🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
数据
任务
Models
特征
模型评估
在深入研究特征工程之前,让我们花点时间看一下整个机器学习管道。这将帮助我们了解应用程序的大局。为此,我们将从对数据和模型等基本概念进行一些思考开始。
数据
我们所说的数据 是对现实世界现象的观察。例如,股票市场数据可能涉及对每日股票价格的观察、个别公司的收益公告,甚至专家的意见文章。个人生物识别数据可以包括我们每分钟的心率、血糖水平、血压等的测量值。客户智能数据包括观察结果,例如“爱丽丝星期天买了两本书”、“鲍勃在网站上浏览了这些页面, ”和“查理点击了上周的特别优惠链接。” 我们可以想出无数跨不同领域的数据示例。
每条数据都为了解现实的有限方面提供了一个小窗口。所有这些观察结果的集合为我们提供了整体图景。但是图片很乱,因为它是由上千个小块组成的,而且总是有测量噪声和丢失的小块。
任务
我们为什么收集数据?有数据可以解答的问题帮助我们回答诸如“我应该投资哪些股票?”之类的问题 或“我怎样才能过上更健康的生活方式?” 或者“我怎样才能了解客户不断变化的口味,以便我的企业可以更好地为他们服务?”
从数据到答案的路径充满了错误的开始和死胡同(见图 1-1). 一开始看起来很有前途的方法可能不会成功。最初只是一种预感可能最终会导致最佳解决方案。包含数据的工作流通常是多阶段的迭代过程。例如,股票价格是在交易所观察到的,由像汤森路透这样的中介机构汇总,存储在数据库中,由公司购买,转换为 Hadoop 集群上的 Hive 存储,通过脚本从存储中提取,二次抽样,由另一个脚本处理和清理,转储到一个文件,并转换为您可以在您最喜欢的 R、Python 或 Scala 建模库中试用的格式。然后将预测转储回 CSV 文件并由评估者解析,模型被多次迭代,由您的生产团队用 C++ 或 Java 重写,

图 1-1。数据和答案之间的分叉路径花园
然而,如果我们暂时忽略工具和系统的混乱,我们可能会看到这个过程涉及两个数学实体,它们是机器学习的基础:模型和特征。
Models
试图通过数据来理解世界就像试图用一个嘈杂的、不完整的拼图游戏和一堆额外的碎片来拼凑现实。这是数学的地方建模——在特定的统计模型——进来了。统计语言包含许多常见的数据特征的概念,例如错误的、冗余的或缺失的。错误的数据是结果的测量错误。冗余数据包含传达完全相同信息的多个方面。例如,星期几可能作为分类变量出现,其值为“星期一”、“星期二”、...“星期日”,并再次作为 0 到 6 之间的整数值包含在内。如果某些数据点不存在该星期几信息,那么您手头的数据就丢失了。
数据的数学模型描述了数据不同方面之间的关系。例如,预测股票价格的模型可能是一个将公司的盈利历史、过去的股票价格和行业映射到预测股票价格的公式。推荐音乐的模型可能会衡量用户之间的相似性(基于他们的收听习惯),并向听过很多相同歌曲的用户推荐相同的艺术家。
数学公式将数值量相互联系起来。但原始数据通常不是数字。(“爱丽丝在星期三购买了指环王三部曲”这个动作不是数字,她随后写的关于这本书的评论也不是数字。)必须有一个片段将两者联系在一起。这就是功能发挥作用的地方。
特征
特征是原始数据的数字表示。有很多方法可以将原始数据转化为数字测量值,这就是为什么特征最终看起来像很多东西的原因。自然地,特征必须源自可用的数据类型。也许不太明显的是它们也与模型相关联;有些模型更适合某些类型的特征,反之亦然。正确的特征与手头的任务相关,并且应该易于模型摄取。特征工程是在给定数据、模型和任务的情况下制定最合适的特征的过程。
特征的数量也很重要。如果没有足够的信息特征,那么模型将无法完成最终的任务。如果特征太多,或者其中大部分不相关,那么模型的训练成本会更高,也更难训练。在影响模型性能的训练过程中可能会出现某些问题。
模型评估
特点和型号介于原始数据和所需的见解之间(见图 1-2)。在机器学习工作流程中,我们不仅选择模型,还选择特征。这是一个双关节杠杆,一个的选择会影响另一个。 良好的特征使后续的建模步骤变得容易,并且生成的模型更能够完成所需的任务。不良特征可能需要更复杂的模型才能达到相同的性能水平。在本书的其余部分,我们将介绍不同类型的特征,并讨论它们对不同类型的数据和模型的优缺点。事不宜迟,让我们开始吧!
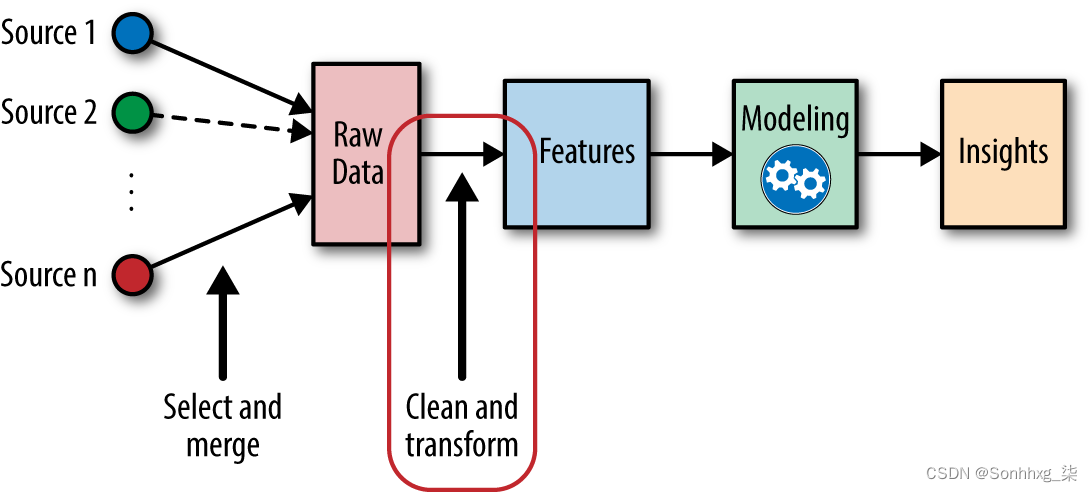
图 1-2。特征工程在机器学习工作流程中的位置