YOLOv2
背景
YOLOv2是YOLO的第二个版本,其目标是显著提高准确性,同时使其更快
相关改进:
- 添加了
BN层——Batch Norm - 采用更高分辨率的网络进行分类主干网络的训练
Hi-res classifier - 去除了全连接层,采用卷积层进行模型的输出,同时采用与锚框(
anchor)进行bounding box的预测 - 采用新的网络架构
Darknet-19 - 采用
k-means聚类方法对训练集中的标准框做聚类分析,获取anchor boxes - 使用
sigmoid函数处理位置预测值 - 采用
passthrough的网络模型的连接方式(类似resnet) - 多尺度输入数据训练模型(可以用任意尺度的图像输入)
改进点详述
Batch Norm
引入Batch Norm,解决数据分布问题,有利于网络的训练
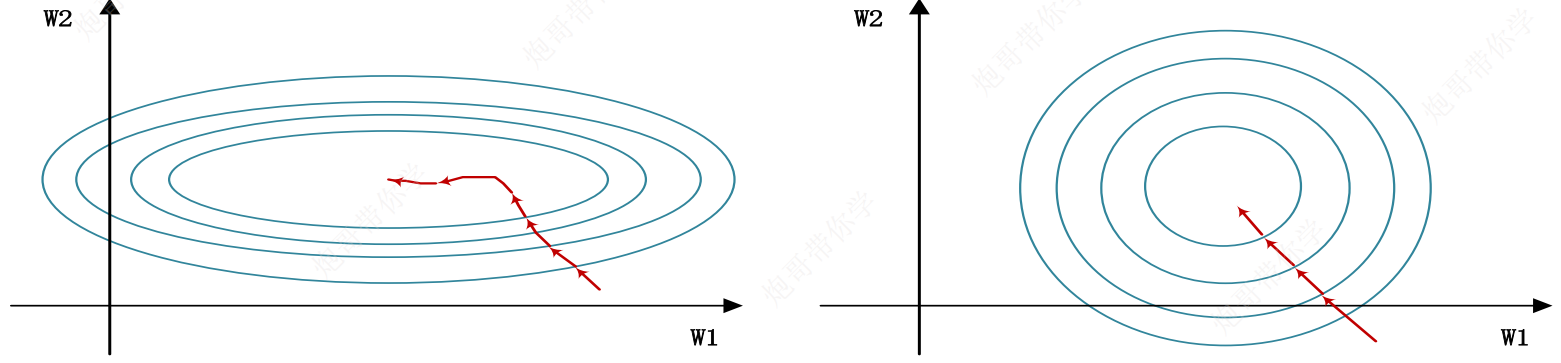
同时,为了防止经过某层网络后,数据的分布发生变化,因此约定,在每一层卷积层后都要加一层BN
基本步骤:
-
求每一个训练批次数据的均值
-
求每一个训练批次数据的方差
-
使用求的的均值和方差对该批次的训练数据做归一化(调整为正态分布
-
尺度变化和偏移:使用可学习的参数,做尺度变化和偏移
B N γ , β = γ x i + β BN_{\gamma, \beta} = \gamma x_i + \beta BNγ,β=γxi+β

实验证明,添加了
BN层同时去除Dropout可以提高2%的mAP一般
BN层不和Dropout一起使用
Hi-res Classifier
使用更高分辨率的图像对模型进行预训练
对于分类模型:
- 先使用224×224的数据训练160轮
- 再使用448×448的数据训练10轮
对于检测模型:
- 利用多尺度训练的方法一共训练160轮
Convolutional + Anchor Box
作者在实验中说明,如果仅仅单独地使用全卷积或者Anchor Box,会导致mAP下降
Yolov1中全连接层的缺点:
- 参数量大
- 容易过拟合
因此,作者在Yolov2中进行了改进:
- 把最后的全连接层去掉
- 一处最后一个
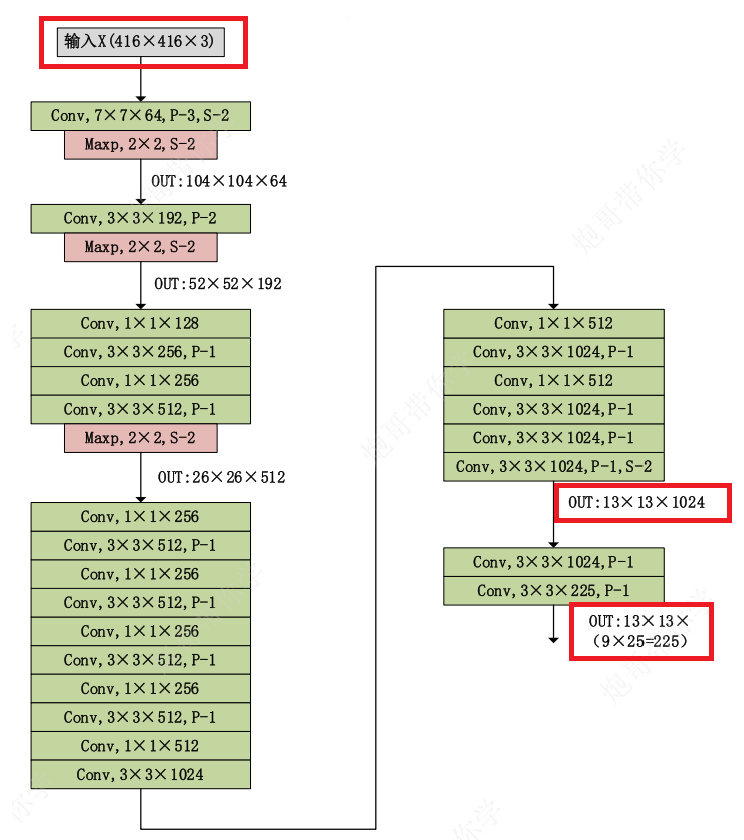
Pool层,使得卷积层输出更高分辨率 - 用416×416代替原来的输入大小448×448
- 最后输出为13×13×225,13代表划分为13×13个
bounding box - 416 / 13 = 0 416 / 13 = 0 416/13=0
- 最后输出为13×13×225,13代表划分为13×13个
- 将分类和空间检测解耦,利用
anchor box来预测目标的空间位置和类别——每一个框使用一组概率:- 最后输出为13×13×225
- 225 = 9×25 → \to → 9 × ( x , y , w , h , c ) + p (x, y, w, h, c) + p (x,y,w,h,c)+p(其中,p为20个类别
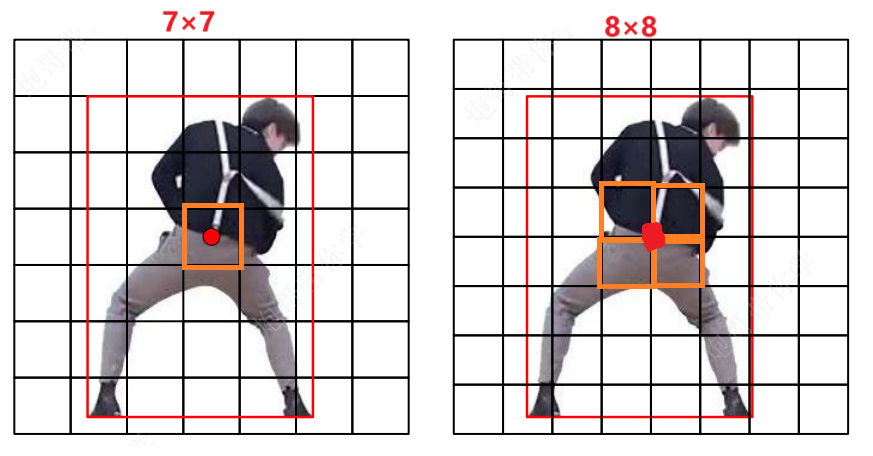
使用奇数划分
bounding box:防止物体中心点落在四个bounding box中心的情况
Anchor Box
yolov1中直接预测出物体的检测框大小的坐标,但由于物体大小不一,直接根据主干网络提取的信息进行矩形框和坐标的预测是一件很难的事情
而yolov2借鉴Faster R-CNN和SSD的做法利用anchor框进行预测——核心是事先设置一个合理的box,即anchor box,基于这个合理的box进行预测
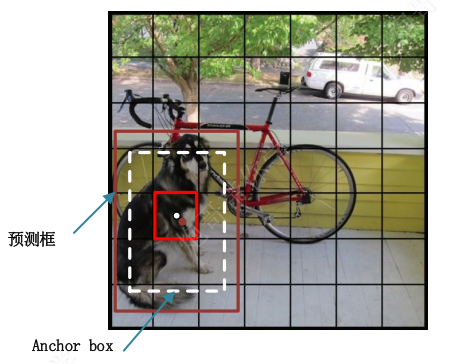
对每个grid cell都设置一些(9个)合理的anchor box,然后每个grid cell都基于这些anchor box进行预测,即预测框基于模型提取的特征和**anchor box**进行检测
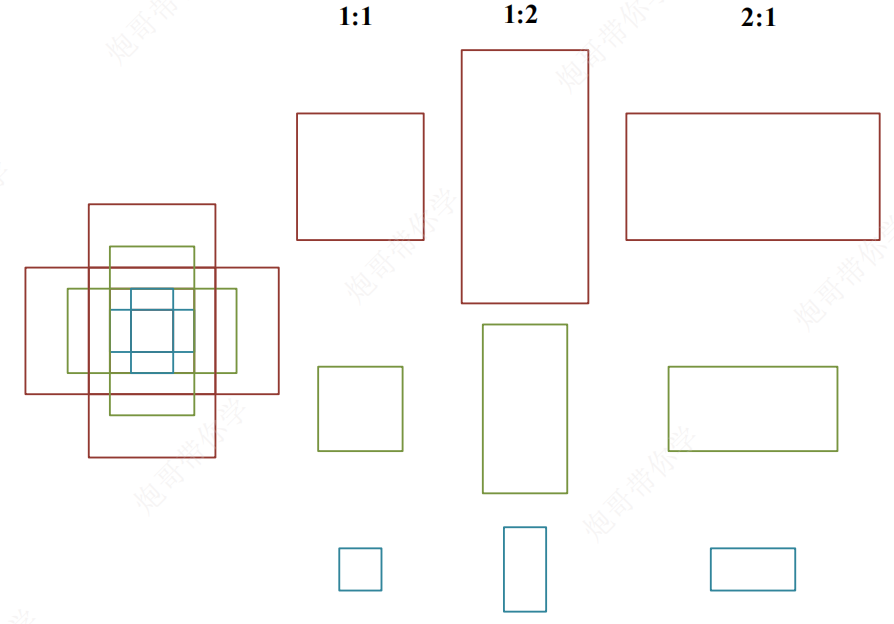
anchor box的设置:
- 三种尺寸:小、中、大三种尺寸
- 三种长宽比例:1:1、1:2、2:1
- 共有 3 × 3 = 9 种
anchor box
同时,由于引入了anchor box,因此存在两个问题:
anchor box的尺寸是人为手动选择,因此需要较合理的先验尺寸- 引入
anchor box后模型训练不稳定,尤其是训练刚开始的时候,这种预测的不稳定来自于预测box的(x,y)值
anchor box的选取
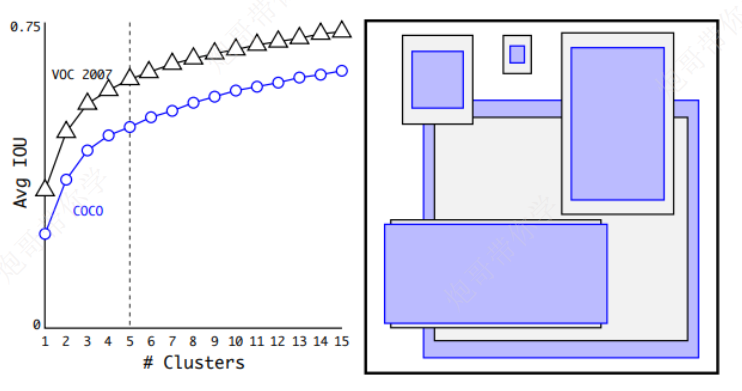
解决:使用k-means对9个设定的anchor box进行筛选
利用k-means对真实框进行聚类算法步骤:
- 定义簇类的个数,随机选取
k个样本作为簇中心 - 分别计算所有样本到
k个簇中心的欧式距离 - 根据距离,将样本点进行簇的划分
- 计算各中心样本的均值作为新的簇心
- 重复上述步骤,直至新的中心和原来的中心基本不变化时,结束
对所有样本中所有的真实框做聚类,将最终聚类的结果作为anchor box
同时,为了确保大的真实框和小的真实框之间的量纲问题,使用IOU作为聚类的评判准则:
d
(
b
o
x
,
c
e
n
t
r
o
i
d
s
)
=
1
−
I
O
U
(
b
o
x
,
c
e
n
t
r
o
i
d
s
)
d(box, centroids) =1-IOU(box, centroids)
d(box,centroids)=1−IOU(box,centroids)
注:计算IOU是将不同的box中心点重合,计算不同box之间的交并比
大的真实框和小的真实框之间的量纲问题:
如果使用欧式距离作为度量,则大的真实框会比小的真实框产生更多地误差,例50x50和45x45的box 与5x5和4.5x4.5的box,使用欧氏距离计算:
( 50 − 45 ) 2 + ( 50 − 45 ) 2 = 50 ( 5 − 4.5 ) 2 + ( 5 − 4.5 ) 2 = 0.5 \sqrt{(50-45)^2 + (50 - 45)^2} = \sqrt{50} \\ \sqrt{(5-4.5)^2 + (5 - 4.5)^2} = \sqrt{0.5} (50−45)2+(50−45)2=50(5−4.5)2+(5−4.5)2=0.5
可见大的真实框产生的误差更大,这就会导致,假设k=5,大的box被分到多个簇中,而其余中小形状的box被分到一个簇中
作者在平衡复杂度和IOU之后,最终得到的最佳k值为5,因此最后的输出是13×13×125(5×25)
DarkNet-19网络模型
分类模型
该网络模型种由于没有全连接层,因此模型对输入数据(图片大小)没有特殊的规定要求
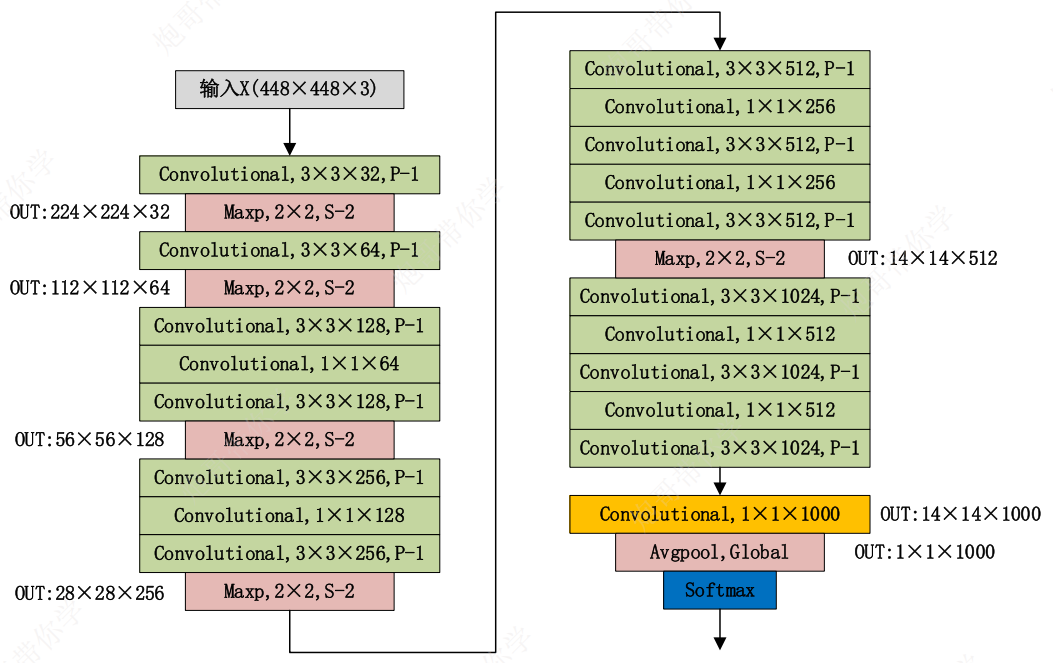
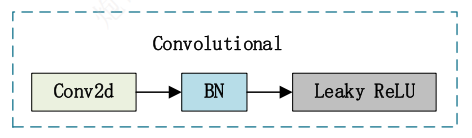
且其中每一个卷积模块由**卷积+BN+激活函数**构成
由上述结构可以看出,不论输入的图片大小是多少,最终经过一层1×1卷积层和全局平均池化后都会转化为1×1×1000的向量,从而进行分类工作
——正是由于这种网络结构(对输入数据大小不做严格要求),使得总体网络架构可以进行多尺度数据训练,增强模型的鲁棒性
检测模型
去除分类输出,即去除最后的1×1卷积层、全局平均池化核Sodtmax,使用一个1×1×N(N由输出结果而定)卷积代替
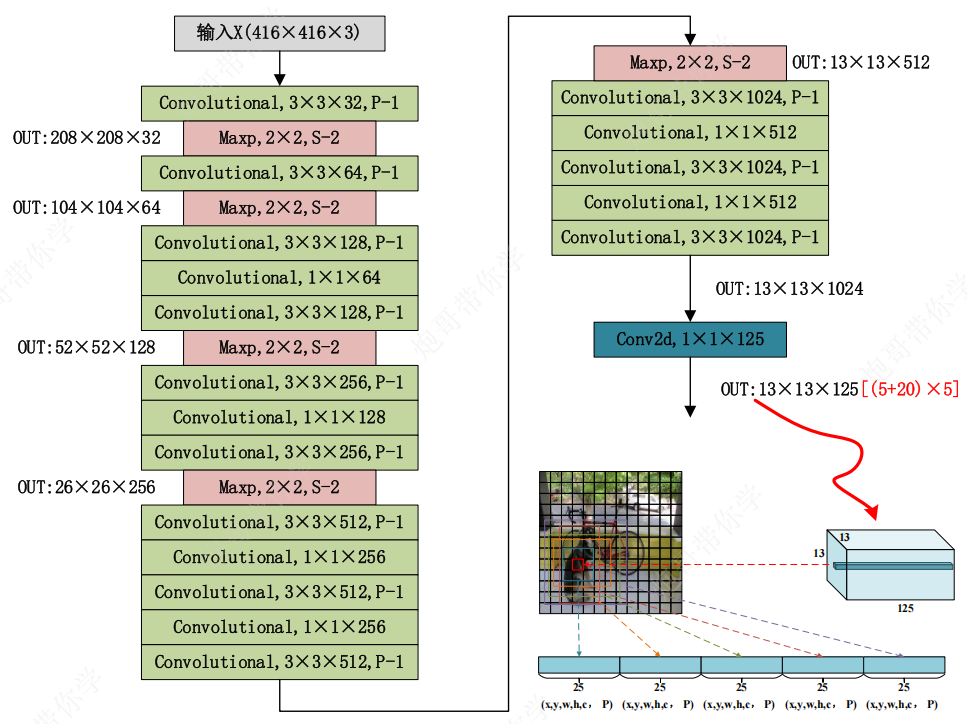
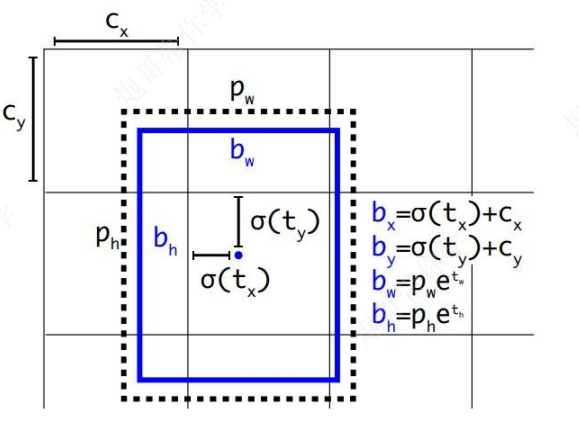
直接位置预测
弃用RPN网络预测方式,沿用yolov1的方式,预测边界框中心点相对于相应cell左上角位置的相对偏移值,同时使用sigmoid函数处理,进行归一化,防止偏移过多
b
x
=
σ
(
t
x
)
+
c
x
b
y
=
σ
(
t
y
)
+
c
y
b
w
=
p
w
e
t
w
b
h
=
p
h
e
t
h
b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y \\ b_w=p_we^{t_w} \\ b_h = p_he^{t_h}
bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=pheth
其中,
(
c
x
,
c
y
)
(c_x, c_y)
(cx,cy)为cell左上角的坐标,
(
p
w
,
p
h
)
(p_w, p_h)
(pw,ph)为anchor框的尺寸大小
Passthrough
输入图像经过多层网络提取特征后(经过卷积、下采样),最后输出的特征图中,较小的对象特征可能不明显或者被忽略掉——为了更好地检测一些比较小的对象,最后输出的特征图需要保留一些更细节的信息
基本步骤:
-
先对原始数据沿着通道维度进行拆分,得到 O 1 O1 O1
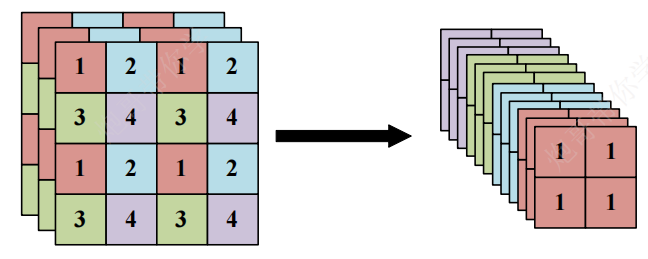
-
再对原始数据进行卷积和池化,得到 O 2 O2 O2
-
对 O 1 O1 O1和 O 2 O2 O2进行Concat,得到特征融合后的数据
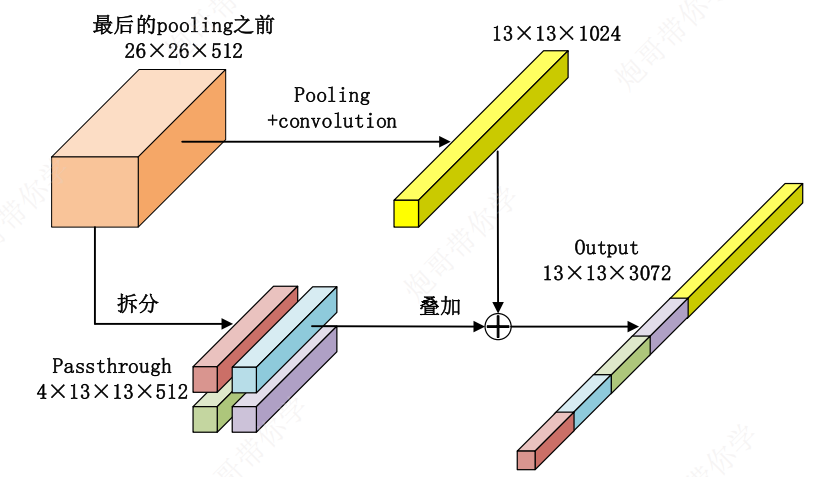
完整版的DarkNet-19

多尺度训练
作者再训练过程中引入了多尺度训练数据,即在训练过程中使用不同尺度的数据大小进行训练,增强模型的鲁棒性
具体操作为:每训练10个batch,网络就会随机选择另一种size的输入
训练过程
Yolov2的训练分为三个阶段
第一阶段
在ImageNet分类数据集上预训练DarkNet-19,此时模型的输入为224×224,共训练160个轮次
第二阶段
将网络的输入调整为448x448,继续在ImageNet数据集上finetune(微调)分类模型,训练10个epoch
第三阶段
-
修改
DarkNet-19分类模型为检测模型,并在检测数据集上继续微调160轮网络的修改包括:
- 移除最后一个卷积层、全局池化层和softmax层,增加三个3×3×1024卷积层
- 增加
passthrough层
-
输出数据中,
channels = num_anchors×(5+num_calsses),该数与数据集有关同时在训练过程中使用多尺度的方式进行训练
损失函数
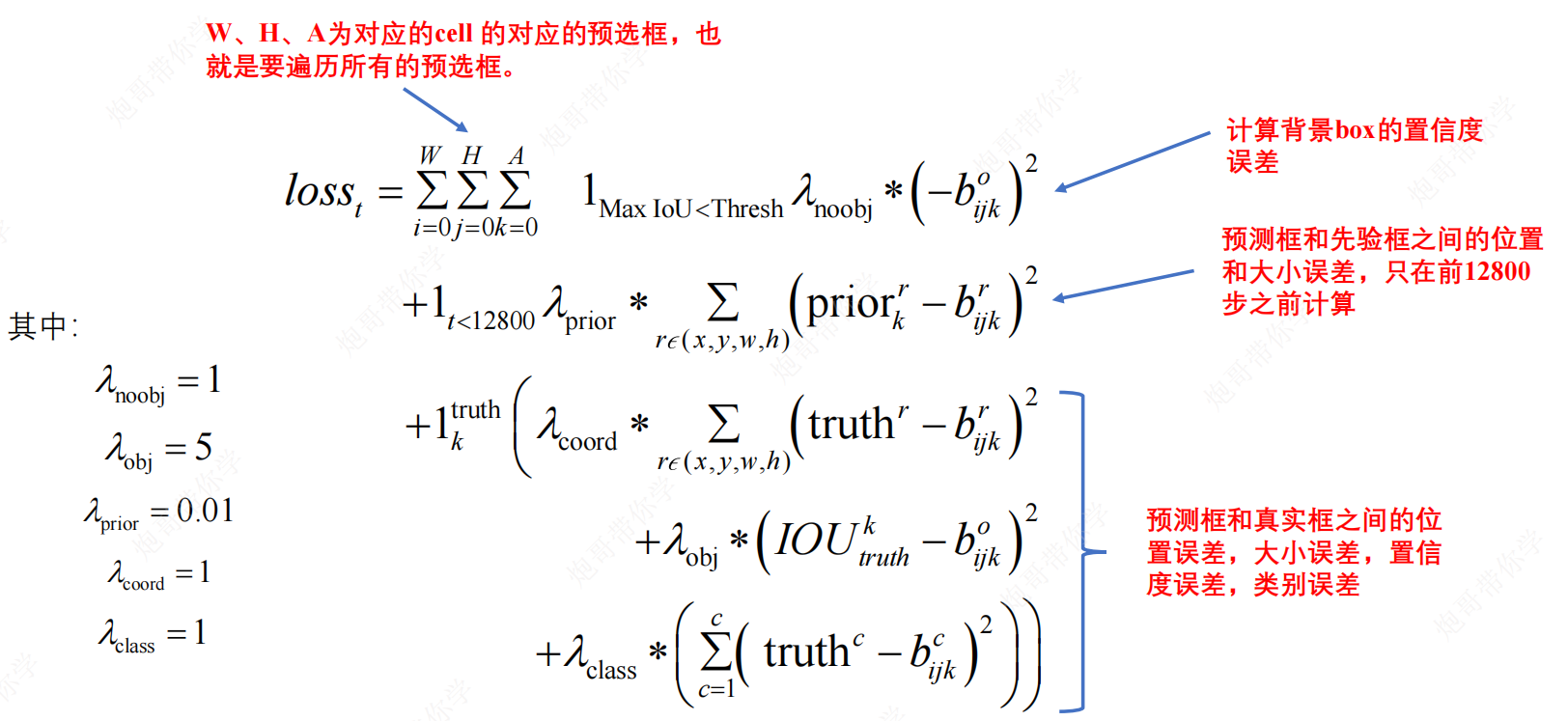
背景置信度误差
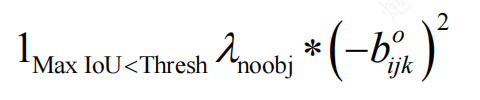
其中, 1 M a x I o U < T h r e s h 1_{Max IoU<Thresh} 1MaxIoU<Thresh为判定条件; λ n o o b j \lambda _{noobj} λnoobj为系数,当框内为背景时,该值为1
该误差用于计算各个预测框和所有真实标注框之间的IoU,并且取最大的IoU,如果该值小于一定的阈值(0.6),则这个预测框就标记为背景
先验框与预测框的坐标误差
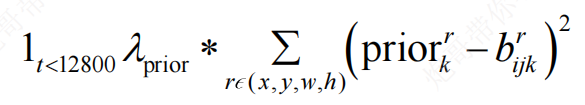
其中,
p
r
i
o
r
prior
prior为anchor box的数据,
b
b
b为预测框的相关数据
只在前12800步计算,目的是在训练前期预测框快速学习到先验框的形状,使得预测框不至于太过离谱
有物体的损失
计算与真实框匹配的预测框的损失,包括坐标损失、置信度损失和类别损失
匹配原则:
- 对于某个特定的真实框,首先计算其中心点落在哪个cell上
- 然后将这个cell对应的所有的
anchor box与真实框之间的IoU,且这个过程中不考虑坐标只考虑形状 - 选择最大的
IoU作为于其匹配的anchor box,用这个anchor box对应的预测框来预测真实框
对于那些没有被真实框匹配的先验框,除去那些Max_IoU低于阈值的(需要计算背景置信度损失),其他的就全部忽略
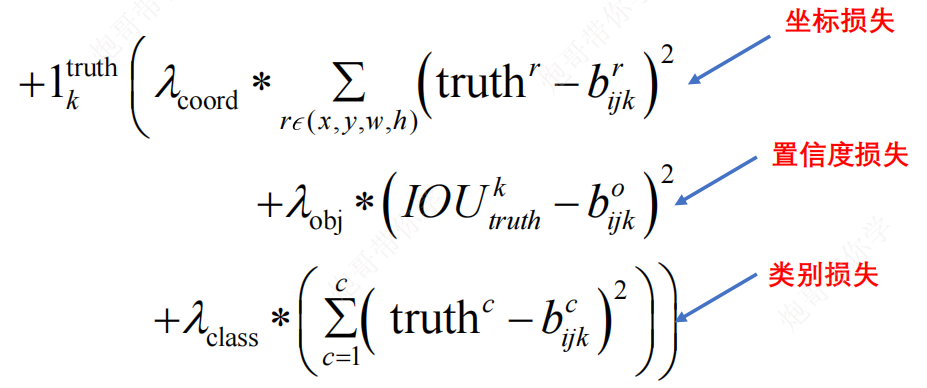
其中, 1 k t r u t h 1_k^{truth} 1ktruth为判定条件
总结
相比于Yolov1,定位的准确度和召回率均有提升,且速度较快
提出了几个比较好的模块,使得后续版本继续沿用:
anchor box预选框DarkNet网络架构
缺点:
- 小目标检测效果差
- 整体检测效果还有待提高