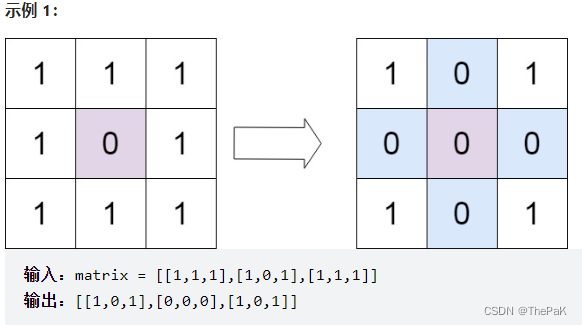
一、论文信息
论文名称:Joint Audio-Visual Deepfake Detection
会议:ICCV2021
作者团队:

二、动机与创新
动机
Visual deepfake上有许多检测方法和数据集,而对audio deepfake以及visual-audio两种模式之间的deepfake方法较少。Audio Deepfake主要有两个任务:1)TTS: text-to-speech文本转语音;2)VC:voice conversion语音转换(将一个人语音转为另一个人的声音)。
创新
本文提出一种新的视觉-听觉Deepfake联合检测任务,利用视觉和听觉两种模式之间的内在关系可以帮助deepfake检测。
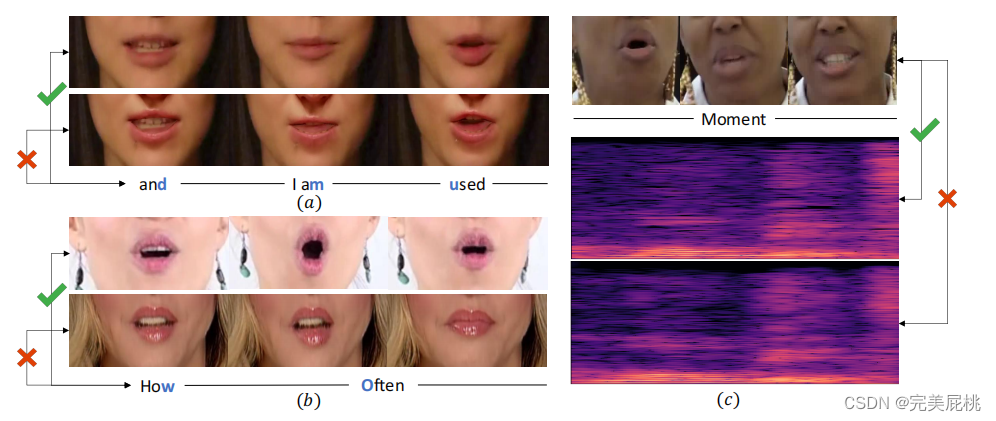
a中第一行视频帧未被修改,第二行是换脸之后的唇部图片,文字是两个视频中的话;b中第一行也是真实的,伪造视频中的唇形与发音存在较大差异。c中最上面一行是真实的视频帧,对应的真实的声谱图在第二行,TTS生成的声谱图在第三行,听起来像“wow-mount”,由第一行和第三行组成的视听对打破了由第一行和第二行保持的同步模式,作者希望在本文中捕捉到。
三、方法

(a)Independently trained video and audio streams(独立流)
Pv与Pa分别为视频和音频被判断为假的概率,F为特征提取器,将视频和音频的特征映射成对应的特征表示,再通过一个Fφ将其映射成标签,当视频和音频概率都小于0.5时整段视频才能判定为真,其中任一为假的概率大于0.5,则为假。backbone为2018年文章中的分类器,将其改为近期较好的分类器效果可能更好。

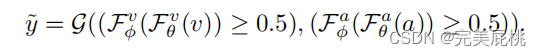
(b)Late fusion of video and audio streams(后融合)
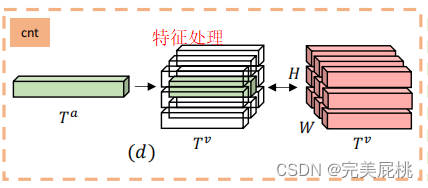
与a不同之处在于对网络的最后一层生成的特征直接进行融合(相加/拼接),文中将视频与音频流最后一层特征直接进行相加,再将融合后的特征放进一个分类头中进行预测。左边为视频流,维度为T,表示帧数,C为视频通道,HW为高宽;右边为音频流,长度为T,通道为C,对原始的声谱图直接处理,所以维度为1。G包括两个操作,先对两个流最后层的特征直接融合,再将融合后的特征直接放进分类头中分类。
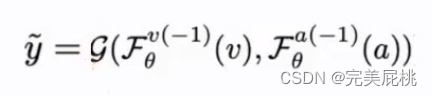
(c)Two-plus-one streams
其中视频流,维度为T,表示帧数,C为视频通道,HW为高宽;音频流,长度为T,通道为C,对原始的声谱图直接处理,所以维度为1。由于特征维度不匹配所以需要对音频特征进行一些处理:1)首先对音频特征进行了1x1卷积,经过卷积后将音频流的时间部分从Ta汇集到Tv,将音频流与视频流在时间维度上对齐。2)音频为1,视频为H*W,将音频流复制H*W次进行堆叠操作对齐空间轴,将音频信号堆叠成和视频信号一样的维度表示,最后通过联合训练的方法,网络随着时间推移自动学习音频和视频之间对应关系,在每一层音频和视频的表示将与当前同步流融合作为下一层融合的输入。
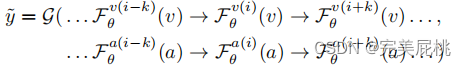

-
inter-attention
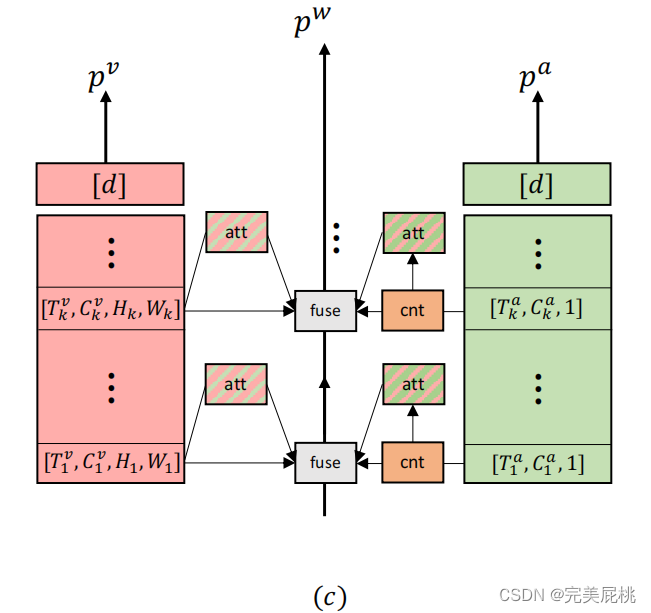
将音视频产生的特征通过下面的公式计算两者之间相关性,然后融合:
Fa为Ta x H x W,Fv转置为H x W x Tv,两个相乘以后得到Ta x Tv,经过上一步将Ta转化为Tv,最终得到了一个Tv x Tv的矩阵e,以第一格为例,横行为来自视频流的一帧特征,竖行为来自音频流的一帧特征,重合部分就是相同帧中音视频的关联性,灰色越深关联性越强。引用注意力机制加强音视频之间的关联性。


-
inter+intra-attention
音视频特征先分别计算各自的相关性,然后融合:

-
Joint-attention
直接将音视频特征进行联立求关联性:
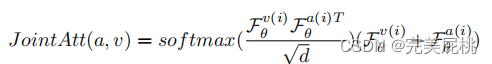
将视频的所有视频帧对应的图片和音频的关联性联合起来,最后做预测pw
四、实验
数据集
-
FF++: 包含5000个带有音频通道的视频序列,其中大多数语音不是英语,但实验性能并没有下降,表明方法实际上是有泛化性的。
-
DFDC:拥有超过100000个英文视频和音频序列,为了确保视听同步,作者移除了那些声音来自摄影师而非演员的序列(画外音)。
-
遵循原始数据中的train/val/test分割,并随机地将真实音频和合成音频交换,对于测试保持“真假”(视频真音频假)、“假真”、“真真”和“假假”的数量平衡。
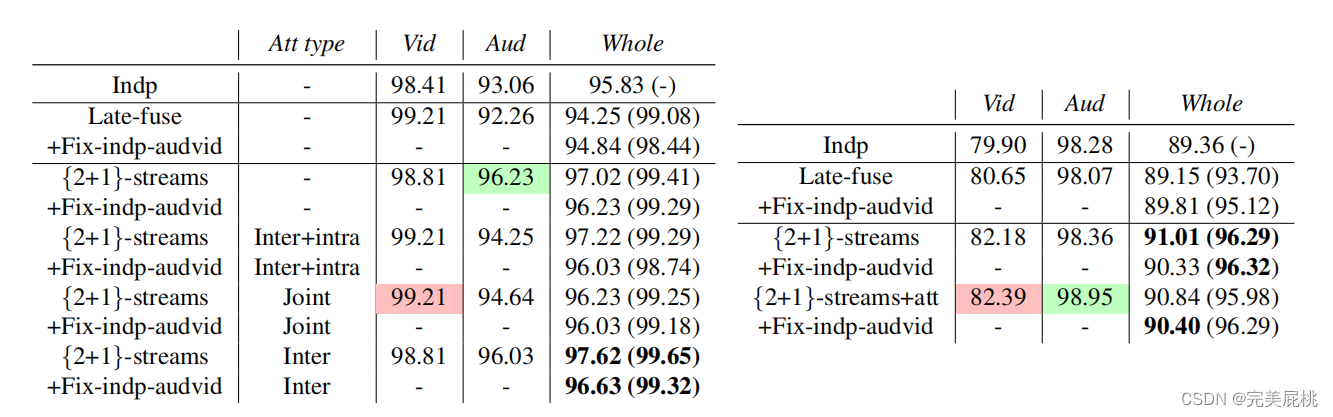
性能
FF++数据集性能(左)、DFDC数据集性能(右)
五、总结
本文提出了一个通过联合视频和音频模式来检测deepfake的新任务,我们事先不知道视频还是音频被操纵,本文利用学习到的视频和音频之间的内在同步提高了基于视频和音频的deepfake检测的性能,同时泛化性不错。