前两篇文章我们介绍了如何使用GPU编程执行简单的任务,比如令人难以理解的并行任务、使用共享内存归并(reduce)和设备函数。为了提高我们的并行处理能力,本文介绍CUDA事件和如何使用它们。但是在深入研究之前,我们将首先讨论CUDA流。
前期准备
导入和加载库,确保有一个GPU。
import warnings
from time import perf_counter, sleep
import numpy as np
import numba
from numba import cuda
from numba.core.errors import NumbaPerformanceWarning
print(np.__version__)
print(numba.__version__)
# Ignore NumbaPerformanceWarning
warnings.simplefilter("ignore", category=NumbaPerformanceWarning)
# 1.21.6
# 0.55.2
# Found 1 CUDA devices
# id 0 b'Tesla T4' [SUPPORTED]
# Compute Capability: 7.5
# PCI Device ID: 4
# PCI Bus ID: 0
# UUID: GPU-eaab966c-a15b-15f7-94b1-a2d4932bac5f
# Watchdog: Disabled
# FP32/FP64 Performance Ratio: 32
# Summary:
# 1/1 devices are supported
# True
流 (Streams)
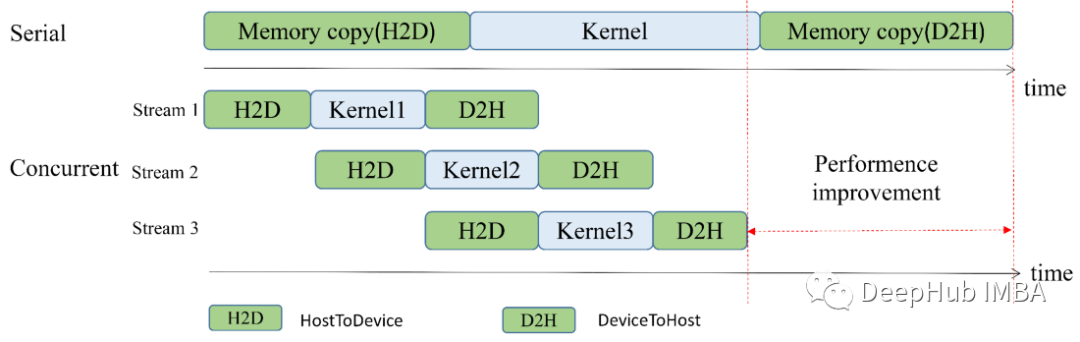
当我们启动内核(函数)时,它会在 GPU 中排队等待执行,GPU 会顺序按照启动时间执行我们的内核。设备中启动的许多任务可能依赖于之前的任务,所以“将它们放在同一个队列中”是有道理的。例如,如果将数据异步复制到 GPU 以使用某个内核处理它,则复制的步骤本必须在内核运行之前完成。
但是如果有两个相互独立的内核,将它们放在同一个队列中有意义吗?不一定!因为对于这种情况,CUDA通过流的机制来进行处理。我们可以将流视为独立的队列,它们彼此独立运行,也可以同时运行。这样在运行许多独立任务时,这可以大大加快总运行时间。
Numba 中的流
我们这里演示一个简单的任务。给定一个数组 a,然后将用规范化版本覆盖它:
a ← a / ∑a[i]
解决这个简单的任务需要使用三个内核。第一个内核 partial_reduce 将是上一篇文章中进行的归并操作的代码。它将返回一个 threads_per_block 大小的数组,把它传递给另一个内核 single_thread_sum,single_thread_sum将进一步将其缩减为单例数组(大小为 1)。这个内核将在单个线程的单个块上运行。最后还使用 divide_by 将原始数组除以我们计算的总和最后得到我们的结果。所有这些操作都将在 GPU 中进行,并且应该一个接一个地运行。
threads_per_block = 256
blocks_per_grid = 32 * 40
@cuda.jit
def partial_reduce(array, partial_reduction):
i_start = cuda.grid(1)
threads_per_grid = cuda.blockDim.x * cuda.gridDim.x
s_thread = 0.0
for i_arr in range(i_start, array.size, threads_per_grid):
s_thread += array[i_arr]
s_block = cuda.shared.array((threads_per_block,), numba.float32)
tid = cuda.threadIdx.x
s_block[tid] = s_thread
cuda.syncthreads()
i = cuda.blockDim.x // 2
while (i > 0):
if (tid < i):
s_block[tid] += s_block[tid + i]
cuda.syncthreads()
i //= 2
if tid == 0:
partial_reduction[cuda.blockIdx.x] = s_block[0]
@cuda.jit
def single_thread_sum(partial_reduction, sum):
sum[0] = 0.0
for element in partial_reduction:
sum[0] += element
@cuda.jit
def divide_by(array, val_array):
i_start = cuda.grid(1)
threads_per_grid = cuda.gridsize(1)
for i in range(i_start, array.size, threads_per_grid):
array[i] /= val_array[0]
当内核调用和其他操作没有指定流时,它们会在默认流中运行。默认流是一个特殊的流,它的行为取决于运行的参数是legacy 还是per-thread。对于我们来说,在非默认流中运行任务就足够了。下面我们看看如何运行我们的三个内核:
# Define host array
a = np.ones(10_000_000, dtype=np.float32)
print(f"Old sum: {a.sum():.2f}")
# Old sum: 10000000.00
# Example 3.1: Numba CUDA Stream Semantics
# Pin memory
with cuda.pinned(a):
# Create a CUDA stream
stream = cuda.stream()
# Array copy to device and creation in the device. With Numba, you pass the
# stream as an additional to API functions.
dev_a = cuda.to_device(a, stream=stream)
dev_a_reduce = cuda.device_array((blocks_per_grid,), dtype=dev_a.dtype, stream=stream)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype, stream=stream)
# When launching kernels, stream is passed to the kernel launcher ("dispatcher")
# configuration, and it comes after the block dimension (`threads_per_block`)
partial_reduce[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_reduce)
single_thread_sum[1, 1, stream](dev_a_reduce, dev_a_sum)
divide_by[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_sum)
# Array copy to host: like the copy to device, when a stream is passed, the copy
# is asynchronous. Note: the printed output will probably be nonsensical since
# the write has not been synchronized yet.
dev_a.copy_to_host(a, stream=stream)
# Whenever we want to ensure that all operations in a stream are finished from
# the point of view of the host, we call:
stream.synchronize()
# After that call, we can be sure that `a` has been overwritten with its
# normalized version
print(f"New sum: {a.sum():.2f}")
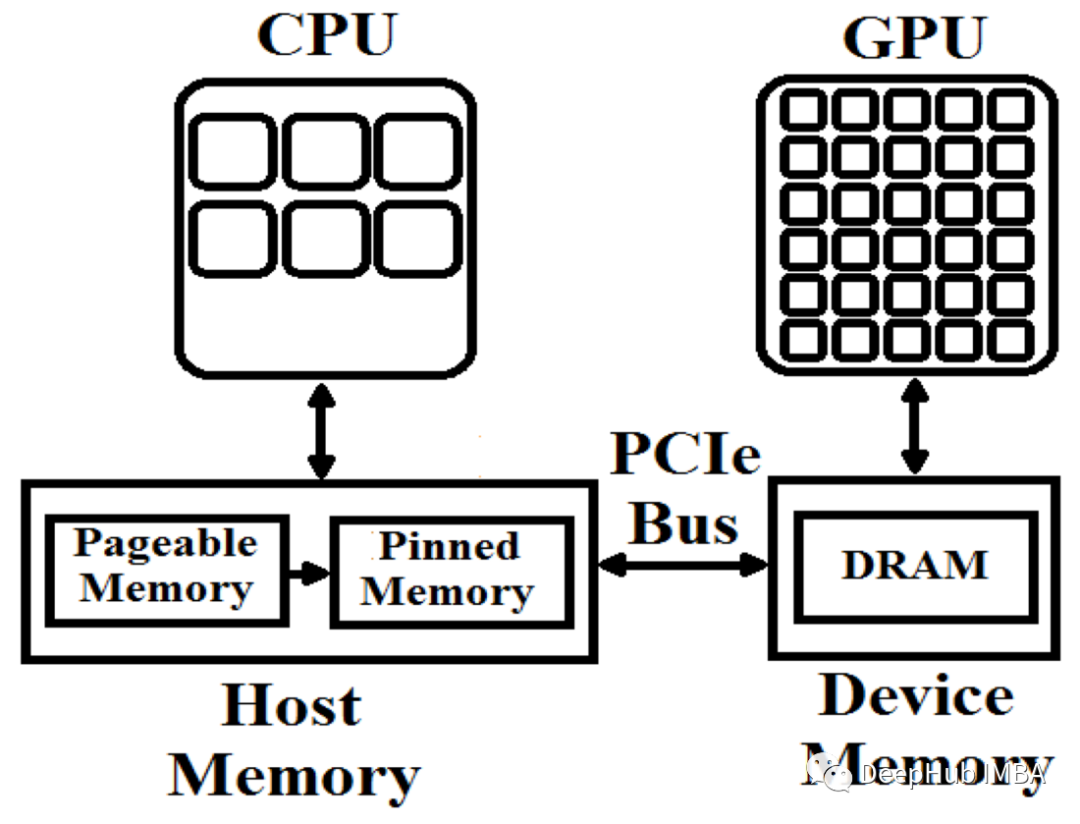
这里还有一个需要强调的内容:cuda.pinned。这是上下文管理器创建一种特殊类型的内存,称为页面锁定或固定内存,CUDA 在将内存从主机传输到设备时使用它会提高速度。
位于主机 RAM 中的内存可以随时进行分页,也就是说操作系统可以偷偷地将对象从 RAM 移动到硬盘。这样做是为了将不经常使用的对象移动到较慢的内存位置,从而将快速的 RAM 内存留给更需要的对象。而是 CUDA 不允许从可分页对象到 GPU 的异步传输。这是因为磁盘(分页)→ RAM → GPU是非常缓慢的传输流。
要异步传输数据,我们必须通过某种方式防止操作系统偷偷将数据隐藏在磁盘中的某个地方,这样可以保证数据始终位于 RAM 中。这就是cuda.pinned的作用,它创建了一个上下文,在该上下文中参数将被“锁定”,即强制位于 RAM 中。见图 3.2。
这样代码就非常简单了。创建一个流,然后将其传递给要对该流进行操作的每个 CUDA 函数。Numba中CUDA 内核配置(方括号)要求流位于块维度大小之后的第三个参数中。
一般情况下,将流传递给 Numba CUDA API 函数不会改变它的行为,只会改变它在其中运行的流。一个例外是从设备到主机的复制。但是有一个例外,当调用 device_array.copy_to_host()(不带参数)时复制是同步进行的。当调用 device_array.copy_to_host(stream=stream)(使用流)时,如果 device_array 没有pinned,复制也会同步进行。如果pinned并传递了流,则复制只会异步进行。
一个有用的提示:Numba 提供了一个有用的上下文管理器,可以在其上下文中排队所有操作;退出上下文时,操作将被同步,包括内存传输。所以例3.1也可以写成:
with cuda.pinned(a):
stream = cuda.stream()
with stream.auto_synchronize():
dev_a = cuda.to_device(a, stream=stream)
dev_a_reduce = cuda.device_array((blocks_per_grid,), dtype=dev_a.dtype, stream=stream)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype, stream=stream)
partial_reduce[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_reduce)
single_thread_sum[1, 1, stream](dev_a_reduce, dev_a_sum)
divide_by[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_sum)
dev_a.copy_to_host(a, stream=stream)
分离独立内核与流
假设我们要normalize的是多个数组。每一个单独数组的归一化操作是完全相互独立的。但是GPU会等到一个标准化结束后才开始下一个标准化,这样不会享受到并行化带来的提升。所以我们可以把这些任务分成不同的流。
让我们看一个规范化10个数组的例子——每个数组都使用自己的流。
# Example 3.2: Multiple streams
N_streams = 10
# Do not memory-collect (deallocate arrays) within this context
with cuda.defer_cleanup():
# Create 10 streams
streams = [cuda.stream() for _ in range(1, N_streams + 1)]
# Create base arrays
arrays = [
i * np.ones(10_000_000, dtype=np.float32) for i in range(1, N_streams + 1)
]
for i, arr in enumerate(arrays):
print(f"Old sum (array {i}): {arr.sum():12.2f}")
tics = [] # Launch start times
for i, (stream, arr) in enumerate(zip(streams, arrays)):
tic = perf_counter()
with cuda.pinned(arr):
dev_a = cuda.to_device(arr, stream=stream)
dev_a_reduce = cuda.device_array(
(blocks_per_grid,), dtype=dev_a.dtype, stream=stream
)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype, stream=stream)
partial_reduce[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_reduce)
single_thread_sum[1, 1, stream](dev_a_reduce, dev_a_sum)
divide_by[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_sum)
dev_a.copy_to_host(arr, stream=stream)
toc = perf_counter() # Stop time of launches
print(f"Launched processing {i} in {1e3 * (toc - tic):.2f} ms")
# Ensure that the reference to the GPU arrays are deleted, this will
# ensure garbage collection at the exit of the context.
del dev_a, dev_a_reduce, dev_a_sum
tics.append(tic)
tocs = []
for i, (stream, arr) in enumerate(zip(streams, arrays)):
stream.synchronize()
toc = perf_counter() # Stop time of sync
tocs.append(toc)
print(f"New sum (array {i}): {arr.sum():12.2f}")
for i in range(4):
print(f"Performed processing {i} in {1e3 * (tocs[i] - tics[i]):.2f} ms")
print(f"Total time {1e3 * (tocs[-1] - tics[0]):.2f} ms")
# Old sum (array 0): 10000000.00
# Old sum (array 1): 20000000.00
# Old sum (array 2): 30000000.00
# Old sum (array 3): 40000000.00
# Old sum (array 4): 50000000.00
# Old sum (array 5): 60000000.00
# Old sum (array 6): 70000000.00
# Old sum (array 7): 80000000.00
# Old sum (array 8): 90000000.00
# Old sum (array 9): 100000000.00
# Launched processing 0 in 12.99 ms
# Launched processing 1 in 11.55 ms
# Launched processing 2 in 11.53 ms
# Launched processing 3 in 11.98 ms
# Launched processing 4 in 11.09 ms
# Launched processing 5 in 11.22 ms
# Launched processing 6 in 12.16 ms
# Launched processing 7 in 11.59 ms
# Launched processing 8 in 11.85 ms
# Launched processing 9 in 11.20 ms
# New sum (array 0): 1.00
# New sum (array 1): 1.00
# New sum (array 2): 1.00
# New sum (array 3): 1.00
# New sum (array 4): 1.00
# New sum (array 5): 1.00
# New sum (array 6): 1.00
# New sum (array 7): 1.00
# New sum (array 8): 1.00
# New sum (array 9): 1.00
# Performed processing 0 in 118.77 ms
# Performed processing 1 in 110.17 ms
# Performed processing 2 in 102.25 ms
# Performed processing 3 in 94.43 ms
# Total time 158.13 ms
下面代码与单个流进行比较:
# Example 3.3: Single stream
# Do not memory-collect (deallocate arrays) within this context
with cuda.defer_cleanup():
# Create 1 streams
streams = [cuda.stream()] * N_streams
# Create base arrays
arrays = [
i * np.ones(10_000_000, dtype=np.float32) for i in range(1, N_streams + 1)
]
for i, arr in enumerate(arrays):
print(f"Old sum (array {i}): {arr.sum():12.2f}")
tics = [] # Launch start times
for i, (stream, arr) in enumerate(zip(streams, arrays)):
tic = perf_counter()
with cuda.pinned(arr):
dev_a = cuda.to_device(arr, stream=stream)
dev_a_reduce = cuda.device_array(
(blocks_per_grid,), dtype=dev_a.dtype, stream=stream
)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype, stream=stream)
partial_reduce[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_reduce)
single_thread_sum[1, 1, stream](dev_a_reduce, dev_a_sum)
divide_by[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_sum)
dev_a.copy_to_host(arr, stream=stream)
toc = perf_counter() # Stop time of launches
print(f"Launched processing {i} in {1e3 * (toc - tic):.2f} ms")
# Ensure that the reference to the GPU arrays are deleted, this will
# ensure garbage collection at the exit of the context.
del dev_a, dev_a_reduce, dev_a_sum
tics.append(tic)
tocs = []
for i, (stream, arr) in enumerate(zip(streams, arrays)):
stream.synchronize()
toc = perf_counter() # Stop time of sync
tocs.append(toc)
print(f"New sum (array {i}): {arr.sum():12.2f}")
for i in range(4):
print(f"Performed processing {i} in {1e3 * (tocs[i] - tics[i]):.2f} ms")
print(f"Total time {1e3 * (tocs[-1] - tics[0]):.2f} ms")
# Old sum (array 0): 10000000.00
# Old sum (array 1): 20000000.00
# Old sum (array 2): 30000000.00
# Old sum (array 3): 40000000.00
# Old sum (array 4): 50000000.00
# Old sum (array 5): 60000000.00
# Old sum (array 6): 70000000.00
# Old sum (array 7): 80000000.00
# Old sum (array 8): 90000000.00
# Old sum (array 9): 100000000.00
# Launched processing 0 in 13.42 ms
# Launched processing 1 in 12.62 ms
# Launched processing 2 in 16.10 ms
# Launched processing 3 in 13.74 ms
# Launched processing 4 in 17.59 ms
# Launched processing 5 in 12.57 ms
# Launched processing 6 in 12.44 ms
# Launched processing 7 in 12.32 ms
# Launched processing 8 in 12.54 ms
# Launched processing 9 in 13.54 ms
# New sum (array 0): 1.00
# New sum (array 1): 1.00
# New sum (array 2): 1.00
# New sum (array 3): 1.00
# New sum (array 4): 1.00
# New sum (array 5): 1.00
# New sum (array 6): 1.00
# New sum (array 7): 1.00
# New sum (array 8): 1.00
# New sum (array 9): 1.00
# Performed processing 0 in 143.38 ms
# Performed processing 1 in 140.16 ms
# Performed processing 2 in 135.72 ms
# Performed processing 3 in 126.30 ms
# Total time 208.43 ms
哪一个更快呢?当使用多个流时并没有看到总时间改进。这可能有很多原因。例如,对于并发运行的流,本地内存中必须有足够的空间。英伟达提供了几个工具来调试CUDA,包括调试CUDA流。请查看他们的Nsight Systems了解更多信息。
事件
CPU 的运行流程的问题之一是它会比 GPU 的包含更多的操作。
所以可以使用 CUDA 直接从 GPU 对事件进行操作时间的记录。事件只是 GPU 中发生某事的时间寄存器。在某种程度上,它类似于 time.time 和 time.perf_counter,但与它们不同的是,我们需要处理的是:从 CPU进行编程,从 GPU 为事件计时。
所以除了创建时间戳(“记录”事件)之外,我们还需要确保事件与 CPU 同步,这样才能对其进行访问。让我们检查一个简单的例子。
用于内核执行的事件的计时器
# Example 3.4: Simple events
# Events need to be initialized, but this does not starting timing.
# We create two events, one at the start of computations, and one at the end.
event_beg = cuda.event()
event_end = cuda.event()
# Create CUDA stream
stream = cuda.stream()
with cuda.pinned(arr):
# Queue array copy/create in `stream`
dev_a = cuda.to_device(arr, stream=stream)
dev_a_reduce = cuda.device_array((blocks_per_grid,), dtype=dev_a.dtype, stream=stream)
# Here we issue our first event recording. `event_beg` from this line onwards
# will contain the time referring to this moment in the GPU.
event_beg.record(stream=stream)
# Launch kernel asynchronously
partial_reduce[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_reduce)
# Launch a "record" which will be trigged when the kernel run ends
event_end.record(stream=stream)
# Future tasks submitted to the stream will wait util `event_end` completes.
event_end.wait(stream=stream)
# Synchronize this event with the CPU, so we can use its value.
event_end.synchronize()
# Now we calculate the time it took to execute the kernel. Note that we do not
# need to wait/synchronize `event_beg` because its execution is contingent upon
# event_end having waited/synchronized
timing_ms = event_beg.elapsed_time(event_end) # in miliseconds
print(f"Elapsed time {timing_ms:.2f} ms")
# Elapsed time 0.57 ms
为GPU操作计时的一个有用方法是使用上下文管理器:
# Example 3.5: Context Manager for CUDA Timer using Events
class CUDATimer:
def __init__(self, stream):
self.stream = stream
self.event = None # in ms
def __enter__(self):
self.event_beg = cuda.event()
self.event_end = cuda.event()
self.event_beg.record(stream=self.stream)
return self
def __exit__(self, type, value, traceback):
self.event_end.record(stream=self.stream)
self.event_end.wait(stream=self.stream)
self.event_end.synchronize()
self.elapsed = self.event_beg.elapsed_time(self.event_end)
stream = cuda.stream()
dev_a = cuda.to_device(arrays[0], stream=stream)
dev_a_reduce = cuda.device_array((blocks_per_grid,), dtype=dev_a.dtype, stream=stream)
with CUDATimer(stream) as cudatimer:
partial_reduce[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_reduce)
print(f"Elapsed time {cudatimer.elapsed:.2f} ms")
# Elapsed time 0.53 ms
对流中事件的计时器
我们将计时器和CUDA中的流进行结合,完成本文的最终目标:
# Example 3.6: Timing a single streams with events
N_streams = 10
# Do not memory-collect (deallocate arrays) within this context
with cuda.defer_cleanup():
# Create 1 stream
streams = [cuda.stream()] * N_streams
# Create base arrays
arrays = [
i * np.ones(10_000_000, dtype=np.float32) for i in range(1, N_streams + 1)
]
events_beg = [] # Launch start times
events_end = [] # End start times
for i, (stream, arr) in enumerate(zip(streams, arrays)):
with cuda.pinned(arr):
# Declare events and record start
event_beg = cuda.event()
event_end = cuda.event()
event_beg.record(stream=stream)
# Do all CUDA operations
dev_a = cuda.to_device(arr, stream=stream)
dev_a_reduce = cuda.device_array(
(blocks_per_grid,), dtype=dev_a.dtype, stream=stream
)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype, stream=stream)
partial_reduce[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_reduce)
single_thread_sum[1, 1, stream](dev_a_reduce, dev_a_sum)
divide_by[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_sum)
dev_a.copy_to_host(arr, stream=stream)
# Record end
event_end.record(stream=stream)
events_beg.append(event_beg)
events_end.append(event_end)
del dev_a, dev_a_reduce, dev_a_sum
sleep(5) # Wait for all events to finish, does not affect GPU timing
for event_end in events_end:
event_end.synchronize()
# The first `event_beg` launched is the earliest event. But the last `event_end`
# is not known a priori. We find which event that is with:
elapsed_times = [events_beg[0].elapsed_time(event_end) for event_end in events_end]
i_stream_last = np.argmax(elapsed_times)
print(f"Last stream: {i_stream_last}")
print(f"Total time {elapsed_times[i_stream_last]:.2f} ms")
# Last stream: 9
# Total time 113.16 ms
# Example 3.7: Timing multiple streams with events
# Do not memory-collect (deallocate arrays) within this context
with cuda.defer_cleanup():
# Create 10 streams
streams = [cuda.stream() for _ in range(1, N_streams + 1)]
# Create base arrays
arrays = [
i * np.ones(10_000_000, dtype=np.float32) for i in range(1, N_streams + 1)
]
events_beg = [] # Launch start times
events_end = [] # End start times
for i, (stream, arr) in enumerate(zip(streams, arrays)):
with cuda.pinned(arr):
# Declare events and record start
event_beg = cuda.event()
event_end = cuda.event()
event_beg.record(stream=stream)
# Do all CUDA operations
dev_a = cuda.to_device(arr, stream=stream)
dev_a_reduce = cuda.device_array(
(blocks_per_grid,), dtype=dev_a.dtype, stream=stream
)
dev_a_sum = cuda.device_array((1,), dtype=dev_a.dtype, stream=stream)
partial_reduce[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_reduce)
single_thread_sum[1, 1, stream](dev_a_reduce, dev_a_sum)
divide_by[blocks_per_grid, threads_per_block, stream](dev_a, dev_a_sum)
dev_a.copy_to_host(arr, stream=stream)
# Record end
event_end.record(stream=stream)
events_beg.append(event_beg)
events_end.append(event_end)
del dev_a, dev_a_reduce, dev_a_sum
sleep(5) # Wait for all events to finish, does not affect GPU timing
for event_end in events_end:
event_end.synchronize()
# The first `event_beg` launched is the earliest event. But the last `event_end`
# is not known a priori. We find which event that is with:
elapsed_times = [events_beg[0].elapsed_time(event_end) for event_end in events_end]
i_stream_last = np.argmax(elapsed_times)
print(f"Last stream: {i_stream_last}")
print(f"Total time {elapsed_times[i_stream_last]:.2f} ms")
# Last stream: 9
# Total time 108.50 ms
总结
CUDA是高性能的。在本教程中,介绍了如何使用事件准确地测量内核的执行时间,这种方法可用于分析代码。还介绍了流以及如何使用它们始终保持gpu的占用,以及映射数组如何改善内存访问。以下是本文的源代码:
https://avoid.overfit.cn/post/fd3454303b9b4a7e8a2898b7d24b41ec
作者:Carlos Costa, Ph.D.






![[注塑]各种进胶方式优缺点分析](https://img-blog.csdnimg.cn/d415d6f71c2c4f979a43d90bda07a8b9.png)


![[Spring Cloud] GateWay自定义过滤器/结合Nacos服务注册中心](https://img-blog.csdnimg.cn/fb4fe2cccab34b23b8f372e5850e2ef4.png)