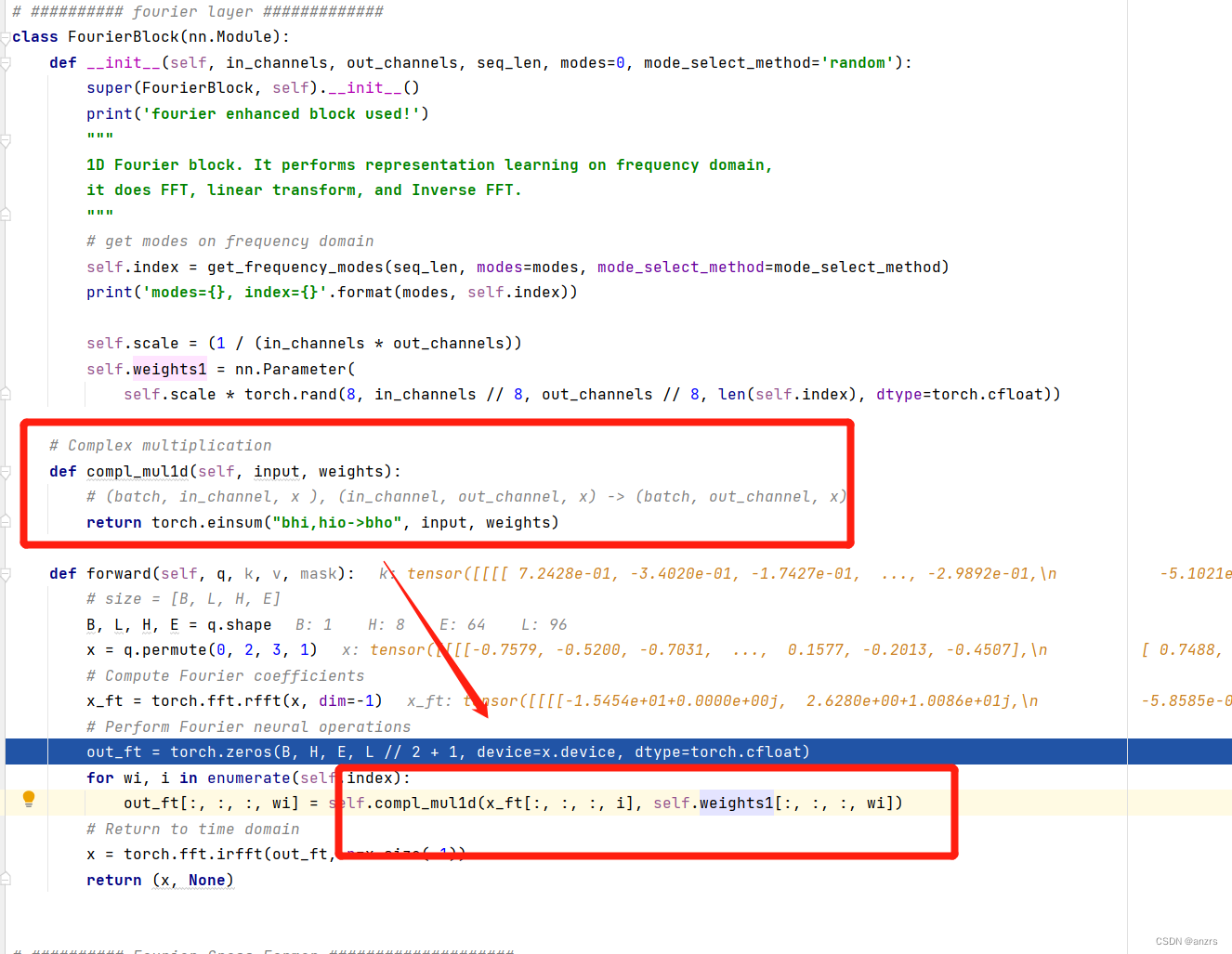
然后,经过傅里叶的inner_correlation后,这个会出去,和注意力的操作是一样的,加了一个前馈,512 to 512 然后往前走。
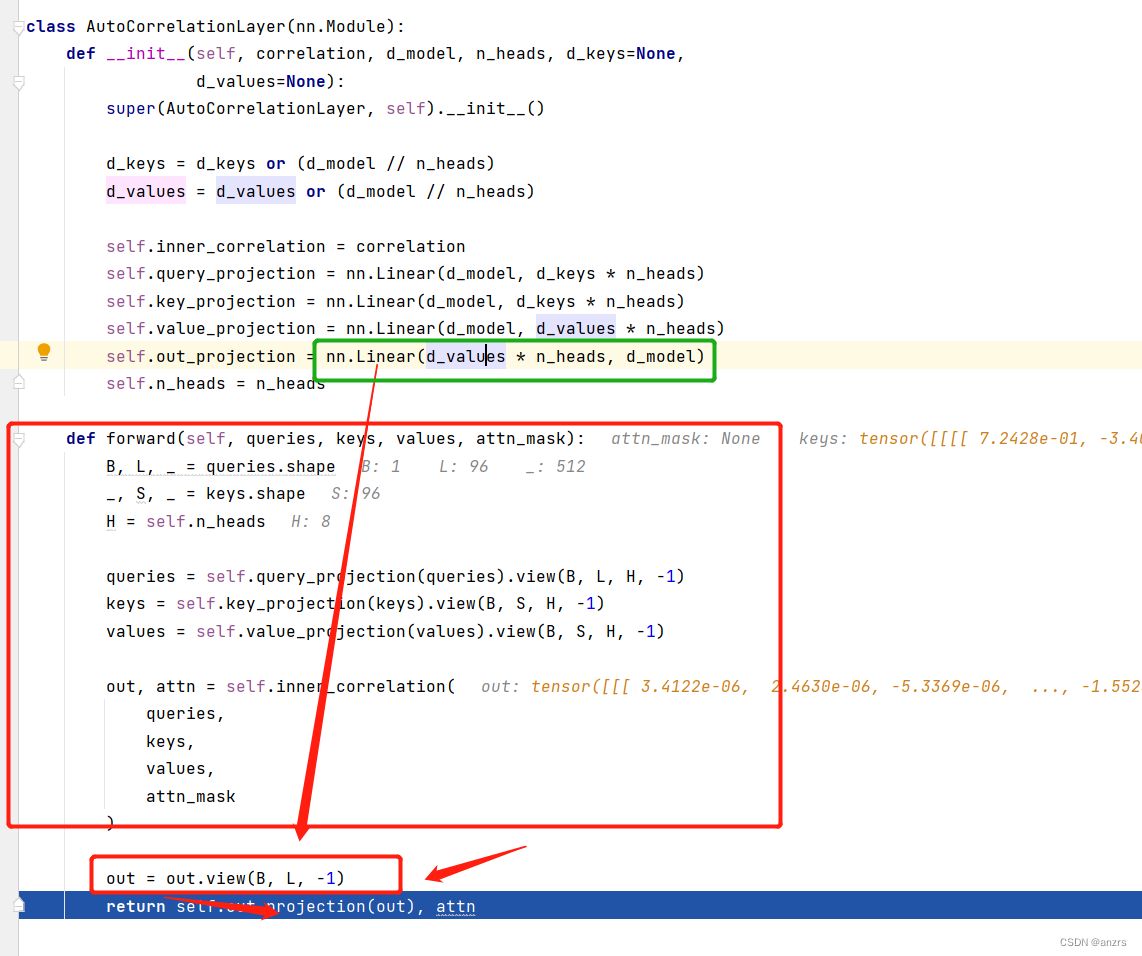
然后,回到了encoder_layer里面,可以看到,这里面加了很多的残差链接。
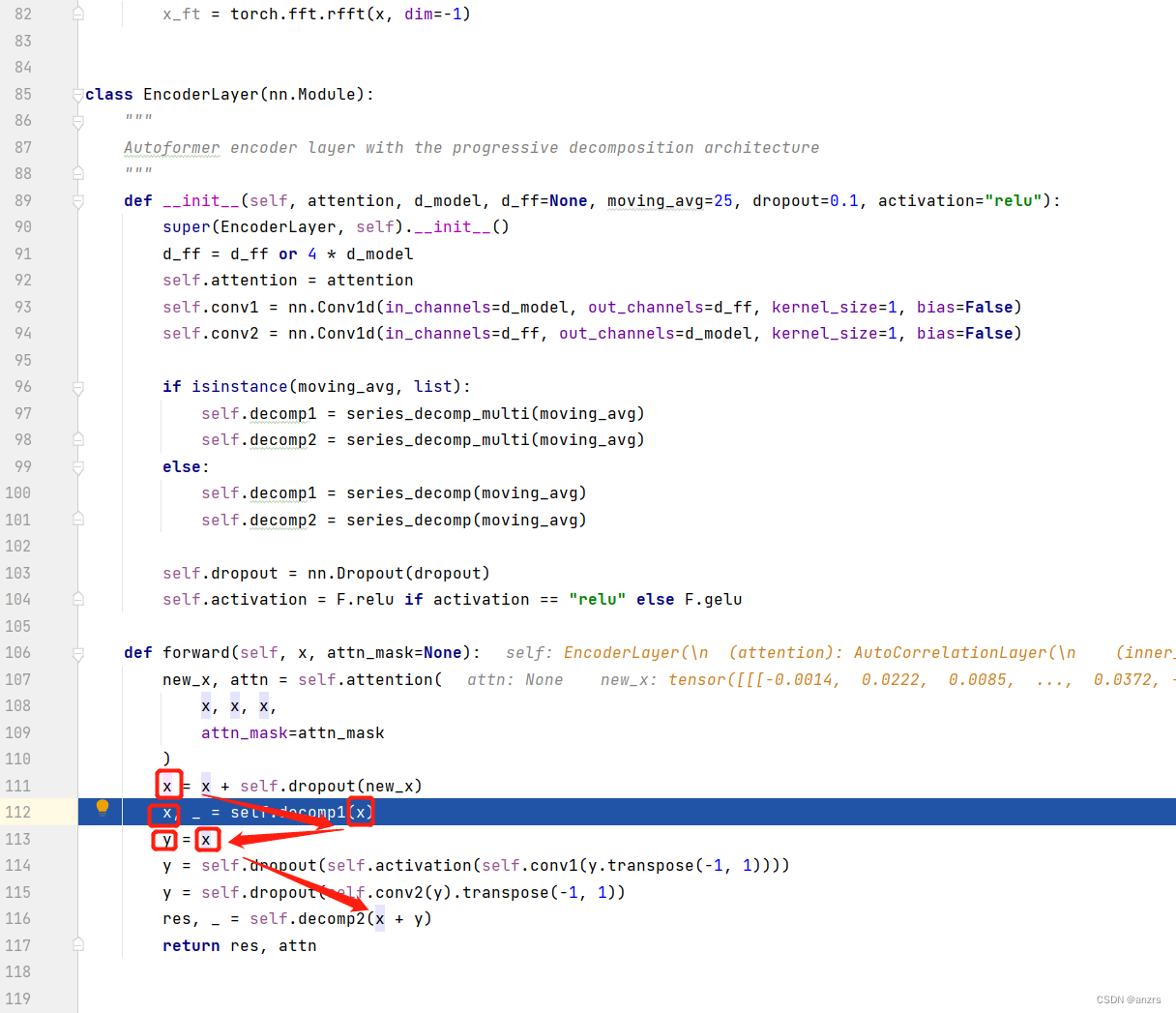
然后,我们来看一下这个decomp1和decomp2,是干什么的操作,。
注意,这里的x还是(1,96,512) 的维度的。
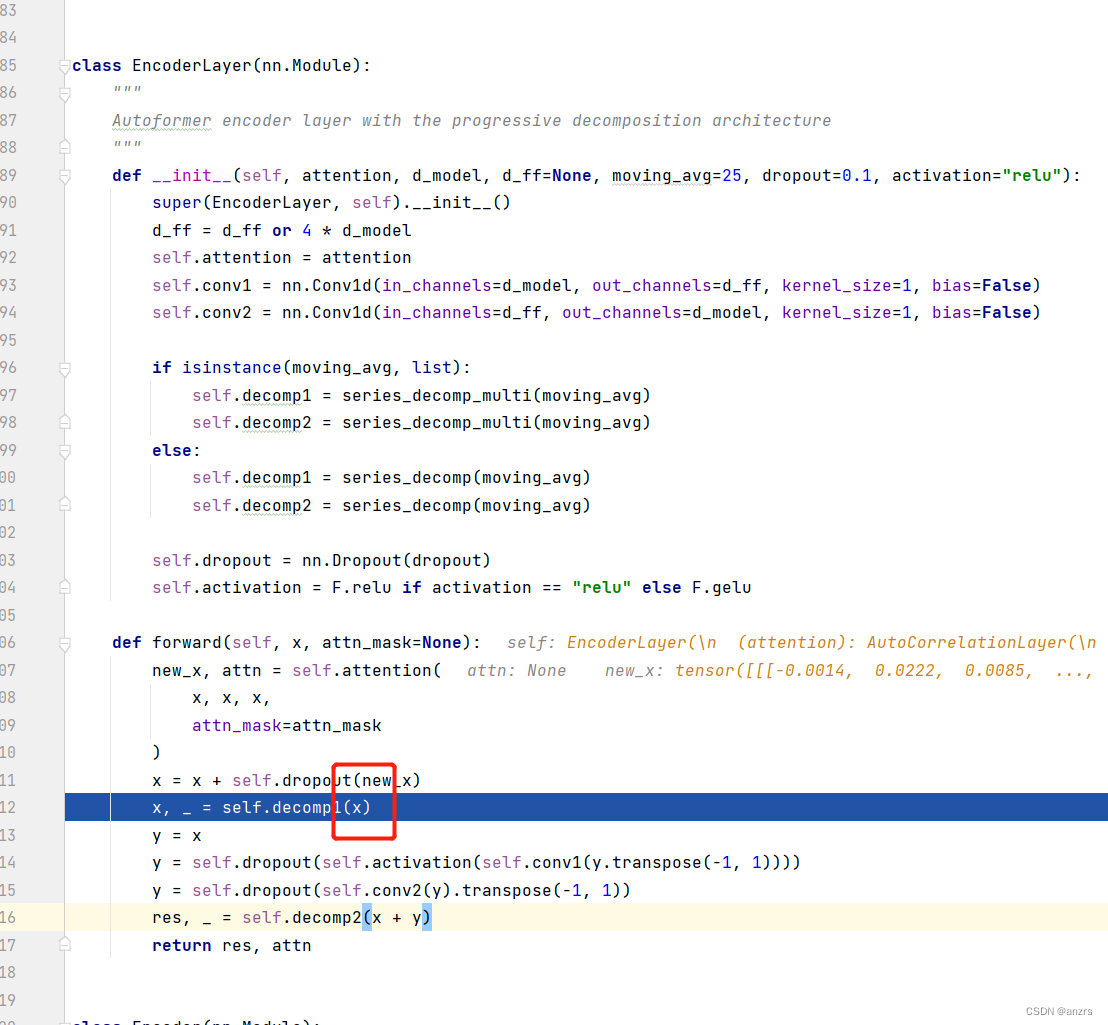
然后,进入了这个序列分解里面。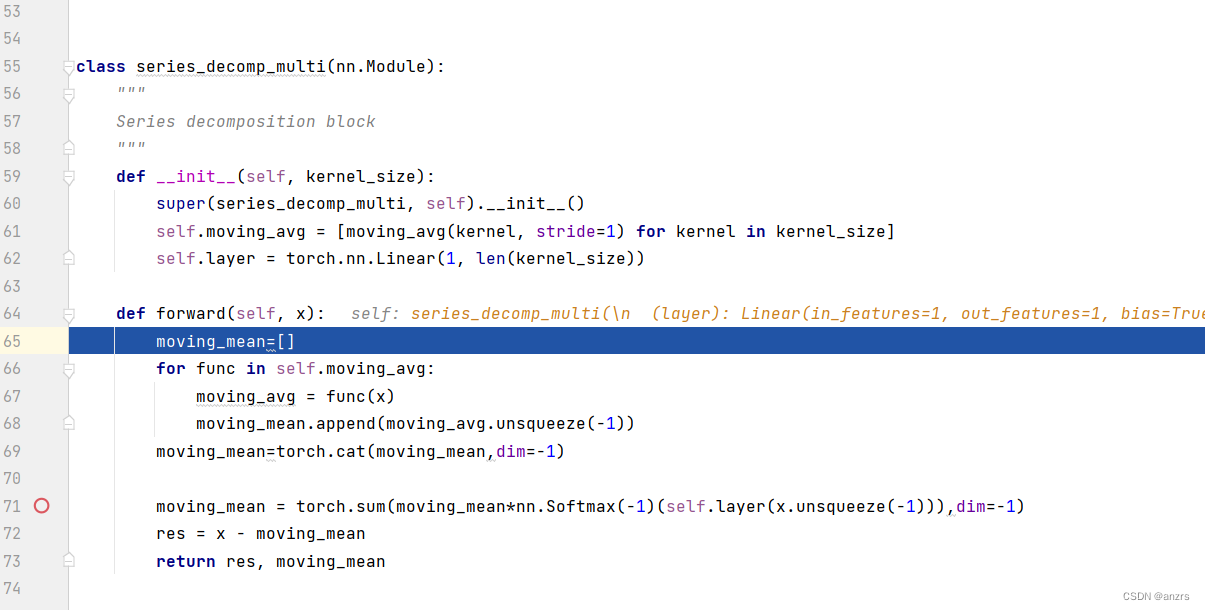
可以看到,这个里面还是只有两个东西
1(超大kernal组成的池化)
2 线性映射
可以看到,这个fedformer里面,都是由这些个重要的小组件构成的,只要理解了这个小组件,一步步的就能理解的很透彻。

可以看到,下面显示,这个x被decomp分解了两次,
然后,通过各种encoder,这个x会输出

然后,重复这个过程两遍,回到了原来的这个地方。
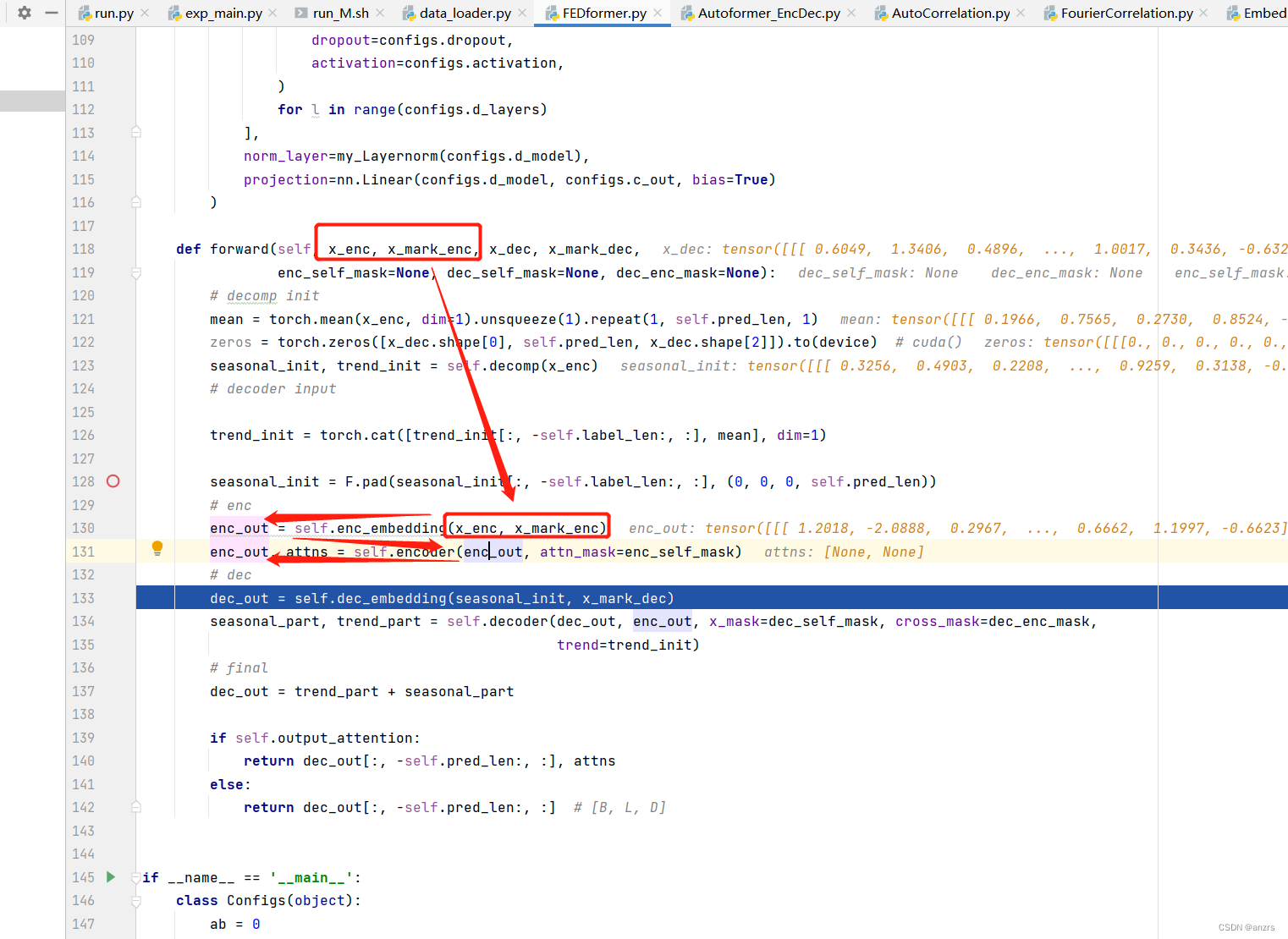
可以看到,encoder里面,用到的输入都是x_enc和他的marker,并没有其他部分。
下一步,到了decoder的不分,decoder的decoder_embedding的部分他的输入并不是纯粹的x_dec而是,seasonal_init这个和他的x_mark_dec这个东西,这是和传统的transformer是有区别的。
还是有一个疑问,为什么这个x_dec这个东西,他只用了一次生成了一个不用的zeros?
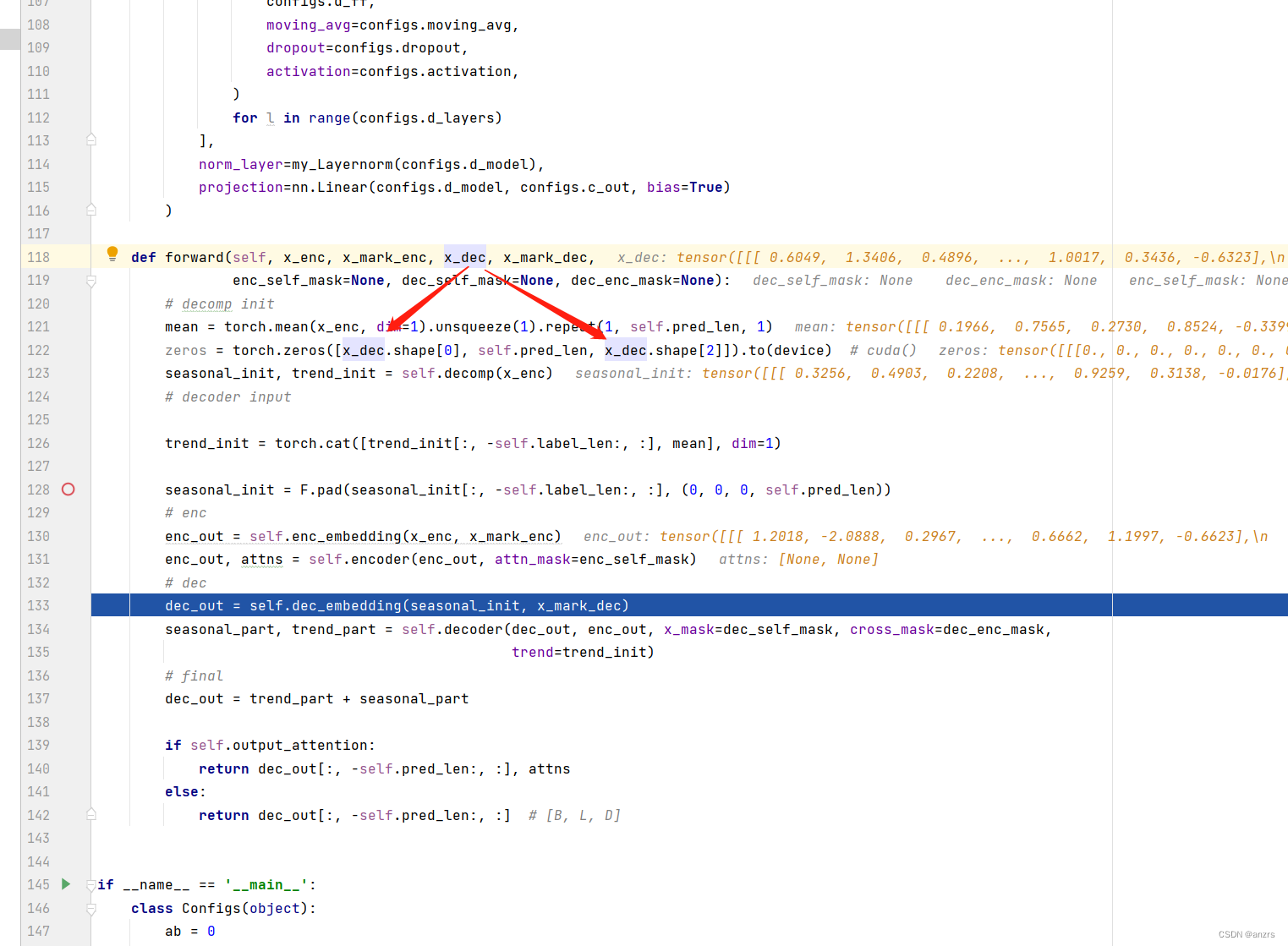
可以观察到,这个decoder的input的主要的东西,是x_enc的分解出来的东西。
这个seasonal_init的维度是(1,144,7)这个维度的。而,enc_out的维度是(1,96,512)的维度的。
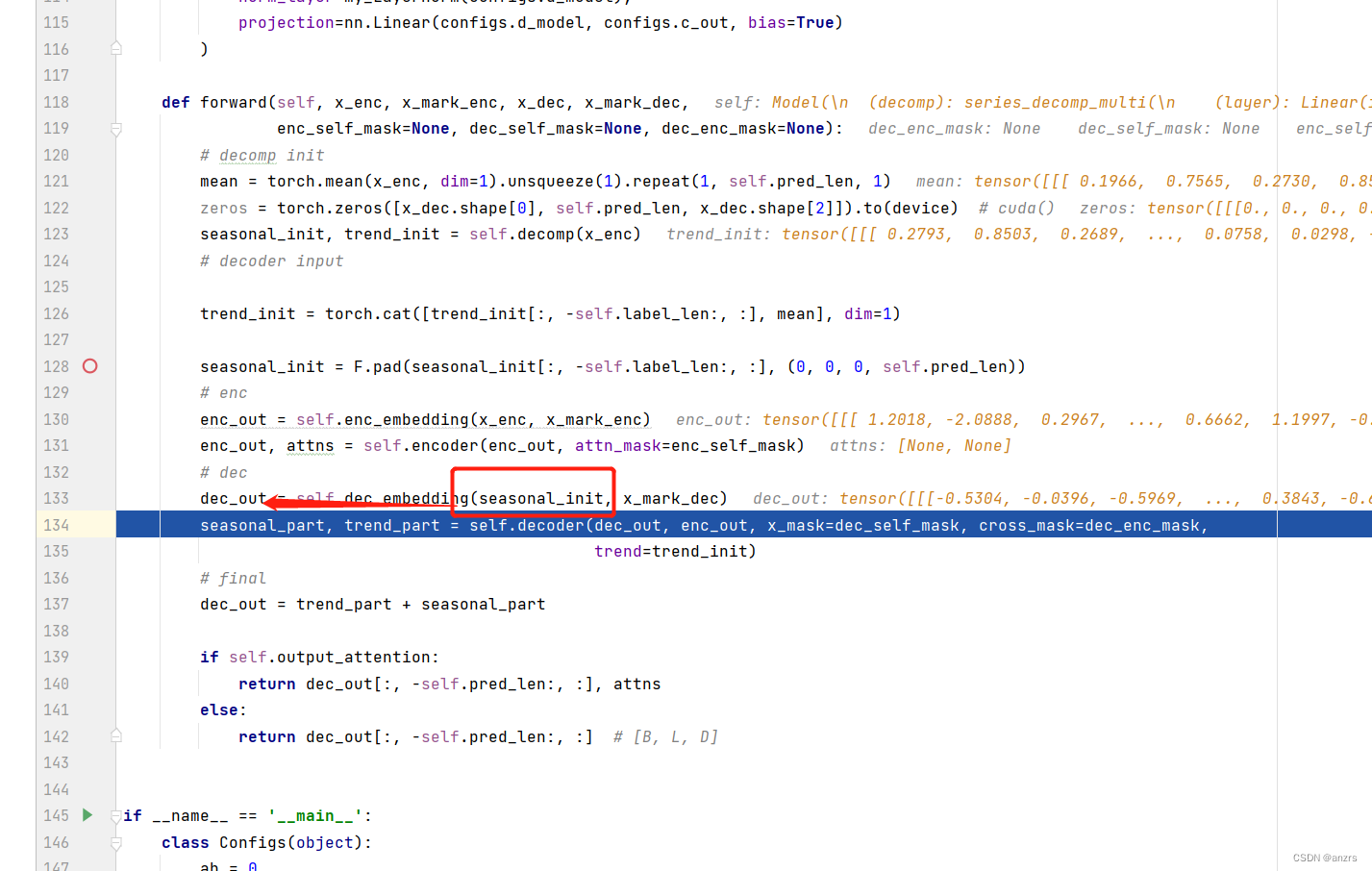
经过上面这一步之后,这个dec_out的维度也是512的维度的了。
即:他的维度是(1,144,512)这个维度的。
然后,注意一下,下面这个decoder的两个输入的维度。
dec_out的维度是(1,144,512)
enc_out的维度是(1,96,512)
trend_init的维度是(1,144,7)
然后进入了decoder里面,可以看到这个trend是没有发生进入运算的,只是进行一个叠加的过程。
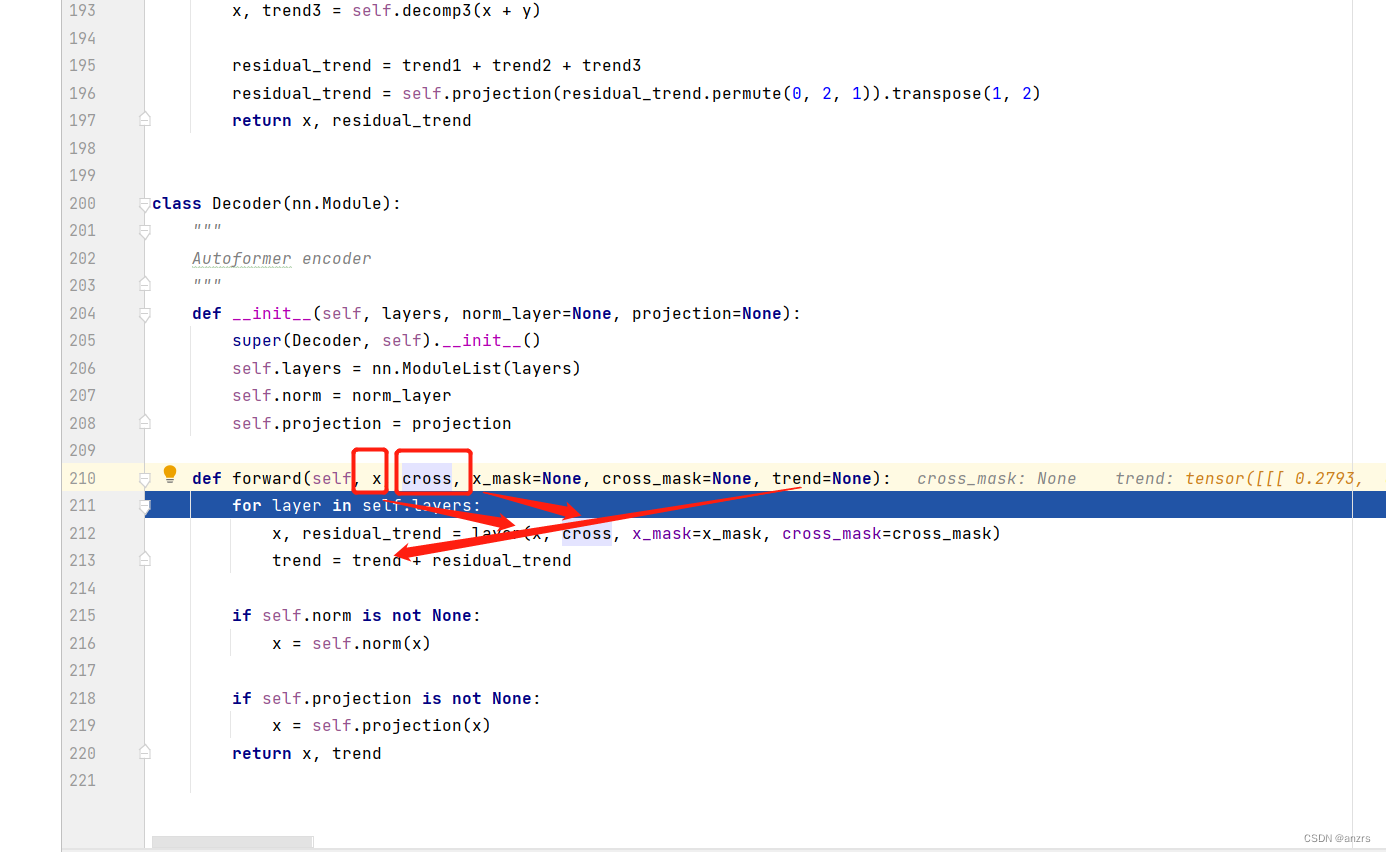
这和cross是encoder的输出,enc_out,这个x是dec_out。
然后,这两个东西就进入了decoder_layer里面,我们来看看这个东西他里面的东西有啥用,很明显他和encoder_layer是有区别的。

如下图,可以看到先是用x做了一个纯的attention。
然后,用x和cross,也就是encoder的输出做了一个交叉的attention。
可以看到,有两种不同的decomp的分解的情况,
其中一个是series_decomp_multi的分解,
另一个是series_decomp的分解。
一会看看这两个有什么区别。
可以看到,每次做一个attention,都会decomp一次。
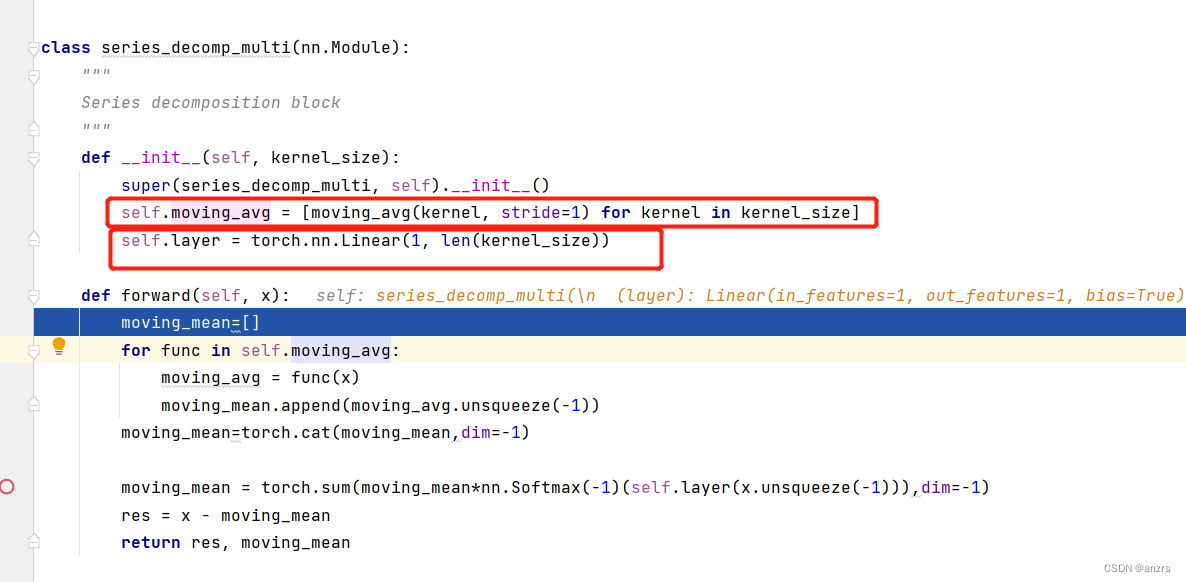
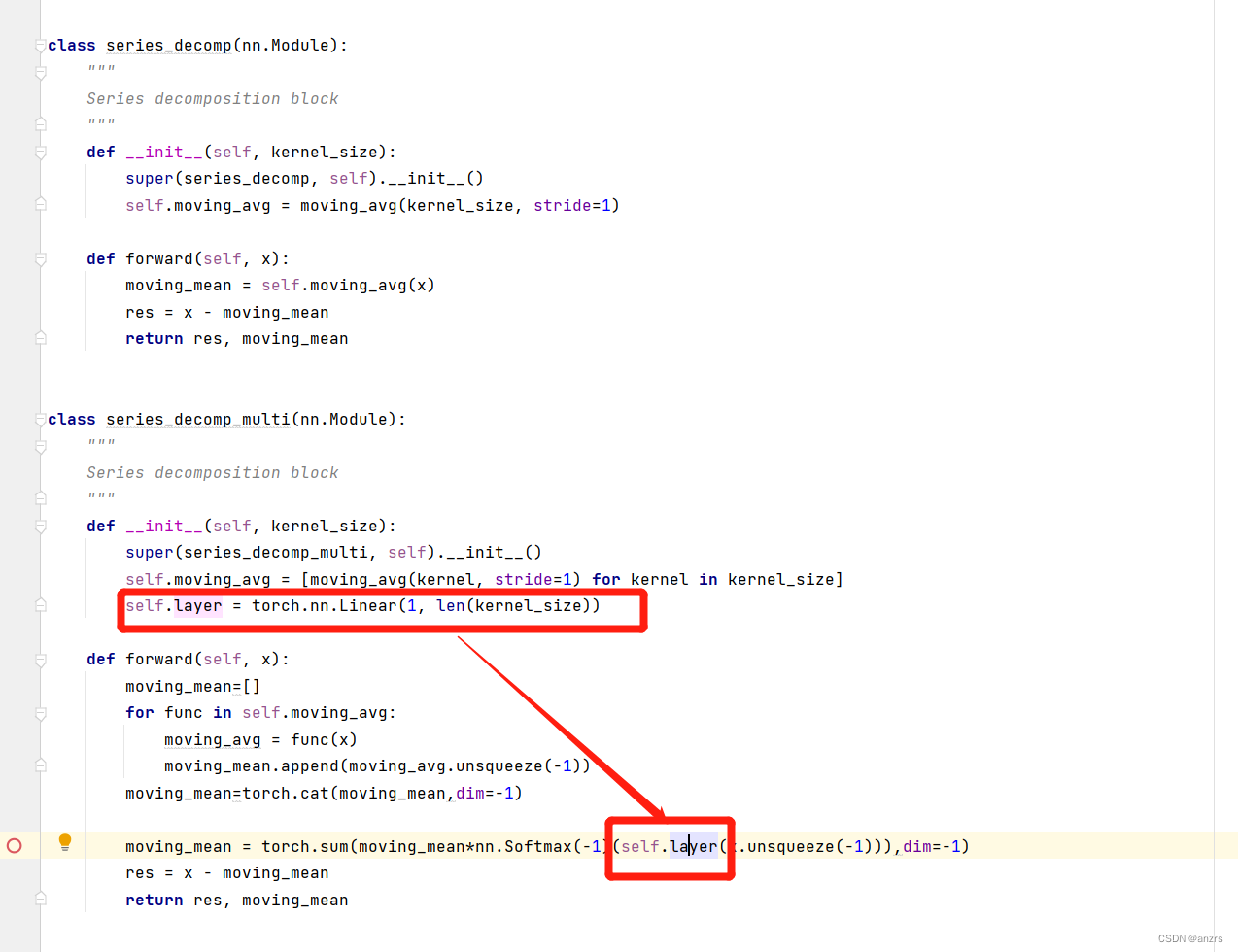
我们可以看到,两个series_decomp两个有区别。
一个是series_decomp,没有linear这个东西。
另外一个是series_decomp_multi这个东西,他是进行了好几次moving这个操作,然后将moving_mean这个东西进行堆叠,然后做了一个linear的操作。
dec_out是decoder的两个输出的相加。

这两个输出都是(1,144,7)这个维度的。
然后,这个decoder的out,就是输出的结果。他的维度是(1,96,7)这个维度的。
![[附源码]java毕业设计疫苗接种管理系统](https://img-blog.csdnimg.cn/9fb81c64f43a42dba18b38e183bb9488.png)