本项目将 Whisper 与 Stable Diffusion 模型结合,可以直接完成语音生成图像的任务。用户可以语音输入一个短句,Whisper 会自动将语音转化为文本,接着,Stable Diffusion 会根据文本生成图像。
本项目基于 Jina AI MLOps 平台搭建,通过使用 DocArray 跨越了不同数据类型之间的鸿沟,减少了应用的数据传输成本。同时使用 Jina 搭建了一个云原生的基于微服务的 Pipeline,并且很容易就能部署到 Kubernetes 系统中。
作者:Sami Jaghouar, Alex C-G
译者:吴书凝
原文链接:jina.ai/news/speech-to-image-generation
我们都习惯了用 Siri、天猫精灵等智能语音助手来设置闹钟,播报天气,甚至它也会给我们讲一些冷笑话。但是怎样才能更进一步呢?我们怎样才能用自己的声音作为桥梁,和世界以及机器进行更加深入、有趣的交互呢?
目前的智能语音助手都是基于单模态的,即输入我们的声音会输出它们的声音,与此同时,智能语音助手还会执行我们的指令。这种单模态的工作模式就像是钢铁侠的 Mark I。虽然对于现有的任务,智能语音助手已经完成得很好了,但是随着技术的不断革新,我们期望它能有更多的创新。
将 AI 技术赋能于语音识别系统,可以使得机器生成精美的画面,这就像是为 Alexa(亚马逊旗下的智能语音助手)装配上激光炮和火箭靴。我们也可以借此实现更加复杂的应用。
不同于单模态的智能语音助手 Alexa、Siri,通过 Jina,我们将打开多模态世界[1]的大门。我们可以利用文本生成图像,语音生成视频,甚至是任何一种模态信息生成(或者检索)另一种模态信息。
与此同时,我们不需要成为钢铁侠这样的天才,甚至无需拥有浩克一样的智力,仅仅使用 90 行代码就能使魔法变为现实。我们可以利用云原生的微服务框架完成跨模态转换任务,并将其部署在 Kubernetes 上。
初步调研
过去的几年里,人工智能技术呈爆发式发展,我们的研究也从单模态模型(例如,用于文本的 Transformers,用于图像的 Big Image Transfer)迅速转向可以同时处理不同形态数据的多模态模型。
遗憾的是,即使我们的模型已经转向多模态,这也依然过时了。就在今年,我们发现文本生成图像的工具急剧增长,例如 DiscoArt[2], DALL-E 2 和 Stable Diffusion。还有一些其他的模型甚至可以完成文本生成视频,图像生成 3D 模型的任务。
Stable Diffusion 可以用来生成图像(我们已经用它生成了以下图像):
美队骑摩托的照片

钢铁侠和Luke Skywalker跳舞的照片

Prompt:用生动的色彩,Artstation的流行趋势画一张蜘蛛侠在纽约上空飞檐走壁的4K数字插画。
现在热门的不仅是多模态的文本图像生成,就在几周前,OpenAI 发布了一个自动语音识别系统 Whisper[3]。在处理口音、背景噪声以及技术术语方面,Whisper几乎达到了人类的水准。
本文将 Whisper 与 Stable Diffusion 结合,可以直接完成语音生成图像的任务。用户可以语音输入一个短句,Whisper 会自动将语音转化为文本,接着,Stable Diffusion 会根据文本生成图像。
现有解决方案
语音生成图像并不是一个新的概念,许多学者已经写过相关的论文:
-
• S2IGAN: Speech-to-Image Generation via Adversarial Learning
-
• Direct Speech-to-Image Translation
-
• Using AI to Generate Art - A Voice-Enabled Art Generation Tool
-
• Built with AssemblyAI - Real-time Speech-to-Image Generation
与以上方案不同的是,我们的示例基于最前沿的模型,并且完全可扩展。我们的应用程序是利用微服务架构搭建的,非常容易就可以部署到 Kubernetes。更重要的是,相比于上述的解决方案,我们需要的代码量更小。
关键挑战
当思考可以用最新的多模态模型搭建什么时,你的想象可能会天马行空,但是实际的搭建不同于想象,存在几个关键问题:
1. 依赖地狱
构建一个单片机集成系统相对简单,但如果将前沿的深度学习模型绑定在一起就会导致依赖冲突。因为这些模型在搭建时为了炫技,而忽略了兼容性。这就像钢铁侠的火箭靴和激光炮并不兼容一样,当他在空中击中齐塔瑞后,火箭靴就会消失,他则像岩石一样从空中坠落。而我们将突破兼容技术,拯救钢铁侠的生命!
2. 选择数据格式
如果要处理多模态信息,只选择一种数据类型在不同模态的数据间互操作非常麻烦,而当我们只需要处理单模态信息时,文本就可以用字符串,图像就可以使用 Tensor。但是在我们的示例中需要同时处理语音和图像,如何为不同的数据类型提供一站式的解决方案是一个棘手问题。
3. 打包所有模型
最大的挑战还是在于混合不同的模型并且构建一个完全成熟的应用。当然你也可以将模型打包成容器,部署到云端并提供 API。但是一旦你想将两个模型连接在一起,创建一个稍微复杂的应用,就会出现混乱。尤其是当你想构建一个基于微服务架构的应用时,例如,复用部分 Pipeline(流水线)以避免停机,此时该如何在不同的模型之间进行通信呢?更不用说在 Kubernetes 这样的云原生平台上部署,或者监控、观测你的 Pipeline 了。
Jina 的解决方案
作为目前最先进的多模态 AI 的 MLOps 平台,Jina 生态帮助开发者和企业解决跨模态生成任务(比如:语音图像生成)面临的挑战。为了以纯净、易扩展、可部署的方式整合 Whisper 和 Stable Diffusion,我们将:
-
• 使用 Jina 将深度学习模型封装成 Executors。
-
• 将 Executors 组合后得到 Jina Flow(可复用、分片的云原生AI应用)。
-
• 使用 DocArray 将数据发送至 Flow,用 Jina Hub 上的 Executor 依次处理数据。
-
• 将应用部署到 Kubernetes/JCloud,并实现可观测性。
Pipelines 和 building blocks 不仅仅只是概念,Flow 是一个云原生应用,每个 Executor 都是一个微服务。
Jina 通过将每个 Executor 作为微服务,将 building blocks 组合 (通过模块、类分离)转化为云原生组合。这些微服务可以无缝复用和分片。Flow 和 Executors 都是由最先进的网络工具提供支持,并且依赖于双流网络。
这解决了以上提到的 3 个问题:
-
1. 依赖地狱 -> 每个模型都被封装成单独的微服务 Executor,因此互相不干扰。
-
2. 选择数据格式 -> DocArray 可以处理我们输入的任何数据,无论是语音、文本、图像还是其它数据格式。
-
3. 打包所有模型 -> Jina 将模型封装成微服务 Executor后,Jina Flow 协调所有的微服务并给用户提供接口。基于 Jina 的云原生功能,我们还可以轻松将应用部署到 Kubernetes 或 JCloud,并观察和监控应用。
1. 构建 Executors
多模态检索或者生成任务都需要一些步骤构建 Executors,具体取决于你的任务。在我们的语音生成图像任务中,步骤如下:
-
1. 在界面中输入用户的声音。
-
2. 用 Whisper 将语音转换为文本。
-
3. 将输出的文本输入到 Stable Diffusion 中即可生成图像。
-
4. 在界面中显示图像。
由于我们更关注后端算法,所以我们将聚焦于步骤 2、3,并将每一个模型都封装成一个个 Executor:
-
• WhisperExecutor - 将用户的声音转化为文本。
-
• StableDiffusionExecutor - 根据文本生成图像。
在 Jina 中,Executor 是可以执行单个任务的微服务。所有 Executor 都使用 Documents 作为基本数据类型。详见“流数据”部分。
通过编写 Executors(模块/类分离)使得每个 Executor 都可以无缝地分片、复用,并部署在Kubernetes,并且他们都是可观测的。
WhisperExecutor 代码见以下代码段,其中每个函数都有自己的@requests装饰器[4],用户可以通过调用函数指定网络端口。由于我们没有指定端口,所以访问任何端口时都会调用transcribe() 。
class WhisperExecutor(Executor):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.model = whisper.load_model('base')
@requests
def transcribe(self, docs: DocumentArray, **kwargs):
for (i, doc_) in enumerate(docs):
model_output = self.model.transcribe(
doc_.uri if doc_.tensor is None else doc_.tensor
)
doc_.text = model_output['text']
doc_.tags['segments'] = model_output['segments']
doc_.tags['language'] = model_output['language']
return docs2. 构建 Flow
Flow 是将 Executors 组合后得到的可以用于多/跨模态模型的 Pipeline,Documents 会进入 Pipeline,并且由 Executors 处理。
Flow 相当于配置和启动微服务架构的接口,其它的工作则是由 Executors 完成。每个 Flow 都会登录 Gateway[5](网关)服务,因此可以通过自定义的 API 连接其他服务。Gateway 将所有的 Executor 连接在一起,并且根据 Flow 的拓扑结构[6] 确保每个请求都能通过不同的 Executor(例如,它在 ExecutorB 之前进入 ExecutorA)。
语音图像生成应用的 Flow 的拓扑结构相对简单,只有两个 Executor,WhisperExecutor 和 StableDiffusionExecutor。下面的代码定义了 Flow,并且为用户提供了连接和传输数据的端口。
Flow 可以通过 flow.plot()可视化[7]。

Flow 拓扑结构
3. 流数据
进出 Flow 的所有内容都必须是 Document,Document 是 DocArray 包中的一个类。DocArray为多模态数据(我们的示例中有语音、文本、图像)提供了一个通用的 API,可以将不同模态的数据,统一成同一种数据结构。
这就意味着无论使用什么模态的数据, Document 都可以存储。并且由于所有的 Executor 使用的数据类型都是Documents 和 DocumentArrays,因此可以确保一致性。
在我们的语音图像生成任务中,输入的 Document 是用户声音的采样。Document 将采样得到的语音数据存储成 Tensor。
如果我们把输入 Document 视为doc:
-
1. 首先会通过前端页面创建
doc,接着,用户输入的声音会存储为doc.tensor。 -
2. 通过调用 gRPC 接口,可以将
doc从前端发送到 WhisperExecutor。 -
3. WhisperExecutor 会将接收到的 tensor 转换成
doc.text。 -
4. 之后,
doc会被发送到 StableDiffusionExecutor。 -
5. StableDiffusionExecutor 会读取
doc.text并根据文本内容生成两张图像,图像将会保存在doc.matches中。 -
6. 紧接着,前端会接收来自于 Flow 的
doc。 -
7. 最终,前端会获取输出的 Document,并且在界面上显示出生成的图像。
用户可以通过 Flow 将 Jina客户端[8]和 第三方客户端[9] 连接起来,在我们的 示例中,Flow 启动了 gRPC 端口。并且只需一行代码,就可以轻松地将 gRPC 端口替代成 RESTful、WebSockets 或者 GraphQL 端口。此外,Gateways 被部署在 Deployment 中,用来将请求发送至 Executors。更重要的是,这些转换都是由 Jina 实时完成的。
5. 部署 Flow
Jina 作为云原生框架,和 Kubernetes 的结合最为耀眼。“用 Kubernetes 部署”的文档[10] 解释了如何在 Kubernetes 上部署 Flow,接下来让我们一起揭开帷幕,深入了解底层的原理吧。
就像之前提到的,Executor 是一个容器化的微服务。我们应用程序中的两个 Executor 都是作为 Deployment 独立部署在 Kubernetes 系统中。此外,Gateway 部署在 Deployment 中,以便请求通过 Executor。这就意味着 Kubernetes 可以处理它们的生命周期、机器调度等。更重要的是, 你只需要用 Python 定义 Flow,Jina 就会即时帮你完成部署工作。
当然你也可以在 JCloud 上部署 Flow,JCloud 也可以完成上述内容,同时它还提供了一个便捷的监视 dashboard。你只需要将 Python Flow 转换为 YAML Flow(包含一些 JCloud 的特定参数),之后就可以部署:
jc deploy flow.yaml最终效果
现在,就是见证奇迹的时刻!输入一些测试查询:
启动监视后(默认开启),Flow 内部发生的一切都可以在 Grafana dashboard 中可视化。

监视的优势在于它可以帮助你优化应用程序,并且通过检测性能瓶颈使得你的应用程序更加经济高效。例如,以下监视结果显示:在我们的应用中,StableDiffusionExecutor 存在性能瓶颈:
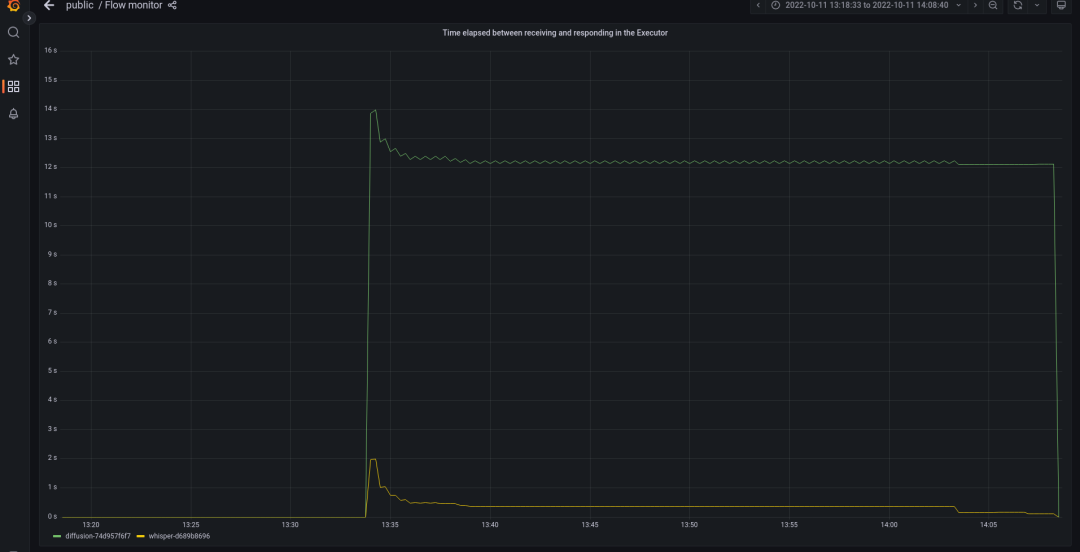
这意味着负载过重会导致延时飙升。为了提高运行效率,我们可以复用 StableDiffusionExecutor,并将图像生成任务分布在不同的机器上。
f = (
Flow(port=54322)
.add(uses=WhisperExecutor)
.add(uses=StableDiffusionExecutor, uses_with={'auth_token': hf_token}, replicas=2)
)或者可以修改 JCloud YAML 文件:
- name: diffusion
uses: jinahub+docker://StableDiffusionExecutor
uses_with:
auth_token: YOUR_TOKEN
timeout_ready: -1 # slow download speed often leads to timeout
replicas: 2
jcloud:
resources:
gpu: 1
memory: 16结论
本文我们用最前沿的 AI 模型和 Jina AI MLOps 平台搭建了一个云原生的语音图像生成的应用程序。
我们通过使用 DocArray 跨越了不同数据类型之间的鸿沟,减少了应用的数据传输成本。同时使用 Jina 搭建了一个原生的基于微服务的 Pipeline,并且它很容易就能部署到 Kubernetes 系统中。
由于 Jina 是一个模块化的架构,所以很容易就能将类似的方案应用到不同的用例中,例如:
-
• 搭建多模态的 PDF 搜索引擎,用户可以使用文本或图像来搜索匹配的 PDF。
-
• 构建一个多模态的时尚搜索引擎,用户可以根据文本或图像来搜索商品。
-
• 用于电影场景设计的 3D 生成模型。
-
• 基于 GPT-3 的博客生成模型。
这些应用都是云原生、易扩展的,并且非常容易部署到 Kubernetes 集群中。
引用链接
[1] 多模态世界: https://jina.ai/news/paradigm-shift-towards-multimodal-ai/[2] DiscoArt: https://colab.research.google.com/github/jina-ai/dalle-flow/blob/main/client.ipynb[3] Whisper: https://openai.com/blog/whisper/?utm_source=blog-speech-image[4] request装饰器: https://docs.jina.ai/fundamentals/executor/executor-methods/?utm_source=blog-speech-image[5] Gateway: https://docs.jina.ai/fundamentals/gateway/?utm_source=blog-speech-image[6] Flow的拓扑结构: https://docs.jina.ai/fundamentals/flow/topologies/?utm_source=blog-speech-image[7] 可视化: https://docs.jina.ai/fundamentals/flow/create-flow/#visualize?utm_source=blog-speech-image[8] Jina客户端: https://docs.jina.ai/fundamentals/client/client/?utm_source=blog-speech-image[9] 第三方客户端: https://docs.jina.ai/fundamentals/client/third-party-client/?utm_source=blog-speech-image[10] 用Kubernetes部署文档: https://docs.jina.ai/how-to/kubernetes/?utm_source=blog-speech-image
更多资料
💻 GitHub: get.jina.ai
📖 文档:docs.jina.ai
🔗 原文链接:jina.ai/news/speech-to-image-generation
🧑💻 本项目地址:github.com/jina-ai/example-speech-to-image








![[附源码]java毕业设计医院档案管理系统](https://img-blog.csdnimg.cn/265a91fb4866483c9d6eae4287b94c36.png)