Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
SPP提出的原因
1、现有的深度卷积神经网络(spp出现之前的)需要固定大小的输入图像(例如224×224)。往往需要对图片裁剪或者resize,导致图片信息损失或者产生几何畸变。这样可能会损害任意大小比例的图像或子图像的识别精度。

2、使用SPP-net,只从整个图像中计算一次特征映射,然后将特征集中到任意区域(子图像)中,生成固定长度的表示,用于训练检测器。解决了卷积神经网络对图相关重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
SPP 实现
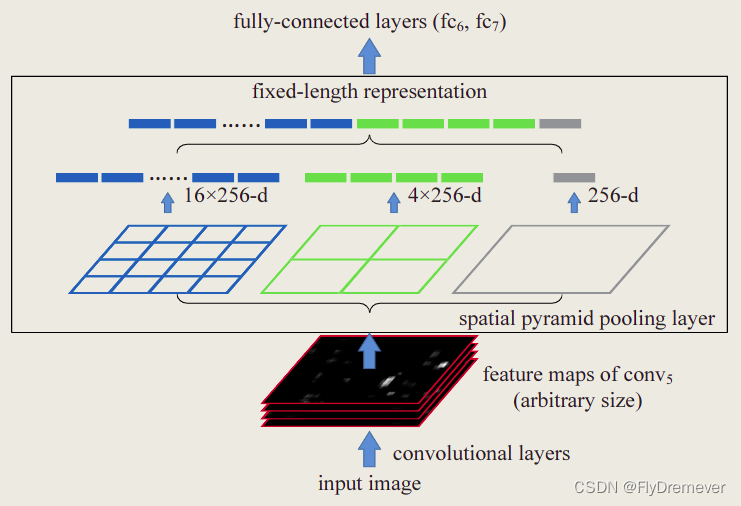
黑色图片代表卷积层之后的特征图,随后我们以不同大小的块来提取特征,分别是4*4,2*2,1*1,就可以得到16+4+1=21种不同的块(Spatial bins).我们从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。这种以不同的大小格子的组合方式来池化的过程就是空间金字塔池化(SPP)。 比如,要进行空间金字塔最大池化,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出单元,最终得到一个21维特征的输出。 输出向量大小为Mk,M=#bins(块数), k=#filters(卷积核个数),作为全连接层的输入。 例如上图,feature map是任意大小的,经过SPP之后,变成固定大小的输出了,以上图为例,共输出(16+4+1)*256的特征。(有256个卷积核)
pooling 参数的计算
[W,H]输入尺寸,
level 可以看做是金字塔的层级,在上面的示意图中产生了三个层级(1,2,4)
k
e
r
n
e
l
_
s
i
z
e
=
c
e
i
l
(
H
l
e
v
e
l
,
W
l
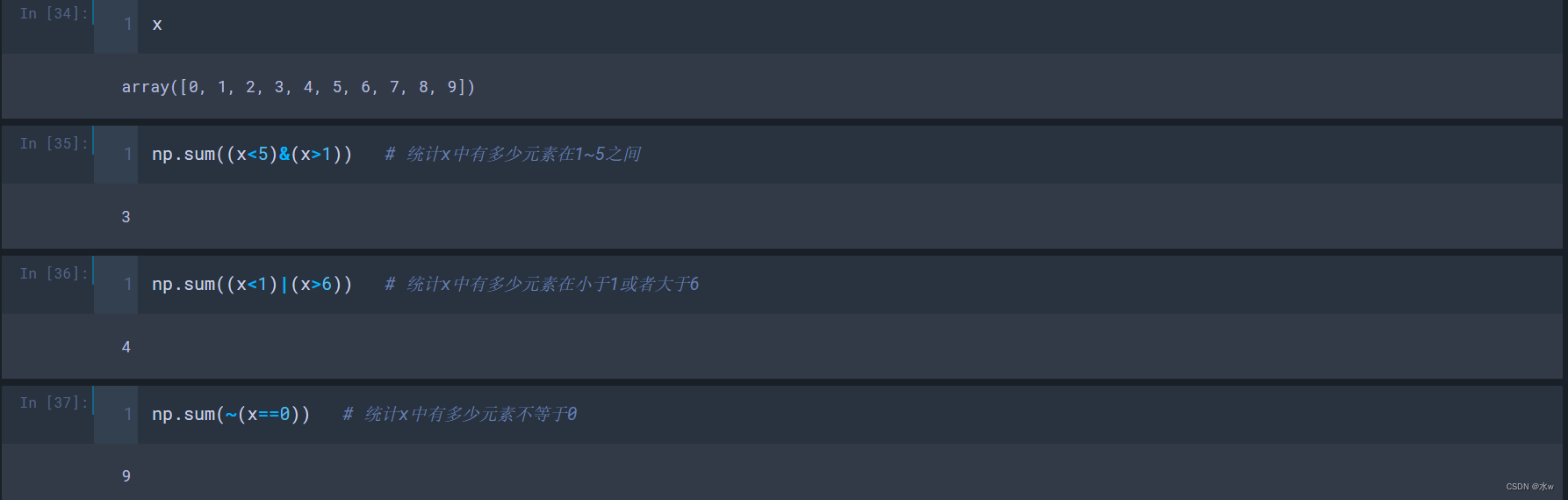
e
v
e
l
)
kernel\_ size=ceil(\frac{H}{level},\frac{W}{level})
kernel_size=ceil(levelH,levelW)
s t r i d e = c e i l ( H l e v e l , W l e v e l ) stride=ceil(\frac{H}{level},\frac{W}{level}) stride=ceil(levelH,levelW)
p a d d i n g = ( f l o o r ( ( k e r n e l _ s i z e ∗ l e v e l − H + 1 ) 2 ) , f l o o r ( ( k e r n e l _ s i z e ∗ l e v e l − W + 1 ) 2 ) padding = (floor(\frac{(kernel\_size * level - H + 1)}{2}), floor(\frac{(kernel\_size * level - W + 1)}{2}) padding=(floor(2(kernel_size∗level−H+1)),floor(2(kernel_size∗level−W+1))
参考代码
from math import floor, ceil
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatialPyramidPooling2d(nn.Module):
r"""apply spatial pyramid pooling over a 4d input(a mini-batch of 2d inputs
with additional channel dimension) as described in the paper
'Spatial Pyramid Pooling in deep convolutional Networks for visual recognition'
Args:
num_level:
pool_type: max_pool, avg_pool, Default:max_pool
By the way, the target output size is num_grid:
num_grid = 0
for i in range num_level:
num_grid += (i + 1) * (i + 1)
num_grid = num_grid * channels # channels is the channel dimension of input data
examples:
>>> input = torch.randn((1,3,32,32), dtype=torch.float32)
>>> net = torch.nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=3,stride=1),\
nn.ReLU(),\
SpatialPyramidPooling2d(num_level=2,pool_type='avg_pool'),\
nn.Linear(32 * (1*1 + 2*2), 10))
>>> output = net(input)
"""
def __init__(self, num_level, pool_type='max_pool'):
super(SpatialPyramidPooling2d, self).__init__()
self.num_level = num_level
self.pool_type = pool_type
def forward(self, x):
N, C, H, W = x.size()
for i in range(self.num_level):
level = i + 1
kernel_size = (ceil(H / level), ceil(W / level))
stride = (ceil(H / level), ceil(W / level))
padding = (floor((kernel_size[0] * level - H + 1) / 2), floor((kernel_size[1] * level - W + 1) / 2))
if self.pool_type == 'max_pool':
tensor = (F.max_pool2d(x, kernel_size=kernel_size, stride=stride, padding=padding)).view(N, -1)
else:
tensor = (F.avg_pool2d(x, kernel_size=kernel_size, stride=stride, padding=padding)).view(N, -1)
if i == 0:
res = tensor
else:
res = torch.cat((res, tensor), 1)
return res
def __repr__(self):
return self.__class__.__name__ + '(' \
+ 'num_level = ' + str(self.num_level) \
+ ', pool_type = ' + str(self.pool_type) + ')'
class SPPNet(nn.Module):
def __init__(self, num_level=3, pool_type='max_pool'):
super(SPPNet,self).__init__()
self.num_level = num_level
self.pool_type = pool_type
self.feature = nn.Sequential(nn.Conv2d(3,64,3),\
nn.ReLU(),\
nn.MaxPool2d(2),\
nn.Conv2d(64,64,3),\
nn.ReLU())
self.num_grid = self._cal_num_grids(num_level)
self.spp_layer = SpatialPyramidPooling2d(num_level)
self.linear = nn.Sequential(nn.Linear(self.num_grid * 64, 512),\
nn.Linear(512, 10))
def _cal_num_grids(self, level):
count = 0
for i in range(level):
count += (i + 1) * (i + 1)
return count
def forward(self, x):
x = self.feature(x)
x = self.spp_layer(x)
print(x.size())
x = self.linear(x)
return x
if __name__ == '__main__':
a = torch.rand((1,3,128,128))
net = SPPNet()
output = net(a)
print(output)
我们注意到SPP对于深度cnn有几个spatial:
- SPP能够产生固定长度的输出,而不管输入大小,而在以前的深度网络中使用的滑动窗口池化不能;
- SPP使用多级
spatial bin,而滑动窗口池只使用单一窗口大小。多级池已被证明更具有鲁棒性; - 由于输入尺度的灵活性,SPP可以将不同尺度提取的特征集合在一起。实验表明,这些因素都提高了深度网络的识别精度
其它特点
- 由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变(scale-invariance)和降低了过拟合(over-fitting)
- 实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛(convergence)
- SPP 对于特定的CNN网络设计和结构是独立的。(也就是说,只要把SPP放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层)
- 不仅可以用于图像分类而且可以用来目标检测





![[附源码]SSM计算机毕业设计基于的花店后台管理系统JAVA](https://img-blog.csdnimg.cn/d8ad966834bc4016960c63adf5ad82bf.png)

![[附源码]计算机毕业设计JAVA课后作业提交系统关键技术研究与系统实现](https://img-blog.csdnimg.cn/b9656591cae548028c70b0fd0b15f724.png)
![[附源码]计算机毕业设计JAVA课堂点名系统](https://img-blog.csdnimg.cn/3a015597afd94e18a2cda5488d2c7dc6.png)