文章目录
- 1、简介
- 2、STL算法分类及常用函数
- 2.1、变序算法(一)
- 2.2.1 初始化算法(2个)
- 2.2.2 修改算法(2个)
- 2.2.3 复制算法(6个)
- 2.2.4 删除算法(6个)
- 3、总结
============================ 【说明】 ===================================================
大家好,本专栏主要是跟学C++内容,自己学习了这位博主【 AI菌】的【C++21天养成计划】,讲的十分清晰,适合小白,希望给这位博主多点关注、收藏、点赞。
主要针对所学内容,通过自己的理解进行整理,希望大家积极交流、探讨,多给意见。后面也会给大家更新,其他一些知识。若有侵权,联系删除!共同维护网络知识权利!
=======================================================================================
写在前面
至此,我们了解了C++的基本语法,但是进一步学习C++,数据结构是必不可少的内容。 数据结构与算法决定了代码测存储方式,以及代码执行效率。
数据结构的重要性不言而喻, 关于数据结构的基本知识可以转至本人另一专栏====>【 数据结构】。同样也可以阅读博主【 AI菌】写的【 数据结构与算法】,比较通俗易懂,可以学习学习!
1、简介
上一节,详细介绍了STL标准模板库——算法整理(上)相关内容,介绍了STL算法分类及常用函数,详细说明非变序算法的常用函数,今天我们继续介绍关于变序算法的一部分常用函数及注意点。
2、STL算法分类及常用函数
STL算法模板库分为两大类:非变序与变序。对于这两种类别如何理解?下面就详细介绍两大类以及各函数的具体应用。
2.1、变序算法(一)
2.2.1 初始化算法(2个)
| 函数名 | 解释 |
|---|---|
| fill() | 将指定值分配给指定范围内的元素。 |
| fill_n() | 将指定值分配给前n个每个元素。 |
(1) fill()/ fill_n()
STL模板库提供了一种为元素序列填入给定值的简单方式,即fill()和fill_n();
fill():将指定范围内的元素设置为指定值,fill() 会填充整个序列
fill_n():将n个元素设置为指定的值。接受的参数包括:起始位置、元素的个数以及设置的值。
关于fill()和fill_n()案例如下:
#include <iostream>
#include <map>
#include<list>
#include<functional>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
void DisplayFill(vector <int> vec)
{
for (int i = 0; i<vec.size(); i++)
cout << vec[i] << " ";
cout << endl;
}
//1、fill/fill_n
int main() {
// 初始化长度为3的数组
vector <int> vec(3);
// 用9填满容器
fill(vec.begin(), vec.end(), 9);
DisplayFill(vec);
vec.resize(6);
DisplayFill(vec);
// 从第三个元素之后,填3个-9
fill_n(vec.begin() + 3, 3, -9);
DisplayFill(vec);
return 0;
}
2.2.2 修改算法(2个)
| 函数名 | 解释 |
|---|---|
| for_each() | 对指定范围内的每个元素,执行指定的操作。 |
| transform() | 对指定范围内的每个元素,执行指定的对指定范围内的每个元愫,执行指定的一元函数。 |
(1)for_each
for_each():是对区间[first,last)(注意左闭右开)上的每一个元素调用function,第三个参数可以全局函数、函数对象
、lambda表达式、并且是一个一元函数。for_each()具体定义如下:
template< class InputIt, class UnaryFunction >
UnaryFunction for_each( InputIt first, InputIt last, UnaryFunction function );
参数first,last:指定该算法操作的区间[first, last);
参数function : 一元函数,即UnaryFunction ,可以是全局函数(函数指针)\函数对象、lambda等、默认按值传递;第三个参数function默认是按值传递的。也就是说,for_each()内部操作的是function的副本,另外,返回值也是按值返回的。当然,也可以打破这种限制(参考:Effective STL 的38条款)。
返回值:返回function 的一个副本,function的任何返回值都将被忽略;
关于for_each()案例如下:
//2、for_each
static void printElement(int &item) {
cout << item << " ";
}
class Printer {
public:
void operator()(int & item) {
cout << item << " ";
}
};
int main() {
int printArray[] = {1,3,5,4,78,25};
//第三个参数为static全局函数
for_each(begin(printArray), end(printArray), printElement);
cout << endl;
//第三个参数为lambda表达式
for_each(begin(printArray), end(printArray), [](int &item) {cout << item << " "; });
cout << endl;
//第三个参数为函数对象
for_each(begin(printArray), end(printArray),Printer());
cout << endl;
return 0;
}

//计算容器/数组元素的sum。
class Sum {
public:
Sum() :sum{ 0 }
{
}
void operator()(const int& item)
{
sum += item;
}
int getSum() {
return sum;
}
private:
int sum;
};
int main(int argc, char *argv[])
{
std::vector<int> nums{ 0,1,2,3,4,5,6,7,8,9 };
Sum elements = std::for_each(nums.begin(), nums.end(), Sum());
std::cout << elements.getSum() << std::endl;
return 0;
}
(2)transform
transform() :可以将函数应用到序列的元素上,并将这个函数返回的值保存到另一个序列中,它返回的迭代器指向输出序列所保存的最后一个元素的下一个位置。
这个算法有一个版本和 for_each() 相似,可以将一个一元函数应用到元素序列上来改变它们的值,但这里有很大的区别。for_each() 中使用的函数的返回类型必须为 void,而且可以通过这个函数的引用参数来修改输入序列中的值;而 transform() 的二元函数必须返回一个值,并且也能够将应用函数后得到的结果保存到另一个序列中。
第二个版本的 transform() 允许将二元函数应用到两个序列相应的元素上,但先来看一下如何将一元函数应用到序列上。在这个算法的这个版本中,它的前两个参数是定义输入序列的输入迭代器,第 3 个参数是目的位置的第一个元素的输出迭代器,第 4 个参数是一个二元函数。
关于transform案例如下:
//3、transform
double Transform(double &num) {
double result = 32.0 + 9.0*num / 5.0;
cout << result<<endl;
return result;
}
//案例1:将摄氏度改为华氏度
int main() {
vector<double> N1{25.5, 26.1, 27.0, 23.8, 24.0};
vector<double> N2(N1.size());
//第四个参数统一采用static全局函数,也可采用lambda表达式:[](double temp){ return 32.0 + 9.0*temp/5.0; }
// 第3 个参数是目的位置的第一个元素的输出迭代器
cout << "Way 1:" << endl;
transform(begin(N1), end(N1), rbegin(N2), Transform);
cout << endl;
// 第3个参数是用 back_insert_iterator 作为 transform() 的第三个参数,可以将结果保存到空的容器中
cout << "Way 2:" << endl;
transform(begin(N1), end(N1), back_inserter(N2), Transform);
cout << endl;
// 第3个参数可以是指向输入容器的元素的迭代器,是输入序列的开始迭代器
cout << "Way 3:" << endl;
transform(begin(N1), end(N1),begin(N2),Transform);
cout << endl;
}
way 1:它的前两个参数是定义输入序列的输入迭代器,第 3 个参数是目的位置的第一个元素的输出迭代器,第 4 个参数是一个二元函数。这个函数必须接受来自输入序列的一个元素为参数,并且必须返回一个可以保存在输出序列中的值。
way 2:为了保存全部结果,生成的 N2需要一定个数的元素。因此第三个参数是 N2的开始迭代器。通过用 back_insert_iterator 作为 transform() 的第三个参数,可以将结果保存到空的容器。
way 3:第三个参数是输入序列的开始迭代器,应用第 4 个参数指定的函数的结果会被存回它所运用的元素上。
//案例2
int main111(){
std::vector<string> words{ "one", "two", "three", "four","five" };
std::vector<size_t> hash_values;
transform(std::begin(words), std::end(words), std::back_inserter(hash_values), std::hash<string>()); // string hashing function
copy(std::begin(hash_values), std::end(hash_values), std::ostream_iterator<size_t> {std::cout, " "});
cout << std::endl;
}
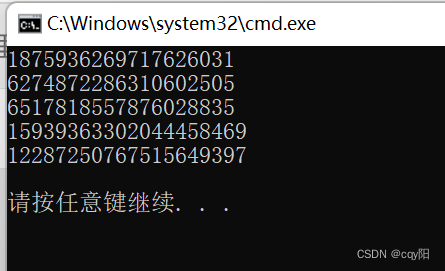
输入序列包含 string 对象,并且应用到元素的函数是一个定义在 string 头文件中的标准的哈希函数对象。这个哈希函数会返回 size_t 类型的哈希值,并且会用定义在 iterator 头文件中的辅助函数 back_inserter() 返回的 back_insert_iterator 将这些值保存到 hash_values 容器中。
//案例3
int main() {
std::deque<string> names{ "Stan Laurel", "Oliver Hardy", "Harold Lloyd" };
std::transform(std::begin(names), std::end(names), std::begin(names), [](string& s) { std::transform(std::begin(s), std::end(s), std::begin(s), ::toupper); return s; });
std::copy(std::begin(names), std::end(names), std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
return 0;
}
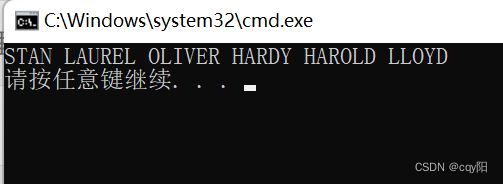
transform() 算法会将 lambda 定义的函数应用到 names 容器中的元素上。这个 lambda 表达式会调用 transform(),将定义在 cctype 头文件中的 toupper() 函数应用到传给它的字符串的每个字符上。它会将 names 中的每个元素都转换为大写。
总结:
应用二元函数的这个版本的 transform() 含有 5 个参数:
前两个参数是第一个输入序列的输入迭代器。
第3个参数是第二个输入序列的开始迭代器,显然,这个序列必须至少包含和第一个输入序列同样多的元素。
第4个参数是一个序列的输出迭代器,它所指向的是用来保存应用函数后得到的结果的序列的开始迭代器。
第5个参数是一个函数对象,它定义了一个接受两个参数的函数,这个函数接受来自两个输入序列中的元素作为参数,返回一个可以保存在输出序列中的值。
2.2.3 复制算法(6个)
| 函数名 | 解释 |
|---|---|
| copy() | 对指定范围内的元素复制到另一范围。 |
| copy_n() | 从源容器复制指定个数的元素到目的容器中。 |
| copy_if() | 可以从源序列复制使谓词返回 true 的元素,所以可以把它看作一个过滤器。 |
| copy_backward() | 对指定范围内的元素复制到另一范围,复制到目标范围的元素顺序反转。 |
| reverse_copy() | 将源序列复制到目的序列中,目的序列中的元素是逆序的。 |
| rotate_copy() | 在新序列中生成一个序列的旋转副本,并保持原序列不变。 |
(1)copy
copy():提供一种方便的方式来输出容器中的元素。函数copy()作为泛型算法的一部分,任何容器类型都可以使用。copy()函数不只是输出容器的元素。通常,它允许我们复制元素从一个地方到另一个地方。例如输出vector的元素或复制vector的元素到另一个vector,我们可以使用copy()函数。该函数模版copy的原型为:
template <class inputIterator, class outputIterator>
outputIterator copy(inputIterator first1, inputIterator last, outputIterator first2);
参数first1:指定了开始拷贝元素的位置;
参数last:指定了结束位置。
参数first2:指定了拷贝元素到哪里。
因此,参数first1和last指定了源;参数first2指定了目的。
关于copy案例如下:
//==================4、copy
int main() {
int intArray[] = { 1,2,3,4,5 };
vector<int> copyList(5);
//ex.1
cout << "ex.1:" << endl;
copy(intArray, intArray + 5, copyList.begin());
cout << endl;
//ex.2
cout << "ex.2:" << endl;
copy(copyList.rbegin() + 2, copyList.rend(), copyList.rbegin());
cout << endl;
//ex.3 迭代器的方式
cout << "ex.3 迭代器:" << endl;
ostream_iterator<int> print(cout, " ");
copy(intArray, intArray + 5, print);
cout << endl;
copy(copyList.begin(), copyList.end(), print);
cout << endl;
return 0;
}
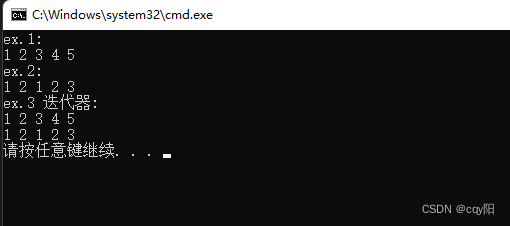
ex.1:该语句复制从位置intArray开始的元素,从数组的第一个组件intArray开始,直到intArray + 5 -1(即为intArray + 4,其为数组intArray的最后一个元素)到容器copyList。
ex.2:其中rbegin(reverse begin)函数返回容器中最后一个元素的指针。用于以反向来对容器中元素进行处理。因此,vecList.rbegin() + 2返回容器vecList中倒数第三个元素的指针。相似地,rend(reverse end)函数返回容器中指向第一个元素的指针。所以,上边的语句把容器vecList中的元素右移两个位置。
ex.3:该语句创建screen作为ostream迭代器(元素类型为int)。迭代器screen有两个参数:对象cout和空格(a space)。因此,迭代器screen使用对象cout来初始化。当该迭代器输出元素时,它们通过空格来分开。
(2)copy_n
copy_n() :可以从源容器复制指定个数的元素到目的容器中。
第一个参数:指向第一个源元素的输入迭代器;
第二个参数:需要复制的元素的个数;
第三个参数:指向目的容器的第一个位置的迭代器。
这个算法会返回一个指向最后一个被复制元素的后一个位置的迭代器,或者只是第三个参数——输出迭代器——如果第二个参数为 0。
关于copy_n案例如下:
//==================4.1、copy_n
int main() {
vector<string> names{ "C++","Java","Python","C#" };
vector<string> more_names{ "C","JavaScript" };
copy_n(rbegin(names)+1, 3, inserter(more_names, begin(more_names)));
for (int i = 0; i < more_names.size(); i++)
{
cout << more_names[i] << " ";
}
cout << endl;
return 0;
}
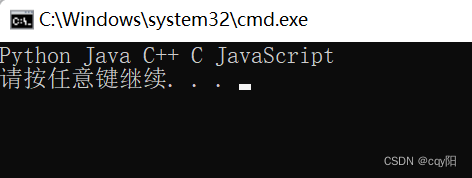
这个 copy_n() 操作会从 names 的倒数第二个元素开始复制 3 个元素到关联容器 more_names 中。目的容器是由一个 vector容器的 insert_iterator 对象指定的,它是由 inserter() 函数模板生成的。insert_iterator 对象会调用容器的成员函数 insert() 来向容器中添加元素。
(3)copy_if
copy_if() :可以从源序列复制使谓词返回 true 的元素,也可以把它看作一个过滤器。
前两个参数定义源序列的输入迭代器;
第三个参数是指向目的序列的第一个位置的输出迭代器;
第 4 个参数是一个谓词。会返回一个输出迭代器,它指向最后一个被复制元素的下一个位置。
关于copy_if案例如下:
int main() {
vector<string> names{ "A1", "Beth", "Carol", "Dan", "Eve","Fred", "George", "Harry", "Iain", "Joe" };
vector<string> more_names{ "Jean", "John" };
rsize_t max_length(4);
cout << "names【origin】:" << endl;
copy(begin(names), end(names), ostream_iterator<string>{cout, " "});
cout << endl;
cout << "more_names【origin】:" << endl;
copy(begin(more_names), end(more_names), ostream_iterator<string>{cout, " "});
cout << endl;
copy_if(begin(names), end(names), inserter(more_names, begin(more_names)), [max_length](const string&s) {return s.length() <= max_length; });
//使用copy()显示more names内容
cout << "after copy_if more_names【new】:" << endl;
copy(begin(more_names), end(more_names), ostream_iterator<string>{cout, " "});
cout << endl;
return 0;
}
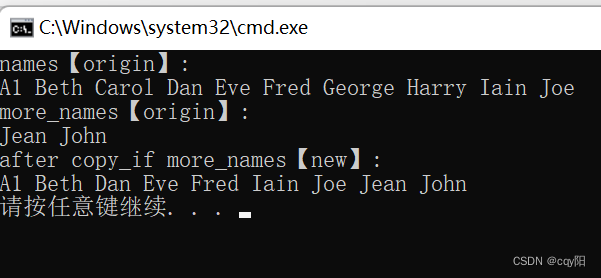
第 4 个参数的 lambda 表达式所添加的条件,这里的 copy_if() 操作只会复制 names 中的 4 个字符串或更少。目的容器是一个 unordered_set 容器 more_names,它已经包含两个含有 4 个字符的名称,insert_itemtor 会将元素添加到限定的关联容器中。为了查看容器more_names内的元素,我们可以采用copy() 算法列出。
//流迭代器示例
vector<string> names{ "Al", "Beth", "Carol", "Dan", "Eve","Fred", "George", "Harry", "Iain", "Joe" };
size_t max_length{ 4 };
copy_if(begin(names), end(names), ostream_iterator< string> {cout, " "}, [max_length](const string& s) { return s.length() > max_length; });
cout << endl;
return 0;
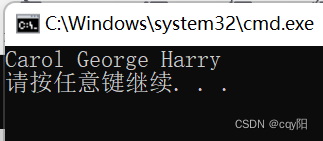
copy_if() 的目的容器也可以是一个流迭代器,将 names 容器中含有 4 个以上字符的名称写到标准输出流中。
//输入流迭代器作为算法源
unordered_set<string> names;
size_t max_length{ 4 };
cout << "Enter names of less than 5 letters. Enter Ctrl+Z on a separate line to end:\n";
copy_if(istream_iterator<string>{cin}, istream_iterator<string>{}, inserter(names, begin(names)), [max_length](const string& s) { return s.length() <= max_length; });
copy(begin(names), end(names), ostream_iterator <string>{cout, " "});
cout << endl;
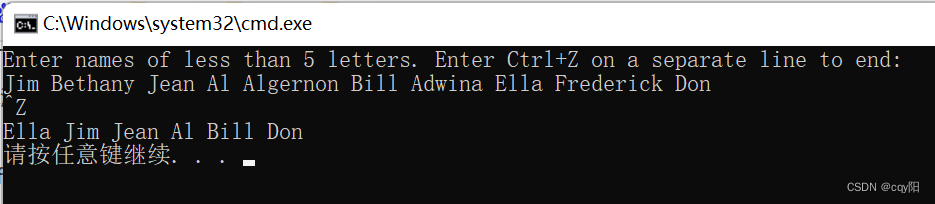
输入流迭代器可以作为 copy_if() 算法的源也可以将它用在其他需要输入迭代器的算法上。容器 names 最初是一个空的 unordered_set。只有当从标准输入流读取的姓名的长度小于或等于 4 个字符时,copy_if() 算法才会复制它们。
超过 5 个字母的姓名可以从 cin 读入,但是被忽略掉,因为在这种情况下第 4 个参数 的判定会返回 false。因此,输入的 10 个姓名里面只有 6 个会被存储在容器中。
(4)copy_backward
copy_backward() :该算法不会逆转元素的顺序,只会像 copy() 那样复制元素,但是从最后一个元素开始直到第一个元素。
关于copy()与copy_backward()的区别如下:
(1) copy_backward
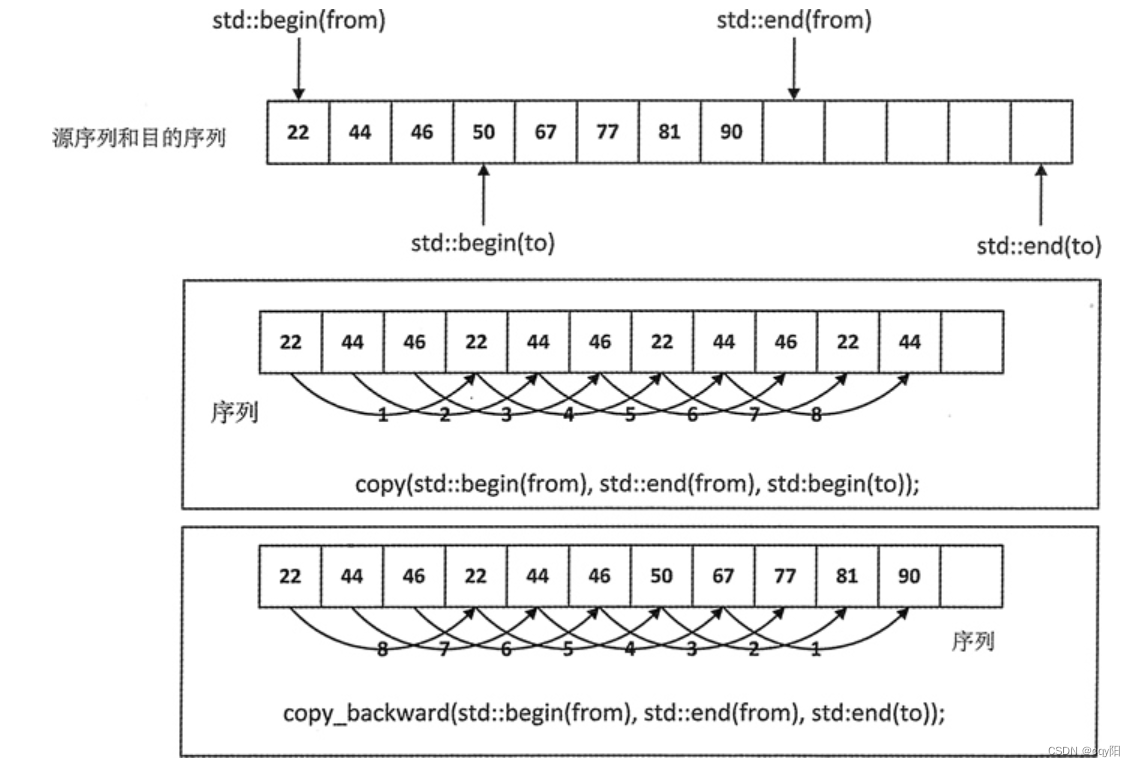
copy_backward() 会复制前两个迭代器参数指定的序列。第三个参数是目的序列的结束迭代器,通过将源序列中的最后一个元素复制到目的序列的结束迭代器之前,源序列会被复制到目的序列中,
如下图 所示。copy_backward() 的 3 个参数都必须是可以自增或自减的双向迭代器,这意味着这个算法只能应用到序列容器的序列上。

(图片来源:http://m.biancheng.net/view/605.html)
图中说明了源序列 from 的最后一个元素是如何先被复制到目的序列 to 的最后一个元素的。从源序列的反向,将每一个元素依次复制到目的序列的前一个元素之前的位置。在进行这个操作之前,目的序列中的元素必须存在,因此目的序列至少要有和源序列一样多的元素,但也可以有更多。copy_backward() 算法会返回一个指向最后一个被复制元素的迭代器,在目的序列的新位置,它是一个开始迭代器。
(1) copy
在序列重叠时,可以用 copy() 将元素复制到重叠的目的序列剩下的位置——也就是目的序列第一个元素之前的位置。如果想尝试用 copy() 算法将元素复制到同一个序列的右边,这个操作不会成功,因为被复制的元素在复制之前会被重写。如果想将它们复制到右边,可以使用 copy_backward(),只要目的序列的结束迭代器在源序列的结束迭代器的右边。下图说明了在将元素复制到重叠的序列的右边时,这两个算法的不同。
(图片来源:http://m.biancheng.net/view/605.html)
图中展示了在序列右边的前三个位置运用 copy() 和 copy_backward() 算法的结果。在想将元素复制到右边时,copy() 算法显然不能如我们所愿,因为一些元素在复制之前会被重写。在这种情况下,copy_backward() 可以做到我们想做的事。相反在需要将元素复制到 序列的左边时,copy() 可以做到,但 copy_backward() 做不到。
关于copy_backward案例如下:
//==================4.2、copy_backward
int main() {
vector<string> name{ "Al", "Beth", "Carol", "Dan", "Eve","Fred" };
cout << "name【origin】:" << endl;
copy(begin(name), end(name), ostream_iterator<string>{cout, " "});
cout << endl;
name.resize(name.size() + 2);
copy_backward(begin(name), begin(name)+6,end(name));
cout << "after copy_backward name【origin】:"<<endl;
copy(begin(name), end(name), ostream_iterator<string>{cout, " "});
cout << endl;
return 0;
}
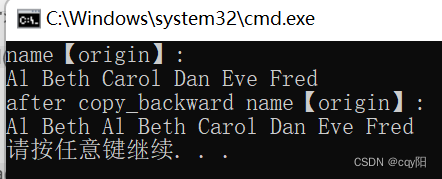
为了能够在右边进行序列的反向复制操作,需要添加一些额外的元素,可以通过使用 vector的成员函数 resize() 来增加 vector容器的元素个数。copy_backward() 算法会将原有的元素复制到向右的两个位置,保持前两个元素不变。
(5)reverse_copy
reverse_copy() :可以将源序列复制到目的序列中,目的序列中的元素是逆序的。
前两个参数迭代器参数必须是双向迭代器。
目的序列由第三个参数指定,它是目的序列的开始迭代器,也是一个输出迭代器。
如果序列是重叠的,函数的行为是未定义的。这个算法会返回一个输出迭代器,它指向目的序列最后一个元素的下一个位置。
关于reverse_copy案例如下:
//==================4.4、reverse_copy
int main() {
string OneSentance;
cout << "please input one swntance and Ctrl+Z to end:" << endl;
getline(cin, OneSentance);
if (cin.eof())
{
exit(0);
}
//复制相同字符至AnotherSentance并将所有字母大写
string AnotherSentance;
copy_if(begin(OneSentance), end(OneSentance),back_inserter(AnotherSentance) ,[](char ch) {return isalpha(ch); });
for_each(begin(AnotherSentance), end(AnotherSentance), [](char &ch) {ch = toupper(ch); });
//判断是否为回文
string reversed;
reverse_copy(begin(AnotherSentance), end(AnotherSentance), back_inserter(reversed));
cout << " ' " << OneSentance << " ' " << (AnotherSentance == reversed ? "is" : "is not") << " a palindrome!" << endl;
return 0;
}
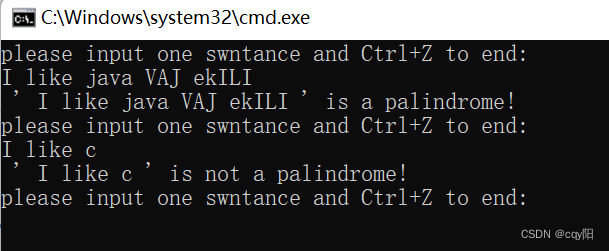
该程序目的是检查一条语句(也可以是很多条语句)是否是回文的。
回文语句是指正着读或反着读都相同的句子,前提是忽略一些像空格或标点这样的细节。
while 使我们可以检查尽可能多的句子。用 getline() 读一条句子到 OneSentence 中。如果读到 Ctrl+Z,输入流中会设置 1 个eof()标志,它会结束循环。用 copy_if() 将 OneSentence 中的字母复制到 AnotherSentence 。这个 lambda 表达式只在参数是字母时返回 true,所以其他的任何字符都会被忽略。然后用 back_inserter() 生成的 back_insert_iterator 对象将这些字符追加到 AnotherSentence。
for_each() 算法会将三个参数指定的函数对象应用到前两个参数定义的序列的元素上,因此这里会将 AnotherSentence中的字符全部转换为大写。然后用 reverse_copy() 算法生成和 AnotherSentence的内容相反的内容。比较 AnotherSentence和 reversed 来判断输入的语句是否为回文。
(6)rotate_copy
rotate_copy() :在新序列中生成一个序列的旋转副本,并保持原序列不变。
前 3 个参数和 copy() 是相同的;
第 4 个参数是一个输出迭代器,它指向目的序列的第一个元素。
这个算法会返回一个目的序列的输出迭代器,它指向最后一个被复制元素的下一个位置。
关于rotate_copy案例如下:
//==================4.4、rotate_copy
int main() {
vector<int> words{1,2,3,4,5,6,7,8};
auto start = find(begin(words), end(words), 2);
auto endd = find(begin(words), end(words), 8);
cout << "原序列:" << endl;
copy(begin(words), end(words), ostream_iterator<int>{cout, " "});
cout << endl;
vector<int> copy_word;
rotate_copy(start, find(begin(words), end(words), 5), endd, back_inserter(copy_word));
cout << "旋转副本序列:" << endl;
copy(begin(copy_word), end(copy_word), ostream_iterator<int>{cout, " "});
cout << endl;
cout << "原序列未变化:" << endl;
copy(begin(words), end(words), ostream_iterator<int>{cout, " "});
cout << endl;
return 0;
}
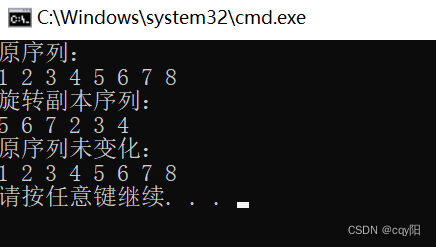

words 中从1 到 8的元素生成一个旋转副本。通过使用 back_insert_iterator 将复制的元素追加到 copy_word容器中,back_insert_iterator 会调用 words_copy 容器的成员函数 push_back() 来插入每个元素。
2.2.4 删除算法(6个)
| 函数名 | 解释 |
|---|---|
| remove() | 在指定范围内,将指定的元素删除。 |
| remove_if() | 在指定范围内,将满足指定一元谓词的元素删除。 |
| remove_copy() | 将源序列中除包含指定删除值外的所有元素复制到目标范围。 |
| remove_copy_if() | 将源序列中除满足指定一元谓词删除值外的所有元素复制到目标范围。 |
| unique() | 比较指定范围内的相邻元素,并删除重复的元素。 |
| unique_copy() | 将源范围内的所有元素复制到目标范围,但相邻的重鰒元素除外。 |
(1)remove
remove() :从前两个正向迭代器参数指定的序列中移除和第三个参数相等的对象。基本上每个元素都是通过用它后面的元素覆盖它来实现移除的。它会返回一个指向新的最后一个元素之后的位置的迭代器。
关于remove案例如下:
//==================5、remove
int main() {
deque<double> measures{ 21.5, 14.8, 0.0, 43.1, 0.0, 24.1, 0.0, 26.7, 0.0 };
measures.erase(remove(begin(measures), end(measures), 0.0), end(measures));
//remove(begin(measures), end(measures), 0.0);
copy(begin(measures), end(measures), ostream_iterator<double>{cout, " "});
cout << endl;
return 0;
}
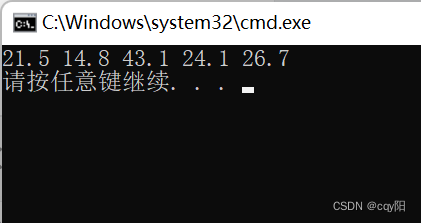
remove的结果:
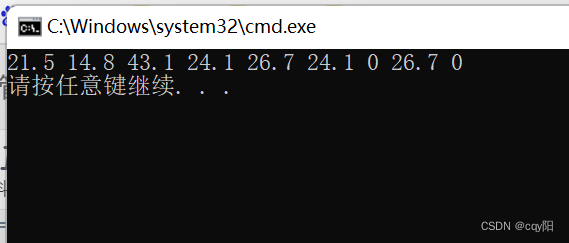
measures中不应包含为 0 的测量值。(重点)remove() 算法会通过左移其他元素来覆盖它们,通过这种方式就可以消除杂乱分布的 0。remove() 返回的迭代器指向通过这个操作得到的新序列的尾部,所以可以用它作为被删除序列的开始迭代器来调用 measures的成员函数 erase()。注释说明容器中的元素没有被改变。
关于remove和erase区别可以参考这篇博文:C++ remove和erase
(2)remove_if
remove_if() :从序列中移除和给定值匹配的元素。其中,谓词会决定一个元素是否被移除;它接受序列中的一个元素为参数,并返回一个布尔值。
remove_if()返回一个指向被修剪的序列的最后一个元素迭代器。remove_if()并不会实际移除序列[start, end)中的元素,所有的元素都还在容器里面。 实际做法是,remove_if()将所有应该移除的元素都移动到了容器尾部并返回一个分界的迭代器。 移除的所有元素仍然可以通过返回的迭代器访问到。为了实际移除元素,必须对容器自行调用erase()以擦除需要移除的元素。
关于remove_if案例如下:
//==================5.1、remove_copy
int main(){
using Name = pair<string, string>; // First and second name
set<Name> blackNames{ Name{ "Al", "Bedo" }, Name{ "Ann", "Ounce" }, Name{ "Jo","King" } };
deque<Name> VIPNames{ Name{ "Stan", "Down" }, Name{ "Al", "Bedo" }, Name{ "Dan", "Druff" },Name{ "Di", "Gress" }, Name{ "Ann", "Ounce" }, Name{ "Bea", "Gone" } };
VIPNames.erase(remove_if(begin(VIPNames), end(VIPNames), [&blackNames](const Name& name) { return blackNames.count(name); }), end(VIPNames));
for_each(begin(VIPNames), std::end(VIPNames), [](const Name& name) {std::cout << '"' << name.first << " " << name.second << "\" "; });
cout << endl;
return 0;
}
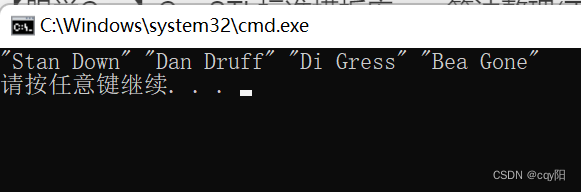
这段代码用来模拟候选人申请成为倶乐部会员:
将黑名单的姓名被保存在 blackNames中,它是一个集合。当前申请成为会员的候选人被保存在 VIPNames容器中,它是一个 deque 容器。用 remove_if() 算法来保证不会有 blackNames中的姓名通过甄选过程。这里的谓词是一个以引用的方式捕获 blackNames容器的 lambda 表达式。当参数在容器中存在时,set 容器的成员函数 count() 会返回 1。谓词返回的值会被隐式转换为布尔值,因此对于每一个出现在 blackNames中的候选人,谓词都会返回 true,然后会将它们从 VIPNames中移除。注释中显示了通过甄选的候选人。
(3)remove_copy
remove_copy():如果想保留原始序列,并生成一个移除选定元素之后的副本。可以使用remove_copy()算法。
关于remove_copy案例如下:
//==================5.2、remove_copy
int main() {
deque<double> measures{ 21.5, 14.8, 0.0, 43.1, 0.0, 24.1, 0.0, 26.7, 0.0 };
vector<double> samples;
cout << "原序列:" << endl;
copy(begin(measures), end(measures), ostream_iterator<double>{cout, " "});
cout << endl;
remove_copy(begin(measures), end(measures), back_inserter(samples), 0.0);
cout << "remove_copy后原序列:" << endl;
copy(begin(measures), end(measures), ostream_iterator<double>{cout, " "});
cout << endl;
cout << "remove_copy后目的序列(samples):" << endl;
copy(begin(samples), end(samples), ostream_iterator<double>{cout, " "});
cout << endl;
return 0;
}
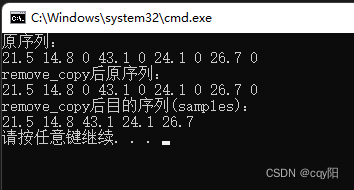
measures容器中的非零元素会被复制到 samples 容器中,samples 正好是一个 vector 容器。通过 back_insert_iterator 对象将这些元素添加到 samples,因此这个容器只包含从 measures中复制的元素。
(4)remove_copy_if
remove_copy_if() 的作用是基于remove_copy()之后,就像 remove_if() 之于 remove()。
关于remove_copy_if案例如下:
//==================5.3、remove_copy_if
int main(){
using Name = pair<string, string>;
set<Name> blackNames{ Name{ "Al", "Bedo" }, Name{ "Ann", "Ounce" }, Name{ "Jo","King" } };
deque<Name> VIPNames{ Name{ "Stan", "Down" }, Name{ "Al", "Bedo" },Name{ "Dan", "Druff" }, Name{ "Di", "Gress" }, Name{ "Ann", "Ounce" },Name{ "Bea", "Gone" } };
deque<Name> validated;
cout << "VIPNames原序列:" << endl;
for_each(begin(VIPNames), std::end(VIPNames), [](const Name& name) {std::cout << '"' << name.first << " " << name.second << "\" "; });
cout << endl;
remove_copy_if(begin(VIPNames), end(VIPNames), back_inserter(validated), [&blackNames](const Name& name) { return blackNames.count(name); });
cout << "remove_copy_if后的VIPNames序列:" << endl;
for_each(begin(VIPNames), std::end(VIPNames), [](const Name& name) {std::cout << '"' << name.first << " " << name.second << "\" "; });
cout << endl;
cout << "remove_copy_if后的validated序列:" << endl;
for_each(begin(validated), std::end(validated), [](const Name& name) {std::cout << '"' << name.first << " " << name.second << "\" "; });
cout << endl;
return 0;
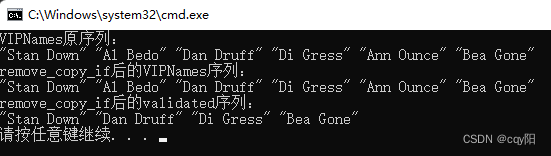
这段代码实现了和之前remove_if()代码类似的功能,除了结果被保存在 validated 容器中和没有修改 VIPNames 容器之外。
(5)unique
unique() :可以在序列中原地移除重复的元素,这就要求被处理的序列必须是正向迭代器所指定的。在移除重复元素后,它会返回一个正向迭代器作为新序列的结束迭代器。可以提供一个函数对象作为可选的第三个参数,这个参数会定义一个用来代替 == 比较元素的方法。
关于unique案例如下:
//==================5.4、unique
int main() {
vector<string> words{ "one", "two", "two", "three", "two", "two", "two" };
auto end_iter = unique(begin(words), end(words));
cout << "unique后的words序列:" << endl;
copy(begin(words), end(words), ostream_iterator<string>{cout, " "});
cout << endl;
cout << "unique后的变化显示:" << endl;
copy(begin(words), end_iter, ostream_iterator<string>{cout, " "});
cout << endl;
return 0;
}

这段代码实现消除 words 中的连续元素。但是,没有元素会从输入序列中移除;算法并没有方法去移除元素,因为它并不知道它们的具体上下文。整个序列仍然存在。但是,无法保证新末尾之后的元素的状态;如果在上面的代码中用 end(words) 代替 end_iter 来输出结果就是:one two three two two two。
(6)unique_copy
前面讲的unique()的功能是去除相邻的重复元素(只保留一个)。但是它并不真正把重复的元素删除了,是把非重复的元素往前移动替换到重复的元素。
而 unique_copy()的功能是去除相邻的重复元素(只保留一个)的结果保留到第三个参数中(一般这是一个空容器),对原容器并不修改。
关于unique_copy案例如下:
//==================5.5、unique_copy
int main() {
vector<int> nums = { 10, 5, 40, 10, 5, 20, 10, 10, 30 };
sort(nums.begin(), nums.end());
cout << "排序后num = " << endl;
for (const auto &num : nums) {
cout << num << " ";
}
cout << endl;
vector<int> newNums;//nums排序后去重的结果保留容器
unique_copy(nums.begin(), nums.end(), back_inserter(newNums));
cout << "排序、去重后newNums = " << endl;
for (const auto &num : newNums) {
cout << num << " ";
}
cout << endl;
return 0;
}

3、总结
最后,长话短说,大家看完就好好动手实践一下,切记不能三分钟热度、三天打鱼,两天晒网。大家也可以自己尝试写写博客,来记录大家平时学习的进度,可以和网上众多学者一起交流、探讨,我也会及时更新,来督促自己学习进度。一开始提及的博主【AI菌】,个人已关注,并订阅了相关专栏(对我有帮助的),希望大家觉得不错的可以点赞、关注、收藏。