1. 自定义损失函数
1.1 以函数方式定义
手动写出损失的公式并用函数进行存储,方便调用。
def my_loss(output, target):
loss = torch.mean((output - target)**2)
return loss1.2 以类方式定义
1.2.1 损失函数的继承关系
(1)Loss函数部分继承_loss,部分继承_WeightedLoss
(2)_weightedLoss继承自_loss
(3)_loss继承自nn.Module
1.2.2 实例
(1)损失函数:Dice Loss
(2)公式:
(3)实现代码:
class DiceLoss(nn.Module):
def __init__(self,weight=None,size_average=True):
super(DiceLoss,self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
# 使用方法
criterion = DiceLoss()
loss = criterion(input,targets)(4)常见的损失函数DiceBCELoss、IoULoss、FocalLoss
class DiceBCELoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceBCELoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice_loss = 1 - (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')
Dice_BCE = BCE + dice_loss
return Dice_BCE
--------------------------------------------------------------------
class IoULoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(IoULoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
total = (inputs + targets).sum()
union = total - intersection
IoU = (intersection + smooth)/(union + smooth)
return 1 - IoU
--------------------------------------------------------------------
ALPHA = 0.8
GAMMA = 2
class FocalLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(FocalLoss, self).__init__()
def forward(self, inputs, targets, alpha=ALPHA, gamma=GAMMA, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')
BCE_EXP = torch.exp(-BCE)
focal_loss = alpha * (1-BCE_EXP)**gamma * BCE
return focal_loss注意: 最好全程使用PyTorch提供的张量计算接口,这样就不需要我们实现自动求导功能并且我们可以直接调用cuda
2. 动态调整学习率
学习率的设置难处:
(1)学习速率设置过小,会极大降低收敛速度,增加训练时间;
(2)学习率太大,可能导致参数在最优解两侧来回振荡;
(3)选定了一个合适的学习率后,经过许多轮的训练后,可能会出现准确率震荡或loss不再下降等情况,说明当前学习率已不能满足模型调优的需求。
2.1 使用官方scheduler
2.1.1 官方提供的API
-
lr_scheduler.LambdaLR
-
lr_scheduler.MultiplicativeLR
-
lr_scheduler.StepLR
-
lr_scheduler.MultiStepLR
-
lr_scheduler.ExponentialLR
-
lr_scheduler.CosineAnnealingLR
-
lr_scheduler.ReduceLROnPlateau
-
lr_scheduler.CyclicLR
-
lr_scheduler.OneCycleLR
-
lr_scheduler.CosineAnnealingWarmRestarts
2.1.2 使用方法
# 选择一种优化器
optimizer = torch.optim.Adam(...)
# 选择上面提到的一种或多种动态调整学习率的方法
scheduler1 = torch.optim.lr_scheduler....
scheduler2 = torch.optim.lr_scheduler....
...
schedulern = torch.optim.lr_scheduler....
# 进行训练
for epoch in range(100):
train(...)
validate(...)
optimizer.step()
# 需要在优化器参数更新之后再动态调整学习率
scheduler1.step()
...
schedulern.step() 注意 : 使用官方给出的torch.optim.lr_scheduler时,需要将scheduler.step()放在optimizer.step()后面进行使用。
2.2 自定义scheduler
2.2.1 自定义函数
(1)方法:自定义函数adjust_learning_rate来改变param_group中lr的值。
(2)实现代码:
def adjust_learning_rate(optimizer, epoch):
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr2.2.2 具体调用方法
直接调用我们已经定义好的adjust_learning_rate函数
def adjust_learning_rate(optimizer,...):
...
optimizer = torch.optim.SGD(model.parameters(),lr = args.lr,momentum = 0.9)
for epoch in range(10):
train(...)
validate(...)
adjust_learning_rate(optimizer,epoch)3. 模型微调
(1)数据量有限,最终训练得到的模型的精度也可能达不到实用的要求。
(2)模型微调(finetune):就是我们先找到一个同类的别人训练好的模型,把别人现成的训练好了的模型拿过来,换成自己的数据,通过训练调整一下参数。
3.1 torchvision
3.1.1 模型微调的流程

3.1.2 使用已有模型结构
以torchvision中的常见模型为例
(1)实例化网络
import torchvision.models as models
resnet18 = models.resnet18()
# resnet18 = models.resnet18(pretrained=False) 等价于与上面的表达式
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()
googlenet = models.googlenet()
shufflenet = models.shufflenet_v2_x1_0()
mobilenet_v2 = models.mobilenet_v2()
mobilenet_v3_large = models.mobilenet_v3_large()
mobilenet_v3_small = models.mobilenet_v3_small()
resnext50_32x4d = models.resnext50_32x4d()
wide_resnet50_2 = models.wide_resnet50_2()
mnasnet = models.mnasnet1_0() (2)传递pretrained参数:通过True或者False来决定是否使用预训练好的权重,默认状态下pretrained = False
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)
mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True)
mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)3.1.3 训练特定层
requires_grad = False来冻结部分层
import torchvision.models as models
# 冻结参数的梯度
feature_extract = True
model = models.resnet18(pretrained=True)
set_parameter_requires_grad(model, feature_extract)
# 修改模型
num_ftrs = model.fc.in_features
model.fc = nn.Linear(in_features=num_ftrs, out_features=4, bias=True)3.2 timm
提供了许多计算机视觉的SOTA模型,可以当作是torchvision的扩充版本,并且里面的模型在准确度上也较高。
3.2.1 timm的安装
(1)通过pip安装
pip install timm(2)通过git与pip进行安装
git clone https://github.com/rwightman/pytorch-image-models
cd pytorch-image-models && pip install -e .3.2.2 查看timm中预训练模型种类
(1)查看数量
import timm
avail_pretrained_models = timm.list_models(pretrained=True)
len(avail_pretrained_models)(2) 查看特定模型种类timm.list_models()
all_densnet_models = timm.list_models("*densenet*")
all_densnet_models
['densenet121',
'densenet121d',
'densenet161',
'densenet169',
'densenet201',
'densenet264',
'densenet264d_iabn',
'densenetblur121d',
'tv_densenet121'](3)查看模型参数default_cfg
model = timm.create_model('resnet34',num_classes=10,pretrained=True)
model.default_cfg
{'url': 'https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet34-43635321.pth',
'num_classes': 1000,
'input_size': (3, 224, 224),
'pool_size': (7, 7),
'crop_pct': 0.875,
'interpolation': 'bilinear',
'mean': (0.485, 0.456, 0.406),
'std': (0.229, 0.224, 0.225),
'first_conv': 'conv1',
'classifier': 'fc',
'architecture': 'resnet34'}3.2.3 使用和修改timm中预训练模型
通过timm.create_model()的方法来进行模型的创建,我们可以通过传入参数pretrained=True,来使用预训练模型
import timm
import torch
# 初始化模型参数
model = timm.create_model('resnet34',pretrained=True)
x = torch.randn(1,3,224,224)
output = model(x)
output.shape
# 查看某一层模型参数(以第一层卷积为例)
model = timm.create_model('resnet34',pretrained=True)
list(dict(model.named_children())['conv1'].parameters())
# 修改模型(将1000类改为10类输出)
model = timm.create_model('resnet34',num_classes=10,pretrained=True)
x = torch.randn(1,3,224,224)
output = model(x)
output.shape
# 改变输入通道数(比如我们传入的图片是单通道的,但是模型需要的是三通道图片) 我们可以通过添加in_chans=1来改变
model = timm.create_model('resnet34',num_classes=10,pretrained=True,in_chans=1)
x = torch.randn(1,1,224,224)
output = model(x)3.2.4 模型的保存
timm库所创建的模型是torch.model的子类,我们可以直接使用torch库中内置的模型参数保存和加载的方法
torch.save(model.state_dict(),'./checkpoint/timm_model.pth')
model.load_state_dict(torch.load('./checkpoint/timm_model.pth'))4. 半精度训练
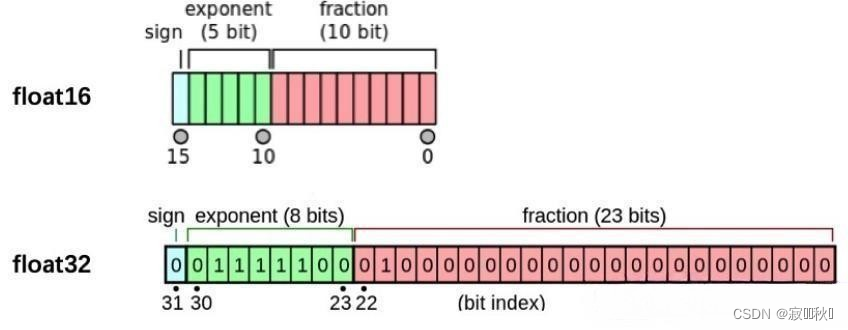
4.1 半精度介绍
(1)GPU性能:算力和显存
(2)半精度:PyTorch默认的浮点数存储方式用的是torch.float32,即torch.float32——>torch.float16
(3)图形表示:
4.2 半精度训练的设置
# 导入模型
from torch.cuda.amp import autocast
# 模型设置:在模型定义中,使用python的装饰器方法,用autocast装饰模型中的forward函数。
autocast()
def forward(self, x):
...
return x
# 训练过程:在训练过程中,只需在将数据输入模型及其之后的部分放入“with autocast():“即可
for x in train_loader:
x = x.cuda()
with autocast():
output = model(x)
...注意: 半精度训练主要适用于数据本身的size比较大。当数据本身的size并不大时,使用半精度训练则可能不会带来显著的提升。
5. 数据增强-imgaug
5.1 imgaug简介和安装
5.1.1 imgaug简介
imgaug是计算机视觉任务中常用的一个数据增强的包
5.1.2 imgaug的安装
(1)conda
conda config --add channels conda-forge
conda install imgaug(2)pip
# install imgaug either via pypi
pip install imgaug
# install the latest version directly from github
pip install git+https://github.com/aleju/imgaug.git5.2 imgaug的使用
5.2.1 单张图片处理
import imageio
import imgaug as ia
%matplotlib inline
# 图片的读取
img = imageio.imread("./Lenna.jpg")
# 可视化图片
ia.imshow(img)
# 一张一种数据增强处理
# imgaug包含了许多从Augmenter继承的数据增强的操作。在这里我们以Affine为例子
from imgaug import augmenters as iaa
# 设置随机数种子
ia.seed(4)
# 实例化方法
rotate = iaa.Affine(rotate=(-4,45))
img_aug = rotate(image=img)
ia.imshow(img_aug)
# # 一张多种种数据增强处理
from imgaug import augmenters as iaa
# 设置随机数种子
ia.seed(4)
# 实例化方法
rotate = iaa.Affine(rotate=(-4,45))
img_aug = rotate(image=img)
ia.imshow(img_aug)
iaa.Sequential(children=None, # Augmenter集合
random_order=False, # 是否对每个batch使用不同顺序的Augmenter list
name=None,
deterministic=False,
random_state=None)
# 构建处理序列
aug_seq = iaa.Sequential([
iaa.Affine(rotate=(-25,25)),
iaa.AdditiveGaussianNoise(scale=(10,60)),
iaa.Crop(percent=(0,0.2))
])
# 对图片进行处理,image不可以省略,也不能写成images
image_aug = aug_seq(image=img)
ia.imshow(image_aug)5.2.2 对批次图片进行处理
# 对批次的图片以同一种方式处理
images = [img,img,img,img,]
images_aug = rotate(images=images)
ia.imshow(np.hstack(images_aug))
aug_seq = iaa.Sequential([
iaa.Affine(rotate=(-25, 25)),
iaa.AdditiveGaussianNoise(scale=(10, 60)),
iaa.Crop(percent=(0, 0.2))
])
# 传入时需要指明是images参数
images_aug = aug_seq.augment_images(images = images)
#images_aug = aug_seq(images = images)
ia.imshow(np.hstack(images_aug))
# 对批次的图片分部分处理
iaa.Sometimes(p=0.5, # 代表划分比例
then_list=None, # Augmenter集合。p概率的图片进行变换的Augmenters。
else_list=None, #1-p概率的图片会被进行变换的Augmenters。注意变换的图片应用的Augmenter只能是then_list或者else_list中的一个。
name=None,
deterministic=False,
random_state=None)
# 对不同大小的图片进行处理
# 构建pipline
seq = iaa.Sequential([
iaa.CropAndPad(percent=(-0.2, 0.2), pad_mode="edge"), # crop and pad images
iaa.AddToHueAndSaturation((-60, 60)), # change their color
iaa.ElasticTransformation(alpha=90, sigma=9), # water-like effect
iaa.Cutout() # replace one squared area within the image by a constant intensity value
], random_order=True)
# 加载不同大小的图片
images_different_sizes = [
imageio.imread("https://upload.wikimedia.org/wikipedia/commons/e/ed/BRACHYLAGUS_IDAHOENSIS.jpg"),
imageio.imread("https://upload.wikimedia.org/wikipedia/commons/c/c9/Southern_swamp_rabbit_baby.jpg"),
imageio.imread("https://upload.wikimedia.org/wikipedia/commons/9/9f/Lower_Keys_marsh_rabbit.jpg")
]
# 对图片进行增强
images_aug = seq(images=images_different_sizes)
# 可视化结果
print("Image 0 (input shape: %s, output shape: %s)" % (images_different_sizes[0].shape, images_aug[0].shape))
ia.imshow(np.hstack([images_different_sizes[0], images_aug[0]]))
print("Image 1 (input shape: %s, output shape: %s)" % (images_different_sizes[1].shape, images_aug[1].shape))
ia.imshow(np.hstack([images_different_sizes[1], images_aug[1]]))
print("Image 2 (input shape: %s, output shape: %s)" % (images_different_sizes[2].shape, images_aug[2].shape))
ia.imshow(np.hstack([images_different_sizes[2], images_aug[2]]))
5.2.3 imgaug在PyTorch的应用
import numpy as np
from imgaug import augmenters as iaa
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
# 构建pipline
tfs = transforms.Compose([
iaa.Sequential([
iaa.flip.Fliplr(p=0.5),
iaa.flip.Flipud(p=0.5),
iaa.GaussianBlur(sigma=(0.0, 0.1)),
iaa.MultiplyBrightness(mul=(0.65, 1.35)),
]).augment_image,
# 不要忘记了使用ToTensor()
transforms.ToTensor()
])
# 自定义数据集
class CustomDataset(Dataset):
def __init__(self, n_images, n_classes, transform=None):
# 图片的读取,建议使用imageio
self.images = np.random.randint(0, 255,
(n_images, 224, 224, 3),
dtype=np.uint8)
self.targets = np.random.randn(n_images, n_classes)
self.transform = transform
def __getitem__(self, item):
image = self.images[item]
target = self.targets[item]
if self.transform:
image = self.transform(image)
return image, target
def __len__(self):
return len(self.images)
def worker_init_fn(worker_id):
imgaug.seed(np.random.get_state()[1][0] + worker_id)
custom_ds = CustomDataset(n_images=50, n_classes=10, transform=tfs)
custom_dl = DataLoader(custom_ds, batch_size=64,
num_workers=4, pin_memory=True,
worker_init_fn=worker_init_fn)6. 使用argparse进行调参
6.1 argparse简介
(1)argsparse是python的命令行解析的标准模块,内置于python,我们直接进行调用即可。
(2)argparse的作用就是将命令行传入的其他参数进行解析、保存和使用。
6.2 argparse的使用
6.2.1 设置步骤
(1)创建ArgumentParser()对象;
(2)调用add_argument()方法添加参数
(3)使用parse_args()解析参数
6.2.2 实际代码实现
# demo.py
import argparse
# 创建ArgumentParser()对象
parser = argparse.ArgumentParser()
# 添加参数
parser.add_argument('-o', '--output', action='store_true',
help="shows output")
# action = `store_true` 会将output参数记录为True
# type 规定了参数的格式
# default 规定了默认值
parser.add_argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3')
parser.add_argument('--batch_size', type=int, required=True, help='input batch size')
# 使用parse_args()解析函数
args = parser.parse_args()
if args.output:
print("This is some output")
print(f"learning rate:{args.lr} ")
6.3 更加高效使用argparse修改超参数
一般在进行一个项目创建时,我们喜欢直接创建config.py文件对参数进行存储,方便对参数进行查询、调用,修改和删除。
config.py文件
import argparse
def get_options(parser=argparse.ArgumentParser()):
parser.add_argument('--workers', type=int, default=0,
help='number of data loading workers, you had better put it '
'4 times of your gpu')
parser.add_argument('--batch_size', type=int, default=4, help='input batch size, default=64')
parser.add_argument('--niter', type=int, default=10, help='number of epochs to train for, default=10')
parser.add_argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3')
parser.add_argument('--seed', type=int, default=118, help="random seed")
parser.add_argument('--cuda', action='store_true', default=True, help='enables cuda')
parser.add_argument('--checkpoint_path',type=str,default='',
help='Path to load a previous trained model if not empty (default empty)')
parser.add_argument('--output',action='store_true',default=True,help="shows output")
opt = parser.parse_args()
if opt.output:
print(f'num_workers: {opt.workers}')
print(f'batch_size: {opt.batch_size}')
print(f'epochs (niters) : {opt.niter}')
print(f'learning rate : {opt.lr}')
print(f'manual_seed: {opt.seed}')
print(f'cuda enable: {opt.cuda}')
print(f'checkpoint_path: {opt.checkpoint_path}')
return opt
if __name__ == '__main__':
opt = get_options()train.py调用其中的参数进行参数的设置
# 导入必要库
...
import config
opt = config.get_options()
manual_seed = opt.seed
num_workers = opt.workers
batch_size = opt.batch_size
lr = opt.lr
niters = opt.niters
checkpoint_path = opt.checkpoint_path
# 随机数的设置,保证复现结果
def set_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
random.seed(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
...
if __name__ == '__main__':
set_seed(manual_seed)
for epoch in range(niters):
train(model,lr,batch_size,num_workers,checkpoint_path)
val(model,lr,batch_size,num_workers,checkpoint_path)参考:深入浅出PyTorch——第六章:PyTorch进阶训练技巧