作者:马海琴 编辑:毕小烦
三. 磁盘
磁盘是可以持久化存储的设备,根据存储介质的不同,常见磁盘可以分为两类:机械磁盘和固态磁盘。磁盘就像人的大脑皮层,负责数据的储存、记忆。
磁盘对于服务器来说十分重要,一旦出现服务器磁盘空间不足,就有可能导致服务器部署的服务异常甚至宕机。
1. 分析磁盘异常
1.1 分析磁盘占用率较高的问题
STEP 1. 用 df 查看系统磁盘的使用情况
我们关注其中数据块/dev/mapper/vg00-lvroot的使用。当磁盘占用率过高的时候,需要分析占用是否正常,如果是正常的那就需要增加磁盘大小;如果是不正常的,那么就需要进一步分析是哪里引起的异常。

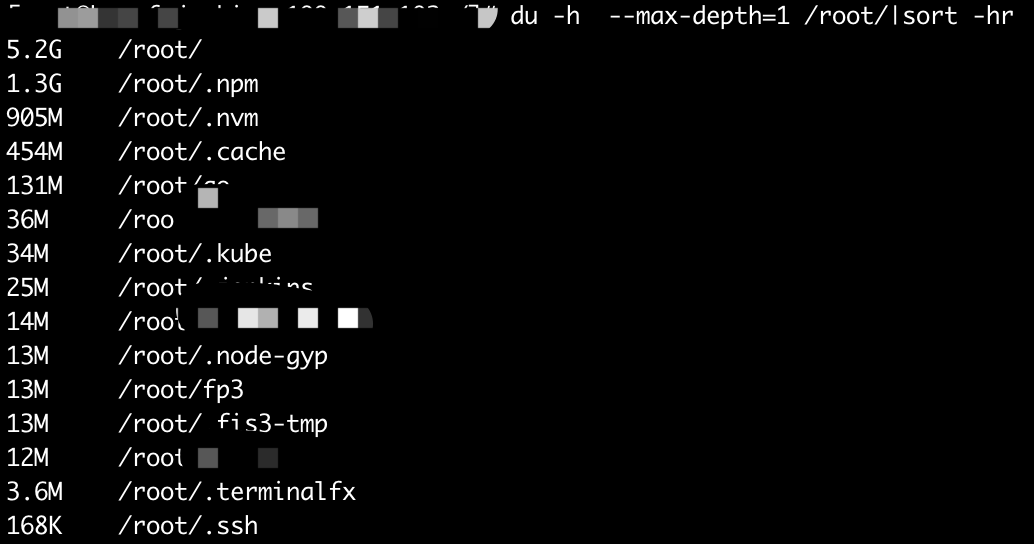
STEP 2. 用 du 查找大文件
通过 du 命令,逐步查找最大文件。找到引起异常的文件,基本就能够锁定的问题的所在。
1.2. 分析系统 I/O 较高的问题
STEP 1. 用 top 查看 wa 占用率
当我们通过 top 命令发现 **wa** 占用率逐渐升高时,说明系统 I/O 存在压力。
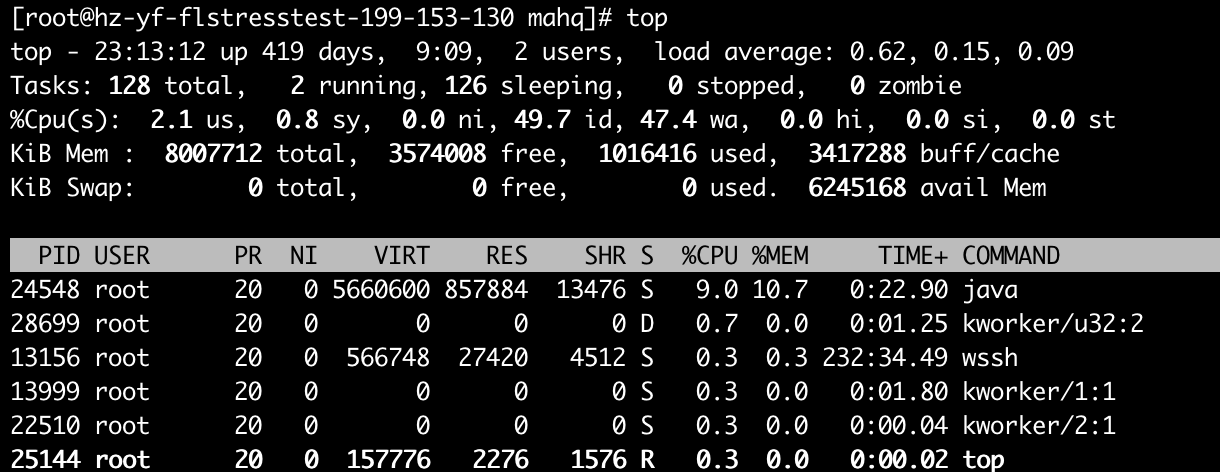
STEP 2. 用 iostat 查看磁盘繁忙程度
我们发现 await 远远高于 svctm,说明 IO 等待队列较长,磁盘十分繁忙;而 w_await 远高于 r_await,说明是磁盘写入造成的磁盘繁忙。
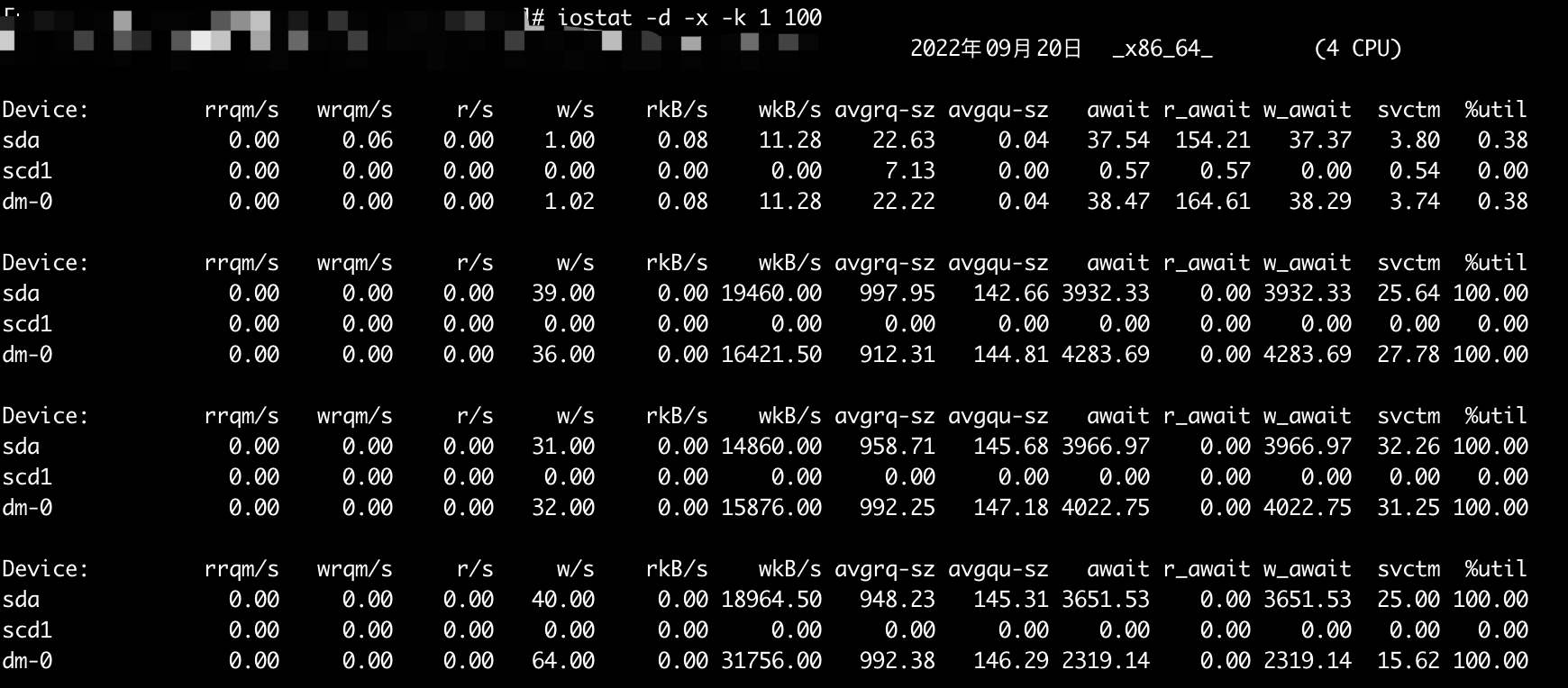
STEP 3. 用 pidstat 查看各进程 IO 使用情况
通过pidstat -d 1 显示各个进程的 IO 使用情况,发现 3046 这个进程的写入的速度较快。
STEP 4. 用 strace 查看系统调用过程
通过strace -p pid 发现一直在执行数据写入的操作。

STEP 5. 用 lsof 查找正在进行读写操作的文件
通过lsof -p pid 发现文件 test.txt 的写入量很大。

根据出现问题的进程和定位的文件名称,我们再结合源码分析,最后定位出现问题的地方,如果代码无法优化,那就需要考虑提升磁盘的性能。
2. 命令详解
df 命令
通过df命令可以查看服务器磁盘的使用情况。
命令格式:
df [-][ahHikmlPTtx][--block-size=<区块大小>][--no-sync][--sync][文件或设备]
参数解释:
a:代表包含全部的文件系统。h:以可读性较高的方式来显示信息。H:与-h参数相同,但在计算时是以 1000 Bytes 为换算单位而非1024 Bytes。i:显示inode的信息。k:以KB为单位显示容量,默认以KB为单位(即指定区块大小为 1024 字节)。m:以MB为单位显示容量,默认以MB为单位(即指定区块大小为 1048576 字节)。l:仅显示本地端的文件系统。P:使用POSIX的输出格式。T:显示文件系统的类型。t:等价于--type=TYPE,仅显示指定文件系统类型的磁盘信息。x:等价于--exclude-type=TYPE,不要显示指定文件系统类型的磁盘信息。block-size:以指定的区块大小来显示区块数目。no-sync:在取得磁盘使用信息前,不要执行sync指令,此为预设值。sync:在取得磁盘使用信息前,先执行sync指令。
如:
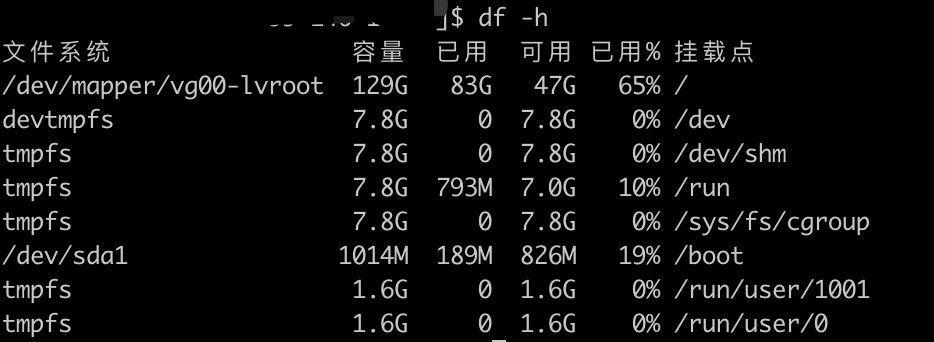
结果说明:
-
系统文件(Files``ystem):表示文件系统位于哪个分区,展示文件系统名称。
-
- 其中
tmpfs是一个临时文件系统,驻留在内存中,读写非常快,可以提供较高的访问速度。
- 其中
-
容量(
Size):文件系统总容量。 -
已用(
Used):文件系统已使用的容量。 -
可用(
Avail):文件系统空闲的容量。 -
可用%(
Use%):文件系统空闲容量占比。 -
挂载点(
Mounted on):文件系统的挂载点。
du 命令
通过du命令查看具体目录下的文件/目录占用空间大小。
命令格式:
du [-abcDhHklmsSx][-L <符号连接>][-X <文件>][--block-size][--exclude=<目录或文件>][--max-depth=<目录层数>][目录或文件]
参数解释:
-a:显示目录中个别文件的大小、-b:显示目录或文件大小时,以byte为单位、-c:除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和、-D:显示指定符号连接的源文件大小、-h:以 K,M,G 为单位,提高信息的可读性、-H:与-h参数相同,但是 K,M,G 是以 1000 为换算单位。-k:以 1024 bytes 为单位。-l:重复计算硬件连接的文件。-L<符号连接>:显示选项中所指定符号连接的源文件大小。-m:以 1MB 为单位。-s:仅显示总计,常用du -sh *统计当前目录下所有一级目录/文件的总用量。-S:显示个别目录的大小时,并不含其子目录的大小。-x:以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。-X<文件>:在 <文件> 指定目录或文件。--exclude=<目录或文件>: 略过指定的目录或文件。--max-depth=<目录层数>: 超过指定层数的目录后,予以忽略。
如:
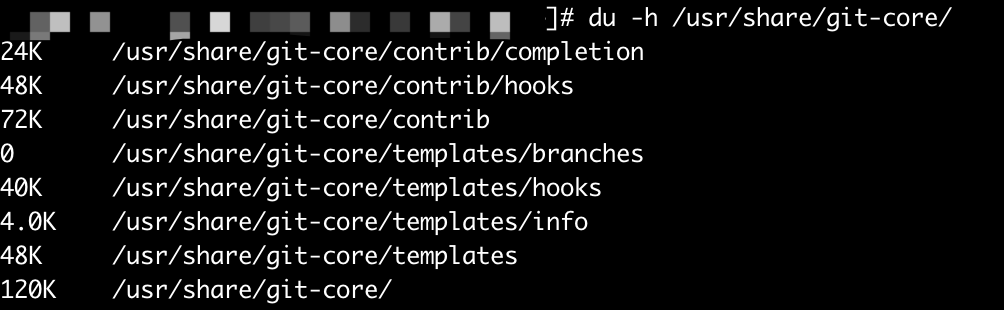
iostat 命令
使用iostat可以监控磁盘的使用情况,通过这个命令可以看出磁盘是否繁忙。
如:
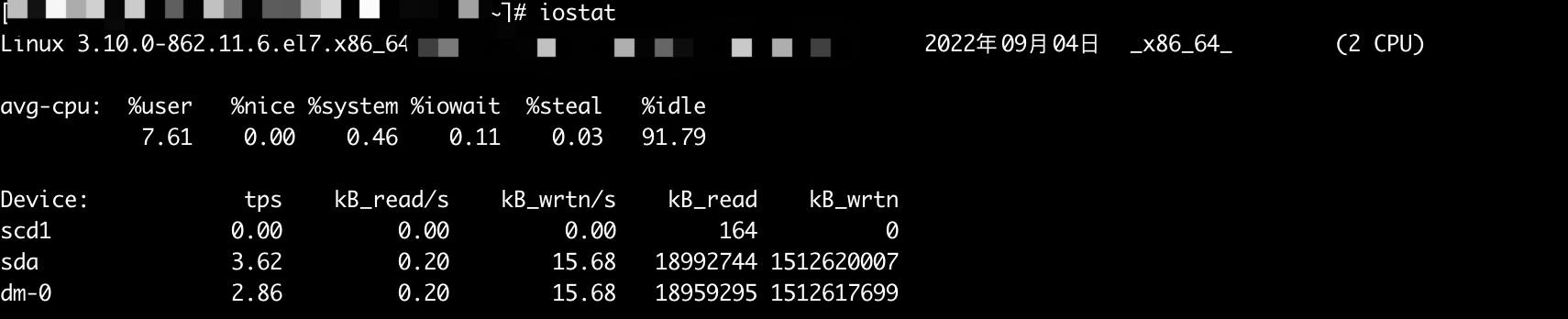
结果说明:
avg-cpu 段:
%user:在用户级别运行所使用的 CPU 的百分比%nice:nice操作所使用的 CPU 的百分比%sys:在系统级别(kernel)运行所使用 CPU 的百分比%iowait:CPU 等待硬件 I/O 时,所占用 CPU 百分比%idle:CPU 空闲时间的百分比
Device 段:
tps:每秒钟发送到的 I/O 请求数Blk_read /s:每秒读取的 block 数Blk_wrtn/s:每秒写入的 block 数Blk_read:读入的 block 总数Blk_wrtn:写入的 block 总数
展示所有磁盘的使用状态
iostat -d -k 1 10打印所有磁盘的使用状态,每秒钟打印一次,打印十次之后结束。
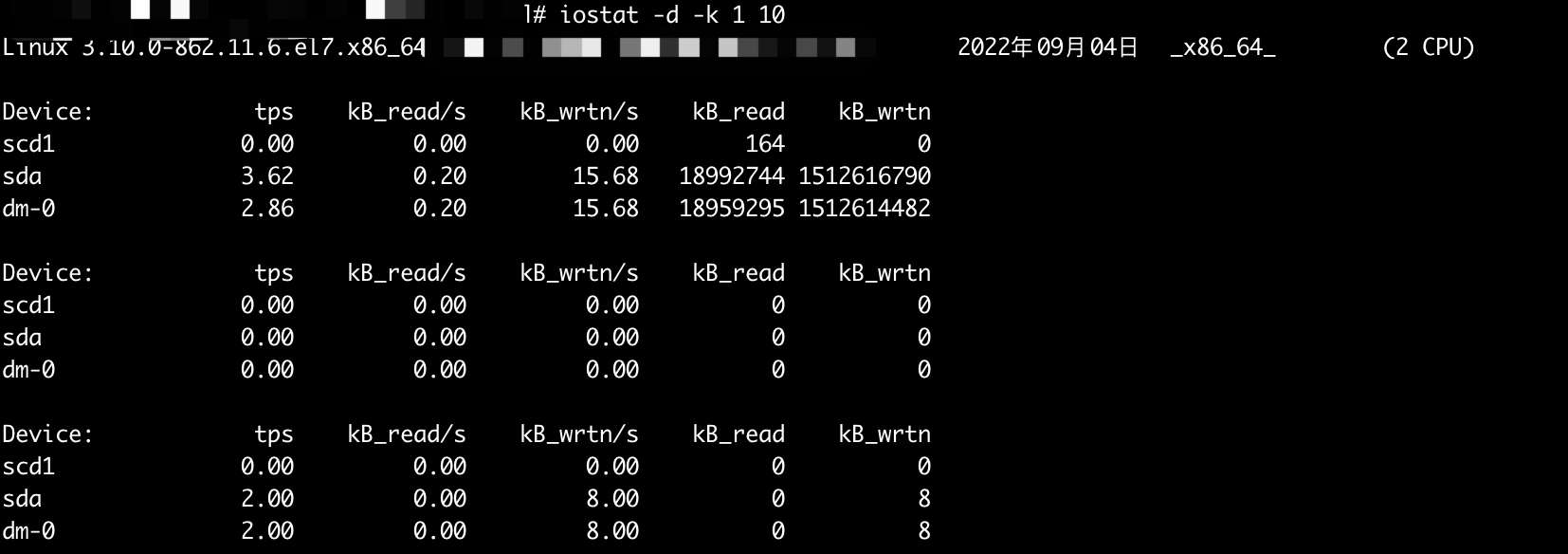
结果说明:
tps:该设备每秒的传输次数。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。kB_read/s:每秒从设备(drive expressed)读取的数据量kB_wrtn/s:每秒向设备(drive expressed)写入的数据量kB_read:读取的总数据量kB_wrtn:写入的总数量数据量
以上结果的单位都为 KB。
IO 相关扩展信息展示
iostat -d -x -k 1 10打印磁盘扩展信息,每秒钟打印一次,打印十次之后结束。
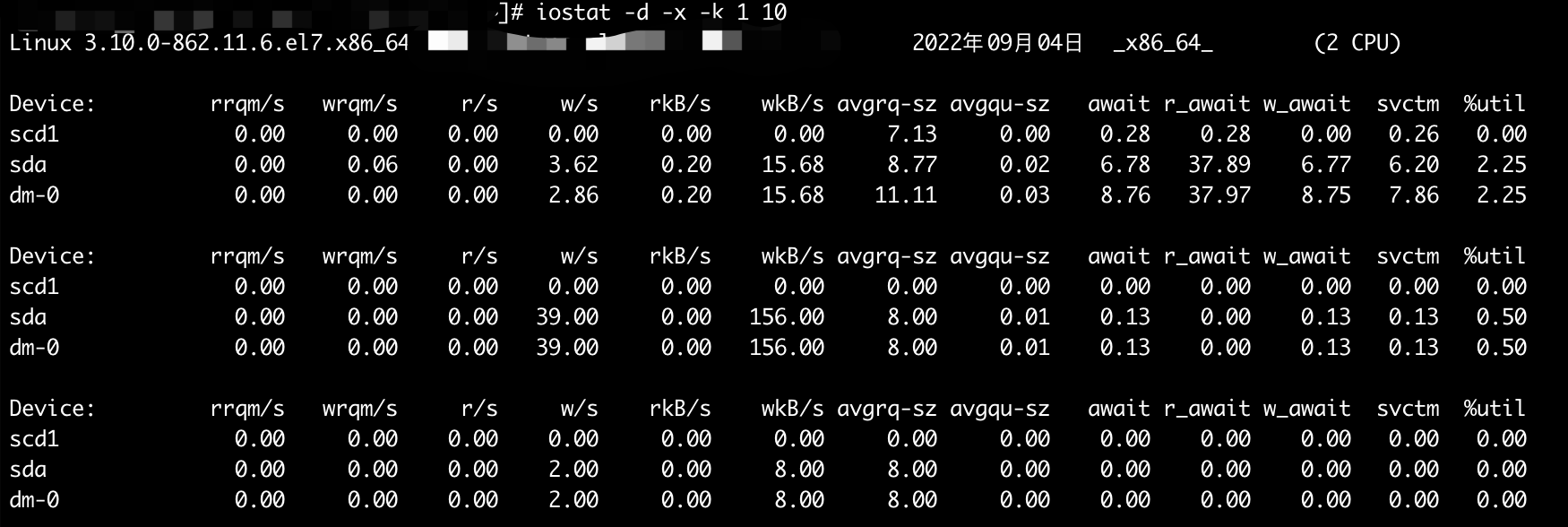
结果说明:
-
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge)。 -
wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。 -
r/s:每秒读取的扇区数。 -
w/s:每秒写入的扇区数。 -
rkB/s:每秒向设备发出的读取请求的数量。 -
wkB/s:每秒向设备发出的写入请求的数量。 -
avgrq-sz:平均请求扇区的大小。 -
avgqu-sz:是平均请求队列的长度。队列长度越短,说明性能越好。 -
await:每一个I/O请求的处理的平均时间(单位是毫秒)。 -
- 这里可以理解为
IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。 - 这个时间包括了队列时间和服务时间。一般情况下,
await大于svctm,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果**await**的值远高于**svctm**的值,则表示**I/O**队列等待太长,系统上运行的应用程序将变慢。
- 这里可以理解为
-
r_await:每一个读取请求的处理的平均时间。 -
w_await:每一个写入请求的处理的平均时间。 -
svctm:表示平均每次设备I/O操作的服务时间(以毫秒为单位)。 -
%util: 在统计时间内所有处理 IO 时间,除以总共统计时间。 -
- 如果统计间隔
1秒,该设备有0.7秒在处理IO,而0.3秒闲置,那么该设备的%util = 0.7/1 = 70%。所以该参数暗示了设备的繁忙程度。 - 一般地,如果
**%util**是**100%**表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
- 如果统计间隔
(完)
如果文章对你有帮助,记得留言、点赞、加关注哦!








![[附源码]java毕业设计学生宿舍设备报修](https://img-blog.csdnimg.cn/4f8df232298447a4949ce589f0438632.png)