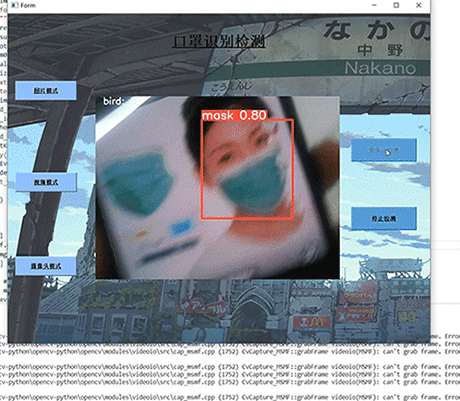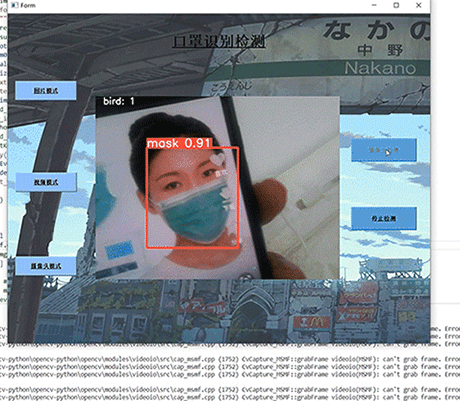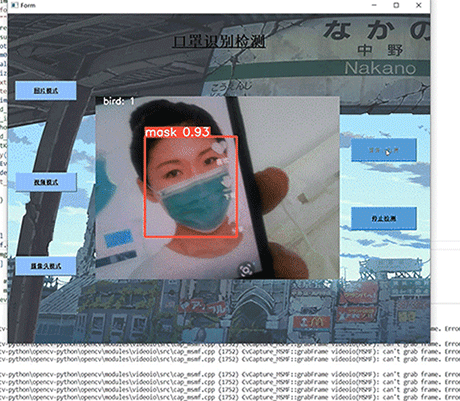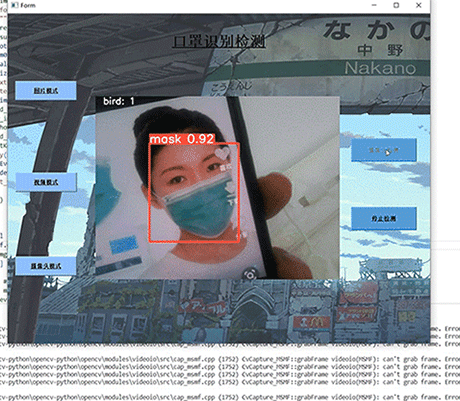
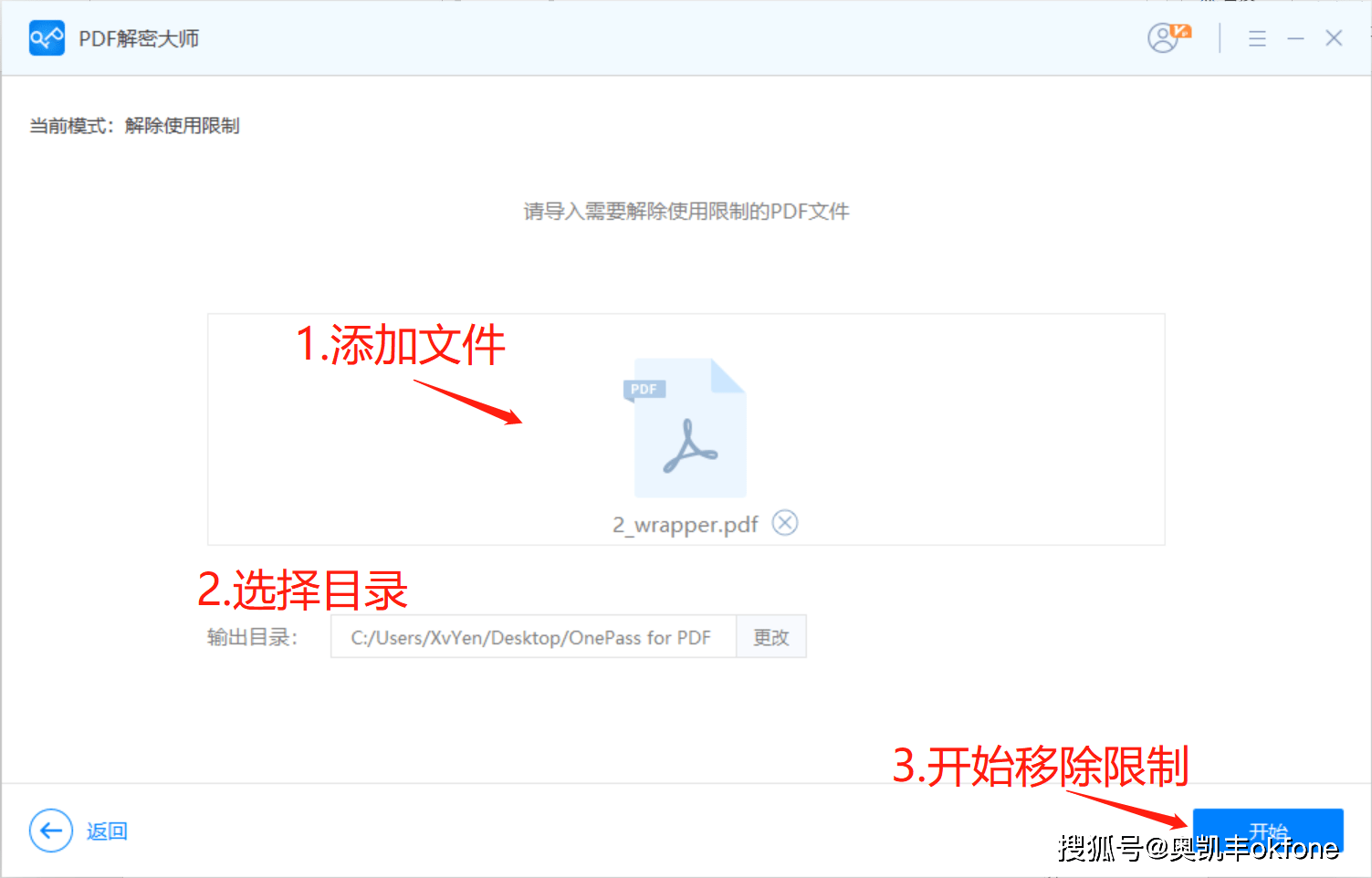
- 数据库技术是信息资源管理最有效的手段。数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库极其应用系统,有效存储数据,满足用户信息要求和处理要求。
数据库设计的步骤
⒈需求分析阶段
- 收集和分析用户需求,结果得到数据字典描述的数据需求。
- 常用的调查方法
- ⑴跟班作业
- ⑵开调查会
- ⑶请专人介绍
- ⑷询问对某些调查中的问题,可以找专人询问。
- ⑸设计调查表请用户填写
- ⑹查阅记录
⒉概念结构设计阶段
- 通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型,可以用E-R图表示。这是数据库设计的关键
⒊逻辑结构设计阶段
- 将概念结构转换为某个DBMS所支持的数据模型(例如关系模型),并对其进行优化(例如使用范式理论)
⒋数据库物理设计阶段
- 为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)。
⒌数据库实施阶段
- 运用DBMS提供的数据语言(例如SQL)及其宿主语言(例如C),根据逻辑设计和物理设计的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行
⒍数据库运行和维护阶段
- 数据库应用系统经过试运行后即可投入正式运行。在数据库系统运行过程中必须不断地对其进行评价、调整与修改
数据字典
对数据库设计来讲,数据字典是进行数据收集和数据分析所获得的主要成果。数据字典是各类数据描述的集合。
数据字典通常包括数据项、数据结构、数据流、数据存储和处理过程五个部分。
- 数据项是不可再分的数据单位
- 数据结构反映了数据之间的组合关系。一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成,或由若干个数据项和数据结构混合组成
- 数据流是数据结构在系统内传输的路径
- 数据存储是数据结构停留或保存的地方,也是数据流的来源和去向之一
- 处理过程描述={处理过程名,说明,输入:{数据流},输出:{数据流}, 处理:{简要说明}}
设计概念结构通常有四类方法
自顶向下
- 即首先定义全局概念结构的框架,然后逐步细化。
自底向上
- 即首先定义各局部应用的概念结构,然后将它们集成起来,得到全局概念结构。这是最经常采用的策略。即自顶向下地进行需求分析,然后再自底向上地设计概念结构
逐步扩张
- 首先定义最重要的核心概念结构,然后向外扩充,以滚雪球的方式逐步生成其他概念结构,直至总体概念结构
混合策略
- 即将自顶向下和自底向上相结合,用自顶向下策略设计一个全局概念结构的框架,以它为骨架集成由自底向上策略中设计的各局部概念结构
E-R图
E-R方法是抽象和描述现实世界的有力工具
要点
- 使用长方形来表示实体型,框内写上实体名
- 椭圆型表示实体的属性,并用无向边把实体和属性连接起来。
- 用菱形表示实体间的联系,菱形框内写上联系名,用无向边把菱形分别与有关实体相连接,在无向边旁标上联系的类型,若实体之间联系也具有属性,则把属性和菱形也用无向边连接上。
E-R图之间的冲突主要有三类
- 属性冲突
- (1) 属性域冲突,即属性值的类型、取值范围或取值集合不同。
- (2) 属性取值单位冲突
- 命名冲突
- (1) 同名异义
- (2) 异名同义(一义多名)
- 结构冲突
- (1) 同一对象在不同应用中具有不同的抽象。例如“教材”在某一局部应用中被当作实体,而在另一局部应用中则被当作属性
- (2) 同一实体在不同局部视图中所包含的属性不完全相同,或者属性的排列次序不完全相同
- (3) 实体之间的联系在不同局部视图中呈现不同的类型。例如实体E1与E2在局部应用A中是多对多联系,而在局部应用B中是一对多联系;又如在局部应用X中E1与E2发生联系,而在局部应用Y中E1、E2、E3三者之间有联系
逻辑结构设计阶段
一个实体型转换为一个关系模式。实体的属性就是关系的属性。实体的码就是关系的码。
-
一个m:n联系转换为一个关系模式。与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性。而关系的码为各实体码的组合。
-
一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。如果转换为一个独立的关系模式,则与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,而关系的码为n端实体的码。
-
一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。如果转换为一个独立的关系模式,则与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,每个实体的码均是该关系的候选码。如果与某一端对应的关系模式合并,则需要在该关系模式的属性中加入另一个关系模式的码和联系本身的属性。
-
三个或三个以上实体间的一个多元联系转换为一个关系模式。与该多元联系相连的各实体的码以及联系本身的属性均转换为关系的属性。而关系的码为各实体码的组合。
-
具有相同码的关系模式可合并。
数据模型的优化
确定数据依赖
对于各个关系模式之间的数据依赖进行极小化处理,消除冗余的联系。
按照数据依赖的理论对关系模式逐一进行分析,考查是否存在部分函数依赖、传递函数依赖、多值依赖等,确定各关系模式分别属于第几范式。
按照需求分析阶段得到的各种应用对数据处理的要求,分析对于这样的应用环境这些模式是否合适,确定是否要对它们进行合并或分解。
对关系模式进行必要的分解。
设计用户子模式
(1) 使用更符合用户习惯的别名
(2) 针对不同级别的用户定义不同的视图,以满足系统对安全性的要求
(3) 简化用户对系统的使用
数据库物理设计
确定数据库存储结构时要综合考虑存取时间、存储空间利用率和维护代价三方面的因素。这三个方面常常是相互矛盾的。
为了提高系统性能,数据应该根据应用情况将易变部分与稳定部分、经常存取部分和存取频率较低部分分开存放