- Lecture 1
- 1.2 Introduction to Heterogeneous异构
- 1.3 Portability and Scalability
- 1.4 Introduction to CUDA 数据并行化 and 执行模型
- 1.5 Introduction to CUDA 内存模型 and 基本函数API
- 1.6 Introduction to CUDA Kernel-based SPMD
- 1.7 更高维的Grid的Kernel-based SPMD例子
- 1.8 Matrix Multiplication矩阵乘法
- Lecture 2
- 2.1 Kernel-Based Parallel Programming
Heterogeneous Programming是采用不同类型的计算节点协同进行计算。而Heterogeneous Parallel Programming则是建立在这种机制上的并行计算。这里使用的是的CUDA。CUDA是NVIDIA推出的建立在C语言和GPU基础上的计算框架。
Lecture 1
1.2 Introduction to Heterogeneous异构
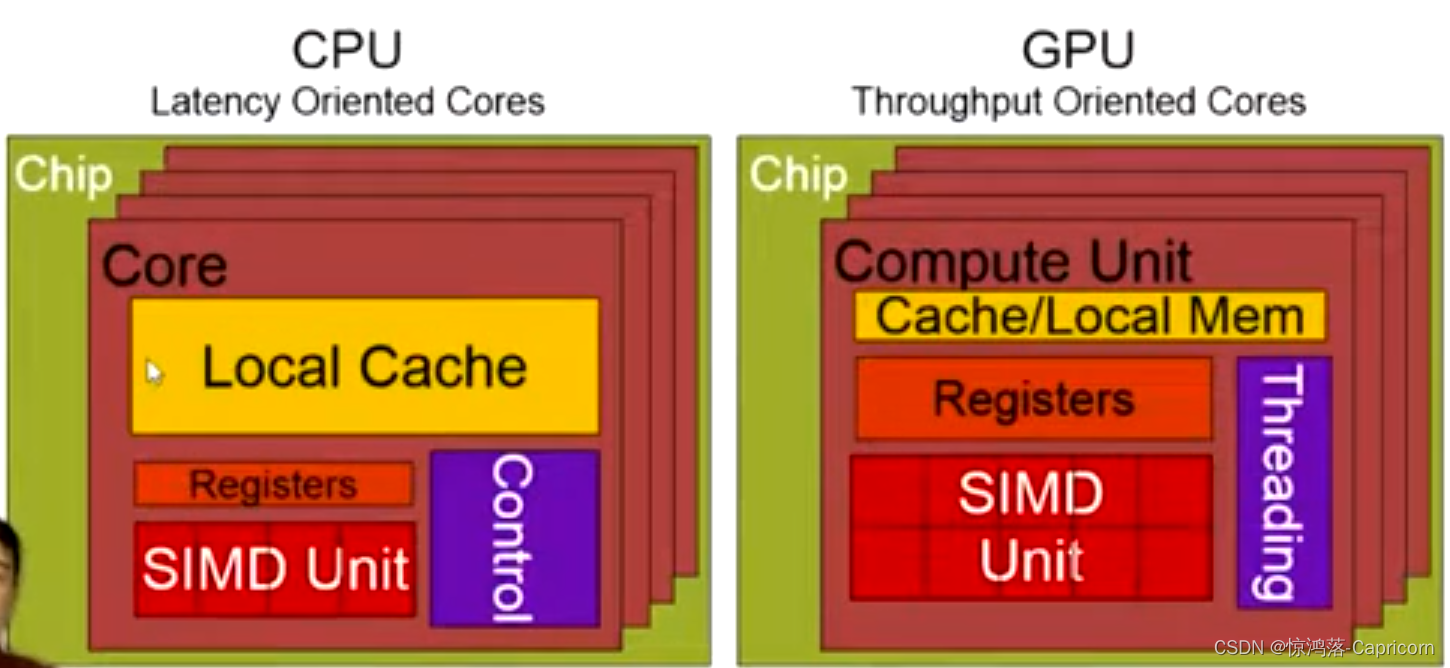
GPU与CPU的设计理念不同:GPU旨在提供高吞吐量throughput,而CPU旨在提供低延迟latency,CPU需要降低指令的执行时间,所以有很大的缓存,而GPU则不然。单一的GPU线程执行时间相当长,因此总是多线程并行,这样提高了吞吐量。所以在串行逻辑计算部分应该使用CPU,而并行数据计算部分则应使用GPU。
1.3 Portability and Scalability
降低软件开发成本的关键:
可扩展性Scalability:细粒度编程风格,只需调整参数,便可扩展到更多相同的硬件上运行。
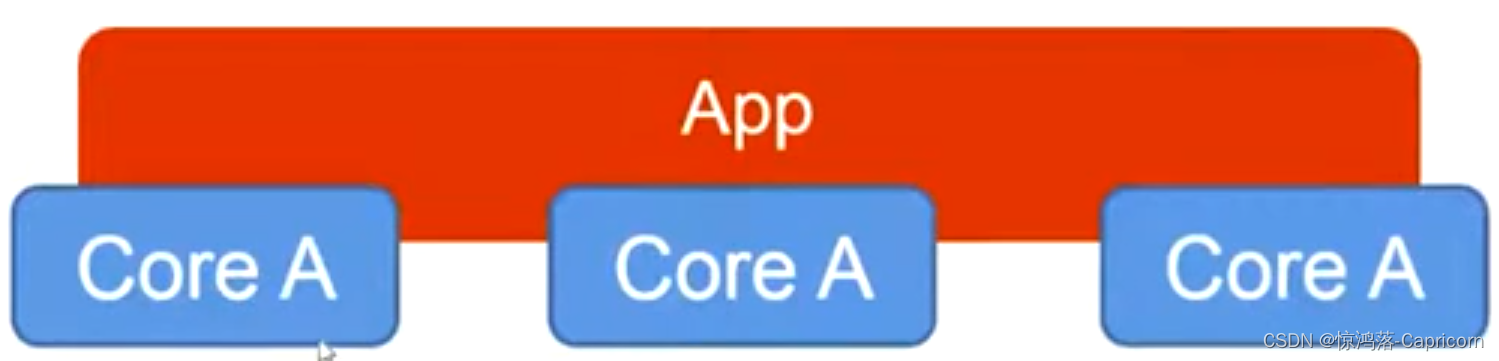
可移植性Portability: 可扩展到更多不同的硬件上运行

1.4 Introduction to CUDA 数据并行化 and 执行模型
数据并行化Data Parallelism:将向量或矩阵对应位置的数据分别交给不同的线程并行处理。
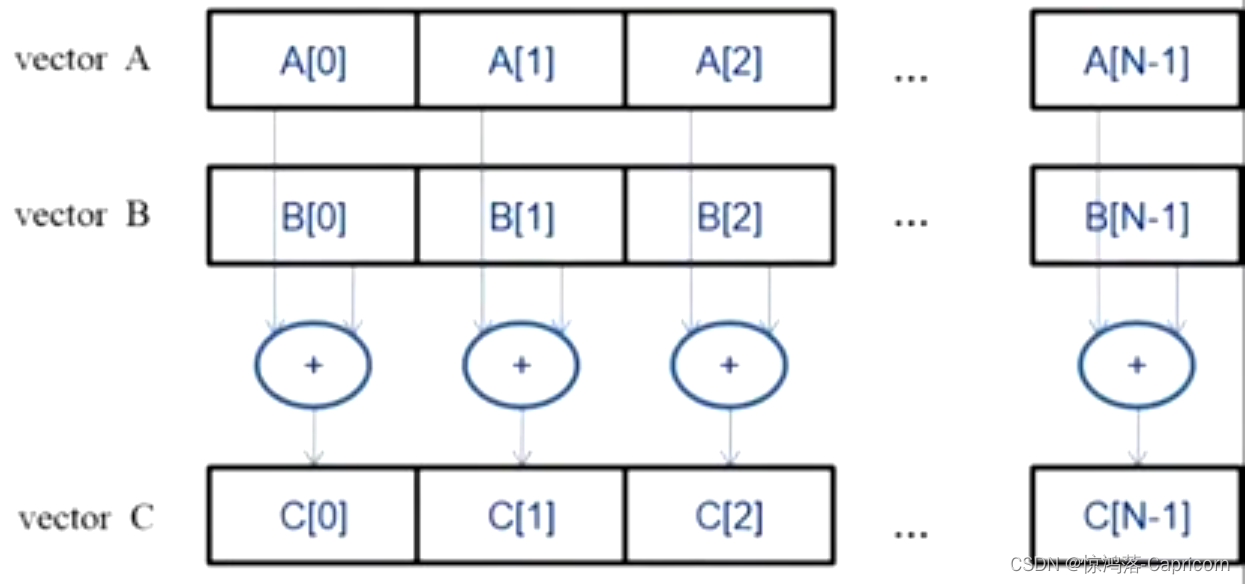
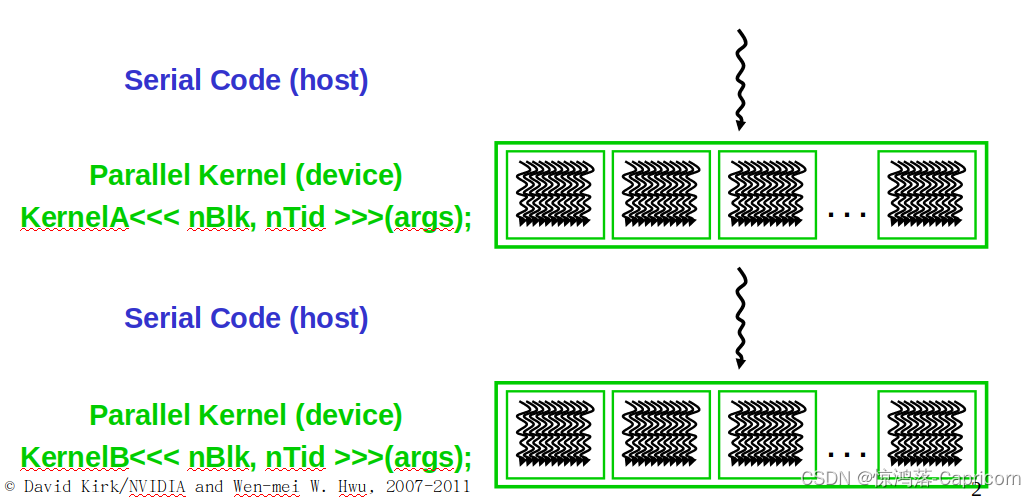
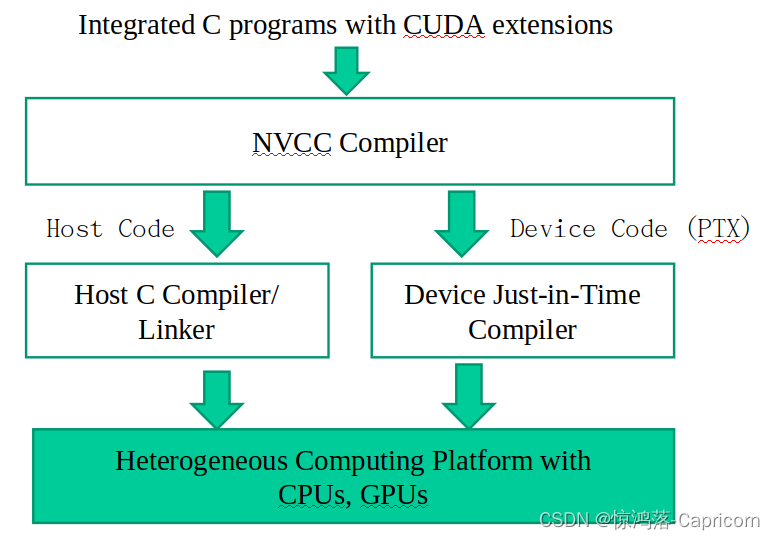
CUDA/OpenCL执行模型:分为两部分,Host 和 Device,串行部分在Host(CPU)上执行,而并行部分在Device(GPU)上执行。相比传统的C语言,CUDA增加了一些扩展,包括了库和关键字。CUDA代码提交给NVCC编译器,该编译器将代码分为Host代码和Device代码两部分。Host代码即为原本的C语言,交由GCC或其他的编译器处理;Device代码部分交给一个称为实时(Just in time)编译器的组件,在给代码运行之前编译。
CUDA架构执行程序时在CPU和GPU上来回切换,CPU程序穿行执行,GPU程序使用核函数Kernel,每个核函数被大量(一组grid)CUDA线程并行执行,Kernel可以使用<<< >>>接受配置参数,也可以使用( )接受调用参数。
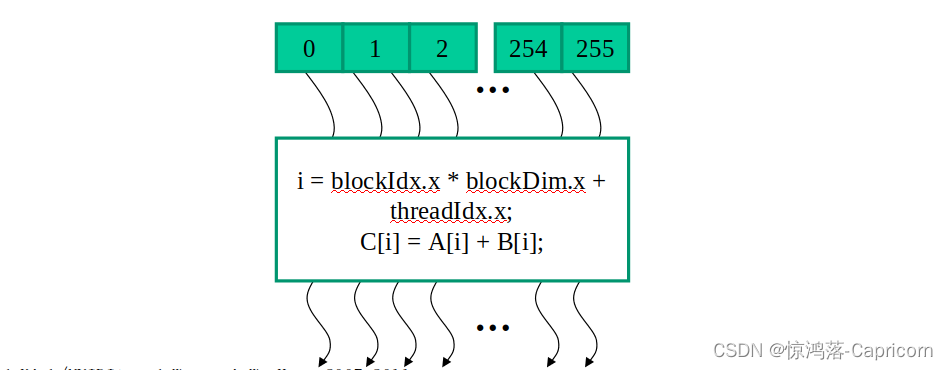
CUDA线程: 每个CUDA线程实际上都是一个虚拟的处理器,去执行核函数,CUDA kernel函数被一网格Gird的线程并行执行,每个网格里有很多块Block,每个块里有很多线程Thread。
如下为单Block线程执行核函数:
在Block中,每个Thread都去执行核函数,去承担运算中的不同部分,但每个Thread都有一个唯一的threadidx。
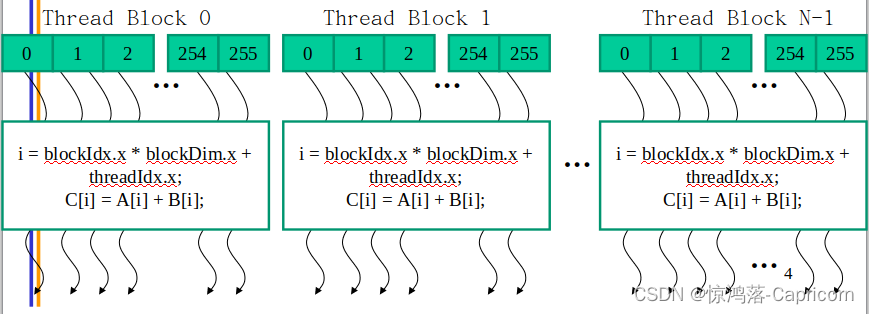
如下为多Block线程执行核函数:
在Grid中,每个Block都去执行核函数,去承担运算中的不同部分,但每个Block都有一个唯一的blockIdx。
并行线程阵列由Grid——Block——Thread三级结构组成,每个Thread有唯一定位ID。
其中DimGrid是Grid的形状和DimBlock三Block的形状 ,它们都是调用核函数的配置参数,用<<<DimGrid,DimBlock>>>设置。
gridDim.x/y/z为每个Grid在x/y/z维度上的大小,blockDim.x/y/z为每个Block在x/y/z维度上的大小。blockIdx标识Grid中的Block,threadIdx标识Block中的Thread。
CUDA Thread 定位公式:
1.先找到当前线程位于Grid中的哪一个Block线程块的blockId:
blockId = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
2.找到当前线程位于Block中的哪一个线程threadId:
threadId = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
3.计算一个Block中一共有多少个线程M:
M = blockDim.x*blockDim.y*blockDim.z
4.求得当前的线程序列号idx:
idx = M*blockId + threadId ;
blockIdx 和 threadIdx 和 gridDim 和 blockDim都是Dim3类型(x,y,z)的变量,每个xyz默认值为1,因此它们可以是1D、2D、3D的。因此每个i也可以是1D、2D、3D的。
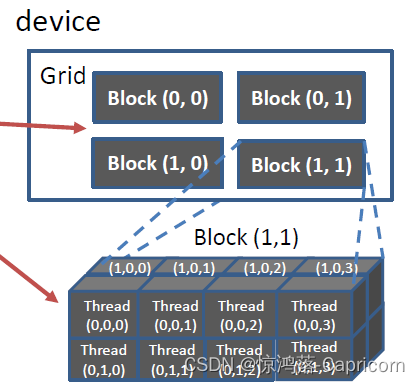
同一Block的Thread通过shared memory 和 atomic operations 和 barrier synchronization进行合作,而不同Block的Thread无法合作。
1.5 Introduction to CUDA 内存模型 and 基本函数API
CUDA程序执行流程: 使用host的数据在device上进行运算,再送回host:
#include <cuda.h>
void vecAdd(float* A, float* B, float* C, int n)
{
int size = n* sizeof(float);
float* A_d, B_d, C_d;
…
1. // Allocate device memory for A, B, and C
// copy A and B to device memory
2. // Kernel launch code – to have the device
// to perform the actual vector addition
3. // copy C from the device memory to host memory
// Free device vectors
}
CUDA 内存模型:每个Grid有一个共享的Global Memory,用于Host和Device交互,其中每个线程有自己私有的寄存器。Host代码负责分配Grid中的共享内存空间,以及数据在Host、Device之间的传输。Device代码则只与共享内存、本地寄存器交互。
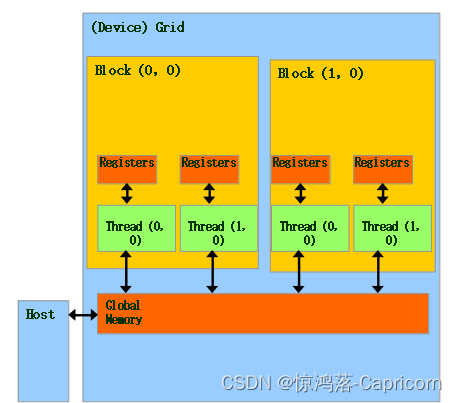
CUDA 内存分配 和 数据传输 API:与C语言中的函数想对应,CUDA有以下几个基本函数:
cudaMalloc()、cudaFree()、cudaMemcpy(),其作用等同于C中的对应函数,不同之处在于这些函数操作的是Device中的共享内存。
cudaMalloc(Pointer , Size of bytes ): 给一个Pointer指针 在device上分配global memory。cudaFree(Pointer ):释放这个Pointer指针的global memorycudaMemcpy(目的Pointer, 源Pointer, 要Copy的bytes数, 传输的类型/方向): 则用于Host内存与Device内存异步传输数据。
CUDA程序执行流程: 使用host的数据在device上进行运算,再送回host:
//host函数
void vecAdd(float* A, float* B, float* C, int n)//传入host指针,向量长度为n
{
int size = n * sizeof(float);
float* A_d, B_d, C_d;//定义device指针
1. // Transfer A and B to device memory
cudaMalloc((void **) &A_d, size);//申请全局device memory
cudaMemcpy(A_d, A, size, cudaMemcpyHostToDevice);//转移host数据到device
cudaMalloc((void **) &B_d, size);//申请全局device memory
cudaMemcpy(B_d, B, size, cudaMemcpyHostToDevice);//转移host数据到device
// Allocate device memory for C
cudaMalloc((void **) &C_d, size);//申请全局device memory
2. // Kernel invocation code – to be shown later
…
3. // Transfer C from device to host
cudaMemcpy(C, C_d, size, cudaMemcpyDeviceToHost); //转移device数据到host
// Free device memory for A, B, C
cudaFree(A_d); cudaFree(B_d); cudaFree (C_d);//释放device memory
}
1.6 Introduction to CUDA Kernel-based SPMD
SPMD:即Single Program Multiple Data,指相同的程序处理不同的数据。在Device端执行的Threads即属于此类型,每个Grid中的所有线程执行相同的Kernel函数(共享PC和IR指针),但是这些Threads需要从共享的Global Memory中取得自身的数据,这样就需要一种数据定位机制。
CUDA的函数分类:

注意都是双下划线。其中的__global__函数即为C代码中调用Device上计算的入口,必须返回void类型;__host__ 函数为传统的C函数,也是默认类型。之所以增加这一标识的原因是有时候可能__device__和__host__共同使用,这时可以让编译器知道,需要编译两个版本的函数。而__device__函数只能由__global__函数或__device__函数调用。
如计算向量加法:
// Compute vector sum C = A+B
// Each thread performs one pair-wise addition
//device code
__global__ void vecAddkernel(float* A_d, float* B_d, float* C_d, int n)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;//device函数要计算thread的索引,以便分配各自的数据
if(i<n) C_d[i] = A_d[i] + B_d[i];//if做boundry check
}
// host code
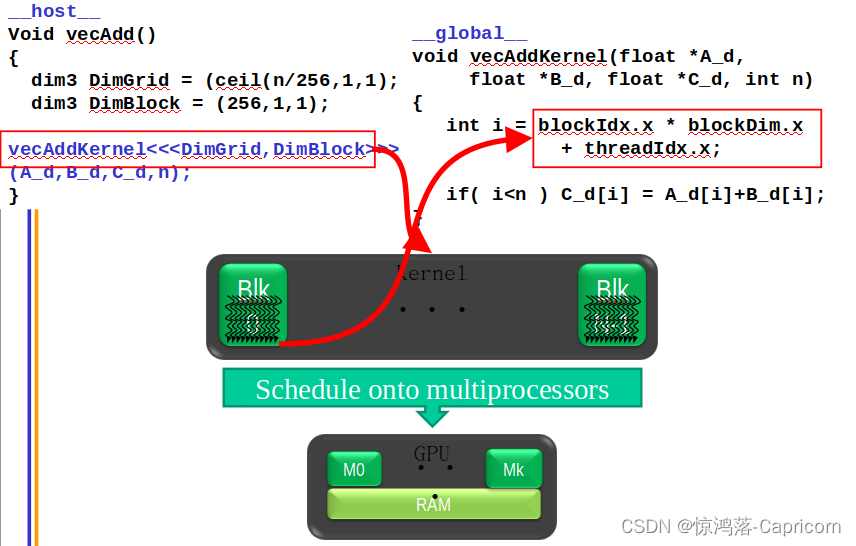
__host__ int vecAdd(float* A, float* B, float* C, int n)
{
//此处省略了 A_d, B_d, C_d allocations and copies
// Run ceil(n/256) blocks of 256 threads each
dim3 DimGrid(n/256, 1, 1);
if (n%256) DimGrid.x++;
dim3 DimBlock(256, 1, 1);
vecAddKernel<<<DimGrid,DimBlock>>>(A_d, B_d, C_d, n);//host函数中调用device函数执行
}
Any call to a kernel function is asynchronous from CUDA 1.0 on, explicit synch needed for blocking
CUDA程序工作流程:host函数 -> device函数(__global __) -> host函数
CUDA程序异构编译过程:编译器nvcc识别Host函数和Device函数,分别让它们与各自的编译器进一步编译,如gcc和intel icc,最后在异构计算平台上运行。
1.7 更高维的Grid的Kernel-based SPMD例子
前面我们讨论了向量的加法,这是一维数据的计算,下面我们讲讲二维数据和内存模型。
一维数据:向量。二维数据:矩阵/图片。对于二维数据,C/C++是行为主,Fortran以列为主。
__global__ void PictureKernel(float* Pin, float* Pout, int n, int m)
{
// Calculate the row # of the Pin and Pout element to process
int Row = blockIdx.y*blockDim.y + threadIdx.y;
// Calculate the column # of the Pin and Pout element to process
int Col = blockIdx.x*blockDim.x + threadIdx.x;
// each thread computes one element of Pout if in range
if ((Row < m) && (Col < n)) {
Pout[Row*n+Col] = 2*Pin[Row*n+Col];
}
}
假定需要处理一张76x62像素的图片,采用16x16的Block,如图:
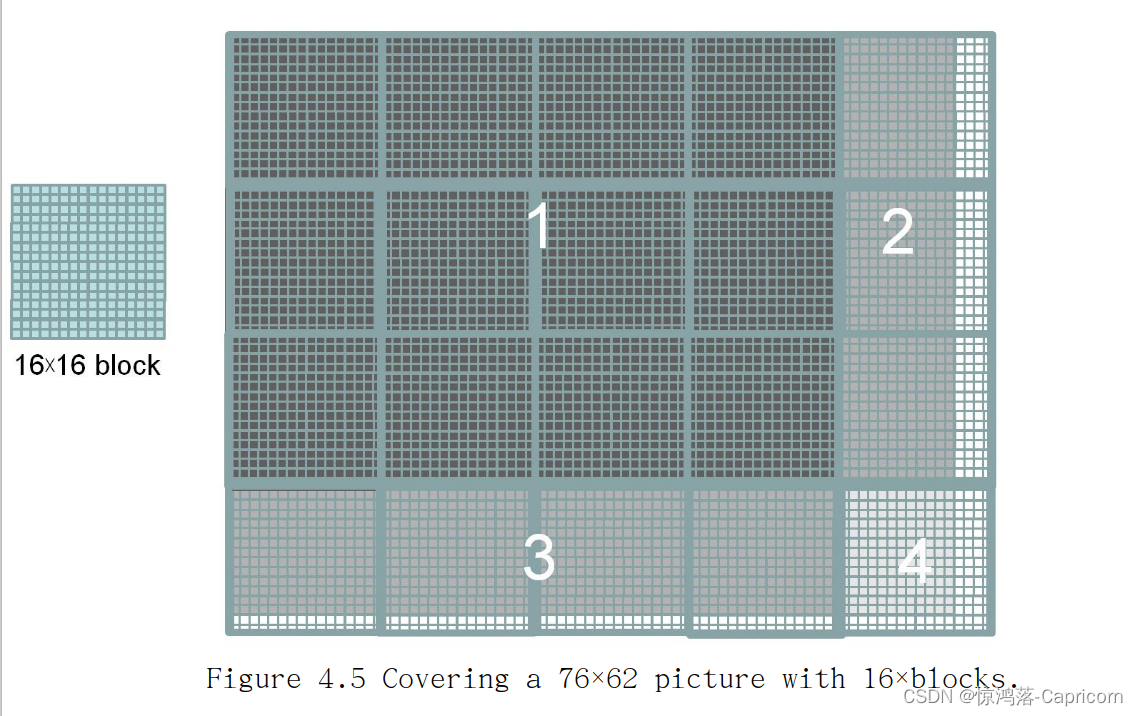 为什么要边界查询,判断(Row < m) && (Col < n):
为什么要边界查询,判断(Row < m) && (Col < n):
因为Threads数量>矩阵单元数,并不是所有的Thread都要参与运算。其中1区域的Block每一个Thread都对应有像素,而2、3、4则没有。
1.8 Matrix Multiplication矩阵乘法
矩阵乘法规则:前行成后列,在实际使用中,我们常常用行主导的一维数组代替二维数组,即,twoDim[2, 3] = oneDim[2 * numCol + 3]。
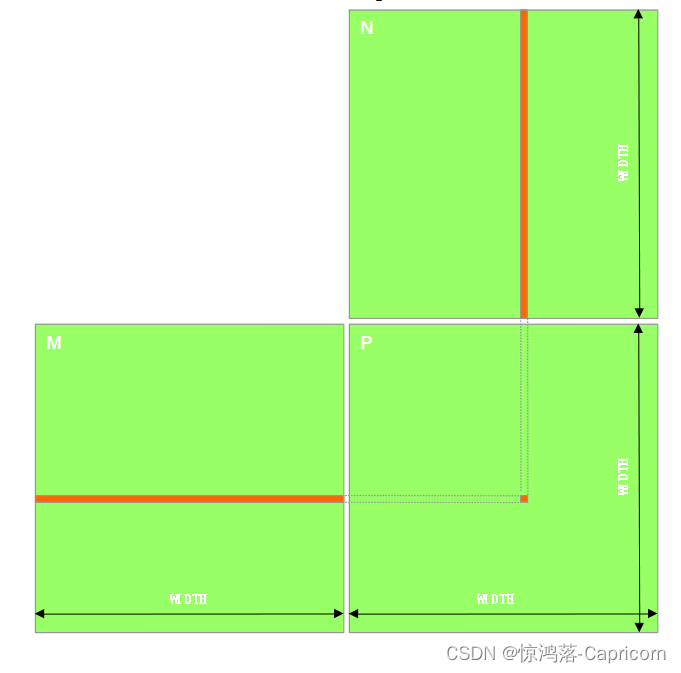
CPU的Host代码: 两个循环遍历整个将结果矩阵
// Matrix multiplication on the (CPU) host in double precision
void MatrixMulOnHost(float* M, float* N, float* P, int Width)
{
for (int i = 0; i < Width; ++i)
for (int j = 0; j < Width; ++j) {
double sum = 0;
for (int k = 0; k < Width; ++k) {
double a = M[i * Width + k];
double b = N[k * Width + j];
sum += a * b;
}
P[i * Width + j] = sum;
}
}
GPU的Device代码: 每个Thread有Row和Col两个量来索引
__global__ void MatrixMulKernel(float* M, float* N, float* P, int Width)
{
// Calculate the row index of the P element and M
int Row = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate the column index of P and N
int Col = blockIdx.x * blockDim.x + threadIdx.x;
if ((Row < Width) && (Col < Width)) {
float Pvalue = 0;
// each thread computes one element of the block sub-matrix
for (int k = 0; k < Width; ++k)
Pvalue += M[Row*Width+k] * N[k*Width+Col];
P[Row*Width+Col] = Pvalue;
}
}
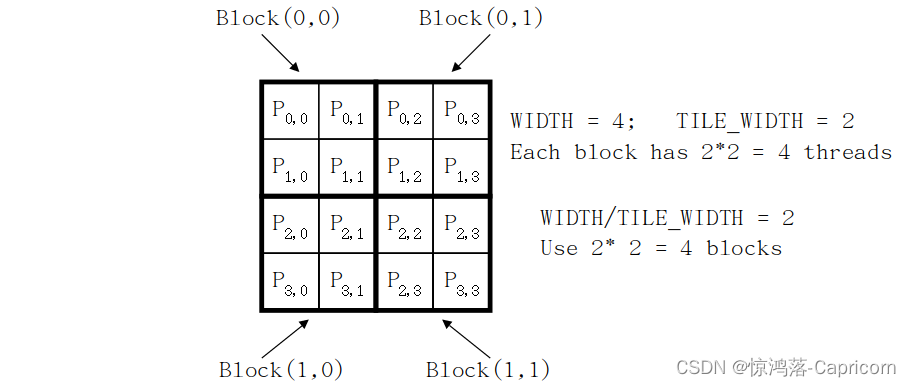
Host代码调用核函数:
// Setup the execution configuration
// TILE_WIDTH is a #define constant
dim3 dimGrid(Width/TILE_WIDTH, Width/TILE_WIDTH, 1);
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH, 1);
// Launch the device computation threads!
MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width);
Lecture 2
2.1 Kernel-Based Parallel Programming
线程调度