- 前言
- 一些关键字定义及理解
- 计算量 FLOPs
- 内存访问代价 MAC
- GPU 内存带宽
- Latency and Throughput
- 英伟达 GPU 架构
- CNN 架构的理解
- 手动设计高效 CNN 架构建议
- 一些结论:
- 一些建议
- 轻量级网络模型部署总结
- 轻量级网络论文解析文章
- 参考资料
文章同步发于 github 仓库 和 知乎,最新板以
github为主。
本人水平有限,文章如有问题,欢迎及时指出。如果看完文章有所收获,一定要先点赞后收藏。毕竟,赠人玫瑰,手有余香。
前言
关于如何手动设计轻量级网络的研究,目前还没有广泛通用的准则,,只有一些指导思想,和针对不同芯片平台(不同芯片架构)的一些设计总结,建议大家从经典论文中吸取指导思想和建议,然后自己实际做各个硬件平台的部署和模型性能测试。
一些关键字定义及理解
FLOPs和MAC的计算方式,请参考我之前写的文章 神经网络模型复杂度分析。
计算量 FLOPs
FLOPs:floating point operations指的是浮点运算次数,理解为计算量,可以用来衡量算法/模型时间的复杂度。FLOPS:(全部大写),Floating-point Operations Per Second,每秒所执行的浮点运算次数,理解为计算速度, 是一个衡量硬件性能/模型速度的指标,即一个芯片的算力。MACCs:multiply-accumulate operations,乘-加操作次数,MACCs大约是FLOPs的一半。将 w[0]∗x[0]+… 视为一个乘法累加或1个MACC。
内存访问代价 MAC
MAC: Memory Access Cost 内存访问代价。指的是输入单个样本(一张图像),模型/卷积层完成一次前向传播所发生的内存交换总量,即模型的空间复杂度,单位是 Byte。
GPU 内存带宽
GPU的内存带宽决定了它将数据从内存 (vRAM) 移动到计算核心的速度,是比GPU内存速度更具代表性的指标。GPU的内存带宽的值取决于内存和计算核心之间的数据传输速度,以及这两个部分之间总线中单独并行链路的数量。
NVIDIA RTX A4000 建立在 NVIDIA Ampere 架构之上,其芯片规格如下所示:

A4000 芯片配备 16 GB 的 GDDR6 显存、256 位显存接口(GPU 和 VRAM 之间总线上的独立链路数量),因为这些与显存相关的特性,所以 A4000 内存带宽可以达到 448 GB/s。
Latency and Throughput
参考英伟达-Ashu RegeDirector of Developer Technology 的
ppt文档 An Introduction to Modern GPU Architecture。
深度学习领域延迟 Latency 和吞吐量 Throughput的一般解释:
- 延迟 (
Latency): 人和机器做决策或采取行动时都需要反应时间。延迟是指提出请求与收到反应之间经过的时间。大部分人性化软件系统(不只是 AI 系统),延迟都是以毫秒来计量的。 - 吞吐量 (
Throughput): 在给定创建或部署的深度学习网络规模的情况下,可以传递多少推断结果。简单理解就是在一个时间单元(如:一秒)内网络能处理的最大输入样例数。
CPU 是低延迟低吞吐量处理器;GPU 是高延迟高吞吐量处理器。
英伟达 GPU 架构
GPU 设计了更多的晶体管(transistors)用于数据处理(data process)而不是数据缓冲(data caching)和流控(flow control),因此 GPU 很适合做高度并行计算(highly parallel computations)。同时,GPU 提供比 CPU 更高的指令吞吐量和内存带宽(instruction throughput and memory bandwidth)。
CPU 和 GPU 的直观对比图如下所示
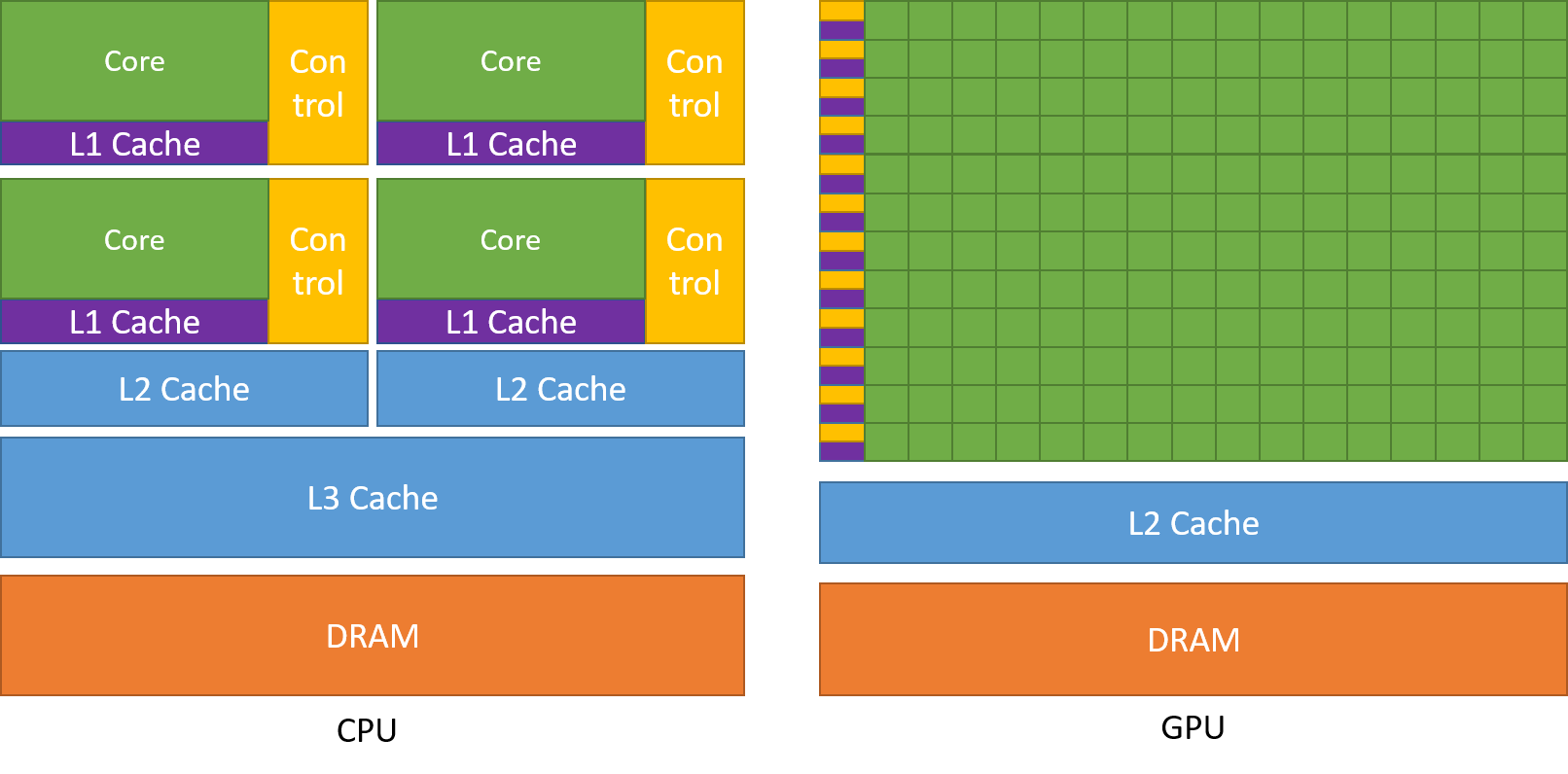
图片来源 CUDA C++ Programming Guide
最后简单总结下英伟达 GPU 架构的一些特点:
SIMT(Single Instruction Multiple Threads) 模式,即多个Core同一时刻只能执行同样的指令。虽然看起来与现代CPU的SIMD(单指令多数据)有些相似,但实际上有着根本差别。- 更适合计算密集与数据并行的程序,原因是缺少
Cache和Control。
2008-2020 英伟达 GPU 架构进化史如下图所示:
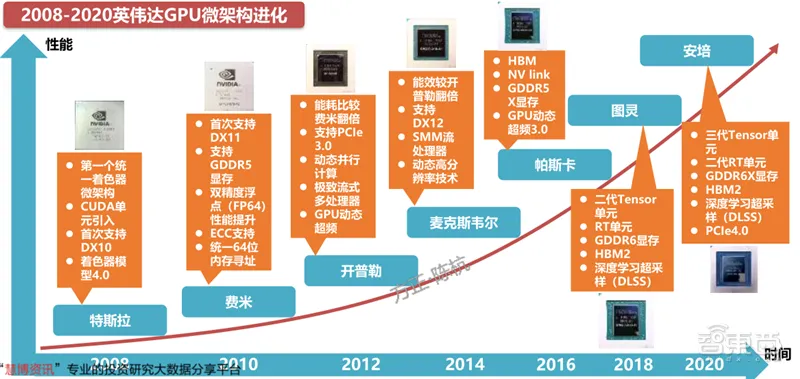
另外,英伟达 GPU 架构从 2010 年开始到 2020 年这十年间的架构演进历史概述,可以参考知乎的文章-英伟达GPU架构演进近十年,从费米到安培。
GPU 架构的深入理解可以参考博客园的文章-深入GPU硬件架构及运行机制。
CNN 架构的理解
在一定的程度上,网络越深越宽,性能越好。宽度,即通道(channel)的数量,网络深度,及 layer 的层数,如 resnet18 有 18 层网络。注意我们这里说的和宽度学习一类的模型没有关系,而是特指深度卷积神经网络的(通道)宽度。
- 网络深度的意义:
CNN的网络层能够对输入图像数据进行逐层抽象,比如第一层学习到了图像边缘特征,第二层学习到了简单形状特征,第三层学习到了目标形状的特征,网络深度增加也提高了模型的抽象能力。 - 网络宽度的意义:网络的宽度(通道数)代表了滤波器(
3维)的数量,滤波器越多,对目标特征的提取能力越强,即让每一层网络学习到更加丰富的特征,比如不同方向、不同频率的纹理特征等。
手动设计高效 CNN 架构建议
一些结论:
- 分析模型的推理性能得结合具体的推理平台(常见如:英伟达
GPU、移动端ARMCPU、端侧NPU芯片等);目前已知影响CNN模型推理性能的因素包括: 算子计算量FLOPs(参数量Params)、卷积block的内存访问代价(访存带宽)、网络并行度等。但相同硬件平台、相同网络架构条件下,FLOPs加速比与推理时间加速比成正比。 - 建议对于轻量级网络设计应该考虑直接
metric(例如速度speed),而不是间接metric(例如FLOPs)。 FLOPs低不等于latency低,尤其是在有加速功能的硬体 (GPU、DSP与TPU)上不成立,得结合具硬件架构具体分析。- 不同网络架构的
CNN模型,即使是FLOPs相同,但其MAC也可能差异巨大。 - 大部分时候,对于
GPU芯片,Depthwise卷积算子实际上是使用了大量的低FLOPs、高数据读写量的操作。这些具有高数据读写量的操作,加上多数时候GPU芯片算力的瓶颈在于访存带宽,使得模型把大量的时间浪费在了从显存中读写数据上,导致GPU的算力没有得到“充分利用”。结论来源知乎文章-FLOPs与模型推理速度。
一些建议
- 在大多数的硬件上,
channel数为16的倍数比较有利高效计算。如海思351x系列芯片,当输入通道为4倍数和输出通道数为16倍数时,时间加速比会近似等于FLOPs加速比,有利于提供NNIE硬件计算利用率。 - 低
channel数的情况下 (如网路的前几层),在有加速功能的硬件使用普通convolution通常会比separable convolution有效率。(来源 MobileDets 论文) - shufflenetv2 论文 提出的四个高效网络设计的实用指导思想: G1同样大小的通道数可以最小化
MAC、G2-分组数太多的卷积会增加MAC、G3-网络碎片化会降低并行度、G4-逐元素的操作不可忽视。 GPU芯片上 3 × 3 3\times 3 3×3 卷积非常快,其计算密度(理论运算量除以所用时间)可达 1 × 1 1\times 1 1×1 和 5 × 5 5\times 5 5×5 卷积的四倍。(来源 RepVGG 论文)- 从解决梯度信息冗余问题入手,提高模型推理效率。比如 CSPNet 网络。
- 从解决
DenseNet的密集连接带来的高内存访问成本和能耗问题入手,如 VoVNet 网络,其由OSA(One-Shot Aggregation,一次聚合)模块组成。
轻量级网络模型部署总结
在阅读和理解经典的轻量级网络 mobilenet 系列、MobileDets、shufflenet 系列、cspnet、vovnet、repvgg 等论文的基础上,做了以下总结:
- 低算力设备-手机移动端
cpu硬件,考虑mobilenetv1(深度可分离卷机架构-低FLOPs)、低FLOPs和 低MAC的shuffletnetv2(channel_shuffle算子在推理框架上可能不支持) - 专用
asic硬件设备-npu芯片(地平线x3/x4等、海思3519、安霸cv22等),目标检测问题考虑cspnet网络(减少重复梯度信息)、repvgg(直连架构-部署简单,网络并行度高有利于发挥GPU算力,量化后有掉点风险) - 英伟达
gpu硬件-t4芯片,考虑repvgg网络(类vgg卷积架构-高并行度带来高速度、单路架构省显存/内存)
MobileNet block (深度可分离卷积 block, depthwise separable convolution block)在有加速功能的硬件(专用硬件设计-NPU 芯片)上比较没有效率。
这个结论在 CSPNet 和 MobileDets 论文中都有提到。
除非芯片厂商做了定制优化来提高深度可分离卷积 block 的计算效率,比如地平线机器人 x3 芯片对深度可分离卷积 block 做了定制优化。
下表是 MobileNetv2 和 ResNet50 在一些常见 NPU 芯片平台上做的性能测试结果。
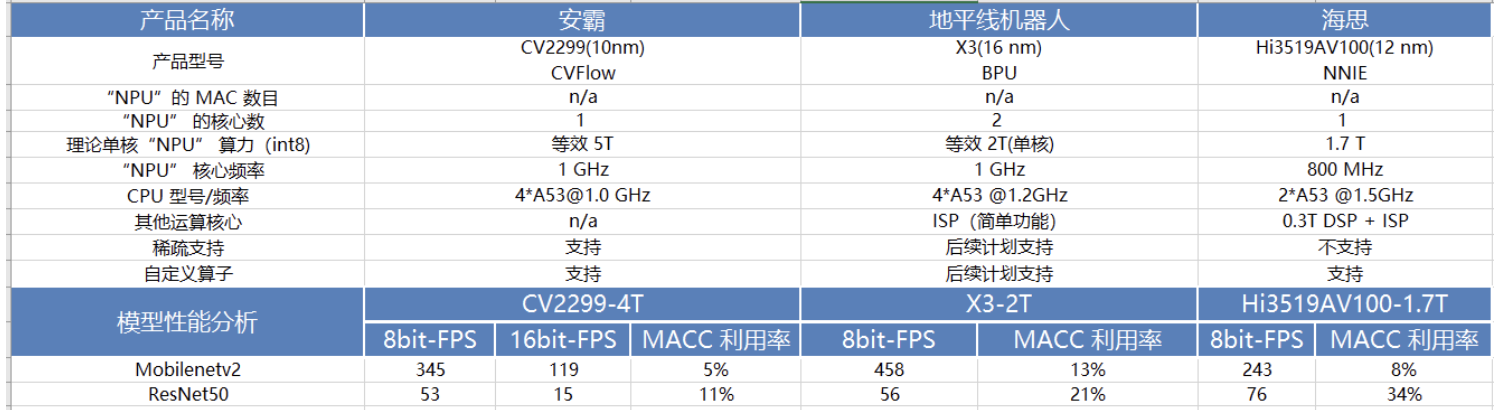
以上,均是看了轻量级网络论文总结出来的一些不同硬件平台部署轻量级模型的经验,实际结果还需要自己手动运行测试。
轻量级网络论文解析文章汇总
- MobileNetv1论文详解
- ShuffleNetv2论文详解
- RepVGG论文详解
- CSPNet论文详解
- VoVNet论文解读
参考资料
- An Introduction to Modern GPU Architecture
- 轻量级网络论文解析合集