一、字符集
1、查看mysql支持的所有字符集
show character set;

2、查看指定数据库的字符集
show variables like ‘character%’;
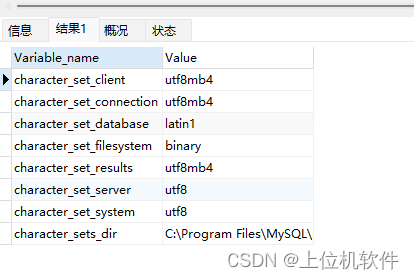
这八种情况分别对应:
1)设置客户端使用的字符集
2)设置链接数据库时的字符集
3)设置创建数据库的编码格式
4)文件系统的编码格式
5)数据库给客户端返回数据时的编码格式
6)服务器安装时指定的编码格式
7)数据库系统使用的编码格式
8)字符集的安装目录
3、查看某个表的字符集
语法如下:show table status from 库名 like 表名;
举例:
show table status from test_database like ‘test_table’;
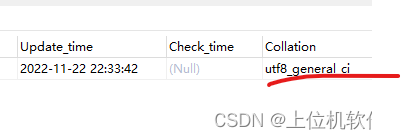
以上是查看test_database 数据库中test_table这个表的字符集,都是通过校对来判断出字符集的,这里的校对是utf8_general_ci,所以字符集是utf8。
4、查看某个表的所有列的字符集
show full columns from test_table;
查看test_table这个表所有列的字符集
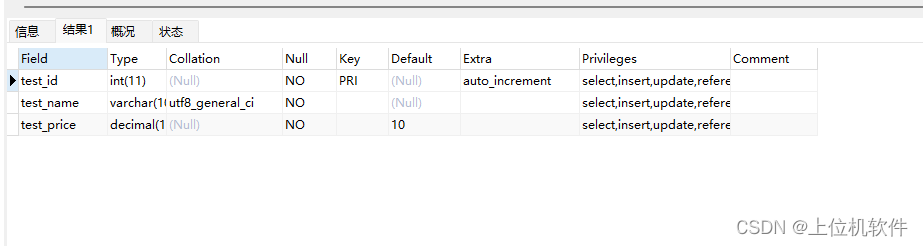
根据Collatio这一列,能判断出test_name这一列的校对是utf8_general_ci,所以字符集是utf8。,其他的test_id,test_price这两列没有指定校对,所以用的就是表的字符集。
5、创建表时指定字符集、校对
create table mytable
(
column1 int,
column2 int
)default CHARACTER set hebrew collate hebrew_general_ci;
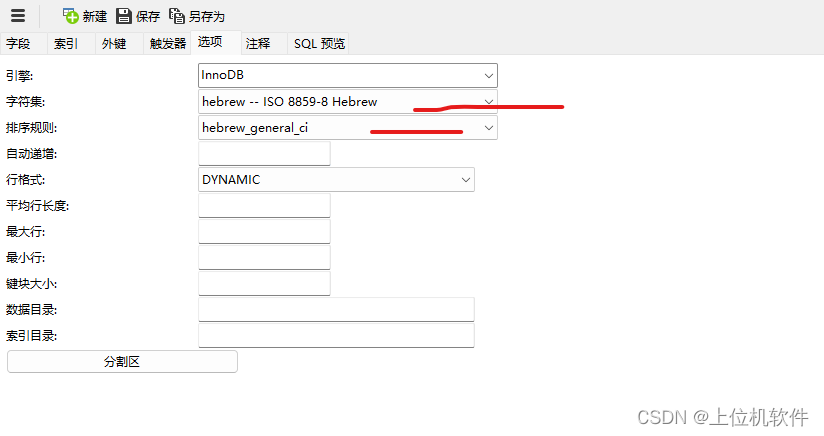
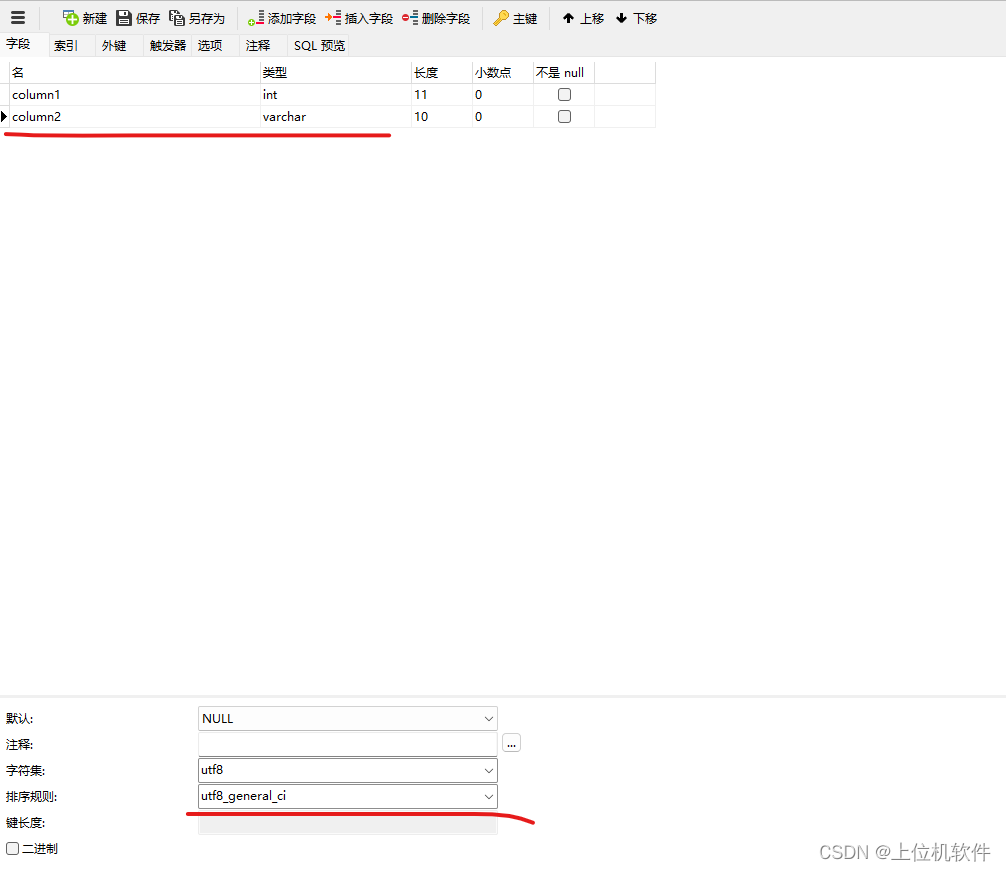
在Navicat的表设计表中可以看到该表的字符集和校对
6、创建表时指定列的字符集、校对
create table mytable
(
column1 int,
column2 varchar(10) character set utf8 collate utf8_general_ci
)default CHARACTER set hebrew collate hebrew_general_ci;
二、校对
1、查看mysql支持的所有校对
2、校对的几种常见情况
排序时指定校对规则
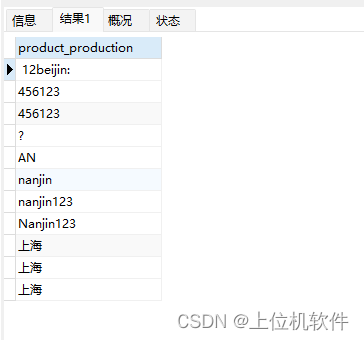
1)utf8_general_ci 不区分大小写,比较时对每个字符的unicode编码从左到右一个个的从小到大排序。
select product_production from product order by product_production collate utf8_general_ci;
2)utf8_bin 降序,且区分大小写
select product_production from product order by product_production collate utf8_bin;
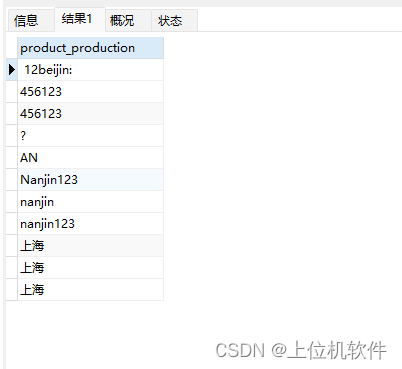
其中各个字符对应的unicode代码为:
空格=U+0020
4=U+0034
?=U+003F
A=U+0041
N=U+004E
n=U+006E
并且从上面可以看出N的unicode代码比n小,也就是大写字母的unicode代码比较小。
3)utf8_bin升序
select product_production from product order by product_production collate utf8_bin desc;

所以如果想指定某一列按照某种校对来排序的话,一方面可以通过更改列的校对(在数据库管理软件上更改,比如navicat更改),另一方面通过更改表的校对(在数据库管理软件上更改,比如navicat更改),这里要注意的是如果列的校对规则和表的校对规则不一致的情况下,列的校对规则是大于表的校对规则的;还可以临时的指定校对规则,就是在sql语句中指定校对。



![[附源码]java毕业设计学校缴费系统](https://img-blog.csdnimg.cn/24c5e7044deb4d0eb3e3c5d4709e254e.png)