文章目录
- 0 前言
- 1. 概念
- 1.2 分类
- 2 基于用户的协同过滤
- 2.1 相似性计算
- 2.1.1 欧氏距离
- 2.1.2 余弦相似度
- 2.1.3 皮尔逊相关系数Pearson
- 2.1.4 杰卡德相似度 Jaccard
- 小结:
- 2.2 结果分数
- 2.3 优缺点分析
- 3 基于物品的协同过滤
- 3.1 结果分数
- 3.2 优缺点分析
- 4 总结
- 4.1 应用场景
- 4.2 问题分析
- 补充:推荐算法评价指标
- 参考
0 前言
最近学习推荐系统算法 ,准备把自己的学习过程记录一下吧,尽量不说废话。因为之前有机器学习和深度学习(CV)领域基础,在算法上面可能会快一些。有时间就会在这边不定期整理出来。
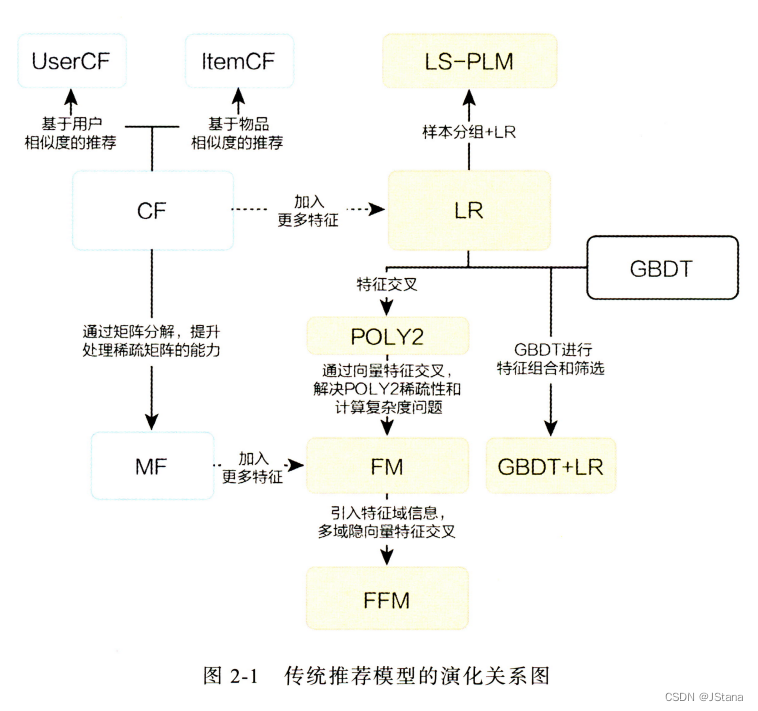
包括大数据和推荐算法。算法方面先从最传统推荐模型开始学习,然后深度学习(NLP 图神经网络领域是我的薄弱环节)。下面是《深度学习推荐系统》中的配图,让我们对传统推荐模型有个整体发展脉络(悄咪咪:我买书了…)
开篇自然从最经典的 协同过滤算法 开始!
本文大量参考博客 主要因为写的通俗易懂,包括案例 就让我懒得再敲CF代码了
1. 概念
协同过滤算法 (Collaborative Filtering Recommendation)
- 协同,就是利用群体的行为来做决策(推荐)
- 过滤,就是从可行的决策(推荐)方案(标的物)中将用户喜欢的方案(标的物)找(过滤)出来
一般是仅仅基于用户的行为数据(评价、购买、下载等), 而不依赖于项的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄, 性别等)。具体而言就是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品(基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐)。
1.2 分类
- 基于邻域的方法(neighborhood-based)
- 隐语义模型 (latent factor model)
- 基于图的随机游走算法(random walk on graph)等
最广泛运用的算法仍然是是**基于领域的方法:**基于用户的协同过滤算法;基于物品的协同过滤算法
- 基于用户的协同过滤算法(UserCF): 给用户推荐和他兴趣相似的其他用户喜欢的产品
- 基于物品的协同过滤算法(ItemCF): 给用户推荐和他之前喜欢的物品相似的物品
我们主要介绍这两种协同过滤算法
2 基于用户的协同过滤
基于用户的协同过滤算法(UserCF):当一个用户A需要个性化推荐的时候, 我们可以先找到和他有相似兴趣的其他用户, 然后把那些用户喜欢的, 而用户A不知道的物品推荐给A。以用户是否购买为例(这个比较好理解)
-
给用户 A找到最相似的N个用户
-
N个用户消费过用品中评分较高的
-
N个用户消费过的产品中- A用户消费过的就是推荐结果
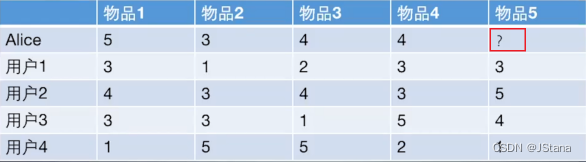
借用一个具体的评分案例(评分案例更有普适性)来做算法具体实现。这边的案例 我们使用大佬博客中。以后的案例借用我也会说出处的:
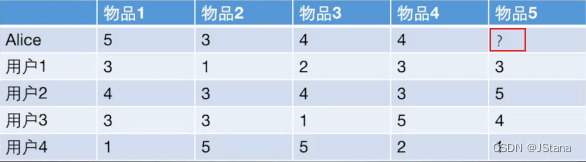
给用户推荐物品的过程可以形象化为一个猜测用户对商品进行打分的任务。
上面表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度(比如用户购买, 那直接量化为5分; 收藏:4分;看某个物品很久:3分等)
通过这样的量化就相当于把每个用户对物品的行为刻画成了向量的形式, 我们就可以计算相似程度了
任务是判断到底该不该把物品5推荐给用户Alice。
针对于评分案例的处理:
-
根据已有的用户打分情况计算Alice和其他用户的相似性,找出最相似的N个用户
-
根据相似最高的N个用户相似性及对物品5的评分情况,估计Alice对物品5的评分,以此决定是否推荐
显然 首先要找到相似用户(计算用户间的相似性)
2.1 相似性计算
相似度有不同类型的计算方式,下面我介绍几种常用的,详情参考
2.1.1 欧氏距离
是一个欧式空间下度量距离的方法. 两个物体, 都在同一个空间下表示为两个点, 假如叫做p,q, 分别都是n个坐标, 那么欧式距离就是衡量这两个点之间的距离. 欧氏距离不适用于布尔向量之间
E
(
p
,
q
)
=
∑
i
=
1
n
(
p
i
−
q
i
)
2
E(p,q) = \sqrt{\sum_{i=1}^n (p_i - q_i)^2}
E(p,q)=i=1∑n(pi−qi)2
欧氏距离的值是一个非负数, 最大值正无穷, 通常计算相似度的结果希望是[-1,1]或[0,1]之间,一般可以使用转换公式
1
1
+
E
(
p
,
q
)
\frac{1}{1+E(p,q)}
1+E(p,q)1
2.1.2 余弦相似度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BkFWmfth-1669213716676)(pics/image-20221123215155285.png)]](https://img-blog.csdnimg.cn/6fc0f4d0923c4e7ebfa346a4a507c94d.png)
-
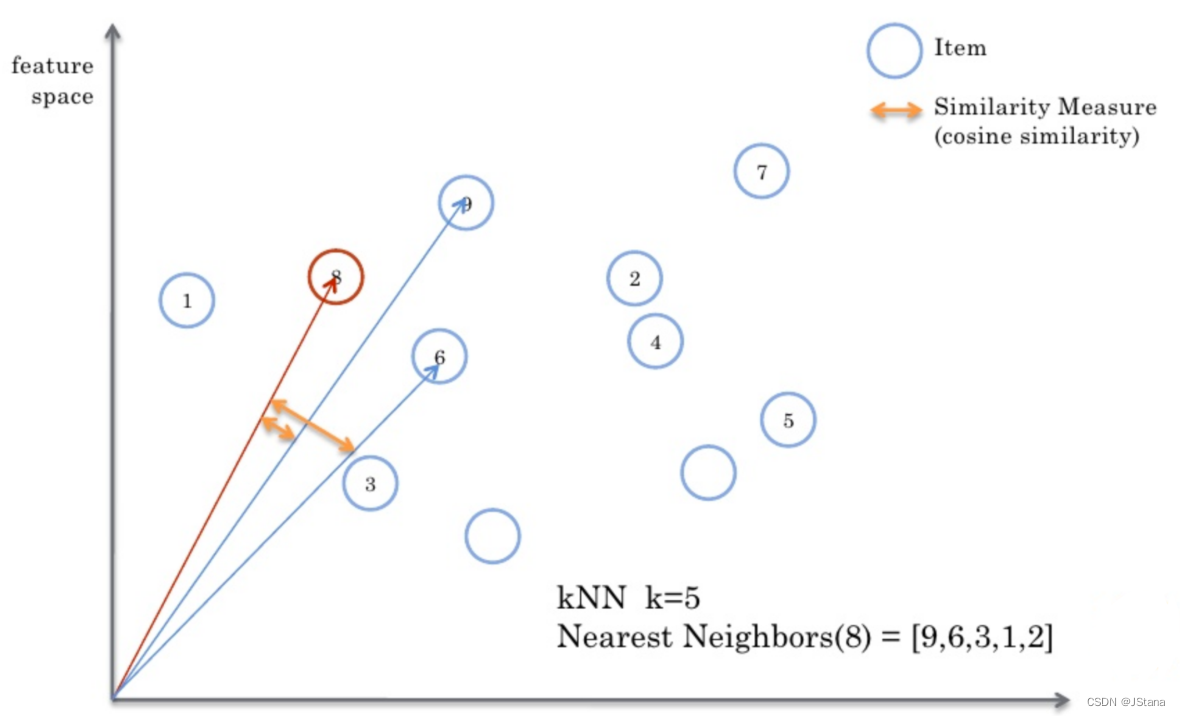
度量的是两个向量之间的夹角, 用夹角的余弦值来度量相似的情况
-
两个向量的夹角为0是,余弦值为1, 当夹角为90度是余弦值为0,为180度是余弦值为-1
-
余弦相似度在度量文本相似度, 用户相似度 物品相似度的时候较为常用
-
余弦相似度的特点, 与向量长度无关,余弦相似度计算要对向量长度归一化, 两个向量只要方向一致,无论程度强弱, 都可以视为’相似’
实现,这里就直接使用 sklearn了
sklearn.metrics.pairwise 包
官方文档
-
cosine_similarity()
传入一个变量a时,返回数组的第i行第j列表示a[i]与a[j]的余弦相似度。 -
pairwise_distances(metric)
该方法返回的是距离,默认欧式距离。返回值 i行 j列 表示 a[i] 与 a[j]的相似距离。metric:更多见 官方文档
’cosine‘ :余弦距离
‘manhattan’:曼哈顿距离
‘jaccard’ :杰卡德
相似度= 1 - 距离
a = [[1, 3, 2], [2, 2, 1]]
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.metrics.pairwise import pairwise_distances
print('sim2:', cosine_similarity(a))
print('sim3:', pairwise_distances(a,metric="cosine"))
#output
sim1: 0.8908708063747479
sim2: [[1. 0.89087081]
[0.89087081 1. ]]
sim3: [[0. 0.10912919]
[0.10912919 0. ]]
2.1.3 皮尔逊相关系数Pearson


-
实际上也是一种余弦相似度, 不过先对向量做了中心化, 向量a b 各自减去向量的均值后, 再计算余弦相似度
-
皮尔逊相似度计算结果在-1,1之间 -1表示负相关, 1表示正相关
-
度量两个变量是不是同增同减
-
皮尔逊相关系数度量的是两个变量的变化趋势是否一致, 不适合计算布尔值向量之间的相关度
##1
df.corr()
##2
from scipy.stats import pearsonr
i = [1, 0, 0, 0]
j = [1, 0.5, 0.5, 0]
pearsonr(i, j)
2.1.4 杰卡德相似度 Jaccard
-
两个集合的交集元素个数在并集中所占的比例, 非常适用于布尔向量表示
-
分子是两个布尔向量做点积计算, 得到的就是交集元素的个数
-
分母是两个布尔向量做或运算, 再求元素和
-
余弦相似度适合用户评分数据(实数值), 杰卡德相似度适用于隐式反馈数据(0,1布尔值)(是否收藏,是否点击,是否加购物车)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pjg8M4Ev-1669213716677)(pics/similarity_calc2-166729115870910.png)]](https://img-blog.csdnimg.cn/8709ca2561e6404e961f2da06f7120dc.png)
实现
#构建数据集
users = ["User1", "User2", "User3", "User4", "User5"]
items = ["Item A", "Item B", "Item C", "Item D", "Item E"]
# 用户购买记录数据集
datasets = [
[1,0,1,1,0],
[1,0,0,1,1],
[1,0,1,0,0],
[0,1,0,1,1],
[1,1,1,0,1],
]
import pandas as pd
df = pd.DataFrame(datasets,
columns=items,
index=users)
print(df)
Item A Item B Item C Item D Item E
User1 1 0 1 1 0
User2 1 0 0 1 1
User3 1 0 1 0 0
User4 0 1 0 1 1
User5 1 1 1 0 1
# 相似度计算 这里显然是布尔型值 选择用杰卡德计算
from sklearn.metrics import jaccard_score
# 计算User1 User2的相似度
jaccard_score(df.loc["User1"],df.loc["User2"])#0.5
# 计算Item A 和Item B的相似度就使用列数据
# 计算所有的数据两两的杰卡德相似系数
from sklearn.metrics.pairwise import pairwise_distances
## 计算用户间相似度
## 返回的是距离 返回值 i行 j列 表示 a[i] 与 a[j]的相似距离
## 相似度 = 1- 距离
pairwise_distances(df.values,metric='jaccard')
output:
array([[0. , 0.5 , 0.33333333, 0.8 , 0.6 ],
[0.5 , 0. , 0.75 , 0.5 , 0.6 ],
[0.33333333, 0.75 , 0. , 1. , 0.5 ],
[0.8 , 0.5 , 1. , 0. , 0.6 ],
[0.6 , 0.6 , 0.5 , 0.6 , 0. ]])
小结:
欧式距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异
余弦相似度、皮尔逊相关系数: 适用于评分数据是连续的
杰卡德相似度:适用于评分是0 1 的布尔值
具体看实际需求决定,例子
如果要统计两部剧的用户观看行为,用户A的观看向量(0,1), 用户B为(1,0), 此时二者的余弦距离很大,而欧式距离很小。我们分析两个用户对于不同视频的偏好,更关注相对差异,显然应当用余弦距离。
而当我们分析用户活跃度,以登录次数和平均观看时长作为特征时, 余弦距离会认为(1,10)和(10,100)两个用户距离很近,但显然这两个用户活跃度是有着极大差异的。此时我们关注的是数值绝对差异,应当使用欧式距离。
2.2 结果分数
计算出Alice和其他用户的相近程度, 这时候我们就可以选出与Alice最相近的前n个用户, 基于他们对物品5的评价猜测出Alice的打分值。其中计算分数的方式:
- 用户相似度和相似用户的评价加权平均获得用户的评价预测
R u , p = ∑ s ∈ S ( w u , s ) ⋅ R s , p ∑ s ∈ S w u , s R_{u,p} = \frac{\sum_{s \in S}(w_{u,s})\cdot R_{s,p}}{\sum_{s\in S}w_{u,s}} Ru,p=∑s∈Swu,s∑s∈S(wu,s)⋅Rs,p
权重 w u , s w_{u,s} wu,s 是用户u和用s 的相似度, R s , p R_{s,p} Rs,p是用户s对物品p的评分
-
该物品的评分与此用户的所有评分的差值进行加权平均
这种方式考虑到用户评分标准不一的情况(有人就是喜欢打低分,有人就是喜欢打高分)
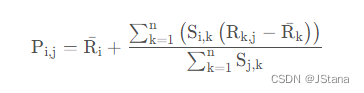
S j , k S_{j,k} Sj,k 表示用户j,k的相似度 同 w u , s w_{u,s} wu,s
实现,看这个例子 直接copy 大佬的代码了 主要不想写数据
![(img-AyuxnTau-1669213716678)(pics/20200820100833678.png)]](https://img-blog.csdnimg.cn/8a2b9fd322524390861647826dbef41a.png)

# 0 定义数据集, 也就是那个表格, 注意这里我们采用字典存放数据, 因为实际情况中数据是非常稀疏的, 很少有情况是现在这样
def loadData():
items={'A': {1: 5, 2: 3, 3: 4, 4: 3, 5: 1},
'B': {1: 3, 2: 1, 3: 3, 4: 3, 5: 5},
'C': {1: 4, 2: 2, 3: 4, 4: 1, 5: 5},
'D': {1: 4, 2: 3, 3: 3, 4: 5, 5: 2},
'E': {2: 3, 3: 5, 4: 4, 5: 1}
}
users={1: {'A': 5, 'B': 3, 'C': 4, 'D': 4},
2: {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
3: {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
4: {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
5: {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
}
return items,users
items, users = loadData()
item_df = pd.DataFrame(items).T
user_df = pd.DataFrame(users).T
"""1.计算用户相似性矩阵"""
similarity_matrix = pd.DataFrame(np.zeros((len(users), len(users))), index=[1, 2, 3, 4, 5], columns=[1, 2, 3, 4, 5])
# 遍历每条用户-物品评分数据
for userID in users:
for otheruserId in users:
vec_user = []
vec_otheruser = []
if userID != otheruserId:
for itemId in items: # 遍历物品-用户评分数据
itemRatings = items[itemId] # 这也是个字典 每条数据为所有用户对当前物品的评分
if userID in itemRatings and otheruserId in itemRatings: # 说明两个用户都对该物品评过分
vec_user.append(itemRatings[userID])
vec_otheruser.append(itemRatings[otheruserId])
# 这里可以获得相似性矩阵(共现矩阵)
similarity_matrix[userID][otheruserId] = np.corrcoef(np.array(vec_user), np.array(vec_otheruser))[0][1]
#similarity_matrix[userID][otheruserId] = cosine_similarity(np.array(vec_user), np.array(vec_otheruser))[0][1]
"""2 计算前n个相似的用户"""
n = 2
similarity_users = similarity_matrix[1].sort_values(ascending=False)[:n].index.tolist() # [2, 3] 也就是用户1和用户2
"""3 计算最终得分"""
base_score = np.mean(np.array([value for value in users[1].values()]))
weighted_scores = 0.
corr_values_sum = 0.
for user in similarity_users: # [2, 3]
corr_value = similarity_matrix[1][user] # 两个用户之间的相似性
mean_user_score = np.mean(np.array([value for value in users[user].values()])) # 每个用户的打分平均值
weighted_scores += corr_value * (users[user]['E']-mean_user_score) # 加权分数
corr_values_sum += corr_value
final_scores = base_score + weighted_scores / corr_values_sum
print('用户Alice对物品5的打分: ', final_scores)
user_df.loc[1]['E'] = final_scores
user_df
2.3 优缺点分析
- 数据稀疏性。比如淘宝中商品太多,但是用户只会购买其中的很小一部分。相似用户寻找困难
- 不适用大用户数据量。用户量大,维护用户相似矩阵开销较大
3 基于物品的协同过滤
基于物品的协同过滤(ItemCF):根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品类似的物品推荐给用户。比如物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A
注意:
这里的物品相似性并不根据物品本身属性(类型,价格等)决定 而是因为有很多人喜欢A的同时喜欢C,这仍然是基于用户行为的
3.1 结果分数

"""1.得到与物品5相似的前n个物品"""
n = 2
similarity_items = similarity_matrix['E'].sort_values(ascending=False)[:n].index.tolist() # ['A', 'D']
"""计算最终得分"""
base_score = np.mean(np.array([value for value in items['E'].values()]))
weighted_scores = 0.
corr_values_sum = 0.
for item in similarity_items: # ['A', 'D']
corr_value = similarity_matrix['E'][item] # 两个物品之间的相似性
mean_item_score = np.mean(np.array([value for value in items[item].values()])) # 每个物品的打分平均值
weighted_scores += corr_value * (users[1][item]-mean_item_score) # 加权分数
corr_values_sum += corr_value
final_scores = base_score + weighted_scores / corr_values_sum
print('用户Alice对物品5的打分: ', final_scores)
user_df.loc[1]['E'] = final_scores
user_df
3.2 优缺点分析
ItemCF算法可以预先在线下计算好不同物品之间的相似度,把结果存在表中,当推荐时进行查表,计算用户可能的打分值,可以同时解决上面两个问题。
其余的优势感觉在大数据的当下也不明显
更多见第四节
4 总结

4.1 应用场景
-
UserCF
由于是基于用户相似度进行推荐, 所以具备更强的社交特性, 这样的特点非常适于用户少, 物品多, 时效性较强的场合, 比如新闻推荐场景
-
ItemCF
适用于兴趣变化较为稳定的应用, 更接近于个性化的推荐, 适合物品少,用户多,用户兴趣固定持久, 物品更新速度不是太快的场合, 比如推荐艺术品, 音乐, 电影

4.2 问题分析
- UserCF;ItemCF 都没有考虑物品本身的属性(最大的问题)
- 稀疏数据的处理能力弱,泛化性差:热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐

A, B, C, D是物品, 看右边的物品共现矩阵, 可以发现物品D与A、B、C的相似度比较大, 所以很有可能将D推荐给用过A、B、C的用户。 但是物品D与其他物品相似的原因是因为D是一件热门商品, 系统无法找出A、B、C之间相似性的原因是其特征太稀疏, 缺乏相似性计算的直接数据。 所以这就是协同过滤的天然缺陷:推荐系统头部效应明显, 处理稀疏向量的能力弱。
解决办法:(下一章的矩阵分解)
补充:推荐算法评价指标

参考
王喆老师:《深度学习推荐系统》
AI上推荐 之 协同过滤_翻滚的小@强