Twins: Revisiting the Design of Spatial Attention in Vision Transformers
- 一、引言
- 二、Twins-PCPVT
- 三、Twins-SVT
- 四、实验
- 五、消融实验
文章链接: https://arxiv.org/abs/2104.13840
代码链接: https://github.com/Meituan-AutoML/Twins
一、引言
在本文中,重新审视了空间注意力的设计,并证明了精心设计但简单的空间注意力机制与最先进的方案相比表现良好。因此,本文提出了两种视觉转换器架构,即Twins PCPVT和TwinsVT。该架构高效且易于实现,仅涉及在现代深度学习框架中高度优化的矩阵乘法。更重要的是,所提出的体系结构在广泛的视觉任务(包括图像级分类以及密集检测和分割)上实现了优异的性能。
本文的第一个发现是,PVT中的全局子采样注意力是非常有效的,并且使用适用的位置编码,其性能可以与最先进的视觉Transformers(例如,Swin)相当甚至更好。本文第一个提出的架构,称为Twins PCPVT。除此之外,还提出了一种精心设计但简单的空间注意力机制,该架构比PVT更高效。本注意力机制受到广泛使用的可分离深度卷积的启发,因此将其命名为空间可分离自注意力(SSSA)。SSSA由两种类型的注意力操作组成——(i)局部分组的自注意力(LSA)和(ii)全局子采样注意力(GSA),其中LSA捕获细粒度和短距离信息,GSA处理长距离和全局信息。这种架构称为Twins SVT。该体系结构中的两种注意力操作都是高效的,并且易于在几行代码中通过矩阵乘法实现。
金字塔视觉Transformers(PVT),可以像在CNN中一样输出特征金字塔。PVT在许多密集预测任务中表现出良好的性能。最近的Swin Transformer引入了不重叠的窗口分区,并限制了每个局部窗口内的自注意力,导致输入令牌数量的线性计算复杂性。为了在不同的局部区域之间交换信息,其窗口分区特别设计为在两个相邻的自注意力层之间移动。语义分割框架OCNet也交织了局部和全局注意力。
分组和可分离卷积:分组卷积最初在AlexNet中提出,用于分布式计算。事实证明,它们在加快网络速度方面既高效又有效。作为一种极端情况,深度卷积使用等于输入或输出通道的组数,然后是逐点卷积,以聚集不同通道上的信息。在这里,本文提出的空间可分离的自注意与它们有一些相似之处。
位置编码:大多数视觉Transformers使用绝对/相对位置编码,这取决于基于正弦函数或可学习的下游任务。在CPVT中,作者提出了条件位置编码,其动态地取决于输入,并且表现出比绝对和相对编码更好的性能。
本文提供了两种简单而强大的空间设计。第一种方法建立在PVT和CPVT的基础上,仅使用全局注意力。因此,该架构被称为Twins PCPVT。第二种称为Twins SVT,基于所提出的SSSA,该SSSA交织了局部和全局注意力。
二、Twins-PCPVT

PVT的性能较差主要是由于PVT中使用的绝对位置编码。如CPVT中,绝对位置编码在处理具有不同大小的输入时遇到困难(这在密集预测任务中很常见)。此外,这种位置编码也打破了平移不变性。相反,SwinTransformers利用了相对位置编码,这绕过了上述问题。在这里,证明了这是Swin优于PVT的主要原因,如果使用适当的位置编码,PVT实际上可以实现与SwinTransformers相同或甚至更好的性能。
本文使用CPVT中提出的条件位置编码(CPE)来代替PVT中的绝对PE。CPE以输入为条件,自然可以避免绝对编码的问题。生成CPE的位置编码生成器(PEG)被放置在每个stage的第一编码器块之后。使用最简单的PEG形式,即无需批量归一化的2D深度卷积。对于图像级分类,在CPVT之后,删除了类标记,并在阶段结束时使用全局平均池(GAP)。对于其他视觉任务,遵循PVT的设计。Twins PCPVT继承了PVT和CPVT的优点,这使其易于高效实施。广泛的实验结果表明,这种简单的设计可以与最先进的SwinTransformers的性能相匹配。本文还尝试在Swin中用CPE替换相对的PE,然而,这并没有导致显著的性能提高。这可能是由于Swin中使用了移位窗口,这可能与CPE不兼容。
三、Twins-SVT
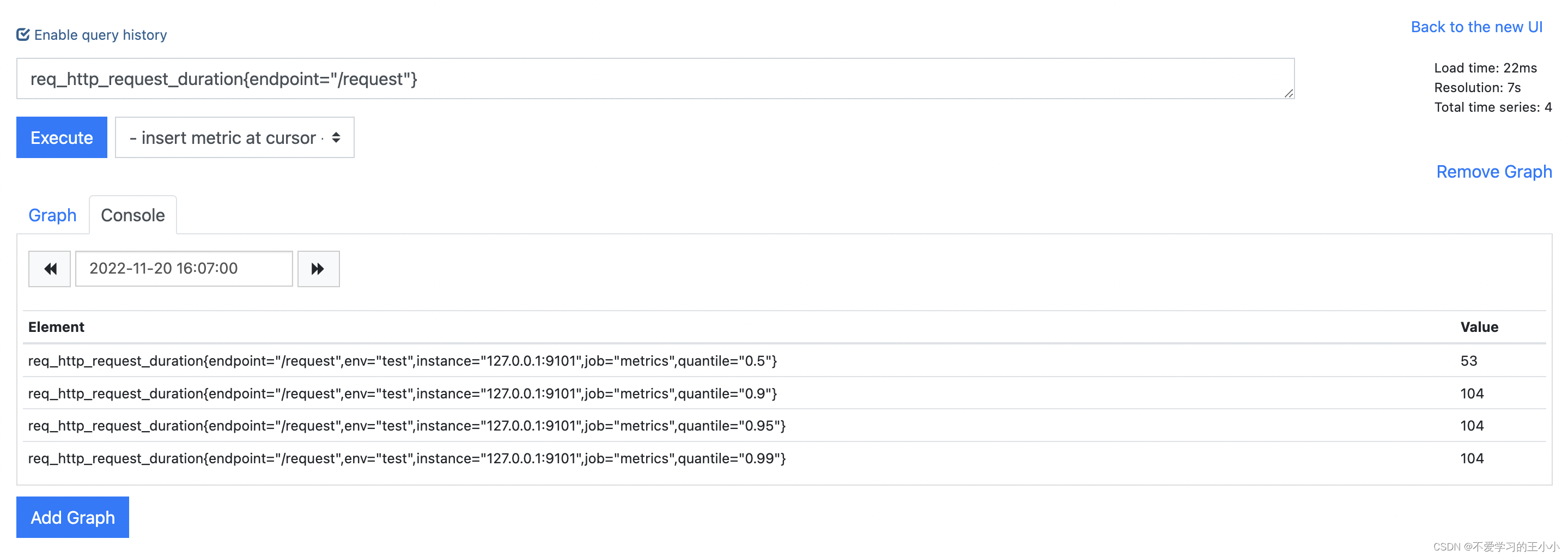
由于高分辨率的输入,视觉 Transformers在密集的预测任务中受到计算复杂性的影响。给定H×W分辨率的输入,维数为d的自注意力的复杂性为
O
(
H
2
W
2
d
O(H^2W^2d
O(H2W2d)。本文提出了空间可分离的自注意力(SSSA)来缓解这一挑战。SSSA由局部分组的自注意(LSA)和全局子采样注意(GSA)组成。
Locally-grouped self-attention (LSA):受深度卷积中的分组设计的影响,首先将2D特征图平均划分为子窗口,使自注意力通信仅发生在每个子窗口中。这种设计也与多头设计在自注意力方面产生了共鸣,其中通信仅发生在同一个头的通道内。具体而言,特征图被划分为m×n个子窗口。在不失一般性的情况下,我们假设
H
%
m
=
0
H\%m=0
H%m=0和
W
%
n
=
0
W\%n=0
W%n=0。每个组包含
H
W
/
m
n
HW/mn
HW/mn元素,因此,该窗口中的自注意力的计算成本为
O
(
H
2
W
2
m
2
n
2
d
)
O(\frac{H^2W^2}{m^2n^2d})
O(m2n2dH2W2),总成本为
O
(
H
2
W
2
m
n
d
)
O(\frac{H^2W^2}{mnd})
O(mndH2W2)。如果我们让
k
1
=
H
/
m
k_1=H/ m
k1=H/m,
k
2
=
W
/
n
k2=W/n
k2=W/n,成本可以计算为
O
(
k
1
k
2
H
W
d
)
O(k_1k_2HW d)
O(k1k2HWd),当
k
1
<
<
H
k1<<H
k1<<H和
k
2
<
<
W
k2<<W
k2<<W并且如果
k
1
k_1
k1和
k
2
k_2
k2固定,则与HW线性相关。
尽管局部分组的自注意力机制是计算友好的,但图像被划分为非重叠的子窗口。因此,需要一种机制来在不同的子窗口之间进行通信,如Swin。否则,信息将被限制在局部处理,这会使感受野变小,并显著降低性能,这类似于这样一个事实,即我们不能用CNN中的深度卷积代替所有标准卷积。

Global sub-sampled attention (GSA):一个简单的解决方案是在每个局部关注块之后添加额外的标准全局自注意力层,这可以实现跨组信息交换。然而,这种方法会带来
O
(
H
2
W
2
d
)
O(H^2W^2d)
O(H2W2d)的计算复杂性。这里,使用一个代表信息来总结每一个m×n个子窗口中每个子窗口的重要信息,并且该代表用于与其他子窗口进行通信(作为自注意力的关键),这可以显著降低成本,使
O
(
m
n
H
W
d
)
=
O
(
H
2
W
2
d
k
1
k
2
)
O(mnHW d)=O(\frac{H^2W^2d}{k_1k_2})
O(mnHWd)=O(k1k2H2W2d)。这基本上等同于在注意力操作中使用子采样特征图作为关键,因此将其称为全局子采样注意力(GSA)。如果我们可选地使用上述LSA和GSA类可分离卷积(深度方向+点方向),则总计算成本为
O
(
H
2
W
2
d
k
1
k
2
+
k
1
k
2
H
W
d
)
O(\frac{H^2W^2d}{k_1k_2}+k_1k_2HW d)
O(k1k2H2W2d+k1k2HWd)。在不失一般性的情况下,使用正方形子窗口,即
k
1
=
k
2
k_1=k_2
k1=k2。因此,
k
1
=
k
2
=
15
k_1=k_2=15
k1=k2=15接近于H=W=224的全局最小值。然而,我们的网络设计为包括具有可变分辨率的几个阶段。阶段1具有56×56的特征图,当
k
1
=
k
2
=
√
56
≈
7.
k_1=k_2=√56≈ 7.
k1=k2=√56≈7.理论上,可以为每个阶段校准最佳k1和k2。为了简单起见,我们处处使用k1=k2=7。对于分辨率较低的阶段,我们控制GSA的汇总窗口大小,以避免生成的密钥太少。具体来说,我们在最后三个阶段分别使用4、2和1的大小。
对于子采样函数,我们研究了几个选项,包括平均池化、深度跨步卷积和标准跨步卷积。经验结果表明,标准跨步卷积在这里表现最好。形式上,我们的空间可分离自我注意(SSSA)可以写成 :

其中LSA表示子窗口内局部分组的自注意力;GSA是通过与来自每个子窗口的代表键(由子采样函数生成)交互而获得的全局子采样注意力
z
i
j
^
∈
R
k
1
×
k
2
×
C
\hat{z_{ij}}∈ R^{k_1×k_2×C}
zij^∈Rk1×k2×C。LSA和GSA都有多个头部,正如标准的自注意力一样。LSA的PyTorch代码在算法1中给出(补充)。 同样,使用CPVT的PEG来编码位置信息并实时处理可变长度输入。它被插入到每个阶段的第一个块之后。
Model variants:Twins SVT的详细配置如下表所示。我们尽可能使用Swin中的类似设置,以确保良好的性能是由于新的设计范式。

四、实验

与ImageNet-1K分类的最先进方法进行比较。吞吐量在单个V100 GPU上以192的批量大小进行测试。所有模型均在ImageNet-1K数据集上以224×224分辨率进行训练和评估。†:w/CPVT的位置编码。

ADE20K验证数据集上不同主干的性能比较。FLOP以512×512分辨率进行测试。除了SETR之外,所有主干都在ImageNet-1k上预训练,SETR在ImageNet-21k数据集上预训练。

使用RetinaNet框架对COCO val2017的对象检测性能。1×是12个轮次,3×是36个轮次。“MS”:多尺度训练。FLOP以800×600分辨率进行评估。

使用Mask R-CNN框架对COCO val2017数据集的对象检测和实例分割性能。FLOP在800×600图像上进行评估。
五、消融实验

基于小模型的LSA(L)和GSA(G)块的不同组合的分类性能。

不同形式的子采样函数对全局子采样注意力(GSA)的ImageNet分类性能。

使用不同的位置编码策略在COCO上的对象检测性能。