目录
- 什么是索引
- 索引类型
- 主键索引
- 唯一索引
- 组合索引
- 前缀索引
- 全文索引
- 空间索引
- 索引的数据结构
- HASH表
- 二叉树
- 平衡二叉树
- 红黑树
- B树
- B+树
- 索引的存储引擎
- MyISAM
- InnoDB
- 索引优化方向
- 分层
- SQL优化
- 表设计
- 三范式
- 索引合理使用
- 服务器优化
- 内存升级
- 碎片优化
- 工具的使用
- explain
- show processlist
- show profile
- performance_schema
- show processlist
- show profile
- performance_schema
先简单介绍一下基础部分
什么是索引
- 帮助MYSQL高效快速获取数据的一种数据结构
- 对数据库表中的一列或多列值进行排序
说明:以空间换取时间 维护索引结构
索引类型
主键索引
primary key
表数据主键,自动创建索引
说明:主键必不可少
唯一索引
unique key
索引列数据必须保证唯一,允许为空
说明:不建议为空,可指定为空字符。因为考虑索引的空间占用:允许为null时,需要额外一个字节保留是否为空。
组合索引
多个列组成一个索引
前缀索引
文本类型,允许指定索引列的长度
全文索引
fulltext key
用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的INDEX 也可以。
用法:MATCH(xxx) AGAINST(xxx)
传送门
空间索引
spatial key
5.7以后支持空间索引,支持OpenGIS几何数据模型
说明:
单索引长度限制:5.6里面默认不能超过767bytes,5.7不超过3072bytes
5.6可以调整配置,放开767长度限制,但是最多也不能超过3072
传送门
一般前三种用的比较多,后面三种使用比较少。
索引的数据结构
HASH表
使用key-value键值对方式存储数据。key存储列数据,value存储存储记录或者磁盘地址,点查命中数据
说明:存在hash冲突,命中地址后,循环链表查询数据
优点:不考虑hash冲突情况下,时间复杂度为O(1)
缺点:
-
不支持范围查询,需要全表扫描完成集合搜索
-
hash冲突之后,时间复杂度变成了O(n)
二叉树
每个节点最多两个分支节点且左小右大。使用二分算法查找,减少IO
优点:理想情况二分查找,减少IO
缺点:
- 结构不稳定
- 数据查找复杂度受树的深度影响
平衡二叉树
子树之间高度差不能超过1,通过左旋,右旋保证树平衡
优点:结构稳定
缺点:
- 需要频繁的自旋来保证树结构的平衡,读写性能不平衡
- 不支持快速范围查询,需要遍历树节点
- 数据查找复杂度受树的深度影响
红黑树
子树之间高度差不能超过2倍,通过左旋,右旋,节点变色保证树平衡
优点:读写性能接近平衡
缺点:
- 不支持快速范围查询,需要遍历树节点
- 数据查找复杂度受树的深度影响
传送门
B树
所有叶子节点都在同一层的平衡多叉树
优点:
- 支持范围查询
- 数的深度可以控制
- 数据块利用率较高【16k的数据量:16*16*16=4096】
不足:mysql数据块使用率还不够高
传送门
B+树
b树的改进版,非叶子节点不存储数据
优点:
a.叶子节点存储数据,充分使用了数据块
b.减少了IO查询,只需要查询叶子节点的数据
传送门
算法延时动态演示:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
索引的存储引擎
MyISAM
特点:
- 数据与索引是分开存放的,只有非聚簇索引【MYD 数据文件、MYI 索引文件、frm 文件结构[表结构]】
- 不支持事务
- 不支持主外键
- 表锁
- …
传送门
InnoDB
特点:
- 数据文件与索引放在一起的,聚簇数据结构【frm 文件结构、ibd 数据和索引】
- 支持事务
- 行锁、表锁
- …
传送门

索引优化方向
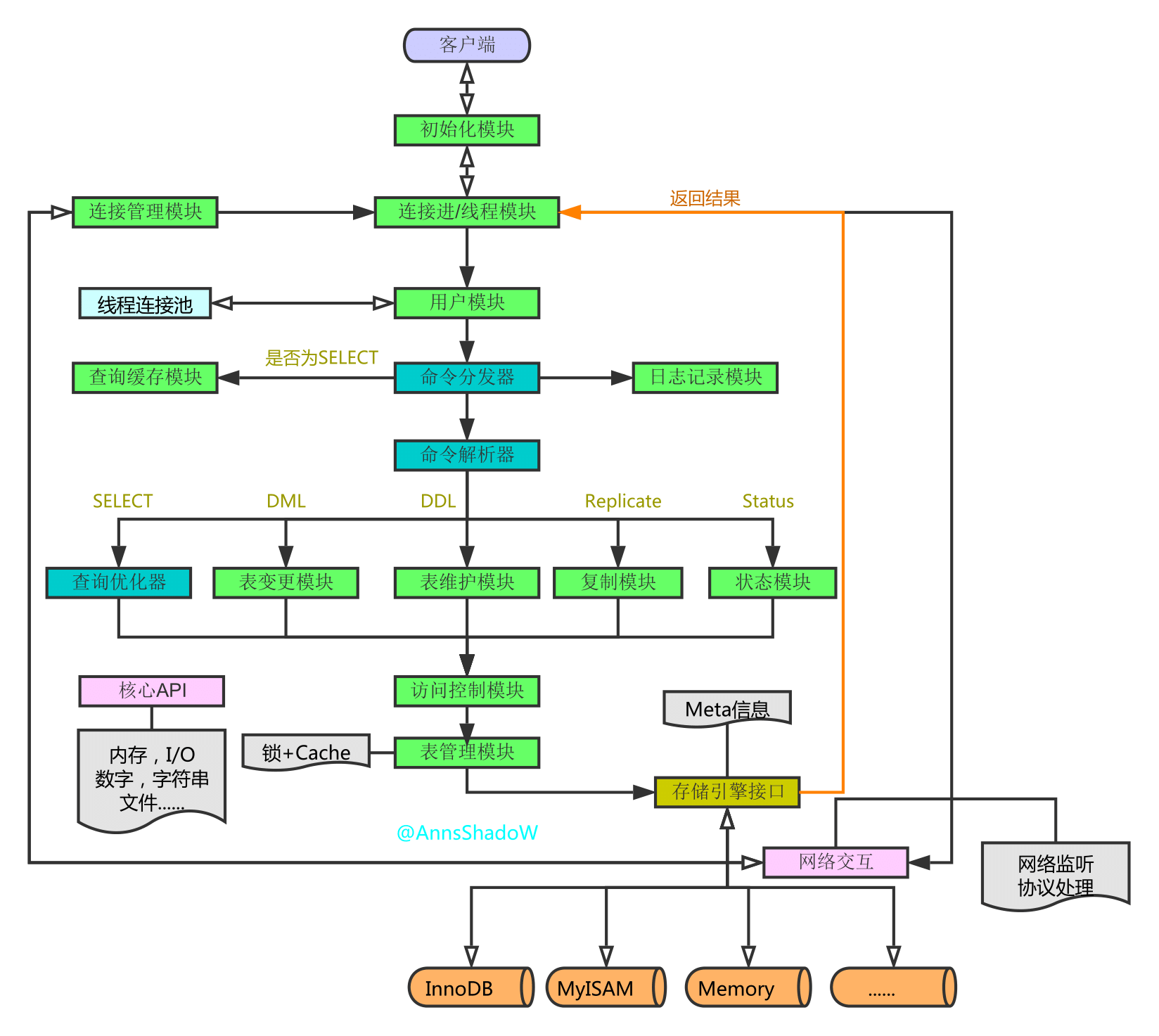
分层
- 连接层
- 服务层
- 引擎层
- 存储层
SQL优化
-
数据点查:等值查询最快
-
最左匹配原则:组合索引的使用
-
索引列不做计算:计算索引失效
-
覆盖索引:非聚簇索引直接返回数据,说明:回表
-
null值判断:非空字段做空判断
-
or导致的索引失效:索引列与非索引列查询导致索引失效
-
字段类型不匹配:字符类型未做匹配
-
索引下推:5.6以后新增
-
group by:临时表、文件排序
表设计
三范式
- 第一范式:所有列不存在再次重复拆分
- 第二范式:非主键列和主键完全依赖
- 第三范式:所有列和主键直接依赖
传送门
注:三范式按实际情况来,不一定要全部满足,比如有时候适当冗余字段比连表查询效果更好。
索引合理使用
- 数据量较小的表不适用索引
- 频繁更新的列不合适用索引
- 重复度较高的列不适合索引【*】
- 关联查询字段创建索引
注:第三条还是得按实际情况来,有时候加上确实比不加要快。
服务器优化
内存升级
cache缓存块、数据集过滤都依赖内存
碎片优化
数据删除会造成不连续的空白空间
传送门
工具的使用
explain
SQL执行计划,优化SQL
传送门
show processlist
查询SQL执行情况
传送门
show profile
查看执行耗时
传送门
performance_schema
传送门
/1093229)
show processlist
查询SQL执行情况
传送门
show profile
查看执行耗时
传送门
performance_schema
传送门



![BUUCTF Reverse/[GXYCTF2019]simple CPP](https://img-blog.csdnimg.cn/eb07f46c30c3402eb0e34012b251689c.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L29va2FtaTY0OTc=,size_16,color_FFFFFF,t_70#pic_center)







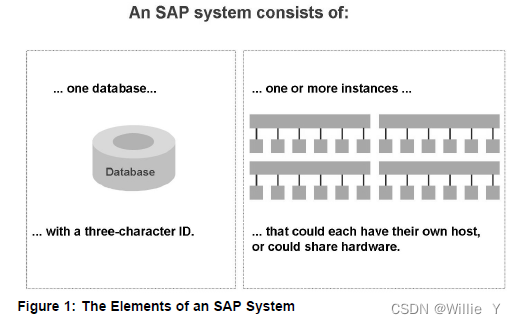
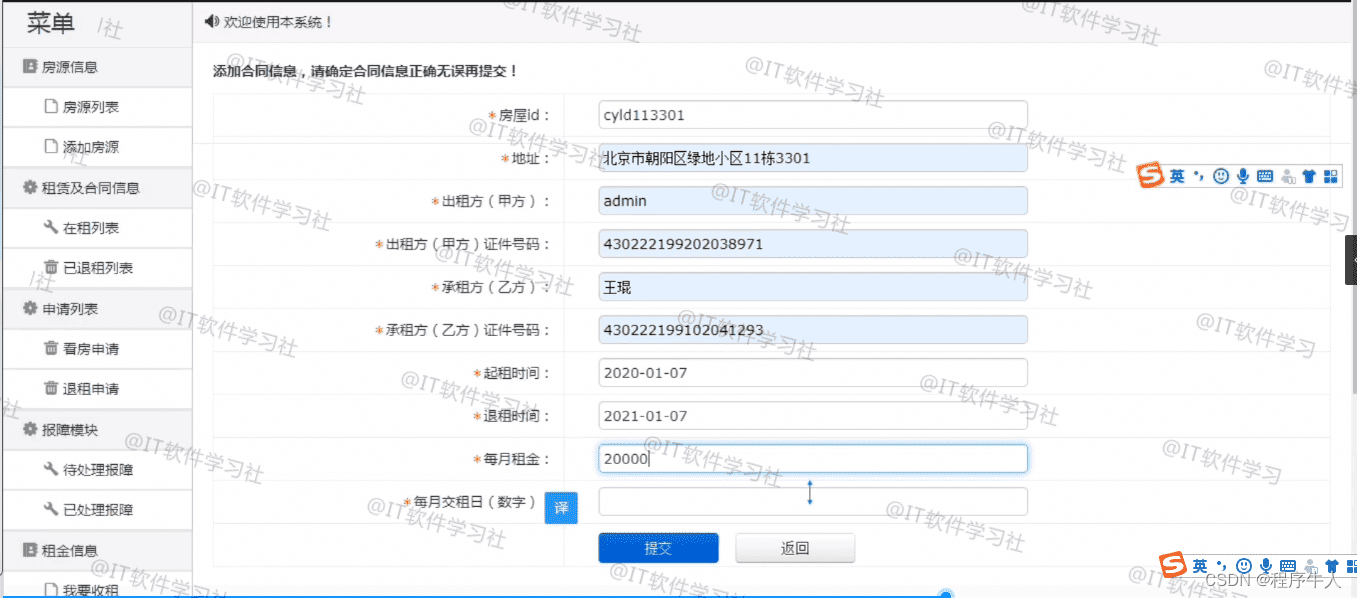
![[附源码]java毕业设计校园跑腿系统](https://img-blog.csdnimg.cn/fe7b384d94c74ecbb2f36a73bd22f709.png)