前言
SENet,胡杰(Momenta)在2017.9提出,通过显式地建模卷积特征通道之间的相互依赖性来提高网络的表示能力,即,通道维度上的注意力机制。SE块以微小的计算成本为现有的最先进的深层架构产生了显著的性能改进,SENet block和ResNeXt结合在ILSVRC 2017赢得第一名。
论文下载链接:
https://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper.pdf
一、简介
(1)提出背景:卷积核通常被看做是在局部感受野上,在空间上和通道维度上同时对信息进行相乘求和的计算。现有网络很多都是主要在空间维度方面来进行特征的融合(如Inception的多尺度)。
(2)通道维度的注意力机制:在常规的卷积操作中,输入信息的每个通道进行计算后的结果会进行求和输出,这时每个通道的重要程度是相同的。而通道维度的注意力机制,则通过学习的方式来自动获取到每个特征通道的重要程度(即feature map层的权重),以增强有用的通道特征,抑制不重要的通道特征。
(3)说起卷积对通道信息的处理,有人或许会想到逐点卷积,即kernel大小为1X1的常规卷积。与1X1卷积相比,SENet是为每个channel重新分配一个权重(即重要程度)。而1X1卷积只是在做channel的融合计算,顺带进行升维和降维,也就是说每个channel在计算时的重要程度是相同的。
二、SE模块
Squeeze:
顺着空间维度来压缩特征,就是在空间上做全局平均池化,每个通道上特征的空间维度从二维变成了一个scale,这个标量某种程度上具有全局的感受野。并且输出的维度和输入的通道数相匹配。用全局平均池化是因为scale是对整个通道作用的,利用的是通道间的相关性,要屏蔽掉空间分布相关性的干扰。
Excitation:
用2个全连接来实现 ,第一个全连接把C个通道压缩成了 C/ratio 个通道来降低计算量(后面跟了RELU,增加非线性能力),ratio是指压缩的比例一般取r=16;第二个全连接再恢复回C个通道(后面跟了Sigmoid函数将值归一化到0~1,这样就可以表示重要程度),Sigmoid后得到权重 s。s就是U中C个feature map的权重,通过训练的参数 w 来为每个特征通道生成权重s,其中参数 w 被学习用来显式地建模特征通道间的相关性。用全连接是因为全连接层可以融合全局池化后各通道的feature map信息。
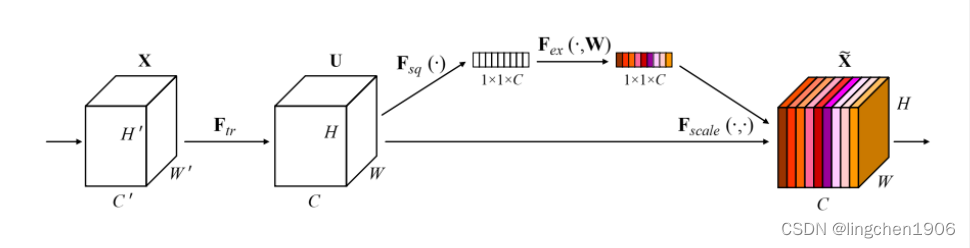
详细流程说明:
(1)X经过一系列传统卷积得到U,对U先做一个Global Average Pooling ,输出的1x1xC数据 (即,上图梯形短边的白色向量),这个特征向量一定程度上可以代表之前的输入信息,论文中称之为Squeeze操作。
(2)再经过两个全连接来学习通道间的重要性 ,用sigmoid限制到[0, 1]的范围,这时得到的输出可以看作每个通道重要程度的权重(即上图梯形短边的彩色向量),论文中称之为Excitation操作。
(3)最后,把这个1x1xC的权重乘到U的C个通道上,这时就根据权重对U的channles进行了重要程度的重新分配。
三、效果
SE 模块可以嵌入到现在几乎所有的网络结构中,而且都可以得到不错的效果提升,用过的都说好。
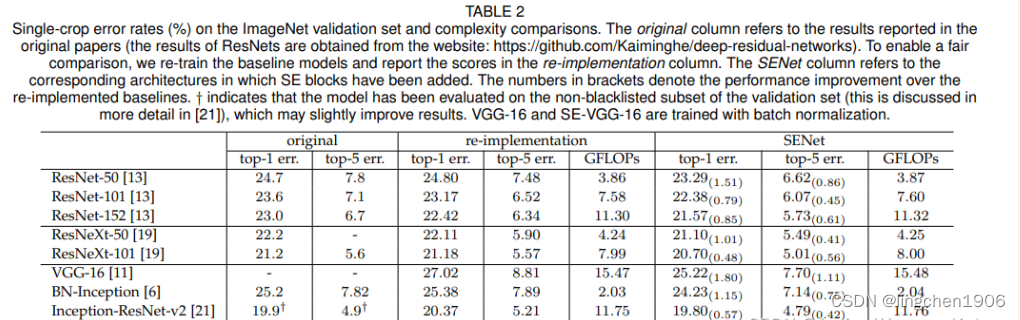
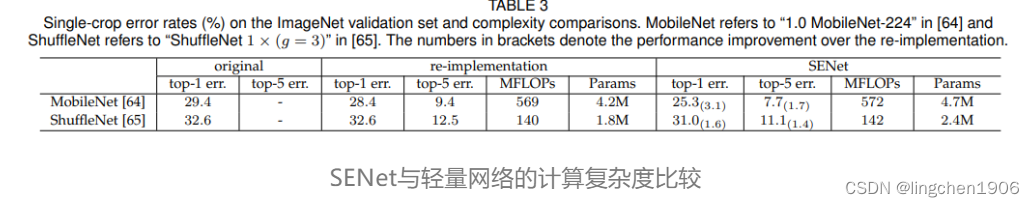
在大部分模型中嵌入SENet要比非SENet的准确率更高出1%左右,而计算复杂度上只是略微有提升,具体如下图所示。 而且SE块会使训练和收敛更容易。CPU推断时间的基准测试:224×224的输入图像,ResNet-50 164ms,SE-ResNet-50 167ms。
四、代码
这里给出模型搭建的python代码(基于pytorch实现)。
class SqueezeExcitation(nn.Module):
def __init__(self, pervious_layer_channels, scale_channels=None, scale_ratio=4):
super().__init__()
if scale_channels is None:
scale_channels = pervious_layer_channels
# assert input_channels > 16, 'input channels too small, Squeeze-Excitation is not necessary'
squeeze_channels = make_divisible8(scale_channels//scale_ratio, 8)
self.fc1 = nn.Conv2d(pervious_layer_channels, squeeze_channels, kernel_size=1, padding=0)
self.fc2 = nn.Conv2d(squeeze_channels, pervious_layer_channels, kernel_size=1, padding=0)
def forward(self, x):
weight = F.adaptive_avg_pool2d(x, output_size=(1,1))
weight = self.fc1(weight)
weight = F.relu(weight, True)
weight = self.fc2(weight)
weight = F.hardsigmoid(weight, True)
return weight * x
五、总结
SE block 可以理解为 channel维度上的注意力机制(即重分配通道上feature map对后续计算的权重),与Stochastic Depth Net一样,本论文的贡献更像一种思想,而非模型。 在之后的模型中,会经常看见SE block的身影。例如,SKNet,MobileNet等等。




![[附源码]java毕业设计学生宿舍设备报修](https://img-blog.csdnimg.cn/4f8df232298447a4949ce589f0438632.png)