⭕⭕ 目 录 ⭕⭕
- ✳️ 一、引言
- ✳️ 二、深度去噪网络结构设计
- ✳️ 2.1 网络层数的设定
- ✳️ 2.2 残差学习
- ✳️ 2.3 批规范化
- ✳️ 三、实验结果
- ✳️ 3.1 网络训练
- ✳️ 3.2 实验结果比较
- ✳️ 四、参考文献
- ✳️ 五、Matlab代码获取
✳️ 一、引言
由于图像去噪问题的退化模型假设比较简单,因此从贝叶斯的角度来说,图像去噪的主要难点在于如何设计更加有效的图像先验,也即如何对自然图像更好的建模。在过去的几十年间,不同的先验模型例如非局部自相似性先验、稀疏性先验、马尔科夫随机场先验等相继提出。特别地,非局部自相似性由于其出色的自然图像建模能力广泛地被用于当今流行的图像去噪方法中,如BM3D、LSSC、NCSR以及WNNM等。
尽管近几年间图像去噪取得了长足的进展,然而这些方法普遍存在着两个缺点。首先,这些方法大都需要求解一个复杂的优化过程,进而影响其在实际应用中的效率,因此这些方法往往牺牲速度来取得比较好的性能。其次,这些方法的优化求解中不可避免的包含大量的手工调整参数,进而限制了其性能的进一步提升。为了克服以上缺点,不同的基于最大后验 (MAP) 推断引导的判别学习方法相继提出。Schmidt 等提出了一种级联收缩场 (CSF) 方法将基于随机场的模型与半二次优化统一到一个框架下。Chen 等从反应扩散方程以及双层优化的角度给出了基于 MAP 推断引导的判别学习模型,并解释了其推断模型与递归神经网络的内在联系。尽管此类方法在效率上明显优于传统的基于模型的方法,但是由于其对应的先验为预先人为设定的解析模型,因此同样不可避免地无法准确对复杂的图像先验进行建模。此外,其基于贪婪训练和微调的训练框架包含众多的手工调整参数,因此其模型的可扩展性不是很好。另一个缺点是,此类判别学习方法只能针对特定噪声水平训练一个模型。
不同于CSF和 TNRD 学习具有显式图像先验的判别模型,将图像去噪问题看作普通的判别学习问题,从函数回归的角度用卷积神经网络(CNN)将噪声从噪声图像中分离出来。之所以采用 CNN,原因有以下几点:
第一,CNN可以有效地提升模型的建模能力,并且有效地对图像先验进行建模。
第二,有关设计、训练 CNN 的方法有了非常大的突破,例如 ReLU 激活函数、批规范化网络训练技术、残差学习等方法可以有效地提升网络训练速度和去噪性能。
第三,CNN 非常适合在 GPU 上进行高性能并行计算,因此可以借助 GPU来提升运算速度。
✳️ 二、深度去噪网络结构设计
图1给出了提出的深度去噪网络结构,假设网络的深度也即网络的卷积层的个数为D,输入图像通道个数为c,提出的网络由三种主要的模块构成,分别为:第一层的“卷积+ReLU激活函数”模块,其中卷积核大小为3×3×c,此卷积层将输入图像映射为64个特征图(Feature Map),然后ReLU激活函数用来激活网络的非线性能力;第2∼(D−1)层的“卷积+批规范化+ReLU激活函数”模块,其中每个卷积层都包含64个3×3×64大小的滤波器;最后一层的“卷积”模块,此卷积层的包含c个3×3×64大小的滤波器,此模块将64个特征图重建为最后的残差图像。

根据以上说明,可以看出该深度去噪网络相比于传统的CNN具有两个不同之处。首先,网络引入了残差学习的策略用于学习 ℜ ( y ) \Re (y) ℜ(y);给定输入y=x+n,传统的判别学习方法例如 MLP、CSF的目标是学习一个映射函数F(y)=x用来预测清晰图像,对于该深度去噪网络,采用残差学习策略训练一个残差映射函数 ℜ ( y ) ≈ n \Re (y)\approx n ℜ(y)≈n,然后根据 x = y − ℜ ( y ) x=y-\Re (y) x=y−ℜ(y)得到最终的清晰图像。因此残差图像与预测的残差图像之间的均方误差

作为损失函数来训练网络的参数Θ,其中 { ( y i , x i ) } i = 1 N \left\{ \left( {{y}_{i}},{{x}_{i}} \right) \right\}_{i=1}^{N} {(yi,xi)}i=1N表示 N 个噪声图像、清晰图像对。其次,采用了批规范化技术用来加快训练速度和提升性能。结合卷积层和非线性 ReLU 层,提出的深度去噪网络可以将隐含的清晰图像逐层去除,这种机制类似于 WNNM和 EPLL等传统基于模型的方法迭代逐次去噪策略,不同的是深度去噪网络可以进行端对端的训练。
✳️ 2.1 网络层数的设定
卷积层滤波器的大小统一设置为3×3,因此层数为d的网络其感受野为(2d+1)×(2d+1)。众所周知,增加网络的感受野可以利用更多的图像上下文信息提高重建性能,然而无限制地增加网络层数会降低网络的效率,因此为了权衡速度和性能,需要对网络层数进行设定。有学者指出去噪网络中的感受野对应着传统去噪方法的有效图像块大小,而且高噪声图像往往需要更大的有效图像块,进而可以利用更多的上下文信息重建清晰图像。
为了研究提出的去噪网络用更小的感受野是否可以超过现有的去噪方法,采用感受野大小为35×35,其对应的网络层数为17。
✳️ 2.2 残差学习
深度网络残差学习的提出最初是用来解决性能退化问题,也即随着网络深度的增加,网络性能开始饱和然后迅速下降,然而实验证明性能下降并不是由过度拟合造成的。相反,增加更多的层数会造成更高的训练误差。残差学习的主要思想对于图像去噪来说,噪声图像y和清晰图像x通常比较相似,因此用网络直接学习恒等映射 F(y) = x 就比较接近恒等映射,而残差网络直接学习 R(y)=y−x会使得训练更容易。由多个残差学习模块构成的网络即为残差网络 ResNet,基于此种思想,ResNet 已经在图像分类、物体检测等取得了非常好的效果。
✳️ 2.3 批规范化
小批量 (mini-batch) 随机梯度下降 (SGD) 已经被广泛地用于训练各种神经网络模型,然而在以往模型的训练当中,通常需要很谨慎地选择模型的超参数,特别是学习率的选择和参数的初始化。因为深层网络中,就单层而言,每一层的输入是前面所有层的输出,这个输出往往是不稳定的,它会随着前面层的参数的迭代更新而产生变化,这导致两个问题:1) 每一层都要学习不同的数据分布,但是本文希望输入网络的数据分布是稳定的。2) 一旦前层的参数产生变化,经过多层以后会被放大,从梯度消失的角度上来说,由于前层的微小变化会导致输出的巨大变化,进而如果网络的输出产生微小的变化,这就需要网络前层的参数几乎不更新。
批规范化的主要思想是在每次SGD时,通过mini-batch来对相应的输入x 做规范化操作,使其 (输出信号各个维度) 的均值为 0、方差为 1,具体操作如

规范化操作之后进行 “放缩和平移 (scale and shift)” 操作

此操作的目的是让因训练所需而加入的批规范化能够有可能还原最初的输入,从而保持整个网络的拟合能力。正是因为批规范可以使得网络中的各层输入具有相同的均值和方差,进而使得每层的输入空间数据分布是一致的,因此批规范化也成功地应用于迁移学习、领域适应等新兴问题。
✳️ 三、实验结果
✳️ 3.1 网络训练
对于高斯去噪,采用400张180×180大小的图像进行训练。发现用更大的训练数据可以稍微提升去噪网络最终的性能。对于非盲高斯去噪,考虑的三种噪声水平,分别为σ=15、25和50。训练图像块的大小设置为40×40,总共裁取128×1600个图像块用于网络的训练。为了训练一个盲高斯去噪网络,本文将图像噪声水平设置为区间σ∈[0,55],其中图像块的大小设置为50×50,总共提取128×3000个图像块用于训练。
✳️ 3.2 实验结果比较
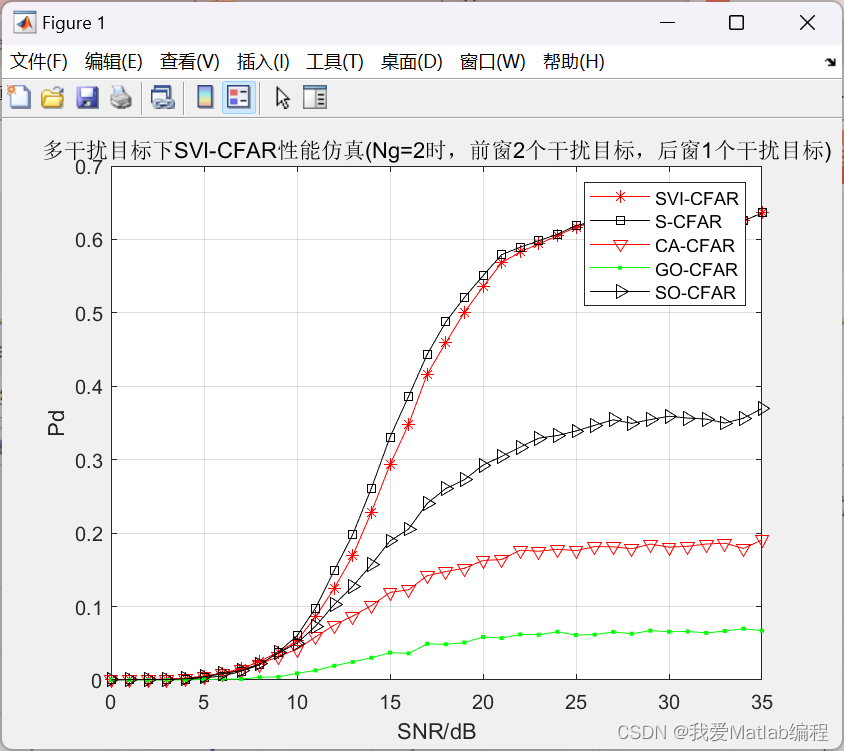
基于残差学习的卷积神经网络图像去噪结果如图2所示,其中,它的峰值信噪比为30.0009;结构相似度指数为0.8778。

开展了基于BM3D的对比实验,其去噪结果如下图所示:此时,它的峰值信噪比为27.6611;结构相似度指数为0.8014。

✳️ 四、参考文献
[1] Dabov K, Foi A, Katkovnik V, Egiazarian K. Image denoising by sparse 3-D transform-domain collaborative filtering [J]. IEEE Transactions on Image Processing. 2007, 16 (8): 2080–2095.
[2] Zhang K., W. Zuo, Y. Chen, et al. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising[J]. IEEE Transactions on Image Processing, 2017, 26(7): 3142-3155.
[3] Mairal J, Bach F, Ponce J, Sapiro G, Zisserman A. Non-local sparse models for image restoration [C]. In IEEE International Conference on Computer Vision. 2009: 2272–2279.
[4] Dong W, Zhang L, Shi G, Li X. Nonlocally centralized sparse representation for image restoration [J]. IEEE Transactions on Image Processing. 2013, 22 (4): 1620–1630.
✳️ 五、Matlab代码获取
上述实验结果由Matlab代码实现,可私信博主获取。
博主简介:研究方向涉及智能图像处理、深度学习等领域,先后发表过多篇SCI论文,在科研方面经验丰富。任何与算法、程序、科研方面的问题,均可私信交流讨论。