需要源码请点赞关注收藏后评论区留下QQ~~~
一、Sarsa算法简介
Sarsa算法每次更新都需要获取五元组(S,A,R,S',A')这也是该算法称为Sarsa的原因,每当从非终止状态进行一次转移后,就进行一次更新,但需要注意的是,动作A是情节中实际发生的动作。在更新(S,A)的动作值函数Q(S,A)时,Agent并不实际执行状态S'下的动作A‘。由于采用了贪心策略,Sarsa算法在各时间步都隐式地进行了策略改进,像这种在每个样本更新后都进行策略改进的策略迭代算法,也成为完全乐观策略算法
估算最优策略的Sarsa算法步骤如下

二、风险投资问题实战
在进行投资时,预期收益是一个非常重要的参考指标,现在越来越多的人接收概率的观点,但是收益为正的投资也未必一定理性。
假设一种风险投资,当前本金为S,下一个单位时间有0.5的概率变为原有资产的0.9倍,0.5的概率变为原有资产的1.11倍。经过一个时间单位后预期收益率变为百分之0.5,但是在实际情况中,进行2n各时间步后连续投资预期收益非常低,当N趋近于无穷时,该投资会血本无归,为了使投资更加合理,利用Sarsa算法给出在给定本金情况下的投资方案
该问题的MDP模型如下
1:状态空间
状态为当前资产的数目,因此状态空间为连续的实数空间
2:动作空间
该问题中一共有两个动作,分别为投资和不投资。用0表示不投资,用1表示投资
3:立即奖赏
在这个问题中 如果不投资则立即奖赏为0,如果进行投资则分为四种情况
资产增长且结果大于等于本金 +1奖赏
资产减少 且投资结果小于等于本金 -1奖赏
资产增加 且投资结果小于本金 +0.5奖赏
资产减少 且投资结果大于本金 -0.5奖赏
使用Sarsa算法解决风险投资问题 首先设置本金为10 将动作值函数设置为50×2的数组,且初值为0,初始学习率为0.05,使用贪心策略
当迭代到20000个情节时 迭代已经收敛 导出的Q值迭代过程表如下
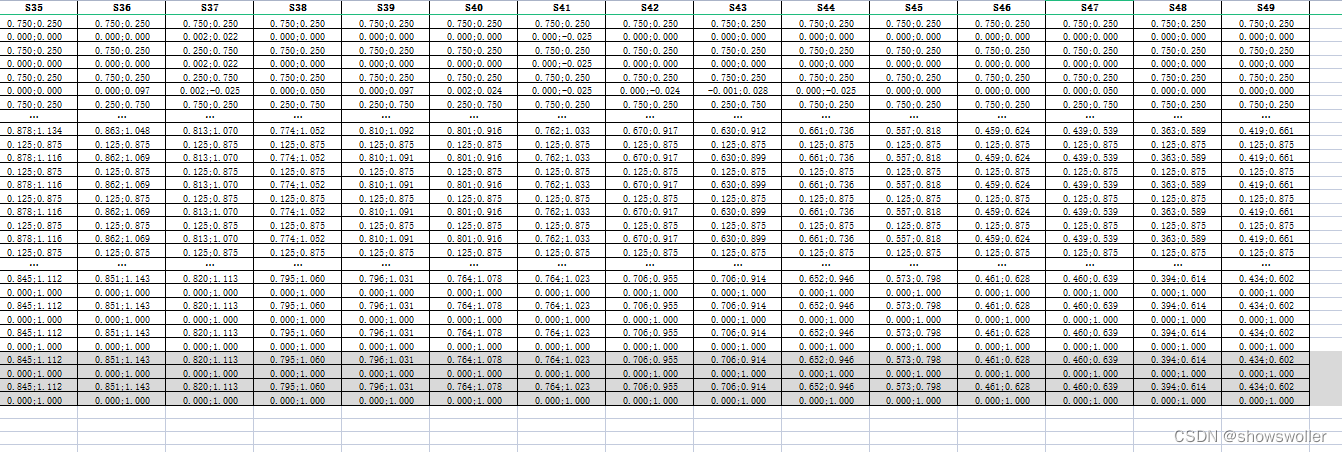
结论:当资金小于本金时(10)时,不进行投资,当现有资金大于等于本金(10)时,可以进行投资
部分代码如下
import numpy as np
from invest import InvestEnv
np.random.seed(1)
env = InvestEnv()
def trans_q(Q): # 输出保留3位小数
new_q = []
new_q = [round(x, 3) for x in Q]
return new_q
def Attenuation(epsilon, alpha, episode_sum, episode): # epsilon和alpha衰减函数
epsilon = (float(episode_sum) - float(episode)) / float(episode_sum) * epsilon
alpha = (float(episode_sum) - float(episode)) / float(episode_sum) * alpha
return epsilon, alpha
# 输出函数
def print_ff(list_q, Q, episode_i, epsilon_k, alpha_k):
list_s = range(0,50)
for em in list_q:
if em == episode_i:
print("*******************************情节数:%s*******************************" % (str(em)))
for state in list_s:
print("Q(%d,*)" % (state) + str(trans_q(Q[state])))
prob = [epsilon_k / 2.0, epsilon_k / 2.0]
max_a = np.argmax(Q[state])
prob[max_a] = 1 - (epsilon_k / 2.0)
print('概率值' + str(trans_q(prob)))
print("epsilon_k: {}".format(epsilon_k))
print("alpha_k:{}".format(alpha_k))
# 输出单步计算过程
def print_dd(s, a, R, next_s, next_a, print_len, episode_i, Q, e_k, a_k, P, P_next):
if s == 6 and a == 1:
print("*********************************单步的计算过程************************************")
print(6, 1)
print("alpha:" + str(a_k))
print("epsilon:" + str(e_k))
print("Q_state: {} Q_next: {}".format(Q[s], Q[next_s]))
print("Q[{},{}]: {}".format(s, a, Q[s, a]))
print("Q[{},{}]: {}".format(next_s, next_a, Q[next_s, next_a]))
print("update:" + str(Q[s, a] + a_k * (R + 0.8 * Q[next_s, next_a] - Q[s, a])))
# print(p)
print("************************************************************************************")
def policy_epsilon_greedy(env, s, Q, epsilon):
Q_s = Q[s]
if np.random.rand() < epsilon:
a = np.random.choice(env.action_space)
else:
a = np.argmax(Q_s)
return a
def Sarsa(env, episode_num, alpha, gamma, epsilon):
Q = np.zeros((env.state_space, env.action_space))
epsilon = epsilon
count = 0
list_q = [0,1,2,3,4,9998,9999,10000,10001,10002,19996,19997,19998,19999,20000]
for episode_i in range(episode_num):
env.reset()
S = env.state
epsilon_k, alpha_k = Attenuation(epsilon, alpha, episode_num, episode_i)
A = policy_epsilon_greedy(env, S, Q, epsilon_k)
print_ff(list_q, Q, episode_i, epsilon_k, alpha_k)
if episode_i == 10000:
print("e_k:" + str(epsilon_k) + "a_k" + str(alpha_k))
done = False
P_S = env.getState()
for i in range(1000):
next_S, R = env.step(A)
P_S_next = env.getState()
if next_S > 49:
Q[S, A] = Q[S, A] + alpha_k * (R + gamma * 0.0 - Q[S, A])
break
next_A = policy_epsilon_greedy(env, next_S, Q, epsilon_k)
# 输出某一个
if episode_i in [9999, 10000]:
count += 1
print(count)
return Q
Q = Sarsa(env, 20001, 0.05, 0.8, 0.5)创作不易 觉得有帮助请点赞关注收藏~~~