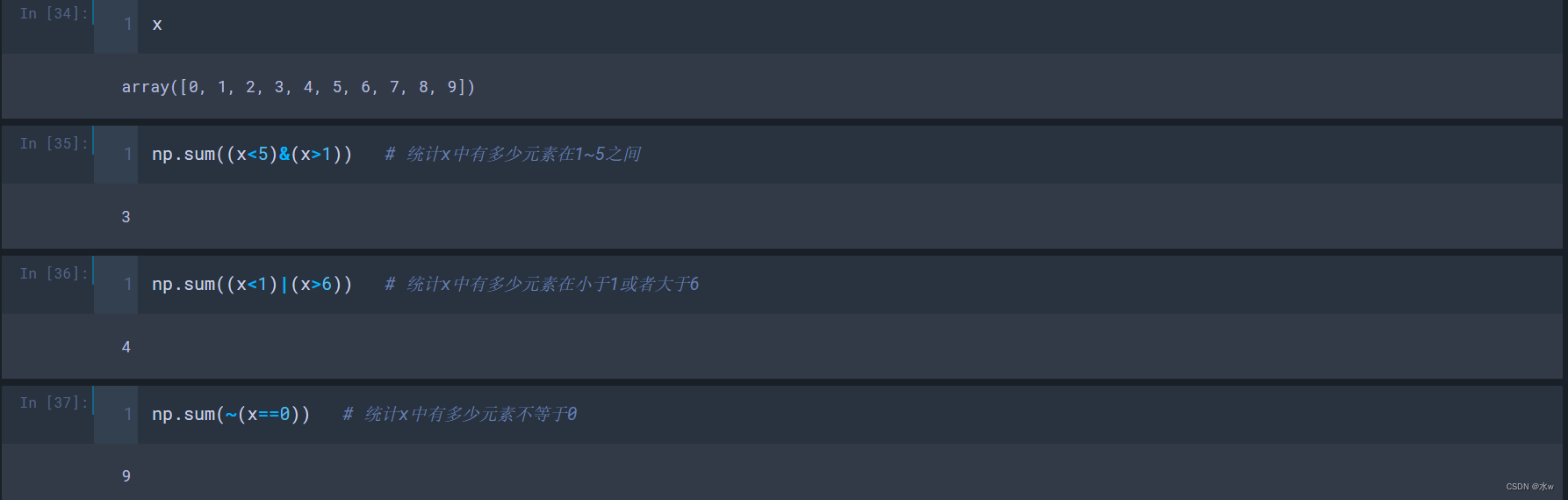
整数之间转换
# 1. 10 -> 16
hex(number)
# 2. 10 -> 2
bin(number)
# 3. 10 -> 8
oct(number)
# 4. x进制 -> 10
int(Union[str, bytes, bytearray],base=x)
------------------
print(int("0x16", base=16)) // 22
字符串转整数
# 10进制
val = int('10')
print(type(val), val)
# 16进制
val = int('0xa', 16)
print(type(val), val)
val = int('a', 16)
print(type(val), val)
# 2进制
val = int('0b1010', 2)
print(type(val), val)
val = int('1010', 2)
print(type(val), val)
----------------------------无意义------------------------------
# 3进制
val = int('101', 3)
print(type(val), val)
# 5进制
val = int('60', 5)
print(type(val), val)
bytes操作
-
什么是bytes? cgo简单易懂
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is // used, by convention, to distinguish byte values from 8-bit unsigned // integer values. type byte = uint8 // rune is an alias for int32 and is equivalent to int32 in all ways. It is // used, by convention, to distinguish character values from integer values. type rune = int32 -
bytes 相比 str 而言更接近底层数据,也更接近存储的形式,它其实是一个字节的数组,类似于 C 语言中的 char [],每个字节是一个范围在 0-255 的数字。
int转bytes([]byte)
int.to_bytes()
def to_bytes(self,
length: int,
byteorder: str,
*,
signed: bool = ...) -> bytes
返回表示整数的字节数组。
-
length:要使用的字节对象的长度。如果整数不能用给定的字节数表示,则会引发OverflowError。
number = 256 print(number.to_bytes(1, "little", signed=False)) -------------------------------------------------------------- >>> OverflowError: int too big to convert 举例: number = 1024 print(number.to_bytes(2, "little", signed=False)) // b'\x00\x04' hex(1024) // 0x0400 -
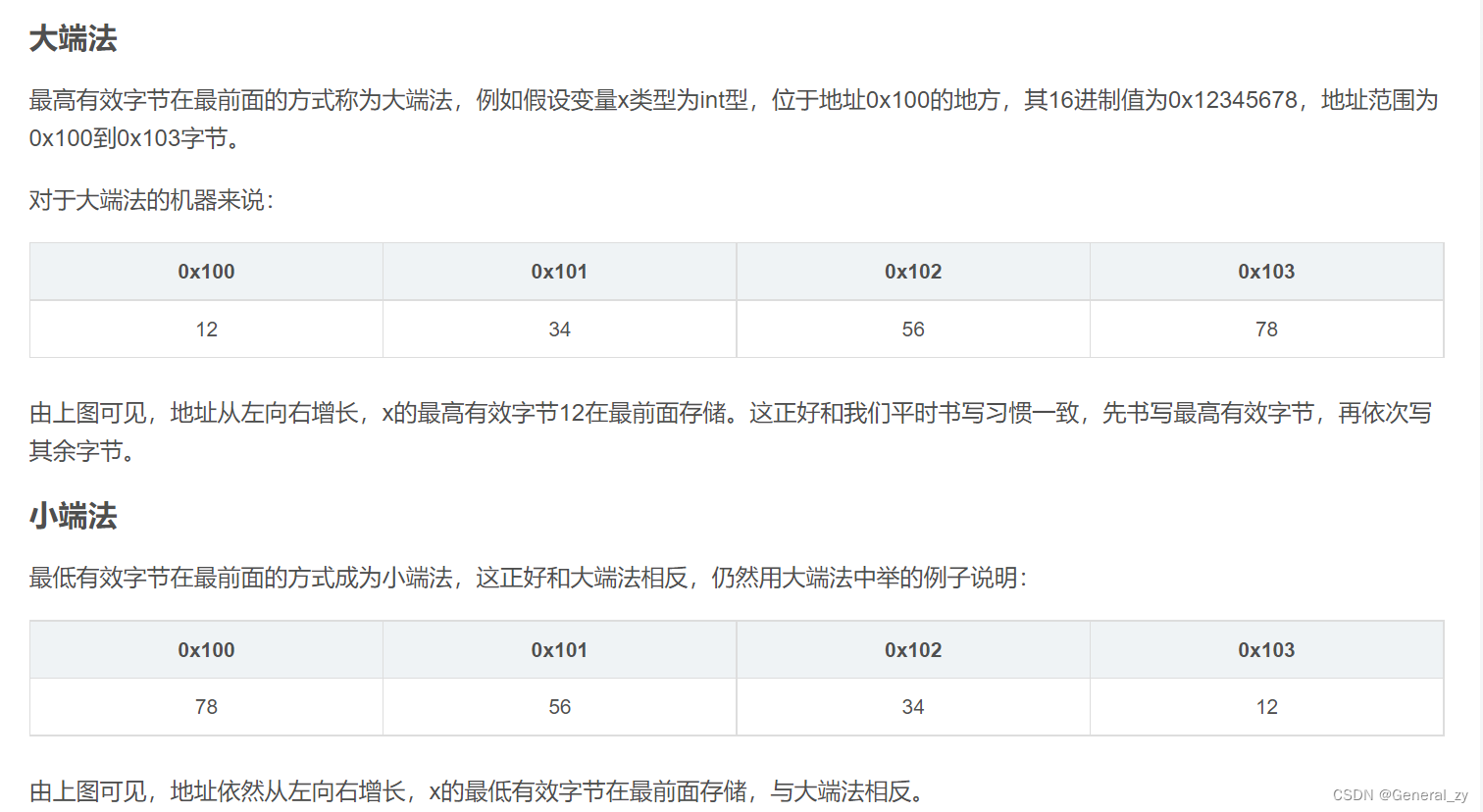
byteorder:
用于表示整数的字节顺序。如果字节顺序为“大端”,最高有效字节在最前面。如果字节顺序为“小端”,最低有效字节在最前面。要请求主机系统的本机字节顺序,请使用“sys.byteorder”作为字节顺序值。
-
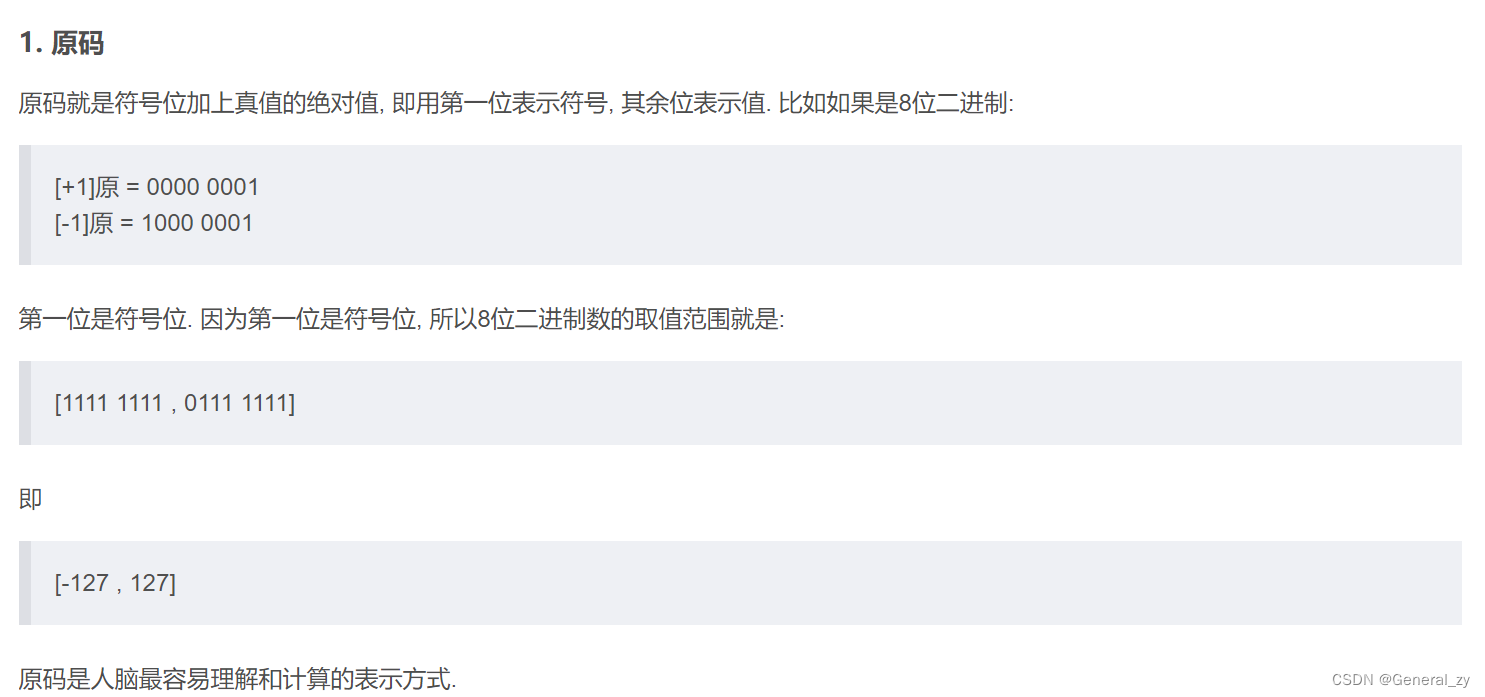
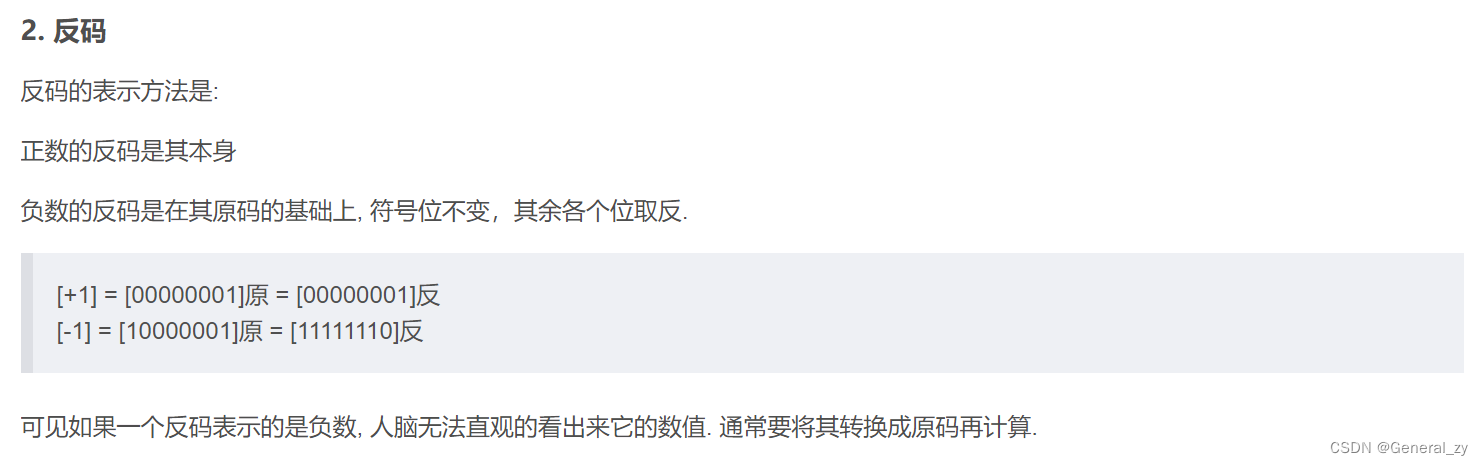
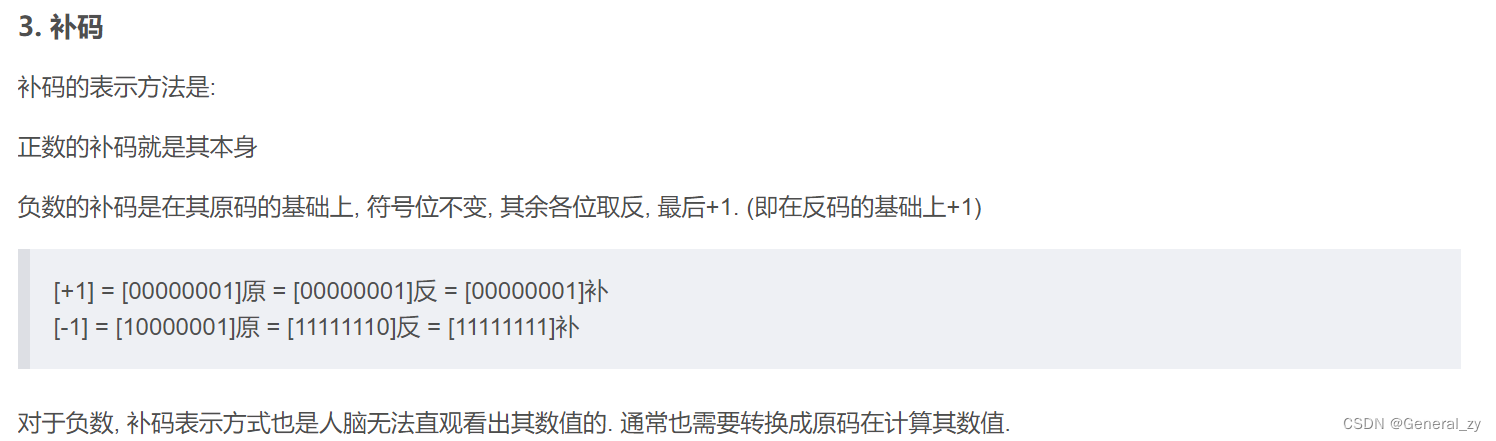
signed:(uint,int的区别)
确定是否使用二的补码来表示整数。如果有符号为False并且给定了负整数,则会引发OverflowError。
bytes()
num_array = [57, 18, 0, 0]
val = bytes(num_array)
print(type(val), val)
# <class 'bytes'> b'9\x12\x00\x00'
print(bytes([0x12,0x12]))
print(bytes([0x13]))
# b'\x12\x12'
# b'\x13'
struct.pack(fmt,number)
num = 4665
val = struct.pack("<I", num)
print(type(val), val)
#<class 'bytes'> b'9\x12\x00\x00'
| 参数 | 含义 |
|---|---|
| > | 大端序 |
| < | 小端序 |
| B | uint8类型 |
| b | int8类型 |
| H | uint16类型 |
| h | int16类型 |
| I | uint32类型 |
| i | int32类型 |
| L | uint64类型 |
| l | int64类型 |
| s | ascii码,s前带数字表示个数 |
bytes([]byte)转int
int.from_bytes()
bys = b'9\x12\x00\x00'
val = int.from_bytes(bys, byteorder='little', signed=False)
print(type(val), val)
#<class 'int'> 4665
struct.unpack()
bys = b'9\x12\x00\x00'
val = struct.unpack("<I", bys)
print(type(val), val)
#<class 'tuple'> (4665,)
string转bytes
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text.
//string是8位字节的所有字符串的集合,一般是这样但不是必然表示UTF-8编码文本。
type string string
encode()
res = "好好学习天天向上".encode("utf-8")
print(res, type(res))
----------------------------
b'\xe5\xa5\xbd\xe5\xa5\xbd\xe5\xad\xa6\xe4\xb9\xa0\xe5\xa4\xa9\xe5\xa4\xa9\xe5\x90\x91\xe4\xb8\x8a' <class 'bytes'>
bytes转string
decode()
略
特殊转换
bytes.fromhex()
十六进制字符串的二进制表示
res = bytes.fromhex("AF12")
print(type(res),res)
-----------------------------------
<class 'bytes'> b'\xaf\x12'
res = "B75285C190E907B8E41AC3BD1D8E8546002144AFEF7032B511C6"
data = binascii.unhexlify(res)
print(data, type(data))
# b'\xb7R\x85\xc1\x90\xe9\x07\xb8\xe4\x1a\xc3\xbd\x1d\x8e\x85F\x00!D\xaf\xefp2\xb5\x11\xc6' <class 'bytes'>
bytes.hex()
二进制的十六进制字符串表示。
b'\xe7\xbe\x8eqaq'.hex()
---------------------------------
b'\xe7\xbe\x8eqaq' => 'e7be8e716171'
bytesarray.fromhex()
16进制字符串转bytesarray
res = bytearray.fromhex("AF12")
print(res, type(res))
--------------------------------
bytearray(b'\xaf\x12') <class 'bytearray'>
for
bytes转16进制数组:0x是int类型
[hex(x) for x in b'\x01\x0212'] ==> ['0x1', '0x2', '0x31', '0x32']
bytes()
[]int转bytes
bytes([57, 18, 0, 0])
---------------------------------
[57, 18, 0, 0] => b'9\x12\x00\x00'
list()
bytesarray转[]int
res = list(bytearray.fromhex("AF12"))
print(res, type(res))
------------------------------------
[175, 18] <class 'list'>
binascii.b2a_hex()
二进制数据的十六进制表示。
binascii.b2a_hex(b'\xe7\xbe\x8eqaq')
------------------------------------------
b'\xe7\xbe\x8eqaq' => b'e7be8e716171'
binascii.a2b_hex()
十六进制表示的二进制数据。
binascii.a2b_hex(b'e7be8e716171')
----------------------------------------
b'e7be8e716171' => b'\xe7\xbe\x8eqaq'
cgo和cpython对比
func main() {
c:="好好学习天天向上"
fmt.Println([]byte(c))
fmt.Println([]rune(c))
for _,val:=range []byte(c){
fmt.Print(string(val),val," ")
}
}
-----------------------------------------------
[229 165 189 229 165 189 229 173 166 228 185 160 229 164 169 229 164 169 229 144 145 228 184 138]
[22909 22909 23398 20064 22825 22825 21521 19978]
// 乱码
å229 ¥165 ½189 å229 ¥165 ½189 å229 173 ¦166 ä228 ¹185 160 å229 ¤164 ©169 å229 ¤164 ©169 å229
c = "好好学习天天向上"
print(list(bytearray(c.encode("utf-8"))))
print([bytes(i, "utf-8").hex() for i in c])
--------------------------------------------------------------------
[229, 165, 189, 229, 165, 189, 229, 173, 166, 228, 185, 160, 229, 164, 169, 229, 164, 169, 229, 144, 145, 228, 184, 138]
['e5a5bd', 'e5a5bd', 'e5ada6', 'e4b9a0', 'e5a4a9', 'e5a4a9', 'e59091', 'e4b88a']





![[附源码]SSM计算机毕业设计基于的花店后台管理系统JAVA](https://img-blog.csdnimg.cn/d8ad966834bc4016960c63adf5ad82bf.png)

![[附源码]计算机毕业设计JAVA课后作业提交系统关键技术研究与系统实现](https://img-blog.csdnimg.cn/b9656591cae548028c70b0fd0b15f724.png)
![[附源码]计算机毕业设计JAVA课堂点名系统](https://img-blog.csdnimg.cn/3a015597afd94e18a2cda5488d2c7dc6.png)