论文链接
Section 1 引言
1. In the context of decision-making, fairness is the absence of any prejudice or favoritism toward an individual or group based on their inherent or acquired characteristics.
公平是指基于个人或群体的固有或后天特征而对其没有任何偏见或偏袒。
2. bias举例:人种:非裔美国人 v.s. 白种人; 肤色深浅
3. In this survey, we identify two potential sources of unfairness in machine learning outcomes— those that arise from biases in the data and those that arise from the algorithms.
bias源于数据data的偏差或算法algorithm本身。
Section 2 算法不公平的实例
1. 在法庭上被用来评估被告重新开始犯罪的概率 e.g., COMPAS
2. 广告投放中女性看到的可能性低于男性
Section 3 偏见的类型与来源
1. 训练数据中存在偏见算法基于这些数据训练从而造成偏见
2. 算法本身设计上存在偏见(数据中没有偏见)这类有偏见的算法的数据结果被用于未来更多模型的训练数据
3. 偏见的类型分类
| 数据中的偏见 | ① 衡量标准有误带来的偏见 e.g., 因为先前有犯罪前科或者其家人中存在犯罪前科,而导致他们被监管的较其他人更频繁,从而在这类人中的逮捕率更高,但不能将prior arrests and friend/family arrests这一特征作为判断其“riskiness”/“crime” ② 遗漏重要因素带来的偏见 e.g., 预测客户停止订阅服务的概率模型忽略了竞争对手这一重要因素 ③ 不具备代表性的数据集中的偏差 e.g., 现有的Open Images数据集和ImageNet图像数据集缺乏地理多样性,导致了对西方文化的明显偏见 ④ Aggregation Bias.聚合偏差 e.g., 监测糖尿病HbA1c水平的模型并不适用于所有人种 是不是可以理解为这是一种“以偏概全”的偏见呢?
⑤ 抽样带来的偏差 非随机抽样导致的 ⑥ Longitudinal Data Fallacy.纵向数据谬误 了解一下Panel Data(面板数据)又叫Longitudinal Data,参见该百度百科,讲的很明白,纵向数据其实是heterogeneous的,即时间序列数据与横截面数据的联合,不能纯粹用其中某一种数据的分析方法来分析,并且两种方法分析下来结果可能完全相悖 ⑦ Linking Bias.链接偏见 阅读了Social data: Biases, methodological pitfalls, and ethical boundaries这篇论文的Linking Bias相关部分后也并不是很清晰,所以就自己推断了可能是从用户点击的链接中去分析用户行为,但是这些链接可能存在链接内容错误或者关联在某一社交网络中错误等问题,导致了数据的偏见?(仅个人推测 |
| 算法设计本身的偏见 | ① 算法偏差 如使用某些优化函数、正则化、选择应用回归模型数据作为一个整体还是考虑subgroups、在算法中使用统计偏差估计等等,都可以导致有偏见的算法决策。 ② 用户交互内容呈现带来的偏见
③ 流行程度带来的偏见 更受欢迎的物品往往会暴露得更多。然而,受欢迎程度的指标也会受到操纵——例如,通过虚假的评论或社交机器人,并不一定是好质量的表现。 ④ Emergent Bias. 突发的偏见(不知道这么翻译合不合适) 在算法设计完成后,真实用户使用并交互带来的。可阅读 这篇文章的相关部分的例子稍微体会一下。 ⑤ 评估机制带来的偏见 算法使用了不恰当的基准来进行评估。 |
| 用户行为带来的偏见 | 许多用于训练ML模型的数据源都是由用户生成的。用户中的任何固有偏见都可能反映在他们生成的数据中。此外,当用户行为受到一个算法的影响/调制时,该算法中存在的任何偏差都可能在数据生成过程中引入偏差。 ① 历史偏见 e.g., 历史上搜索引擎搜索CEO,出来男性CEO而非女性CEO,导致以后搜索更难搜索出女性CEO ② 人口 当数据集中中所代表的用户群体与原始的目标群体不同时,统计数据、人口统计数据、代表和用户特征就会产生人口偏差。 ③ Self-selection Bias.自我选举带来的偏见 当抽样对象参与调查时,会对自己的认知有偏心。e.g., 像学生调查某一个群体更聪明时,倾向于认为自己所在的群体更聪明。 ④ Social Bias. 社会偏见 我们对某件事的观点会由于看到其他人的观点而改变。(一种从众心理?) ⑤ 行为偏差 不同环境下的人行为不同。e.g.,不同平台上的人对同一个表情符号的理解不同。 ⑥ 时间偏差 产生于种群和行为随时间的差异。e.g., Twitter上,人们在谈论一个特定的话题时,开始在某个时候使用一个标签来吸引注意力,然后继续讨论这个事件,而不使用这个标签。 ⑦ 内容产生偏差 来自于用户生成的内容的结构、词汇、语义和句法差异。e.g., 不同性别和年龄组的语言使用存在差异,同时语言使用的差异也可以在不同国家和国家和人口内部看到。 |
4. 数据偏见实例
① DL公开数据集中的偏见
② 医疗应用程序中的偏见
5. 歧视的类型分类
- 可解释的歧视:一些差异是有理由的,合理而不被认为是非法歧视。
- 不可解释的歧视:对一个群体的歧视是不合理的,即非法
- 直接的歧视:法律上被保护的一些属性被歧视是非法的。
- 间接的歧视:non-sensitive attributes被歧视,e.g., 邮政编码(隐含着种族属性)
- 歧视的来源
- 系统性歧视:e.g., 绝大多数的雇主更喜欢与他们文化相似、有相似经验和爱好的有能力的候选人。如果决策者碰巧绝大多数属于某些子群体,那么这可能会导致对不属于这些子群体的合格候选人的歧视。
- 统计歧视:使用平均群体统计数据来判断属于该群体的个人
Section 4 算法公平
1. No universal definition of fairness exists shows the difficulty of solving this problem.
2. 公平性的定义
|
Equalized Odds
|
A predictor |
|
Equal Opportunity
| A binary predictor |
|
Demographic Parity / Statistical Parity
| A predictor |
|
Fairness through Awareness
|
An algorithm is fair if it gives similar predictions to similar individuals. 换句话说,任何两个在为特定任务定义的相似性(
inverse distance反距离)度量方面具有相似的个体都应该得到相似的结果。
|
|
Fairness through Unawareness
|
An algorithm is fair as long as any
protected attributes
A
are not
explicitly
used
in the decision-making process
|
|
Treatment Equality
| 受保护群体的假阴性和假阳性的比例相同,即达到treatment equality |
|
Test Fairness
|
A score S = S(x) is test fair (well-calibrated) if it reflects the same likelihood of recidivism irrespective of the individual’s group membership, R. That is, if for all values of s, P(Y =1|S=s,R=b)=P(Y =1|S=s,R=w),即对于任何预测概率得分S,受保护群体和未受保护群体的人必须具有
正确属于正类的
相同概率
。
|
|
Counterfactual Fairness
| 译为反事实公平,指如果一个决定在现实世界中和在不同的反事实世界中都是相同概率发生的,那么这个决定是公平的,举个例子应该就明白了。 Alice没有在她的工作中得到晋升、她是一个女人、我们可以观察到的她的情况和表现等等一切,那么如果她是一个男人,她得到晋升的可能性有多大? 如果可能性一样,则判定她这次没被晋升的决定是公平的。Note that, 这是一个公平的个人概念,不同于总体评估晋升过程是否公平或不公平的统计学说。也许整个晋升制度是相当公平的,但在爱丽丝的特殊情况下发生了不公平的歧视。[参考资料] |
|
Fairness in Relational Domains
|
“A notion of fairness that is able to capture the
relational structure in a domain—not only by taking attributes of individuals into consideration
but by taking into account the social, organizational, and other connections between individuals”
|
| Conditional Statistical Parity | (和统计均等真的很像)
For a set of legitimate factors L, predictor |
以上各类公平性定义又可分为三类:
|
Individual Fairness
|
平等对待不同的群体。
[Demographic parity,Conditional statistical parity,Equalized odds,Equal opportunity,Treatment equality,Test fairness.]
|
|
Subgroup Fairness
|
Subgroup fairness intends to obtain the best properties of the group and individual notions of fairness.
[Subgroup fairness.]
|
|
Group Fairness
|
给相似的人做出类似的预测。
[Fairness through unawareness,Fairness through awareness,Counterfactual fairness.]
|
Section 5 公平机器学习的方法
1. 一般来说,针对算法中偏见的方法可以分为三类:
① 预处理:从数据入手,处理数据中的偏见。
② in-processing(在处理中):试图修改和改变最先进的学习算法,以消除在模型训练过程中的歧视。如果允许改变机器学习模型的学习过程,那么就可以在训练模型的过程中使用in-processing——要么通过将更改纳入目标函数,要么通过施加约束。
③ post-processing后处理:在训练后通过访问模型训练过程中没有涉及的保留集(我理解为没有用来训练的那批数据集)来执行的,训练好的黑盒模型分配的标签在后处理阶段根据函数重新分配。
2. 公平的机器学习
① 公平分类
② 公平回归
公平处罚(3类):个人公平、组公平、混合公平
③ 结构化预测中
e.g., RBA (reducing bias amplification):为了确保模型的预测在训练数据中遵循相同的分布
④ 公平的PCA
常规PCA(主成分分析)提高某一群体(如女性)的重构错误率。
⑤ 社区检测/图形嵌入/聚类
社区检测方法中有偏见,CLAN减轻对在线社会社区中弱势群体的伤害;图形嵌入/聚类中也有类似方法。
⑥ 公平因果推理
因果模型/因果图
消除因果依赖,从而做出不考虑群体或个人的敏感属性的决定。
一篇有关“RL中的公平policy”的论文——Learning optimal fair policies
3. 代表性公平学习
① 变分自编码器Variational Fair Autoencoder
使用了maximum mean discrepancy (MMD)去消除敏感变量带来的影响② 对抗学习 Adversarial Learninge.g., FairGAN 生成与真实数据集相似的新数据集,它具有去偏性.
① 字嵌入e.g., 性别倾斜, gender-specific words(去除),gender-neutral words(硬去偏:去除/软去偏:通过trade-off尽可能保持与原始嵌入的相似性 )② Coreference Resolution 有译为指代消解a data-augmentation technique, word2vec debiasing techniques结合原始数据集和辅助数据集来训练模型+word2vec去偏技术来生成单词嵌入③ 语言模型平均绝对偏差和标准偏差来测量偏差a regularization loss term 正则损失项 最小化性别词嵌入影响④ 语句编码器word embedding⑤ 机器翻译e.g., 在一些翻译系统中,当我们将“He is a nurse. She is a doctor”翻译成匈牙利语之后,再翻译回英语,句子将会变成 “She is a nurse. He is a doctor”。
use the existing debiasing methods in word embedding and apply them in the machine translation pipeline数据集中男性说的话的比例更高⑥ Named Entity Recognition 命名实体识别六种偏见衡量标准:
- Error Type-1 Unweighted:
,识别出在人口统计群体(男性和女性)中被标记为非人实体的比例。这可能是没有被标记或被标记为其他实体的实体。
- Error Type-1 Weighted:
,加权,即考虑名字的频率或流行程度,例如如果一个更流行的名字被错误地标记了,他们可能会受到惩罚。
- Error Type-2 Unweighted:
,与Error Type-1 Unweighted不同的是,如果实体没有标记,此错误不计算。
,类比Error Type-2 Unweighted。
,会报告实体是否根本没有被标记。 与Error Type-1 Unweighted不同的是,即使该实体被标记为非人实体,此错误类型也不会考虑。
,类比Error Type-3 Unweighted。
5. 算法公平性领域是一个相对较新的研究领域,它的工作仍有待改进。
Section 6 公平性研究所面临的挑战和机遇
1. 挑战
① 统一公平性的定义
当前的公平定义的不兼容性问题
② 从平等到公平
目前工作中提出的定义大多集中于平等
equity, which is the concept that each individual or group is given the resources they need to succeed
③ 寻找不公平
围绕detect unfairness展开Given a definition of fairness, it should be possible to identify instances of this unfairness in a particular dataset.
2. 机遇
机器学习的各个子领域中研究 algorithmic biases and fairness 的热度不一,并不是每个领域都得到研究界同样多的关注,这也是机遇所在。
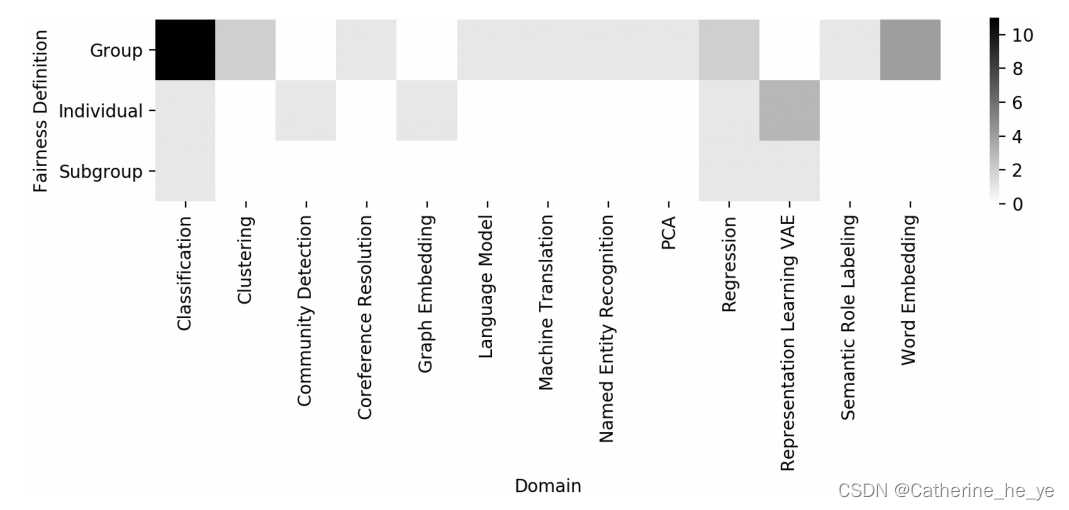
Section 7 结论
从数据和算法两方面,来了解bias和unfairness,do this survey。



![[附源码]Python计算机毕业设计大学生心理健康管理系统](https://img-blog.csdnimg.cn/43419b3d45cf479ba93eded038b91114.png)
![[附源码]java毕业设计学生信息管理系统](https://img-blog.csdnimg.cn/ce16ce78ce624b45bf4f0cdcacc5ef5d.png)

![[附源码]Python计算机毕业设计大学生项目众筹系统](https://img-blog.csdnimg.cn/43da00c80b0f468a93390f82dacd0593.png)