课程地址:数据库 SQLServer 视频教程全集(99P)| 22 小时从入门到精通_哔哩哔哩_bilibili

目录
identity(主键自动增长,用户不需要为identity修饰的主键赋值)
用法
如何重新设置identity字段的值
如何向identity字段插入数据
视图
为什么需要视图 —— 简化查询
例子
总结
什么是视图
视图的格式
视图的优点
视图的缺点
注意的问题
事务
初学者必须要掌握的三个问题
事务是用来研究什么的
事务和线程的关系
事务和第三方插件的关系
大纲
为什么需要事务
什么是事务
如何创建事务
事务三种运行模式
自动提交事务
显式事务
隐性事务
总结事务的四大特性
原子性
一致性
隔离性
持久性
注意问题
代码示例
后期数据库内容概述
索引
存储过程
触发器
游标
TL_SQL(流程控制)
总复习
重点:数据库是如何解决数据存储问题的
查询
事务
identity(主键自动增长,用户不需要为identity修饰的主键赋值)
主键通常为代理主键(无实际含义,整型数字),一般不使用有业务含义的字段充当主键
create table student2(
student_id int primary key,
student_name nvarchar(200) not null
)
insert into student2 values (1,'张三')
insert into student2 values (2,'李四')
insert into student2 values (1,'张三') -- error,主键不允许重复
insert into student2 values ('张三') -- error,主键不允许省略
insert into student2(student_name) values ('张三') -- error,把编号student_id当主键时,必须得为它赋值
用法
identity表示该字段的值会自动更新,不需要我们维护,通常情况下我们不可以直接给 identity 修饰的字符赋值,否则编译时会报错
语法格式为:
- identity [ (m,n) ]
- m表示的是初始值,n表示的是每次自动增加的值
- 要么同时指定m和n的值,要么m和n都不指定,不能只写其中一个值。如:identity(3,2)、identity都是正确的,但是identity(3)、identity(2)、identity()都是错误的
- 如果m和n都未指定,则取默认值(1,1)
数据类型是整型的列才能被定义成标识列
- int、bigint、smallint列都可以被定义成identity
- 不含有小数位的 decimal 和 numeric 也可以被标记为identity,如:decimal、decimal(6,0) 字段都可以被标记为identity,但是 decimal(6,2) 字段就不能被标记为identity
标识列通常与 primary key 约束一起用作表的唯一行标识符
- 非主键也是可以被定义为identity的,但不推荐
例子:
- identity默认从1开始,每次递增1
- 若写成 identity(100, 5),表示从100开始,每次递增5
create table student3(
student_id int primary key identity(100,5),
student_name nvarchar(200) not null
)
insert into student3(student_name) values ('张三') -- student_id为100
insert into student3 values ('李四') -- OK,student_id为105
select * from student3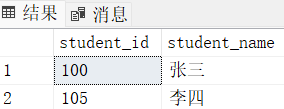
delete from student3 where student_name = '李四'
insert into student3(student_name) values ('王五') -- student_id为110
select * from student3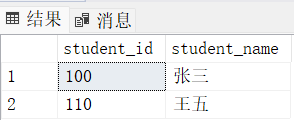
总结:
- 用户如何手动给被 identity 修饰的主键赋值——不重要
- 表中删除数据又插入数据会导致主键不连续递增——不重要,主键即便不连续递增,也是可以的(主键是否连续增长不是十分重要)
如何重新设置identity字段的值
如果对表中数据进行了删除操作,如何让identity字段重新从某个值开始自增?
dbcc checkident('表名', reseed, identity字段的初始值)
dbcc checkident('表名', reseed, 0)
-- 种子的值也可以是0,这样设置的话,用户插入值时,种子的初始值将从1开始例子:
create table emp(
empid int identity(1,1),
ename nvarchar(20) not null
)
insert into emp values ('aaaa')
insert into emp values ('bbbb')
insert into emp values ('cccc')
insert into emp values ('dddd') -- 9行
select * from emp
delete from emp where empid = 4 -- 删除empid为4的记录
select * from emp
insert into emp values ('eeee') -- 因为执行9行时empid为4,所以执行本语句时empid为5
select * from emp
delete from emp where empid = 5
dbcc checkident('emp',reseed,3) -- 20行(把emp表中identity字段的初始值重新设置为3)
insert into emp values ('eeee') -- 此时插入记录时,empid为4,因为20行代码已经把empid设置成了3
select * from emp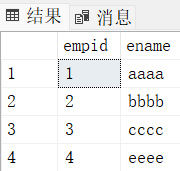
如何向identity字段插入数据
通常identity标记的字段,我们是不需要插入数据的,即我们不需要维护identity字段的值,它会自动更新。如果我们需要向identity修饰的字段插入值,则必须满足如下两点:
- 先得执行
set identity_insert [database.[owner.]] {table} {on|off}- 插入数据时必须得指定identity修饰的字段的名字
create database Example
use Example
create table dept(
deptid decimal(6,0) identity,
deptname varchar(20)
)
set identity_insert Example.dbo.dept on
-- 执行本语句的目的是:希望可以向identity修饰的字段插入值
-- 不可以改为 set identity_insert dept on
-- 不可以改为 set identity_insert dbo.Example.dept on
-- 不可以改为 set identity_insert dbo.Example.dept.on
insert into dept(deptid, deptname) values (1,'zhangsan')
-- 不能改为 insert into dept values (1,'zhangsan')
select * from dept视图
为什么需要视图 —— 简化查询
例子
求出平均工资最高的部门的编号和部门的平均工资
top 只有 SQL Server 里才有,MySQL和Oracle里没有这种用法
select deptno, avg(sal) "avg_sal" from emp
group by deptno -- 临时表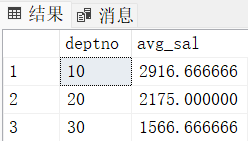
写法1:
select * from (
select deptno, avg(sal) "avg_sal" from emp
group by deptno -- 临时表
) T
where T.avg_sal = (
select max(E.avg_sal) from (select deptno, avg(sal) "avg_sal" from emp group by deptno) E -- 临时表
)
写法2:创建视图
create view v$_emp_1
as
select deptno, avg(sal) "avg_sal"
from emp
group by deptno -- 临时表
select * from v$_emp_1 -- 视图可以当做一个临时表
select * from v$_emp_1
where avg_sal = (select max(avg_sal) from v$_emp_1)总结
方便简化查询,避免了代码的冗余,避免书写大量重复的SQL语句
什么是视图
- 从代码上看,视图是个select语句
- 逻辑上,视图被当做一个虚拟表看待
视图的格式
create view 视图的名字
as
-- select前面不能添加begin
select语句
-- select后面不能添加end 视图的优点
- 简化查询
- 增加数据的保密性(如隐藏工资列)
如隐藏emp表的工作年份和工资两列
create view v$_emp_2
as
select empno, ename, job, mgr, comm, deptno
from emp
select * from v$_emp_2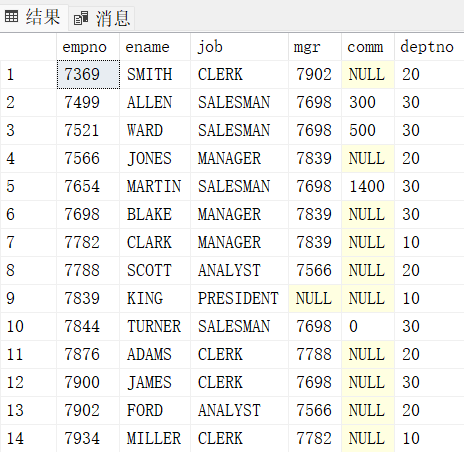
视图的缺点
- 增加了数据库维护的成本(在SQL Server中,若删除了原始表,不会自动删除依附在原始表上的视图;若已经删除了原始表,但没有删除相应的视图,在使用视图时会报错)
- 视图只是简化了查询,并不能加快查询的速度,这也是视图使用不足的地方
注意的问题
- 创建视图的select语句必须得为所有的计算列指定别名
-- error create view v$_a as select avg(sal) from emp -- ok create view v$_a as select avg(sal) as "avg_sal" from emp - 视图不是物理表,是虚拟表
- 不建议通过视图更新视图所依附的原始表的数据或结果
不使用分组,但使用了聚合函数时,默认把所有记录当做一组
事务
初学者必须要掌握的三个问题
事务是用来研究什么的
- 避免数据处于不合理的中间状态:如转账
- 怎样避免多用户同时访问(并发访问)时不出错,即呈现给用户的数据是合理的:很复杂,现在仍然没有很好的解决办法(同时只允许一个用户访问,可以解决,但效率低)
事务和线程的关系
- 事务也是通过锁来解决很多问题的
- 线程同步就是通过锁来解决的 synchronized
悲观锁、乐观锁...
谁访问谁上锁,会导致其他用户不能访问
脏读、串行化...
事务和第三方插件的关系
- 直接使用数据库技术的难度很大,很多人是借助第三方插件来实现,因此我们一般人不需要细细地研究数据库中事务的语法细节
- 第三方插件要想完成预期的功能,一般必须得借助数据库中的事务机制来实现(不同数据库的事务机制不同)
大纲
- 为什么需要事务
- 什么是事务
- 怎样使用事务
- 怎样使用事务来保证避免数据处于一种不合理的中间状态
- 怎样使用事务来实现多个用户对共享资源的同时访问
为什么需要事务
事务主要用来保证数据的合理性和并发处理的能力。通俗点说:
- 事务可以保证避免数据处于一种不合理的中间状态
- 利用事务可以实现多个用户对共享资源的同时访问
例子:
- 银行中的转账操作:账户A把一定数量的款项转到账户B上,这个操作包括两个步骤。一个是从账户A上把存款减去一定数量,二是在账户B上把存款加上相同的数量。这两个步骤显然要么都完成,要么都取消,否则银行就会受损失。显然,这个转账操作中的两个步骤就构成一个事务
- 假设A和B用户都希望查询修改M表数据,A用户不应该刚把M表的数据改成5,查询时显示的数据却是8(因为B用户修改M表的数据成8了)。事务必须得保证多个用户对共享资源同时访问时,数据库给用户的反应是合理的
什么是事务
一系列操作要么全都执行成功,要么全部执行失败,这就是事务
如何创建事务
T-SQL使用下列语句来管理事务:
- 开始事务:Begin Transaction
- 提交事务:Commit Transaction(事务里的所有操作必须彻底生效。try里写操作,任一操作出错都会抛出异常)
- 回滚(撤销)事务:Rollback Transaction(catch里写撤销)
一旦事务提交或回滚,则事务结束
默认任何一个语句就是一个事务,必须显式地开启一个事务后才能提交或回滚
执行之前开启,执行之后结束(默认)
Oracle有的语句一写完就提交,有的不是;而SQL Server都是一写完就提交
判断某条语句执行是否出错:
- 使用全局变量 @@Error
- @@Error 只能判断当前一条T-SQL语句执行是否有错,为了判断事务中所有T-SQL是否有错,我们需要对错误进行累计,如:
SET @errorSum = @errorSum + @@error -- @ 用户变量 -- @@ 系统变量
事务三种运行模式
自动提交事务
每条单独的语句都是一个事务。如果成功执行,则自动提交;如果错误,则自动回滚(默认模式)
显式事务
每个事务均以 begin transaction 语句显式开始,以 commit 或 rollback 语句显式结束
隐性事务
在前一个事务完成时,新事务隐式启动,但每个事务仍以 commit 或 rollback 语句结束
总结事务的四大特性
事务必须具备以下四个属性,简称ACID属性
原子性
事务是一个完整的操作。事务的各步操作是不可分的(原子的),要么都执行,要么都不执行
一致性
当事务完成时,数据必须处于一致状态,要么处于开始状态,要么处于结束状态,不允许出现中间状态
隔离性
指当前的事务与其他未完成的事务是隔离的。在不同的隔离级别下,事务的读取操作,可以得到的结果是不同的
持久性
事务完成后,它对数据库的修改被永久保持,事务日志能够保持事务的永久性
注意问题
- 不能在 SQL server 中单独使用commit、rollback 语句
delete from dept2 where deptno = 50
commit -- error
rollback -- error- 事务重在理解概念,如果不是数据库DBA,初学者对事务的语法细节不需要深究
代码示例
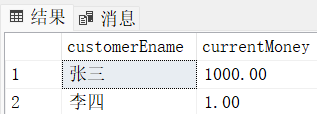
create table bank(
customerEname nvarchar(200),
currentMoney money
)
insert into bank values ('张三',1000)
insert into bank values ('李四',1)
alter table bank add constraint check_currentMoney check(currentMoney >= 1)
select * from bank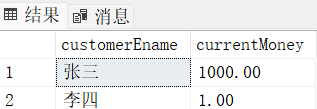
-- 张三要给李四转账1000元
-- 则张三账户余额为1000-1000=0 < 1(不符合要求)
-- 李四账户余额为1+1000=1001
-- 理应转账失败
没有事务时:
update bank set currentMoney = currentMoney-1000 where customerEname = '张三'
update bank set currentMoney = currentMoney+1000 where customerEname = '李四'
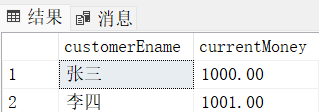
这显然不合理
有事务时:
begin transaction
declare @errorSum int
set @errorSum = 0
update bank set currentMoney = currentMoney-1000 where customerEname = '张三'
set @errorSum = @errorSum + @@ERROR
update bank set currentMoney = currentMoney+1000 where customerEname = '李四'
set @errorSum = @errorSum + @@ERROR
if (@errorSum<>0)
begin
print '转账失败'
rollback transaction
end
else
begin
print '转账成功'
commit transaction
end
后期数据库内容概述
索引
类似字典的目录,可以加快查询速度(视图只能简化查询,不能加快查询速度)。但若索引建立的不合理,反而会降低查询的速度
- 如何合理建索引
- 聚合索引、唯一索引、组合索引、单列索引...
- SQL优化内容
存储过程
触发器
当对一个表执行增删改查操作时,会自动触发另外一些语句的执行(主要是为了完成一些约束功能)
游标
对处理结果集分情况处理,对多行数据按单行方式做操作
TL_SQL(流程控制)
数据库语言(第四代语言,命令,不需要考虑内部实现,但由于无for循环或if语句,功能弱)
- 库内部语言实现:安全、速度快;换个库功能就不能移植了
- 库里数据调入内存,由网络发送到服务器,服务器里的Java语言实现,处理完再把数据回写入库:效率低、安全性低;跨平台性强(jdbc)、简单
TL_SQL是一个含有流程控制,只能用在SQL Server中的编程语言
总复习
重点:数据库是如何解决数据存储问题的
字段、表、记录、属性、列、元素、约束、关系、主键、外键、check、default、unique、not null、触发器
查询
distinct、内连接、视图...