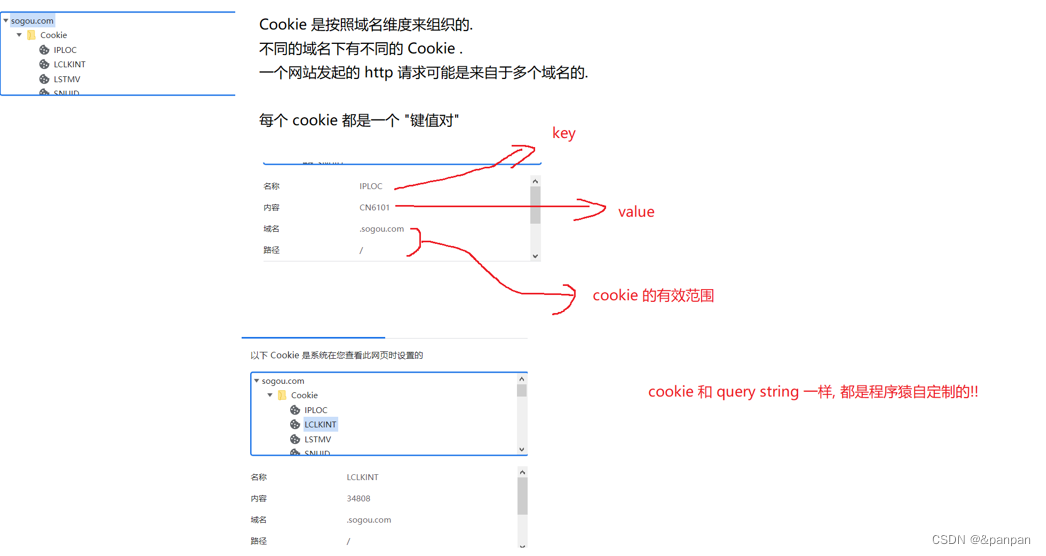
学习总结:
- 一般的RNN模型我们的输入和输出是什么,我们对RNN输入一个序列
X
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
X = [x^1,x^2,...,x^n]
X=[x1,x2,...,xn] ,注意我们序列中的每一个节点都是一个向量,那么我们的RNN会给我们的输出也是一个序列
Y
=
[
y
1
,
y
2
,
.
.
.
,
y
n
]
Y = [y^1,y^2,...,y^n]
Y=[y1,y2,...,yn], 那我们如何通过RNN提取出输入序列的特征呢,常用做法有两种(GRU4Rec用的第一种获得序列表征):
- 取出 y n y^n yn的向量表征作为序列的特征,这里可以认为 x 1 , x 2 , … , x n x^1, x^2, \ldots, x^n x1,x2,…,xn的所有信息,所有可以简单的认为 y n y^n yn的结果代表序列的表征
- 对所有时间步的特征输出做一个Mean Pooling,也就是对 Y = [ y 1 , y 2 , . . . , y n ] Y = [y^1,y^2,...,y^n] Y=[y1,y2,...,yn] 做均值处理,以此得到序列的表征
- GRU4Rec亮点在于设计了mini-batch和高效的sampling方法。
- 本质是多分类问题:得到用户embedding后,直接通过多分类进行损失计算,多分类的标签是用户下一次点击的item的index,直接通过User的向量表征和所有的Item的向量做内积算出User对所有Item的点击概率(一个
score),然后通过Softmax进行多分类损失计算 。 - listwise训练模式的Loss 为
torch.nn.CrossEntropyLoss, 即对输出进行 Softmax 处理后取交叉熵。 - 本task还学习
faiss向量检索库和TSNE的Embedding分布可视化。
- 本质是多分类问题:得到用户embedding后,直接通过多分类进行损失计算,多分类的标签是用户下一次点击的item的index,直接通过User的向量表征和所有的Item的向量做内积算出User对所有Item的点击概率(一个
- 回顾DIEN:利用 AUGRU(GRU with Attention Update Gate) 组成的序列模型,在兴趣抽取层GRU基础上加入注意力机制,模拟与当前目标广告(Target Ad)相关的兴趣进化过程,兴趣进化层的最后一个状态的输出就是用户当前的兴趣向量 h’(T)。
文章目录
- 学习总结:
- 一、序列召回基础
- 1.1 推荐系统
- 1.2 推荐系统中的召回
- (1)基于规则的召回算法
- (2)基于协调过滤的召回算法
- (3)基于向量的召回算法
- 1)基于I2I的召回算法
- 2)基于U2I的召回算法
- (4)表征学习 / 匹配函数的学习
- 二、基于GRU4Rec的基础序列召回
- 2.1 GRU模型
- 2.2 基于GRU的序列召回
- 1)用户嵌入提取和模型训练
- 2)模型验证和faiss向量召回
- 3)损失函数
- (1)Point wise (很多CTR模型使用)
- (2)Pair wise (BRP损失函数)
- (3)List wise(softmax后交叉熵)
- 2.3 GRU4Rec中的trick
- 三、GRU4Rec代码实践
- 3.1 Dataset类
- 3.2 GRU4Rec模型定义
- (1)paddle版实现
- 3.3 Pipeline
- 3.4 基于Faiss的向量召回
- 3.5 基于TSNE的Item Embedding分布可视化
- 时间安排
- Reference
一、序列召回基础
1.1 推荐系统
推荐系统中采用一种“漏斗”的形式,将算法分为多个阶段来进行推荐:
- 召回:待计算的候选集合大、计算速度快、模型简单、特征较少,尽量让用户感兴趣的物品在这个阶段能够被快速召回,即保证相关物品的召回率。常用的有多路召回(即多种策略进行召回),embedding向量召回
- 精排:首要目标是得到精准的排序结果。需要处理的物品数量少,可以利用较多的特征,使用比较复杂的模型
- 重排:为了避免排序阶段的结果趋于同质化,让用户有更好的体验,这里对排序的结果进行多样化考虑,提高用户的使用体验

1.2 推荐系统中的召回
由于召回算法是面对全部的Item进行计算筛选的,所以我们的召回算法的核心特点如下:算法结构简单;计算效率高;准确率不需要太高;每一种召回算法都会针对性解决某一类问题。一把可以将召回算法分为以下类别:
- 基于规则
- 基于协同过滤
- 向量召回
(1)基于规则的召回算法
基于规则的召回算法比较好理解,就是我们通常的一些运营规则,例如:
- 召回点击次数最多的Item
- 召回购买次数最多的Item
- 召回购买金额最多的Item
- 召回地域最热的Item
- …
可以看出这种召回算法属于最原始的笨办法,但是这种方法虽然在算法层面的技术难度不高,但是要做出一个非常优秀的策略也是需要极强的业务理解以及极大的人力投入的。
(2)基于协调过滤的召回算法
基于协调过滤的方法有以下的两个大流派:
- 基于统计的协同过滤
- 基于MF(Matrix Factorization)的协同过滤
首先我们讨论一下基于统计的协同过滤模型,这种模型是完全基于用户行为记录的统计信息的,不涉及机器学习/深度学习模型的建模以及训练,在基于统计的协同过滤中,一般按照视角分为两种协同过滤模型。
- 基于User的协同过滤
- 基于Item的协同过滤

这两个协同过滤模型的核心思想是统一的,对于基于User的协同过滤模型而言,其核心的假设是:相似的用户可能喜欢相同物品。
- 这一点当然十分符合我们的直观感受了,实际上就是将用户喜欢的商品推荐给和这个用户相似的用户;
- 所以重点就落在了如何“度量”两个用户的相似度,最直观的做法就是统计两个用户共同喜欢的Item的个数,如果两个用户共同喜欢的Item个数越多,那是不是就代表着两个用户就“越相似”,核心思路是这样的,但是在实际的计算过程中会加一些系数修正。
那么对于基于Item的协同过滤也一样,其核心的假设是:相似的物品可能被同个用户喜欢。
- 我们会对推荐用户喜欢的Item的相似Item,那我们这里的核心其实就是“度量”两个Item的相似度,这里的最直观的做法就是:统计两个Item被用户同时喜欢的次数,可以简单的认为如果两个Item同时在用户喜欢列表中出现的次数越多,就可以认为这两个Item相似,当然了实际实现的时候也会加一些修正系数。
- 基于MF的协同过滤模型相当于是在基于User-Item的交互矩阵的基础上进行分解的,其示意图如下。也可以简单的认为我们通过Embedding方法对User/Item分别学习到一个向量表征,然后使用内积的方法来计算User-Item的交互概率。

(3)基于向量的召回算法
基于向量的召回算法算是大量需要深度学习的一个召回算法的流派了,其主要可以分为一下流派:
- I2I:计算item-item相似度,用于相似推荐、相关推荐、关联推荐
- U2I:基于矩阵分解,直接给用户推荐item
- U2U2I:基于用户的协同过滤,先找相似用户,再推荐相似用户喜欢的item
- U2I2I:基于物品的协同过滤,先统计用户喜爱的item,再推荐他喜欢的item
- U2TAG2I:基于标签偏好推荐,先统计用户偏好的tag,然后匹配所有的item;其中tag一般是item的标签、分类、关键词等。
- X2X2X2X:…
其中这里用的最多的就是I2I和U2I这两类算法:
1)基于I2I的召回算法
(1)基于I2I的召回算法大致有如下两个流派:
- Item-Item相似度可以通过内容理解来生产Item向量,通过向量相似度来度量
- Item-Item相似度可以通过图表示学习/GNN来生产Item向量,通过向量相似度来度量
这里的I2I向量召回的核心就是通过某种算法生产出Item的向量表征,然后通过向量的相似度来进行召回,其中Faiss可以帮助我们快速的在大规模向量中找出和Query向量最相似的Top-K个向量,这就解决了我们向量召回计算效率的问题。
2)基于U2I的召回算法
(2)基于U2I的召回算法大致有如下两个流派:
- 输入User特征和Item特征,直接对齐User与Item的向量表征:一般是双塔模型,如DSSM等。
- 通过User的历史序列提取User的向量表征,然后和Item的表征对齐。即将User的向量在全部的Item向量中进行召回,也是本次学习的主题【序列召回】。核心在两个点:
- 序列信息的利用以及系列特征的提取
- 如何通过序列构建User的向量表征
(4)表征学习 / 匹配函数的学习
召回算法一般分类:
- 表征学习:如下图,input representation可以是无序交互特征、序列特征、多模态、图数据等。
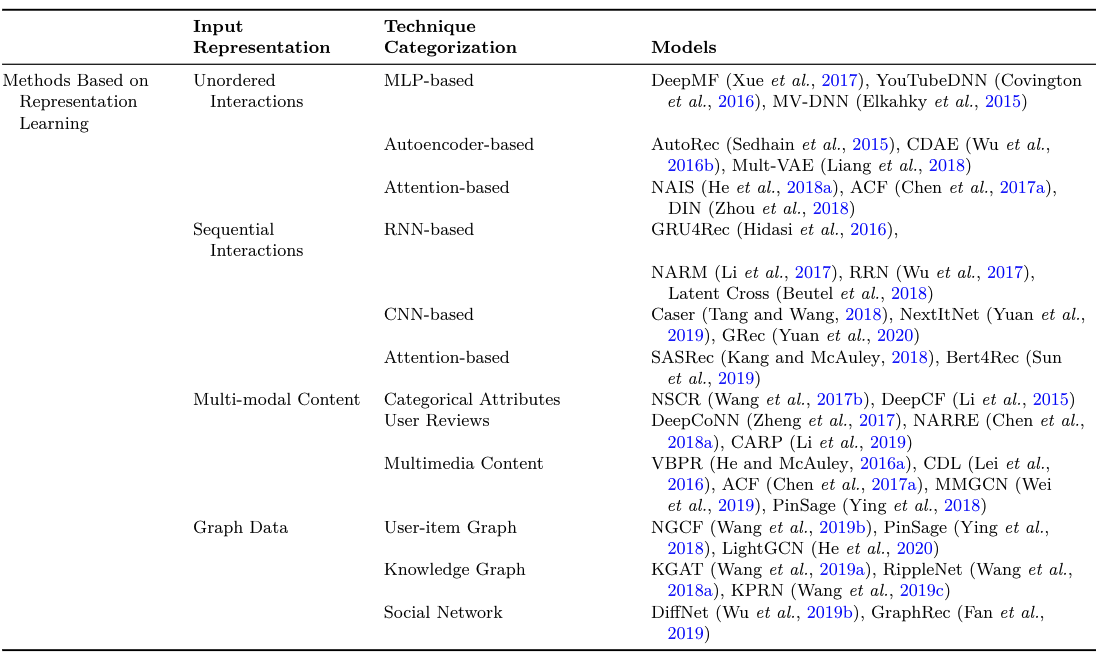
- 匹配函数的学习:如下图

上图摘自《Deep Learning for Matching in Search and Recommendation》李航,何向南 第五章
二、基于GRU4Rec的基础序列召回
2.1 GRU模型

(1)首先我们明确一下对于一个一般的RNN模型我们的输入和输出是什么,由上图可以看出,我们对RNN输入一个序列 X = [ x 1 , x 2 , . . . , x n ] X = [x^1,x^2,...,x^n] X=[x1,x2,...,xn] ,这里需要注意,我们序列中的每一个节点都是一个向量,那么我们的RNN会给我们的输出也是一个序列 Y = [ y 1 , y 2 , . . . , y n ] Y = [y^1,y^2,...,y^n] Y=[y1,y2,...,yn], 那我们如何通过RNN提取出输入序列的特征呢,这里常用的做法有两种:
- 取出 y n y^n yn的向量表征作为序列的特征,这里可以认为 x 1 , x 2 , … , x n x^1, x^2, \ldots, x^n x1,x2,…,xn的所有信息,所有可以简单的认为 y n y^n yn的结果代表序列的表征
- 对每一个时间步的特征输出做一个Mean Pooling,也就是对 Y = [ y 1 , y 2 , . . . , y n ] Y = [y^1,y^2,...,y^n] Y=[y1,y2,...,yn] 做均值处理,以此得到序列的表征
(2)这里我们选择第一种方法来获取序列表征,在明确了RNN的一般处理机制之后,我们就会发现,RNN中可以操作的主要集中在对每个时间步i信息和前i-1信息的处理上,这就衍生出LSTM,GRU等一系列方案。GRU的计算逻辑:
- GRU(Gate Recurrent Unit 门控循环单元)是介于RNN和LSTM的网络,只有两个门(更新门zt和重置门rt,结构比LSTM简单,性能却相当)。可以参考
torch官方文档的API介绍。 - 更新门zt:控制前一时刻的状态信息被带入到当前状态的程度,zt越大则说明带入的信息越多。
- 重置门rt:控制前一状态有多少信息被写入到当前的候选集 h ~ t \tilde{h}_t h~t上,重置门越小前一状态的信息被写入的就越少。

2.2 基于GRU的序列召回
1)用户嵌入提取和模型训练

我们这里首先对Item进行Embedding操作,这里的Embedding层可以认为是一张表,他内部存储的是每一个Item ID到其向量表征的映射,例如:我有10个Item,我想对每个Item表征成一个4维的向量,那么我们可以有如下的Embedding层:
#声明一个10个Item,维度为4的Embedding表
emb_layer = nn.Embedding(10,4)
# 比如我查询index为 [1,0,1,2,3]的向量
query_index = paddle.to_tensor([1,0,1,2,3])
# 可以看出embedding内部的存储是一个10x4的二维矩阵,其中每一行都是一个4维的向量,也就是一个item的向量表征
print(emb_layer.weight)
# 查询结果是对应index对应在embedding里面的行向量
print(emb_layer(query_index))
在获取Item的Embedding向量之后,我们就对序列进行GRU特征提取,注意我们选择的是GRU输出的最后一个节点的向量,我们将这个向量作为序列整体的特征表达:
seq_emb = self.item_emb(item_seq)
seq_emb,_ = self.gru(seq_emb)
user_emb = seq_emb[:,-1,:] #取GRU输出的最后一个Hidden作为User的Embedding
得到用户embedding后,直接通过多分类进行损失计算,多分类的标签是用户下一次点击的item的index,直接通过User的向量表征和所有的Item的向量做内积算出User对所有Item的点击概率,然后通过Softmax进行多分类损失计算:
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
2)模型验证和faiss向量召回
- 数据集是:Movielens-20M,我们对其按照User进行了数据划分,按照
8:1:1的比例做成了train/valid/test数据集。 - 对于测试阶段,我们选择用户的前80%的行为作为序列输入,我们的标签是用户后20%的行为,使用Faiss进行向量召回:
# 第一步:我们获取所有Item的Embedding表征,然后将其插入Faiss(向量数据库)中
item_embs = model.output_items().cpu().detach().numpy()
item_embs = normalize(item_embs, norm='l2')
gpu_index = faiss.IndexFlatIP(hidden_size)
gpu_index.add(item_embs)
# 第二步:根据用户的行为序列生产User的向量表征
user_embs = model(item_seq,mask,None,train=False)['user_emb']
user_embs = user_embs.cpu().detach().numpy()
# 第三步:对User的向量表征在所有Item的向量中进行Top-K检索
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
3)损失函数
pointwise排序不适合该类网络,作者使用了pairwise(正样本的score大于负样本即可)方式训练,并且损失函数为BPR(Bayesian Personalized Ranking)或TOP1。
(1)BPR考虑用户物品交互中的可观察项和不可观察项的相对顺序,BPR假定更能反映出用户偏好的可观察项的交互相较于那些不可观察项来说应该赋予高的预测值。BPR损失函数:
Loss
=
∑
(
u
,
i
,
j
)
∈
O
−
ln
σ
(
y
^
u
i
−
y
^
u
j
)
+
λ
∥
Θ
∥
2
2
\text { Loss }=\sum_{(u, i, j) \in O}-\ln \sigma\left(\hat{y}_{u i}-\hat{y}_{u j}\right)+\lambda\|\Theta\|_2^2
Loss =(u,i,j)∈O∑−lnσ(y^ui−y^uj)+λ∥Θ∥22
(2)TOP1 loss是对bpr loss的一个改进,相比bpr 在loss 后面加了一项负样本正则项(二范数),希望负样本评分越小越好:
L
s
=
1
N
s
∑
j
=
1
N
s
σ
(
r
^
s
,
j
−
r
^
s
,
i
)
+
σ
(
r
^
s
,
j
2
)
L_s=\frac{1}{N_s} \sum_{j=1}^{N_s} \sigma\left(\hat{r}_{s, j}-\hat{r}_{s, i}\right)+\sigma\left(\hat{r}_{s, j}^2\right)
Ls=Ns1j=1∑Nsσ(r^s,j−r^s,i)+σ(r^s,j2)
TOP1损失函数:使用传统的bpr loss进行优化时,可能会面临正负样本的评分都持续增长的问题。比如1 5 8的例子,优化1的时候,一定希望1对于第一个序列评分高,5较低;而优化5的时候,一定希望1评分低,5评分高。当GRU面临可能的梯度消失问题时,可能丧失user的序列特征,只关注于当下的物品,如果序列的局部比较接近,就会使模型优化在1,5之间陷入两难局面。所以才会正负采样的评分同步增长。
为了后面代码的复用,下面和后面的task都是使用listwise进行模型训练。关于三种训练方式这里做一个回顾:【召回中的三种训练方式】,召回中,一般的训练方式分为三种:point-wise、pair-wise、list-wise。每一种不同的训练方式也对应不同的Loss。参考下图,其中a表示user的embedding,b+表示正样本的embedding,b-表示负样本的embedding。

(1)Point wise (很多CTR模型使用)
思想:将召回视作二分类,独立看待每个正样本、负样本。
对于一个召回模型:
- 输入二元组<User, Item>,
- 输出 P ( U s e r P(U s e r P(User, Item ) ) ), 表示 User 对 Item 的感兴趣程度。
- 训练目标为: 若物品为正样本, 输出 cos ( a , b ) \cos (\mathbf{a}, \mathbf{b}) cos(a,b)应尽可能接近 1 , 负样本则输出尽可能接近 0 。 采用的 Loss 最常见的就是 BCELoss(Binary Cross Entropy Loss)。
- 控制正负样本数量为1:2或者1:3
(2)Pair wise (BRP损失函数)
思想:用户对正样本感兴趣的程度应该大于负样本。


改进的损失函数Logistic loss:

对于一个召回模型:
- 输入三元组<User, ItemPositive, ItemNegative>,
- 输出兴趣得分 P ( P( P( User, ItemPositive ) , P ( ), P( ),P( User, ItemNegative ) ) ), 表示用户对正样本物品和负样 本物品的兴趣得分。
- 训练目标为:正样本的兴趣得分应尽可能大于负样本的兴趣得分。
Loss 为 BPRLoss(Bayes Personalized Ranking Loss)。Loss 的公式这里放 一个公式, 详细可以参考【贝叶斯个性化排序(BPR)算法小结】(链接里的内容和下面的公式有些细微的差别, 但是思想是一 样的)。公式: L o s s = 1 N ∑ N i i = 1 − log ( L o s s=\frac{1}{N} \sum^{N} i_{i=1}-\log ( Loss=N1∑Nii=1−log( sigmoid ( ( ( pos_score − - − neg_score ) ) )) ))。
(3)List wise(softmax后交叉熵)
思想:思想同Pair wise,但是实现上不同。

引入Softmax 激活函数,最小化交叉熵损失,相当于最大化
S
+
\mathrm{S}^{+}
S+,也即最大化正样本的相似度。

对于一个召回模型:
- 输入 N + 2 \boldsymbol{N}+2 N+2 元 组 ⟨ \langle ⟨ User, ItemPositive, ItemNeg_1,…, ItemNeg_N ⟩ \rangle ⟩;
- 输出用户对 1 个正样本和 N \mathrm{N} N 个负样本的兴趣得分。
- 训练目标为:对正样本的兴趣得分应该尽可能大于其他所有负样本的兴趣得分。 Loss 为
torch.nn.CrossEntropyLoss, 即对输出进行 Softmax 处理后取交叉熵。
PS: 召回的 List wise 方式容易和 Ranking 中的 List wise 混淆, 虽然二者名字一样, 但 ranking 的 List wise 考虑了样本之间的顺序关系。例如 ranking 中会考虑 MAP、NDCP 等考虑顺序的指标作为评价指标, 而 Matching 中的 List wise 没有考虑顺序。
2.3 GRU4Rec中的trick
(1)session-parallel mini-batch:一般RNN如果为了用batch加速,需要统一长度(长度短的就进行padding),但是由于推荐系统中item长尾分布,长序列和短序列相差很大,padding方法不合适。
下图中是五个并行的session, 每次输入到GRU中的是每一个序列
s
s
s 在
t
s
t_s
ts 时刻的行为, GRU预测序列在
t
s
+
1
t_s+1
ts+1 的行为, 由于序列有长有短, 所以当一个序列并行结束后, 将新的序列补进来, 这样可以最大限度提高并行效率, 甚至不需要padding。

(2)基于流行度的负采样,并且在batch中负采样:在目标样本中根据热门程度进行采样,采样后将同一个mini-batch中,但是是其他session内的next-item作为负样本,用这些正负样本进行训练模型。如下图: 序列的next-item的gt是1, 5, 8对于1来讲 5,8是负样本。

和随机抽样相比,优势有两个: 一个是基于pop的采样,可解释性更强,另一个是对于batch内需要计算的item是一致的,那么可以将batch内所有序列的next-item预测,统一成一个矩阵运算,大大降低显存占用。
三、GRU4Rec代码实践
3.1 Dataset类
这里的hist_mask_list是像transformer一样的mask处理序列长短不一致的问题。
class SeqnenceDataset(Dataset):
def __init__(self, config, df, phase='train'):
self.config = config
self.df = df
self.max_length = self.config['max_length']
self.df = self.df.sort_values(by=['user_id', 'timestamp'])
self.user2item = self.df.groupby('user_id')['item_id'].apply(list).to_dict()
self.user_list = self.df['user_id'].unique()
self.phase = phase
def __len__(self, ):
return len(self.user2item)
def __getitem__(self, index):
if self.phase == 'train':
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = random.choice(range(4, len(item_list))) # 从[8,len(item_list))中随机选择一个index
# k = np.random.randint(2,len(item_list))
item_id = item_list[k] # 该index对应的item加入item_id_list
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), paddle.to_tensor([item_id])
else:
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = int(0.8 * len(item_list))
# k = len(item_list)-1
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), item_list[k:]
# 用后20%作为测试集
def get_test_gd(self):
self.test_gd = {}
for user in self.user2item:
item_list = self.user2item[user]
test_item_index = int(0.8 * len(item_list))
self.test_gd[user] = item_list[test_item_index:]
return self.test_gd
3.2 GRU4Rec模型定义
(1)paddle版实现
其实这里paddle和torch一样有nn.GRU可以直接调用。模型forward中取GRU输出的最后一个Hidden作为User的Embedding。注意nn.GRU层中需要将time_major设置为false,即为[batch, seq_len, emb_size],如果在torch中则是batch_first参数:

class GRU4Rec(nn.Layer):
def __init__(self, config):
super(GRU4Rec, self).__init__()
self.config = config
self.embedding_dim = self.config['embedding_dim']
self.max_length = self.config['max_length']
self.n_items = self.config['n_items']
self.num_layers = self.config['num_layers']
self.item_emb = nn.Embedding(self.n_items, self.embedding_dim, padding_idx=0)
self.gru = nn.GRU(
input_size=self.embedding_dim,
hidden_size=self.embedding_dim,
num_layers=self.num_layers,
time_major=False,
)
self.loss_fun = nn.CrossEntropyLoss()
self.reset_parameters()
# 计算损失函数,使用listwise模型训练,loss_fun(dot_res, pos_item)
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
def output_items(self):
return self.item_emb.weight
def reset_parameters(self, initializer=None):
for weight in self.parameters():
# hekaiming参数初始化
paddle.nn.initializer.KaimingNormal(weight)
def forward(self, item_seq, mask, item, train=True):
seq_emb = self.item_emb(item_seq) # (b,s,e)
seq_emb,_ = self.gru(seq_emb)
# 取GRU输出的最后一个Hidden作为User的Embedding
user_emb = seq_emb[:,-1,:]
if train:
loss = self.calculate_loss(user_emb,item)
output_dict = {
'user_emb':user_emb,
'loss':loss
}
else:
output_dict = {
'user_emb':user_emb
}
return output_dict
取GRU输出的最后一个Hidden作为序列的embedding,即User的Embedding。
3.3 Pipeline
定义一些模型参数、保存模型、导入模型的操作。
(1)额外注意my_collate函数,是为了将后20%作为测试集时,__getitem__函数返回值之一item_list[k:]长度可能不一致的一个处理:
def my_collate(batch):
hist_item, hist_mask, item_list = list(zip(*batch))
hist_item = [x.unsqueeze(0) for x in hist_item]
hist_mask = [x.unsqueeze(0) for x in hist_mask]
hist_item = paddle.concat(hist_item,axis=0)
hist_mask = paddle.concat(hist_mask,axis=0)
return hist_item,hist_mask,item_list
(2)早停策略:patience=5只如果连续5个epoch指标都没上升则停止训练。
(3)训练后的指标结果如下,这里发现第5个epoch就停止了,说明已经连续5个epoch指标没有涨了,所以停止训练模型,具体指标如下,完整代码参考paddle传统序列召回实践:GRU4Rec。这里第5个epoch的test指标用的第0个epoch的结果(权重)进行测试。

3.4 基于Faiss的向量召回

- Faiss:Facebook 开源的向量相似检索库:https://github.com/facebookresearch/faiss,类似的有
annoy向量检索库。从多媒体文档中快速搜索出相似的条目——这个场景下的挑战是基于查询的传统搜索引擎无法解决的。Faiss使用的数据流如上图所示。可以通过如下命令下载:
#cpu 版本
conda install faiss-cpu -c pytorch
# GPU 版本
conda install faiss-gpu cudatoolkit=8.0 -c pytorch # For CUDA8
conda install faiss-gpu cudatoolkit=9.0 -c pytorch # For CUDA9
conda install faiss-gpu cudatoolkit=10.0 -c pytorch # For CUDA10
- 下面代码中
get_predict函数使用了faiss向量相似检索库;evaluate函数计算recall、hitrate、ndcg。hitrate指标在top N推荐中经常使用:
H R = 测试集中的item出现在 T o p − N 推荐列表中的用户数量 用户总数 H R=\frac{\text { 测试集中的item出现在 } T o p-N \text { 推荐列表中的用户数量 }}{\text { 用户总数 }} HR= 用户总数 测试集中的item出现在 Top−N 推荐列表中的用户数量
def get_predict(model, test_data, hidden_size, topN=20):
# 1. 获得所有item的embedding,然后插入faiss向量数据库中
item_embs = model.output_items().cpu().detach().numpy()
item_embs = normalize(item_embs, norm='l2')
gpu_index = faiss.IndexFlatIP(hidden_size)
gpu_index.add(item_embs)
test_gd = dict()
preds = dict()
user_id = 0
for (item_seq, mask, targets) in tqdm(test_data):
# 获取用户嵌入
# 2. 多兴趣模型,shape=(batch_size, num_interest, embedding_dim)
# 其他模型,shape=(batch_size, embedding_dim)
user_embs = model(item_seq,mask,None,train=False)['user_emb']
user_embs = user_embs.cpu().detach().numpy()
# 用内积来近邻搜索,实际是内积的值越大,向量越近(越相似)
# 非多兴趣模型评估
if len(user_embs.shape) == 2:
user_embs = normalize(user_embs, norm='l2').astype('float32')
# 3. Inner Product近邻搜索,D为distance,I是index
D, I = gpu_index.search(user_embs, topN)
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
# 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
for i, iid_list in enumerate(targets):
test_gd[user_id] = iid_list
preds[user_id] = I[i,:]
user_id +=1
else: # 多兴趣模型评估
ni = user_embs.shape[1] # num_interest
user_embs = np.reshape(user_embs,
[-1, user_embs.shape[-1]]) # shape=(batch_size*num_interest, embedding_dim)
user_embs = normalize(user_embs, norm='l2').astype('float32')
# Inner Product近邻搜索,D为distance,I是index
D, I = gpu_index.search(user_embs, topN)
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
# 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
for i, iid_list in enumerate(targets):
recall = 0
dcg = 0.0
item_list_set = []
# 将num_interest个兴趣向量的所有topN近邻物品(num_interest*topN个物品)集合起来按照距离重新排序
item_list = list(
zip(np.reshape(I[i * ni:(i + 1) * ni], -1), np.reshape(D[i * ni:(i + 1) * ni], -1)))
# 降序排序,内积越大,向量越近
item_list.sort(key=lambda x: x[1], reverse=True)
# 按距离由近到远遍历推荐物品列表,最后选出最近的topN个物品作为最终的推荐物品
for j in range(len(item_list)):
if item_list[j][0] not in item_list_set and item_list[j][0] != 0:
item_list_set.append(item_list[j][0])
if len(item_list_set) >= topN:
break
test_gd[user_id] = iid_list
preds[user_id] = item_list_set
user_id +=1
return test_gd, preds
def evaluate(preds,test_gd, topN=50):
total_recall = 0.0
total_ndcg = 0.0
total_hitrate = 0
for user in test_gd.keys():
recall = 0
dcg = 0.0
item_list = test_gd[user]
for no, item_id in enumerate(item_list):
if item_id in preds[user][:topN]:
recall += 1
dcg += 1.0 / math.log(no+2, 2)
idcg = 0.0
for no in range(recall):
idcg += 1.0 / math.log(no+2, 2)
total_recall += recall * 1.0 / len(item_list)
if recall > 0:
total_ndcg += dcg / idcg
total_hitrate += 1
# recall/ndcg/hitrate
total = len(test_gd)
recall = total_recall / total
ndcg = total_ndcg / total
hitrate = total_hitrate * 1.0 / total
return {f'recall@{topN}': recall, f'ndcg@{topN}': ndcg, f'hitrate@{topN}': hitrate}
# 指标计算
def evaluate_model(model, test_loader, embedding_dim,topN=20):
test_gd, preds = get_predict(model, test_loader, embedding_dim, topN=topN)
return evaluate(preds, test_gd, topN=topN)
3.5 基于TSNE的Item Embedding分布可视化
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种非线性降维技术,主要用途为对高维数据进行可视化。下面这里首先进行了归一化操作。
def plot_embedding(data, title):
x_min, x_max = np.min(data, 0), np.max(data, 0)
data = (data - x_min) / (x_max - x_min)
fig = plt.figure(dpi=120)
plt.scatter(data[:,0], data[:,1], marker='.')
plt.xticks([])
plt.yticks([])
plt.title(title)
plt.show()

时间安排
| 任务信息 | 截止时间 | 完成情况 |
|---|---|---|
| 11月14日周一正式开始 | ||
| Task01:Paddle开发深度学习模型快速入门 | 11月14、15、16日周三 | 完成 |
| Task02:传统序列召回实践:GRU4Rec | 11月17、18、19日周六 | 完成 |
| Task03:GNN在召回中的应用:SR-GNN | 11月20、21、22日周二 | |
| Task04:多兴趣召回实践:MIND | 11月23、24、25、26日周六 | |
| Task05:多兴趣召回实践:Comirec-DR | 11月27、28日周一 | |
| Task06:多兴趣召回实践:Comirec-SA | 11月29日周二 |
Reference
[1] paddle传统序列召回实践:GRU4Rec
https://github.com/THUDM/ComiRec/blob/a576eed8b605a531f2971136ce6ae87739d47693/src/model.py
https://github.com/RUCAIBox/RecBole/blob/master/recbole/model/sequential_recommender/gru4rec.py
[2] 什么是推荐系统?推荐系统类型、用例和应用
[3] 推荐系统2–隐语义模型(LFM)和矩阵分解(MF)
[4] 推荐场景中召回模型的演化过程. 京东大佬
[5] 论文阅读笔记一:SESSION-BASED RECOMMENDATIONS WITHRECURRENT NEURAL NETWORKS
[6] GRU4Rec2 《Recurrent Neural Networks with Top-k Gains for Session-based Recommendations》
[7] DeepLearning-500-questions
[8] GRU4Rec入门
[9] 序列推荐模型(四): GRU4Rec
[10] Deep Learning for Matching in Search and Recommendation.李航,何向南
[11] 深度学习之GRU网络
[12] 向量检索库Faiss使用指北
[13] https://pytorch.org/docs/stable/generated/torch.nn.GRU.html?highlight=gru#torch.nn.GRU
[14] word2vec Parameter Learning Explained.Xin Rong
[15] 【RS样本选择与构造】正负样本的选择 | 负采样 | pointwise、pairwise、listwise
[16] 推荐系统中如何评价embedding的质量
[17] 贝叶斯个性化排序(BPR)算法小结
[18] 图像检索:再叙ANN Search
[19] Faiss:https://blog.razrlele.com/p/2594
[20] Faiss官方文档:https://github.com/facebookresearch/faiss
[21] 深度学习在序列化推荐中的应用 (1)-GRU4REC 以及扩展
[22] GRU4Rec v2 - Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
[23] Faiss从入门到实战精通
[24] 时间序列数据的预处理方法总结
![[附源码]SSM计算机毕业设计江苏策腾智能科技公司人事管理系统JAVA](https://img-blog.csdnimg.cn/1fde4f81b3fd451e81bf7cb440197553.png)