Flink
- 状态管理
- 状态的分类
- Flink容错机制
- State Vs CheckPoint
- CheckPoint原理
- State状态后端/State存储介质
- 状态恢复和重启策略
- SavePoint
- Flink TableAPI&SQL
- 案例
- 广播流
状态管理


状态的分类
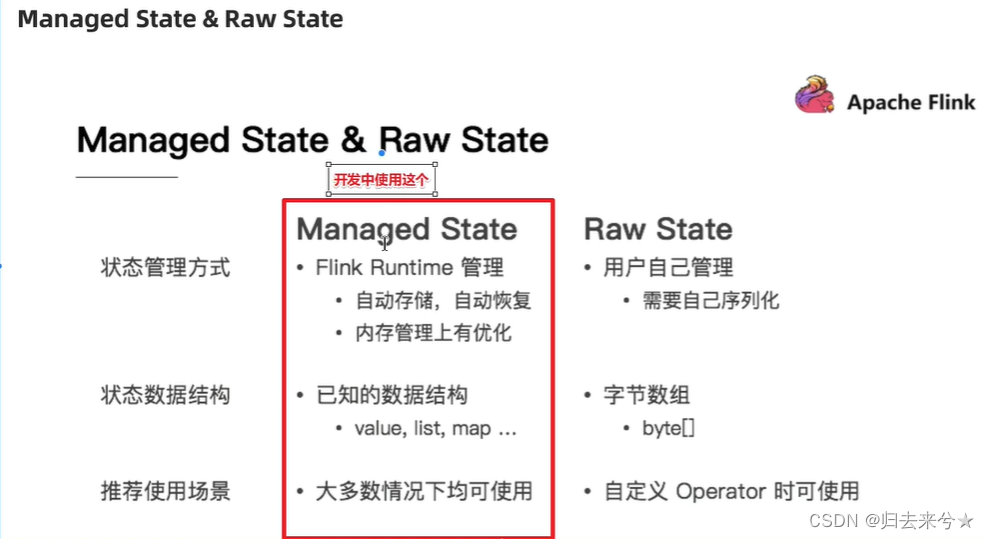

- State
- ManagerState–开发中推荐使用:Flink自动管理/优化,支持多种数据结构
- KeyState–只能在keyedStream上使用,支持多种数据结构
- OperatorState–一般用在Source上,支持ListState
- RawState–完全有用户自己管理,只支持byte[],只能在自定义Operator上使用
- OperatorState
- ManagerState–开发中推荐使用:Flink自动管理/优化,支持多种数据结构
KeyState案例
public class KeyStateDemo {
/**
* 使用KeyState中得ValueState获取数据中的最大值(实际中直接使用maxBy即可)
* 编码步骤;
* 1. 定义一个状态用来存放最大值
* private transient ValueState<Long> maxValueState;
* 2. 创建一个状态描述对象
* ValueStateDescriptor descriptor = new ValueStateDescriptor(“maxValueState”,Long.class)
* 3. 根据状态描述符获取State
* maxValueState = getRuntimeContext().getState(maxValueStateDescriptor)
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Tuple2<String, Integer>> tupleDs = env.fromElements(
Tuple2.of("北京", 3),
Tuple2.of("上海", 6),
Tuple2.of("北京", 8),
Tuple2.of("重庆", 9),
Tuple2.of("天津", 6),
Tuple2.of("北京", 3),
Tuple2.of("上海", 22)
);
// 开发使用
SingleOutputStreamOperator<Tuple2<String, Integer>> result1 = tupleDs.keyBy(t -> t.f0).maxBy(1);
SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> result2 = tupleDs.keyBy(t -> t.f0).map(new RichMapFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>>() {
//1 定义一个状态用来存放最大值
private ValueState<Integer> maxValueState;
// 初始化状态
@Override
public void open(Configuration parameters) throws Exception {
// 2 创建状态描述器
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("maxValueState", Integer.class);
// 3 根据状态描述器获取/初始化状态
maxValueState = getRuntimeContext().getState(stateDescriptor);
}
// 使用状态
@Override
public Tuple3<String, Integer, Integer> map(Tuple2<String, Integer> value) throws Exception {
Integer currentValue = value.f1;
Integer historyValue = maxValueState.value();
if (historyValue == null || currentValue > historyValue) {
historyValue = currentValue;
maxValueState.update(historyValue);
return Tuple3.of(value.f0, currentValue, historyValue);
} else {
maxValueState.update(historyValue);
return Tuple3.of(value.f0, currentValue, historyValue);
}
}
});
result1.print();
result2.printToErr();
env.execute();
}
}
模拟KafkaSource 功力不够,先简单熟悉
public class OperateStateDemo {
/**
* 需求 使用ListState存储offset-->模拟kafka的offset
*
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// TODO Source
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1); // 设置并行度为1
// CheckPoint和重启策略,先照抄
env.enableCheckpointing(1000); // 每隔1s执行一次Checkpoint
env.setStateBackend(new FsStateBackend("file:///F:/ckp"));
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 固定延迟重启策略:程序出现异常的时候,重启两次,每次延迟3秒重启,超过2次程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(2, 3000));
// TODO Source
DataStreamSource<String> ds = env.addSource(new MyKafkaSource()).setParallelism(1);
// TODO Transformation
// TODO Sink
ds.print();
env.execute();
}
// s使用Operator中得ListState模拟KafkaSource进行offset维护
public static class MyKafkaSource extends RichParallelSourceFunction<String> implements CheckpointedFunction {
// 1 声明ListState
private ListState<Long> offsetState = null;
private Long offset = 0L;
private Boolean flag = true;
// 2 初始化/创建ListState
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Long> stateDescriptor = new ListStateDescriptor<>("offsetState", Long.class);
offsetState = context.getOperatorStateStore().getListState(stateDescriptor);
}
//3 使用state
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (flag) {
Iterator<Long> iterator = offsetState.get().iterator();
if (iterator.hasNext()) {
offset = iterator.next();
}
offset += 1;
int subtaskId = getRuntimeContext().getIndexOfThisSubtask();
ctx.collect("subTaskId " + subtaskId + ", 当前offset值为 " + offset);
Thread.sleep(1000);
if (offset % 5 == 0) {
throw new RuntimeException("bug 出现了");
}
}
}
// 4 state 持久化
// 该方法会定时执行将state状态从内存持久化到Checkpoint磁盘目录
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
offsetState.clear();// 清理磁盘数据并存入Checkpoint磁盘目录中
offsetState.add(offset);
}
@Override
public void cancel() {
flag = false;
}
}
}
Flink容错机制
State Vs CheckPoint
- State
维护/存储 的是一个Operator的运行状态/历史值,是维护在内存中
一般指一个具体的Operator的状态(operator的状态表示一些算子在运行过程中会产生一些历史结果,如前面的maxBy底层会维护当前的最大值,也就是会维护一个keyedOperator,这个State里面存放就是maxBy这个Operator中得最大值)
State数据默认保存子java 的堆内存中/TaksManager节点上
State可以被记录,在失败的情况下数据还可以恢复 - CheckPoint
某一时刻,Flink中的所有的Operator的当前State的全局快照,一般存在磁盘上
表示了一个Flink Job在一个特定时刻的一份全局状态快照,即包含了所有Operator的状态
可以理解为CheckPoint是把State数据定时持久化存储了
比如KafkaConsumer算子中维护的Offset状态,当任务重新恢复的时候可以从Checkpoint中获取
CheckPoint原理
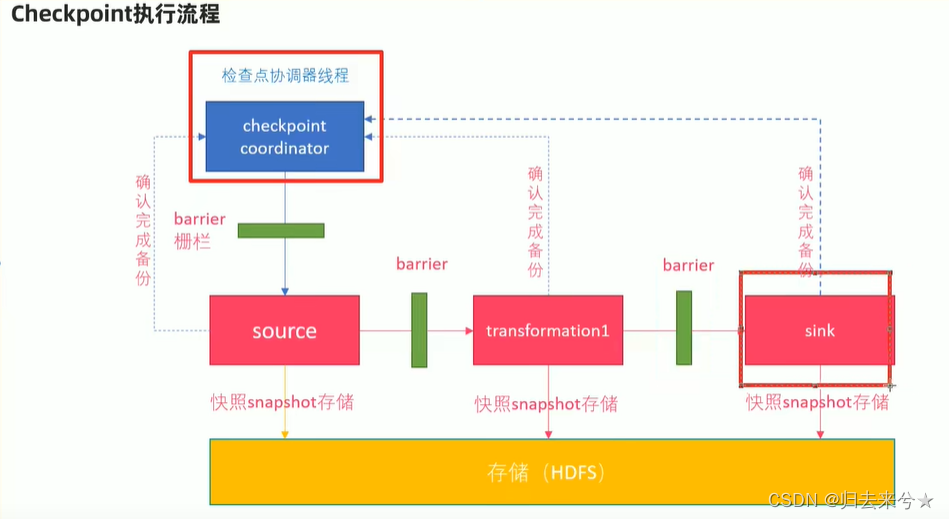
0. Flink的JobManager创建CheckpointCoordinator
- Coordinator向所有的SourceOperator发送Barrier栅栏(理解未执行Checkpoint的信号)
- SourceOperator接收到Barrier之后,暂停当前的操作(暂停的时间很短,因为后续的写快照是异步的),并制定State快照,然后将自己的快照保存到指定的介质中(如HDFS),一切ok之后向Coordinator汇报并将Barrier发送给下游的其他Operator
- 其他的 如TransformationOperation接收到Barrier,重复第2步,最后将Barrier发送给sink
- Sink接收到Barrier之后重复第2步
- Coordinator接收到所有的Operator的执行ok的汇报结果,认为本次快照执行成功
State状态后端/State存储介质
注意:
前面学习了Checkpoint其实就是Flink中某一时刻,所有的Operator的全局快照,
那么快照存储存储的地方叫做 状态后端



使用RocksDB引入依赖


状态恢复和重启策略
重启策略分类
-
默认重启策略
配置了Checkpoint的情况下不做任务配置:默认无限重启并自动恢复,可以解决小问题,但可能会隐藏真正的bug -
无重启策略
有bug立即抛出
env.setrestartStrategy(RestartStrategies.noRestart()) -
固定延迟重启策略(开发中使用)
job 失败,重启3次,每次间隔5s
env.setRestartStrategy(RestartStrategies.fixeDelayRestart(
3,// 最多重启次数
Time.of(5,TimeUnit.SECONDS)
))
- 失败重启策略(开发偶尔使用)
如果5分钟job失败不超过3次,自动重启,每次重启间隔3s
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3,
Time.of(5,TimeUnit.MINUTES),
Time.of(3,TimeUnit.SECONDS)
))
手动重启
基于flink 浏览器客户端
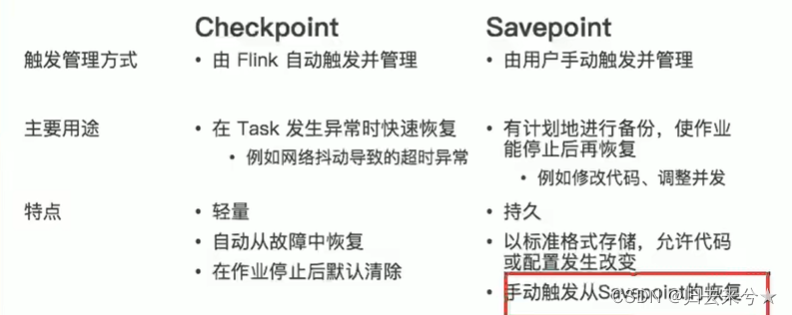
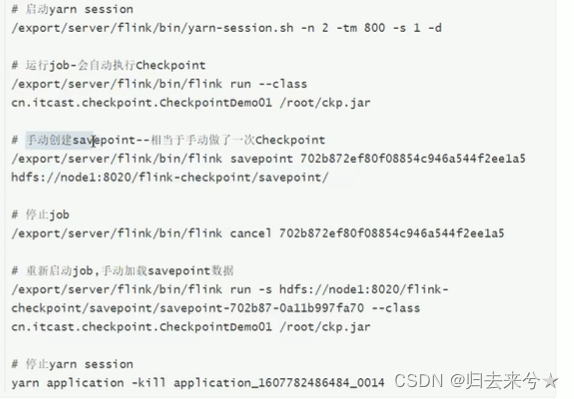
SavePoint
Flink TableAPI&SQL

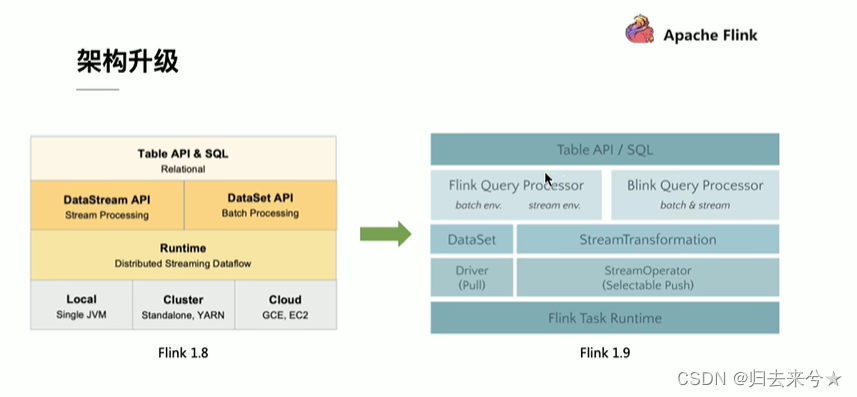
1.11 开始,默认使用Blink
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
案例
依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>Flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>Flink-demo</name>
<url>http://maven.apache.org</url>
<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
public class SqlDemo1 {
public static void main(String[] args) throws Exception {
demo3();
}
/**
* 将DataStream数据转Table和View然后使用Sql进行统计查询
*
* @throws Exception
*/
public static void demo1() throws Exception {
// TODO env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
// TODO source
DataStreamSource<Order> orderA = env.fromElements(
new Order(1L, "beer", 3),
new Order(1L, "diaper", 4),
new Order(3L, "rubber", 2),
new Order(3L, "ali", 3),
new Order(1L, "tom", 4)
);
DataStreamSource<Order> orderB = env.fromElements(
new Order(1L, "beer", 3),
new Order(1L, "diaper", 4),
new Order(3L, "rubber", 2),
new Order(3L, "ali", 3),
new Order(1L, "tom", 4)
);
// TODO transform 转化table 和 view
Table tableA = tenv.fromDataStream(orderA, $("user"), $("product"), $("amount"));
tableA.printSchema();
System.out.println(tableA);
tenv.createTemporaryView("tableB", orderB, $("user"), $("product"), $("amount"));
String sql = "select * from " + tableA + " where amount > 2 union select * from tableB where amount > 1";
Table resultTable = tenv.sqlQuery(sql);
resultTable.printSchema();
System.out.println(resultTable);
// 将table 转为dataStream
// 将计算后的数据append到结果DataStream中去
// DataStream<Order> resultDS = tenv.toAppendStream(resultTable, Order.class);
// 将计算后的性的数据在DataStream元数据的基础上更新true或是删除false
DataStream<Tuple2<Boolean, Order>> resultDS = tenv.toRetractStream(resultTable, Order.class);
resultDS.print();
// TODO exe
env.execute();
}
/**
* 使用SQL和Table两种方式做WordCount
*
* @throws Exception
*/
public static void demo2() throws Exception {
// TODO env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
// TODO source
DataStreamSource<WC> wordsDs = env.fromElements(
new WC("hello", 1L),
new WC("word", 1L),
new WC("hello", 1L)
);
/* tenv.createTemporaryView("t_words",wordsDs,$("word"),$("frequency"));
String sql = "select word,sum(frequency) as frequency from t_words group by word";
Table table = tenv.sqlQuery(sql);
DataStream<Tuple2<Boolean, WC>> ds = tenv.toRetractStream(table, WC.class);
ds.print();*/
/* Table table = tenv.fromDataStream(wordsDs, $("word"), $("frequency"));
String sql = "select word,sum(frequency) as frequency from "+table+" group by word";
Table table1 = tenv.sqlQuery(sql);
DataStream<Tuple2<Boolean, WC>> ds = tenv.toRetractStream(table1, WC.class);
ds.print();*/
Table table = tenv.fromDataStream(wordsDs, $("word"), $("frequency"));
Table select = table.groupBy($("word"))
.select($("word"), $("frequency").sum().as("frequency"));
DataStream<Tuple2<Boolean, Row>> ds = tenv.toRetractStream(select, Row.class);
ds.print();
// TODO exe
env.execute();
}
/**
* 使用Flink SQL来统计5秒内 每个用户的 订单数、订单的最大金额、订单的最小金额
* <p>
* 也就是每隔5s统计最近5s的每隔用户的订单总数,订单的最大金额,订单的最小金额
* <p>
* WaterMarker+时间时间+窗口 : SQL 实现
*
* @throws Exception
*/
public static void demo3() throws Exception {
// TODO env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
DataStreamSource<TOrder> ds = env.addSource(new RichSourceFunction<TOrder>() {
private Boolean flag = true;
@Override
public void run(SourceContext<TOrder> sourceContext) throws Exception {
Random random = new Random();
SimpleDateFormat df = new SimpleDateFormat("HH:mm:ss");
while (flag) {
String orderId = UUID.randomUUID().toString();
int userId = random.nextInt(2);
int money = random.nextInt(101);
long eventTime = System.currentTimeMillis() - random.nextInt(5) * 1000;
TOrder tOrder = new TOrder(orderId, userId, money, eventTime, df.format(new Date(eventTime)));
sourceContext.collect(tOrder);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
});
SingleOutputStreamOperator<TOrder> wDS = ds.assignTimestampsAndWatermarks(
WatermarkStrategy.<TOrder>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((o, l) -> o.eventTime)
);
tenv.createTemporaryView("t_order", wDS, $("orderId"), $("userId"), $("money"), $("eventTime").rowtime(), $("timeString"));
String sql = "select userId,count(orderId) as orderCount,max(money) as maxMoney,min(money) as minMoney from t_order " +
"group by userId,tumble(eventTime,INTERVAL '5' SECOND)";
Table table = tenv.sqlQuery(sql);
DataStream<Tuple2<Boolean, Row>> rDS = tenv.toRetractStream(table, Row.class);
rDS.print();
// TODO exe
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class TOrder {
public String orderId;
public Integer userId;
public Integer money;
public Long eventTime;
public String timeString;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class WC {
public String word;
public Long frequency;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Order {
private Long user;
private String product;
private Integer amount;
}
}
FlinkSql 直连 kafka
public class SqlKafka {
/**
* flink SQL直接读写kafka
* {"user_id":"1","page_id":"1","status":"success"}
* {"user_id":"1","page_id":"1","status":"success"}
* {"user_id":"1","page_id":"1","status":"success"}
* {"user_id":"1","page_id":"1","status":"fail"}
* @param args
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
String inputSQL = "CREATE TABLE input_kafka (`user_id` BIGINT,`page_id` BIGINT,`status` STRING ) " +
"with (" +
"'connector'='kafka','topic'='input_kafka','properties.bootstrap.servers'='hadoop102:9092', " +
"'properties.group_id'='testGroup','scan.startup.mode'='latest-offset','format'='json')";
TableResult inputTable = tenv.executeSql(
inputSQL
);
// TODO Transformation
String sql = "select * from input_kafka where status='success'";
Table etl = tenv.sqlQuery(sql);
// tenv.toRetractStream(etl, Row.class ).print();
// TODO Sink
TableResult outputTable= tenv.executeSql(
"CREATE TABLE output_kafka (`user_id` BIGINT,`page_id` BIGINT,`status` STRING )" +
"with (" +
"'connector'='kafka','topic'='input_kafka','properties.bootstrap.servers'='hadoop102:9092'," +
"'sink.partitioner'='round-robin','format'='json')"
);
tenv.executeSql("insert into output_kafka select * from "+etl);
env.execute();
}
}
双十一大屏


import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.lang.time.FastDateFormat;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.ContinuousProcessingTimeTrigger;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.text.SimpleDateFormat;
import java.util.List;
import java.util.PriorityQueue;
import java.util.Random;
import java.util.stream.Collectors;
public class BigScreemDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, Double>> orderDS = env.addSource(new MySource());
// TODO transform--:初步聚合:每隔1s聚合一下各个分类的销售总额
SingleOutputStreamOperator<CategoryPojo> tempAggResult = orderDS.keyBy(t -> t.f0)
// 窗口从当前时间的 00:00:00开始
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8)))
// 自定义触发时机 :每隔1秒触发
.trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(1)))
// 简单聚合
// .sum()
// 自定义聚合
.aggregate(new PriceAggregate(), new WindowResult());
tempAggResult.keyBy(CategoryPojo::getDateTime)
.window(TumblingProcessingTimeWindows.of(Time.seconds(1)))
.process(new FinalResultWindowProcess());
env.execute();
}
private static class PriceAggregate implements AggregateFunction<Tuple2<String, Double>, Double, Double> {
// 初始化累加器
@Override
public Double createAccumulator() {
return 0D;
}
// 把数据累加到累加器上
@Override
public Double add(Tuple2<String, Double> value, Double accumulator) {
return value.f1 + accumulator;
}
// 获取累加结果
@Override
public Double getResult(Double accumulator) {
return accumulator;
}
// 合并各个Subtask结果
@Override
public Double merge(Double a, Double b) {
return a + b;
}
}
// 自定义窗口函数,指定窗口数据手机规则
private static class WindowResult implements WindowFunction<Double, CategoryPojo, String, TimeWindow> {
private FastDateFormat df = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@Override
public void apply(String category, TimeWindow window, Iterable<Double> input, Collector<CategoryPojo> out) throws Exception {
long currentTimeMillis = System.currentTimeMillis();
String dateTime = df.format(currentTimeMillis);
Double totalPrice = input.iterator().next();
out.collect(new CategoryPojo(category, totalPrice, dateTime));
}
}
private static class FinalResultWindowProcess extends ProcessWindowFunction<CategoryPojo, Object, String, TimeWindow> {
/**
* 下面的Key/dataTime表示当前这1s的时间
* elements:表示截止到当前这1s各个分类的销售总额
*
* @param dataTime
* @param context
* @param elements
* @param out
* @throws Exception
*/
@Override
public void process(String dataTime,
ProcessWindowFunction<CategoryPojo, Object, String, TimeWindow>.Context context,
Iterable<CategoryPojo> elements,
Collector<Object> out) throws Exception {
// // 1 实时计算当前0点截止到当前时间的销售总额
double total = 0D; // 用来记录销售总额
// 创建小顶锥
PriorityQueue<CategoryPojo> queue = new PriorityQueue<>(
3,// 初始容量
// 正常排序,就是小的在前,大的在后,也就是c1>c2的时候返回1,也就是升序,也就是小顶锥
(c1, c2) -> c1.getTotalPrice() >= c2.getTotalPrice() ? 1 : -1
);
for (CategoryPojo element : elements) {
Double price = element.getTotalPrice();
total += price;
if (queue.size() < 3) {
queue.add(element);
} else {
if (price >= queue.peek().getTotalPrice()) {
queue.poll();
queue.add(element);
}
}
}
List<String> top3List = queue.stream()
.sorted((c1, c2) -> c1.getTotalPrice() >= c2.getTotalPrice() ? -1 : 1)
.map(c -> "分类:" + c.getTotalPrice() + " 金额: " + c.getTotalPrice())
.collect(Collectors.toList());
// 每秒更新
double roundResult = new BigDecimal(total).setScale(2, RoundingMode.HALF_UP).doubleValue();
System.out.println("时间: " + dataTime + " 总金额:" + roundResult);
System.out.println("top3 : \n" + StringUtils.join(top3List, "\n"));
}
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class CategoryPojo {
private String category; // 分类名称
private Double totalPrice; // 该分类销售总额
private String dateTime; // 截止当前时间的时间,本来应该是EventTime,这里使用系统时间
}
class MySource implements SourceFunction<Tuple2<String, Double>> {
private Boolean flag = true;
private String[] categorys = {"女装", "男装", "图书", "家电", "洗护", "美妆", "运动", "游戏", "户外", "家具", "乐器", "办公"};
private Random random = new Random();
@Override
public void run(SourceContext<Tuple2<String, Double>> sourceContext) throws Exception {
while (flag) {
int index = random.nextInt(categorys.length);
String category = categorys[index];
double price = random.nextDouble() * 100;
sourceContext.collect(Tuple2.of(category, price));
}
}
@Override
public void cancel() {
flag = false;
}
}
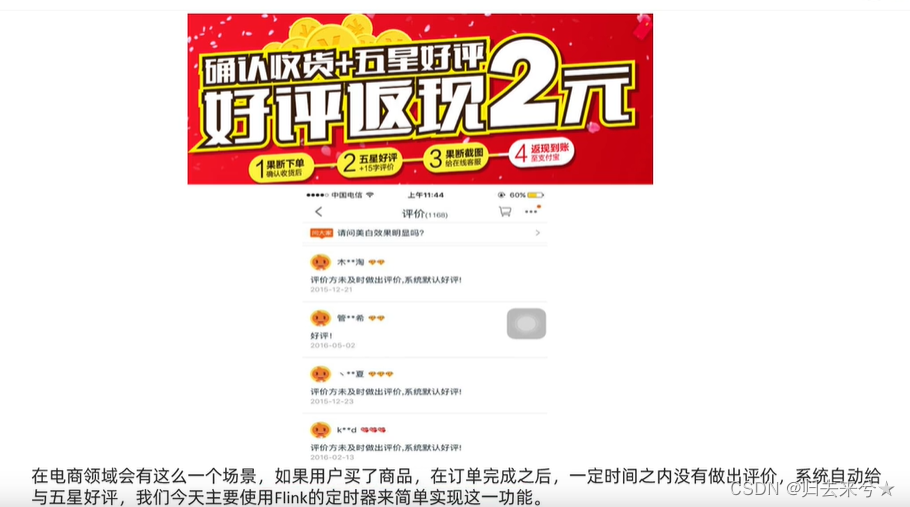
超时自动好评
public class OrderAutomaticFavorableComments {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// <用户Id,订单Id,订单生成时间>
DataStreamSource<Tuple3<String, String, Long>> orderDS = env.addSource(new MySource());
long interval = 5000L;// 超时时间
// 分组后 使用自定义KeyedProcessFunction完成定时判断超时订单并自动好评
orderDS.keyBy(t->t.f0)
.process(new TimeProcessFunction(interval));
env.execute();
}
public static class MySource implements SourceFunction<Tuple3<String, String, Long>> {
private Boolean flag = true;
@Override
public void run(SourceContext<Tuple3<String, String, Long>> sourceContext) throws Exception {
Random random = new Random();
while (flag) {
String userId = random.nextInt(5) + "";
String orderId = UUID.randomUUID().toString();
long currentTimeMillis = System.currentTimeMillis();
sourceContext.collect(Tuple3.of(userId,orderId,currentTimeMillis));
}
}
@Override
public void cancel() {
flag= false;
}
}
private static class TimeProcessFunction extends KeyedProcessFunction<String,Tuple3<String, String,Long>,Object> {
private MapState<String,Long> mapState = null;
private Long interval;
public TimeProcessFunction(long interval){
this.interval = interval;
}
// 初始化
@Override
public void open(Configuration parameters) throws Exception {
MapStateDescriptor<String, Long> mapStateDescriptor = new MapStateDescriptor<>("mapState", String.class, Long.class);
mapState= getRuntimeContext().getMapState(mapStateDescriptor);
}
@Override
public void processElement(Tuple3<String, String, Long> value,
KeyedProcessFunction<String, Tuple3<String, String, Long>, Object>.Context context,
Collector<Object> out) throws Exception {
// Tuple3 <用户Id,订单id,订单生成时间> value里面是当前进来的数据里面有订单生成时间
// 把订单数据保存到状态中 ,为了以后从定时器中查出来
mapState.put(value.f1,value.f2);
// 该订单在value.f2 + interval 时过期/到期,这时如果没有好评的话就需要系统给与默认好评
// 注册一个定时器在value.f2 + interval + interval 时检查是否需要默认好评
context.timerService().registerProcessingTimeTimer(value.f2+interval);
}
@Override
public void onTimer(long timestamp,
KeyedProcessFunction<String, Tuple3<String, String, Long>, Object>.OnTimerContext ctx,
Collector<Object> out) throws Exception {
// 检查历史订单数据(在状态存储)
// 遍历取出状态中的订单数据
Iterator<Map.Entry<String, Long>> iterator = mapState.iterator();
while (iterator.hasNext()) {
Map.Entry<String, Long> map = iterator.next();
String orderId = map.getKey();
Long orderTime = map.getValue();
//先判断好评--实际中应该去调用订单系统看是否好评,我们这里洗个方法模拟
if(!isFavorable(orderId)){
// 判断是否超时
if (System.currentTimeMillis() - orderTime >=interval) {
System.out.println("orderId:" + orderId + " 该订单已超时未好评,系统自动给与好评");
}
}else {
System.out.println("orderId:" + orderId + " 订单已经评价");
}
// 移除状态,避免重复处理
iterator.remove();
mapState.remove(orderId);
}
}
private boolean isFavorable(String orderId) {
return orderId.hashCode() % 2 == 0;
}
}
}
广播流

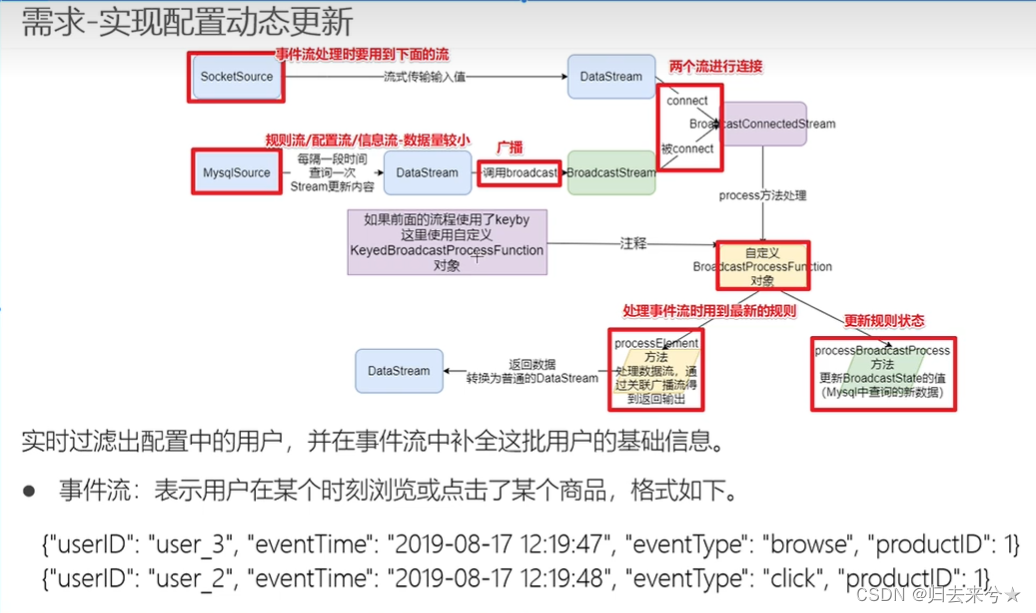
此逻辑 未处理完
public class BoardCastDemo {
/**
* 有一个事件流--用户行为日志,里面有用户Id,但是没有用户详细信息
* 有一个配置流--规则流--里面有用户的详细信息
* 现在要将事件流和配置流进行关联,得出日志中用户的详细信息,如果(用户Id,详细信息,操作)
* 那么我们可以将配置流/规则流--用户信息流 作为状态进行广播(因为配置流/规则流 -- 用户信息流较小)
*/
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple4<String, String, String, Integer>> eventDs = env.addSource(new MySource());
DataStreamSource<Map<String, Tuple2<String, Integer>>> userDs = env.addSource(new MysqlSource());
// 定义描述器
MapStateDescriptor<Void, Map<String, Tuple>> descriptor = new MapStateDescriptor<>("info", Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT)));
// 配置广播流
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDs = userDs.broadcast(descriptor);
// 将事件流与广播流进行连接
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS = eventDs.connect(broadcastDs);
connectDS.process(new BroadcastProcessFunction)
}
public static class MySource implements SourceFunction<Tuple4<String, String, String, Integer>> {
private boolean isRunning = true;
@Override
public void run(SourceContext<Tuple4<String, String, String, Integer>> sourceContext) throws Exception {
Random random = new Random();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
while (isRunning) {
int id = random.nextInt(4) + 1;
String userId = "user_" + id;
String eventTime = df.format(new Date());
String eventType = "type_" + random.nextInt(3);
int projectId = random.nextInt(4);
sourceContext.collect(Tuple4.of(userId,eventTime,eventType,projectId));
Thread.sleep(500);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
public static class MysqlSource implements SourceFunction<Map<String,Tuple2<String,Integer>>>{
private boolean isRunning = true;
@Override
public void run(SourceContext<Map<String, Tuple2<String, Integer>>> sourceContext) throws Exception {
HashMap<String, Tuple2<String, Integer>> map = new HashMap<String, Tuple2<String, Integer>>();
while (isRunning) {
map.put("user_1",Tuple2.of("张三",10));
map.put("user_2",Tuple2.of("李四",20));
map.put("user_3",Tuple2.of("王五",30));
map.put("user_4",Tuple2.of("赵六",40));
}
sourceContext.collect(map);
}
@Override
public void cancel() {
isRunning = false;
}
}
}