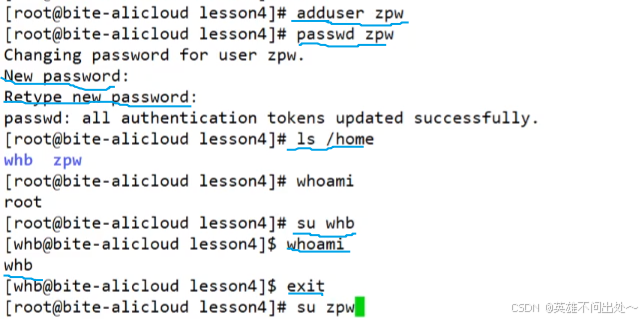
第7集:聚类算法——发现数据中的隐藏模式
在机器学习中,聚类(Clustering) 是一种无监督学习方法,用于发现数据中的隐藏模式或分组。与分类任务不同,聚类不需要标签,而是根据数据的相似性将其划分为不同的簇。今天我们将深入探讨 K-Means 聚类 的原理,并通过实践部分使用 顾客消费行为数据 进行分组。
K-Means 聚类的原理
什么是 K-Means?
K-Means 是一种基于距离的聚类算法,其目标是将数据划分为 K 个簇,使得每个样本点与其所属簇的中心(质心)的距离最小化。算法步骤如下:
- 随机选择 K 个初始质心。
- 将每个样本分配到最近的质心所在的簇。
- 更新质心为当前簇内所有样本的均值。
- 重复步骤 2 和 3,直到质心不再变化或达到最大迭代次数。
图1:K-Means 聚类过程
(图片描述:二维平面上展示了 K-Means 算法的迭代过程,初始随机质心逐渐调整位置,最终收敛到稳定状态。)

如何选择最佳的 K 值(肘部法则)
选择合适的 K 值是 K-Means 聚类的关键问题之一。常用的 肘部法则(Elbow Method) 通过绘制簇内误差平方和(SSE, Sum of Squared Errors)随 K$ 值的变化曲线来确定最佳 K 值。当 SSE 下降速度明显减缓时,对应的 K 值即为最佳值。
公式如下:
SSE
=
∑
i
=
1
K
∑
x
∈
C
i
∣
∣
x
−
μ
i
∣
∣
2
\text{SSE} = \sum_{i=1}^{K} \sum_{x \in C_i} ||x - \mu_i||^2
SSE=i=1∑Kx∈Ci∑∣∣x−μi∣∣2
其中:
C
i
是第
i
个簇。
C_i 是第 i 个簇。
Ci是第i个簇。
μ
i
是第
i
个簇的质心。
\mu_i 是第 i 个簇的质心。
μi是第i个簇的质心。
图2:肘部法则示意图
(图片描述:折线图展示了 SSE 随 K 值的变化,随着 K 增加,SSE 逐渐减小,但在某个 K 值后下降趋于平缓,形成“肘部”。图中 K = 3 时形成“肘部”。)

层次聚类与 DBSCAN 简介
1. 层次聚类
层次聚类是一种基于树形结构的聚类方法,分为两种类型:
- 凝聚式(Agglomerative):从单个样本开始,逐步合并最相似的簇。
- 分裂式(Divisive):从整个数据集开始,逐步分裂成更小的簇。
优点:无需指定 K 值;缺点:计算复杂度较高。
2. DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
DBSCAN 是一种基于密度的聚类算法,能够发现任意形状的簇,并对噪声点具有鲁棒性。其核心思想是:
- 核心点:在某半径范围内有足够多的邻居点。
- 边界点:在核心点的邻域内,但自身不是核心点。
- 噪声点:既不是核心点也不是边界点。
优点:无需指定 K 值;缺点:对参数敏感。
聚类结果的可视化
聚类结果通常通过散点图进行可视化,不同簇用不同颜色表示。对于高维数据,可以使用降维技术(如 PCA 或 t-SNE)将其投影到二维或三维空间。
实践部分:使用 K-Means 对顾客消费行为数据进行分组
数据集简介
我们使用一个模拟的顾客消费行为数据集,包含以下特征:
Annual Income:年收入(单位:千美元)。Spending Score:消费评分(范围 1-100,越高表示消费能力越强)。
目标是对顾客进行分组,以便制定个性化的营销策略。
完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 加载数据
url = "https://raw.githubusercontent.com/DennisKimt/datasets/main/Mall_Customers.csv"
data = pd.read_csv(url)
# 提取特征
X = data[['Annual Income (k$)', 'Spending Score (1-100)']]
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 使用肘部法则选择最佳 K 值
sse = []
K_range = range(1, 11)
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X_scaled)
sse.append(kmeans.inertia_)
# 绘制肘部法则图
plt.figure(figsize=(8, 5))
plt.plot(K_range, sse, marker='o')
plt.title('Elbow Method for Optimal K', fontsize=16)
plt.xlabel('Number of Clusters (K)', fontsize=12)
plt.ylabel('Sum of Squared Errors (SSE)', fontsize=12)
plt.grid()
plt.show()
# 选择 K=5 构建 K-Means 模型
kmeans = KMeans(n_clusters=5, random_state=42)
clusters = kmeans.fit_predict(X_scaled)
# 可视化聚类结果
plt.figure(figsize=(10, 6))
plt.scatter(X.iloc[:, 0], X.iloc[:, 1], c=clusters, cmap='viridis', s=100, edgecolor='k')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red', label='Centroids', marker='X')
plt.title('Customer Segmentation using K-Means', fontsize=16)
plt.xlabel('Annual Income (k$)', fontsize=12)
plt.ylabel('Spending Score (1-100)', fontsize=12)
plt.legend()
plt.show()
运行结果
肘部法则图
图3:肘部法则图
(图片描述:折线图展示了 SSE 随 $ K $ 值的变化,当 $ K=5 $ 时,曲线出现明显的“肘部”,表明这是最佳的簇数。)

聚类结果可视化
图4:K-Means 聚类结果
(图片描述:二维散点图展示了顾客的年收入与消费评分分布,不同簇用不同颜色表示,红色叉号标记了各簇的质心位置。)

总结
本文介绍了 K-Means 聚类的基本原理及其应用,并通过实践部分展示了如何使用 K-Means 对顾客消费行为数据进行分组。希望这篇文章能帮助你更好地理解聚类算法!
参考资料
- Scikit-learn 文档: https://scikit-learn.org/stable/documentation.html
- Mall Customers 数据集: https://github.com/stedy/Machine-Learning-with-R-datasets