SPARKSQL3.0-Catalog源码剖析
一、前言
阅读本节需要先掌握Analyzer阶段的相关知识
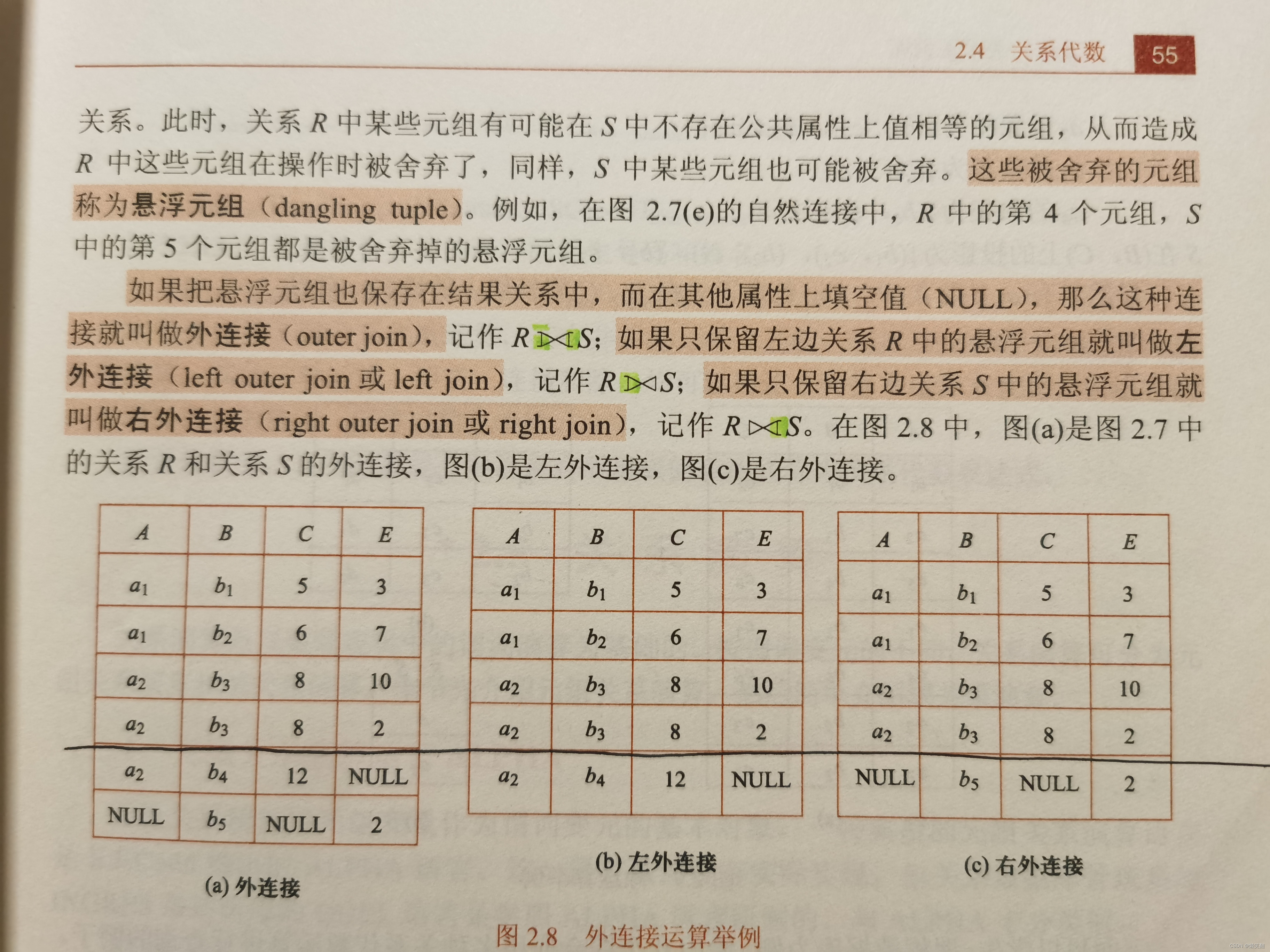
在Spark SQL 系统中,Catalog 主要用于各种函数资源信息和元数据信息 (数据库、数据表数据视图、数据分区等)的统一管理。
初次看这种解释还是比较模糊,一会我们看源码就很清晰了
二、源码
首先Catalog是在SessionState类中,看过SessionState一节的话应该知道SessionState是在BaseSessionStateBuilder类中的build函数构建的:
def build(): SessionState = {
new SessionState(
session.sharedState,
conf,
experimentalMethods,
functionRegistry,
udfRegistration,
() => catalog, // 构建catalog
sqlParser,
() => analyzer,
() => optimizer,
planner,
() => streamingQueryManager,
listenerManager,
() => resourceLoader,
createQueryExecution,
createClone,
columnarRules)
}
// 构建catalog
protected lazy val catalog: SessionCatalog = {
val catalog = new SessionCatalog(
() => session.sharedState.externalCatalog,
() => session.sharedState.globalTempViewManager,
functionRegistry,
conf,
SessionState.newHadoopConf(session.sparkContext.hadoopConfiguration, conf),
sqlParser,
resourceLoader)
parentState.foreach(_.catalog.copyStateTo(catalog))
catalog
}
回顾一下:由于BaseSessionStateBuilder有两个子类分别是:HiveSessionStateBuilder、SessionStateBuilder;
所以决定构建哪个builder关键在于构建SparkSession时是否使用了enableHiveSupport函数,这里我们主要讲有关hive的HiveSessionStateBuilder,SessionStateBuilder不做介绍;
父类BaseSessionStateBuilder的catalog函数在子类HiveSessionStateBuilder中被覆盖,故看子类HiveSessionStateBuilder的catalog函数:
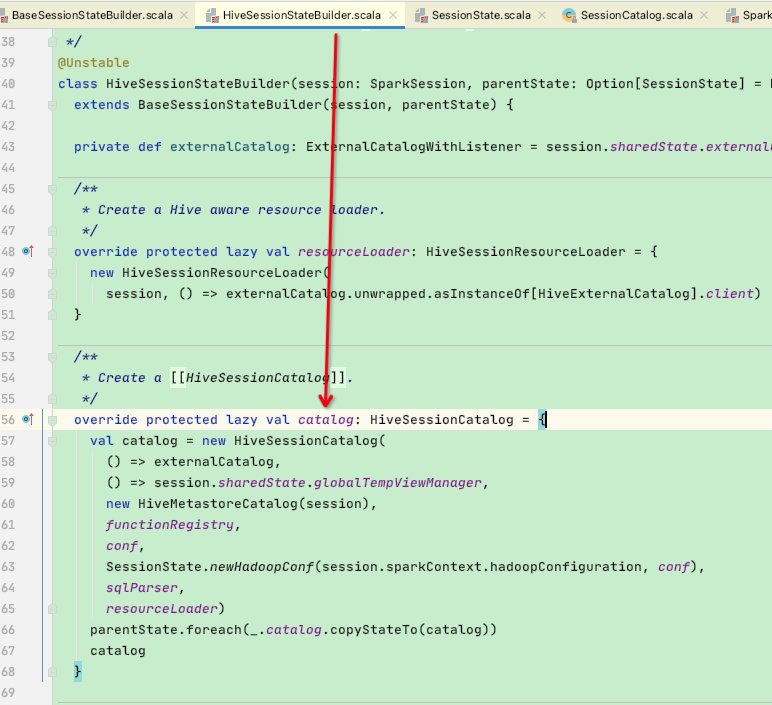
可以看到此处创建的catalog是HiveSessionCatalog【是SessionCatalog的子类】,这里放一张catalog的类图:
如果使用hive则创建HiveSessionCatalog
这里简单介绍一下HiveSessionCatalog的属性:
class HiveSessionCatalog(
externalCatalogBuilder: () => ExternalCatalog,
globalTempViewManagerBuilder: () => GlobalTempViewManager,
val metastoreCatalog: HiveMetastoreCatalog,
functionRegistry: FunctionRegistry,
conf: SQLConf,
hadoopConf: Configuration,
parser: ParserInterface,
functionResourceLoader: FunctionResourceLoader)
1. externalCatalogBuilder【重要】:(外部系统的Catalog ):用来管理外部数据库(Databases )、数据 (Tables )、数据分区( Partitions )和函数(Functions )的接口;顾名思义其目标是与外部系统交互。
2. globalTempViewManagerBuilder:全局的临时视图管理,对应 DataFrame 中常用的 createGlobalTempView 方法,进行跨 Session 的视图管理
3. metastoreCatalog:用于与配置单元元存储交互的旧目录,将来将取消此类,统一使用externalCatalogBuilder对外交互
4. functionRegistry:函数注册接口,用来实现对函数的注册 Register 、查找( Lookup )和删除Drop 等功能。
5. xxxconf:相关配置类
6. functionResourceLoader:函数资源加载器:在 SparkSQL 中除内置实现的各种函数外,还支持用户自定义的函数和 Hive 中的各种函数
通过以上属性的介绍,再看关于catalog的定义:Catalog 主要用子各种元数资源信息和元数据信息 (数据库、数据表数据视图、数据分区与函数等)的统一管理;感觉是不是清晰了一些
在上面众多属性中最重要的是:externalCatalogBuilder,下面将着重介绍它;
先来看一下它的构建过程:可以看到是通过session.sharedState.externalCatalog构建出来的
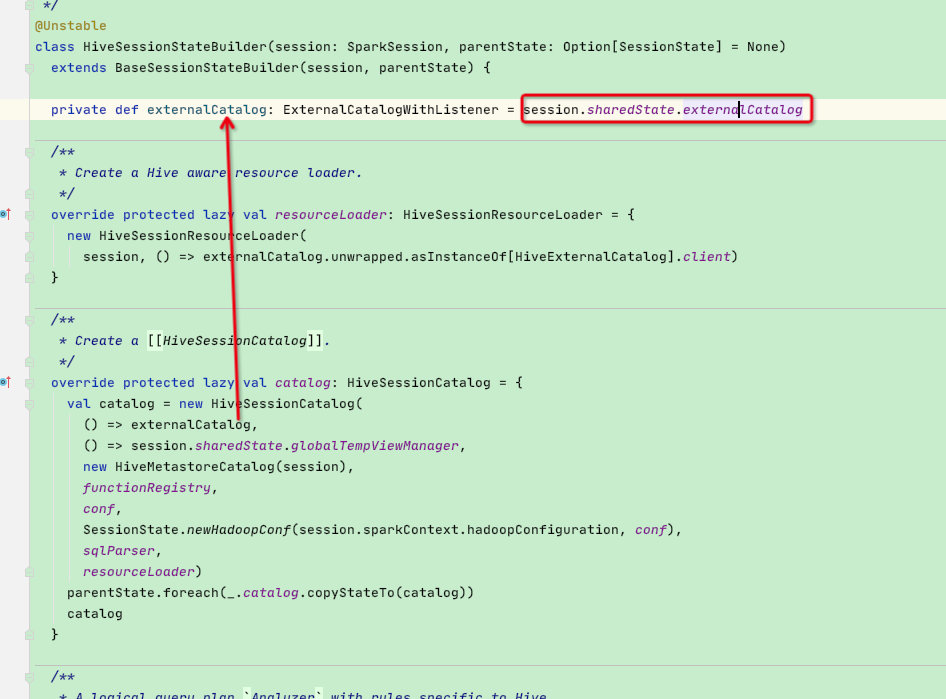
这里进入到ShareState类中,贴一下源码:可以看到是根据hive的属性值来确定最终会构建HiveExternalCatalog
lazy val externalCatalog: ExternalCatalogWithListener = {
// 这里是通过externalCatalogClassName函数获取到要反射的类名,然后通过reflect函数反射获取到externalCatalog
val externalCatalog = SharedState.reflect[ExternalCatalog, SparkConf, Configuration](
SharedState.externalCatalogClassName(conf), conf, hadoopConf)
// 默认数据库default相关配置
val defaultDbDefinition = CatalogDatabase(
SessionCatalog.DEFAULT_DATABASE,
"default database",
CatalogUtils.stringToURI(conf.get(WAREHOUSE_PATH)),
Map())
// 这里就是如果连接不上hive,会在默认目录下构建default数据库
if (!externalCatalog.databaseExists(SessionCatalog.DEFAULT_DATABASE)) {
externalCatalog.createDatabase(defaultDbDefinition, ignoreIfExists = true)
}
// Wrap to provide catalog events
val wrapped = new ExternalCatalogWithListener(externalCatalog)
// spark的事件总线,暂不关注
wrapped.addListener((event: ExternalCatalogEvent) => sparkContext.listenerBus.post(event))
wrapped
}
private val HIVE_EXTERNAL_CATALOG_CLASS_NAME = "org.apache.spark.sql.hive.HiveExternalCatalog"
// 可以看到和SessionState构建的方式一样,关键在于构建SparkSession时是否使用了enableHiveSupport函数
// 如果使用了enableHiveSupport,则CATALOG_IMPLEMENTATION = hive ,即此处会构建HiveExternalCatalog
private def externalCatalogClassName(conf: SparkConf): String = {
conf.get(CATALOG_IMPLEMENTATION) match {
case "hive" => HIVE_EXTERNAL_CATALOG_CLASS_NAME
case "in-memory" => classOf[InMemoryCatalog].getCanonicalName
}
}
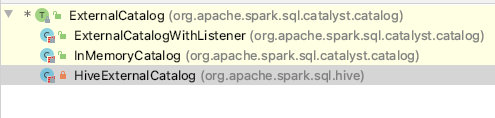
这里放一张HiveExternalCatalog相关类图:可以看到统一父类的接口是ExternalCatalog,如果非hive,则会生成InMemoryCatalog
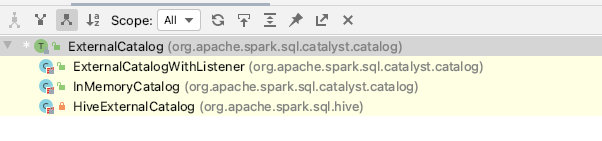
这里我们再看一下HiveExternalCatalog实现的函数:可以看出对hive的DDL、DML操作都在这个类中

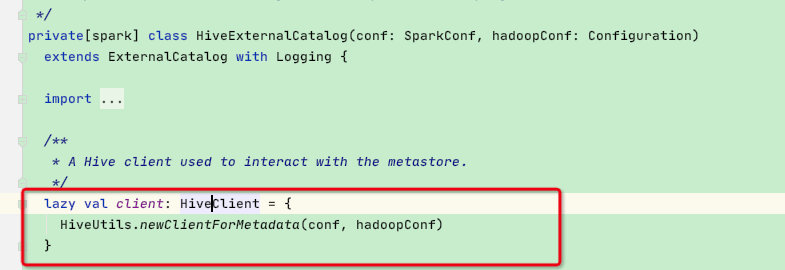
在该类中大部分函数的操作都是使用内部的HiveClient【重要】:这是HiveClient接口,其实现类为HiveClientImpl

而在HiveClientImpl类中同样有一个shim变量,该变量便是spark兼容不同版本hive的关键所在:其内部实现较为巧妙,是将各个函数名称作为抽象函数,再由不同的版本的子类实现函数反射参数名称和入参类型,感兴趣的小伙伴可以跟进去看看
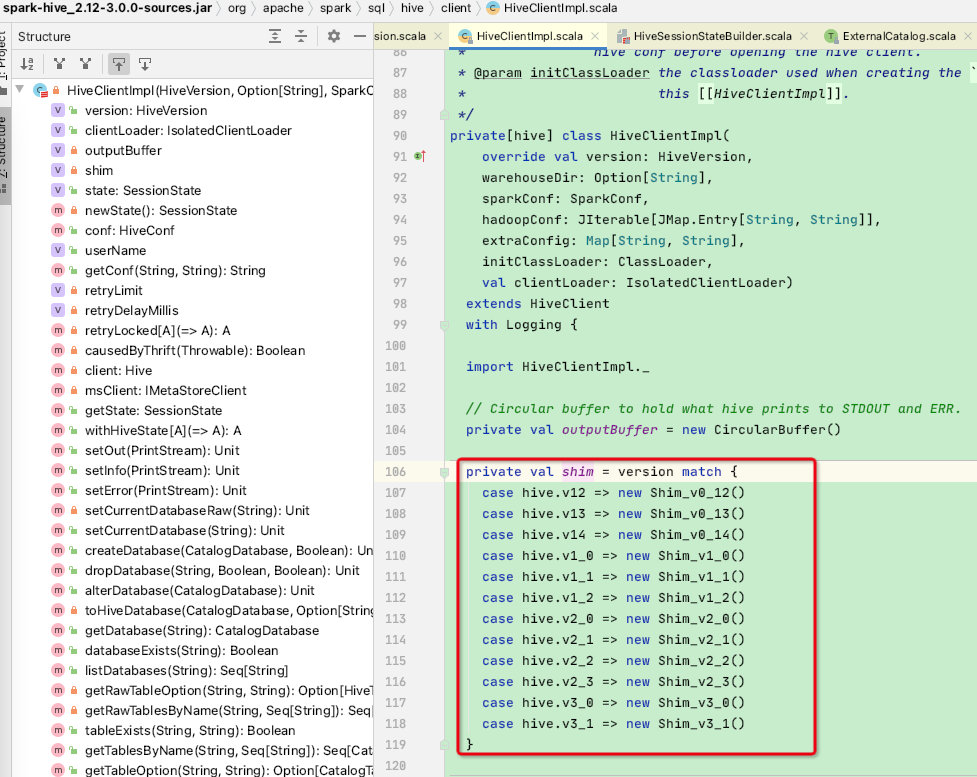
HiveClientImpl内部提供了各种DML/DDL的实现,我们随便看一个dropTable函数:都是使用shim引用进行操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EnCWa1o3-1669097347665)(/Users/hzxt/Library/Application Support/typora-user-images/image-20221103123942870.png)]
再来看一下该类中的import引用:都是hive的原生包引用,至此可以很清楚的知道spark中对hive元数据的操作几乎都是通过hive原生包所提供的API
至此catalog中的externalCatalog介绍完毕,其余属性感兴趣的小伙伴可以对照源码观看
**这里再介绍一个Analyzer阶段中hive表解析规则ResolveTables,如果没看过Analyzer阶段,建议先看完Analyzer阶段:https://blog.csdn.net/qq_35128600/article/details/127970299 **
当我们在执行一个sql = select 字段 from table时,Analyzer阶段会通过catalog来确定表是否存在以及获取表字段等相关属性,这个步骤是由解析表数据规则:ResolveTables实现的

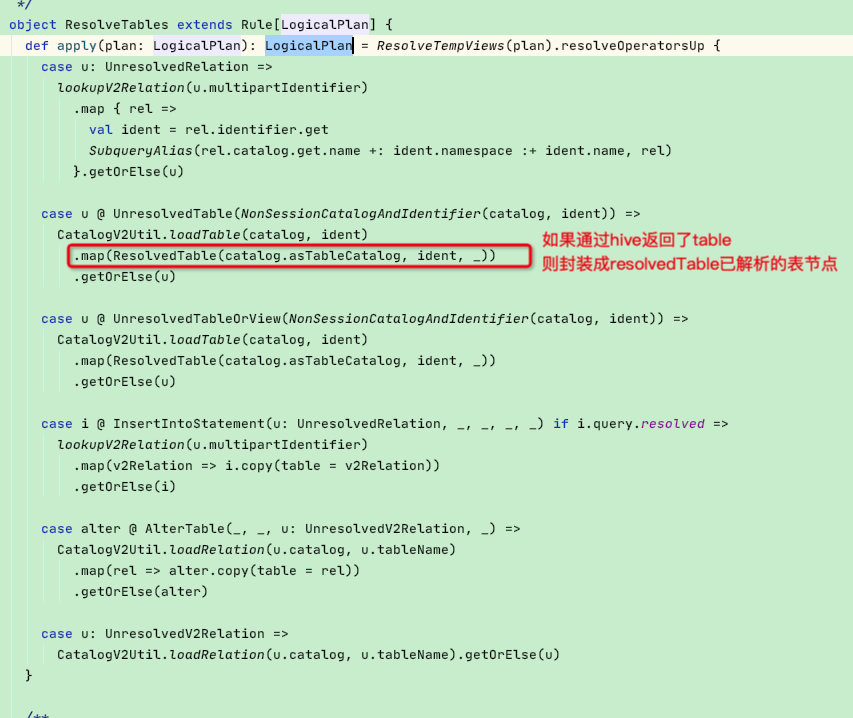
点进去看到apply函数有模式匹配,这里我们以UnresolvedTable【未解析表】为节点类型,随后执行CatalogV2Util.loadTable(catalog, ident)函数
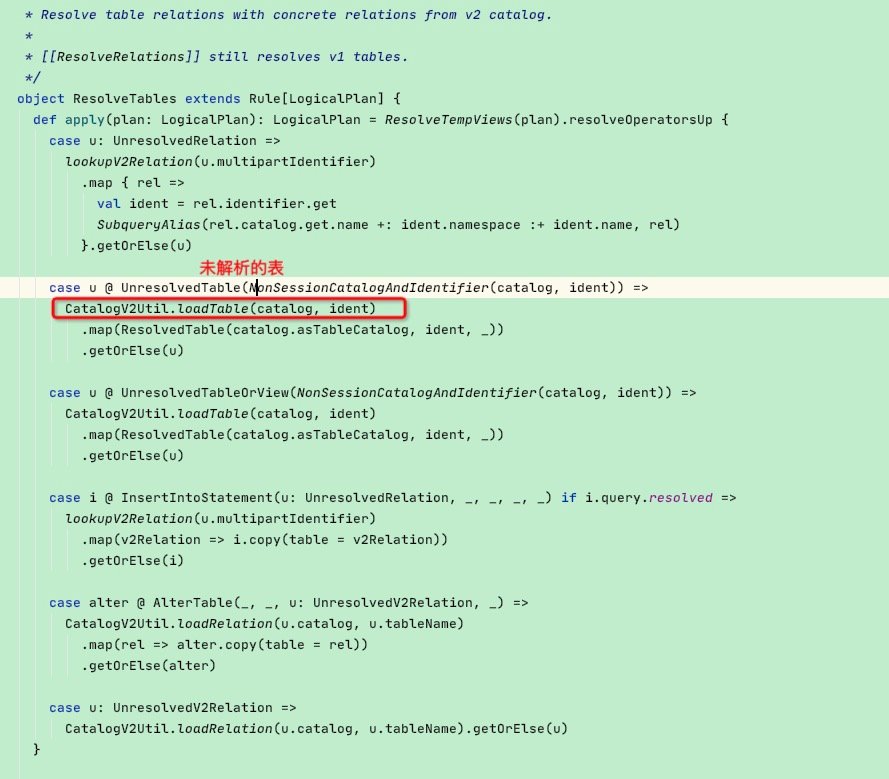
这里又调用了catalog.asTableCatalog.loadTable(ident)
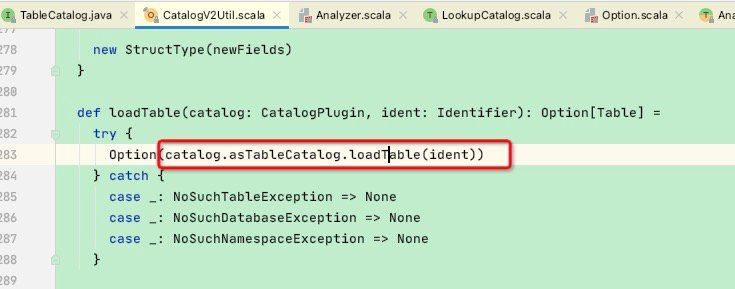
这里来到了TableCatalog.loadTable,根据下面的结构知道这里会有几个子类,具体执行的其实是V2SessionCatalog
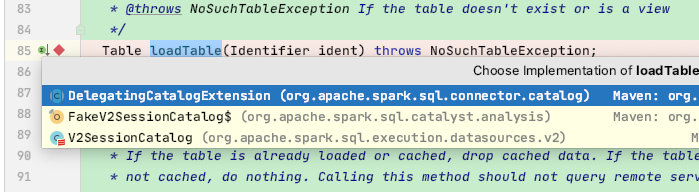
我们可以简单做个debug测试验证一下,如下我们写一个sql然后执行
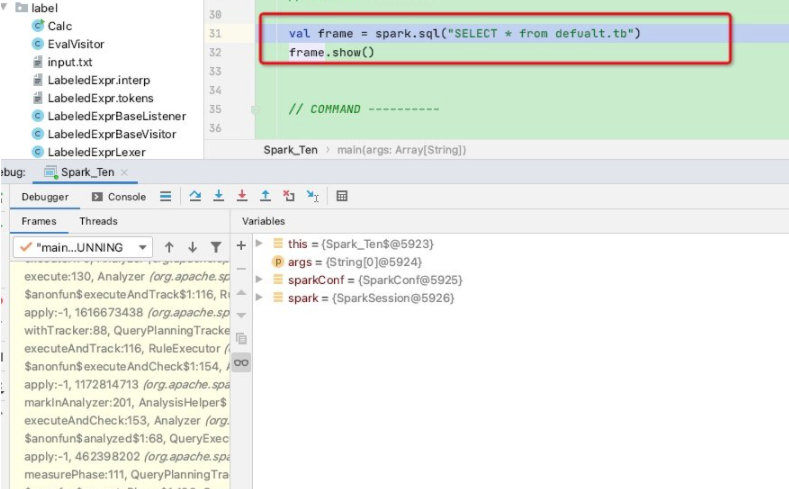
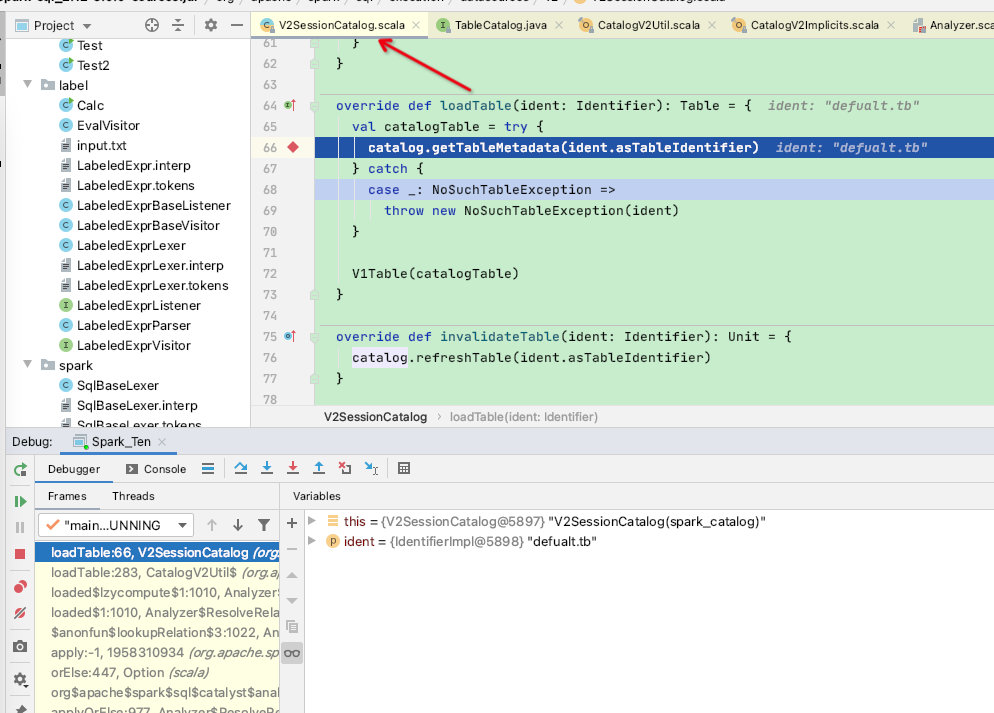
在V2SessionCatalog中看到调用catalog.getTableMetadata,此处走到了SessionCatalog,如下图
在catalog.getTableMetadata函数中执行了externalCatalog.getTable(db, table)
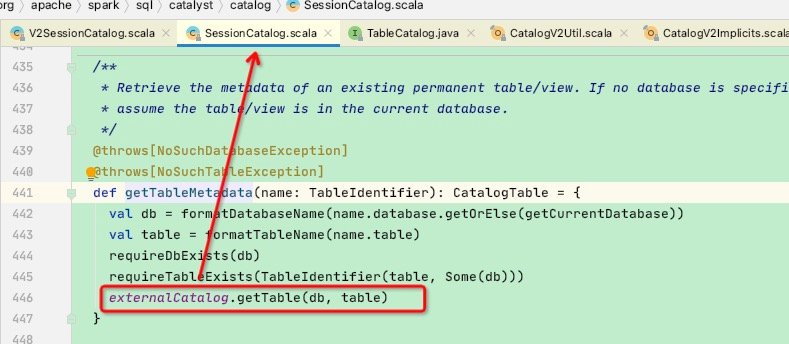
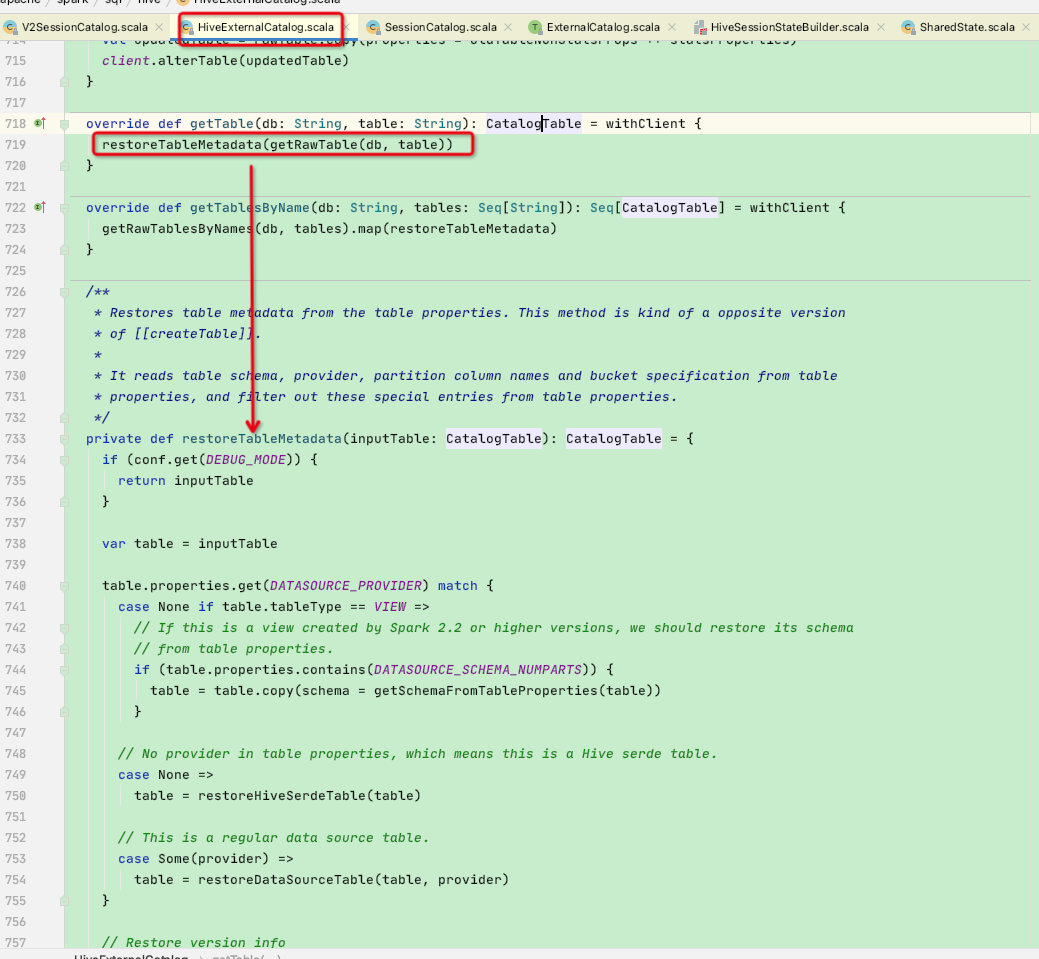
这里看到externalCatalog就比较亲切了,假设我们是连接hive的session,则此时会走HiveExternalCatalog的getTable函数:
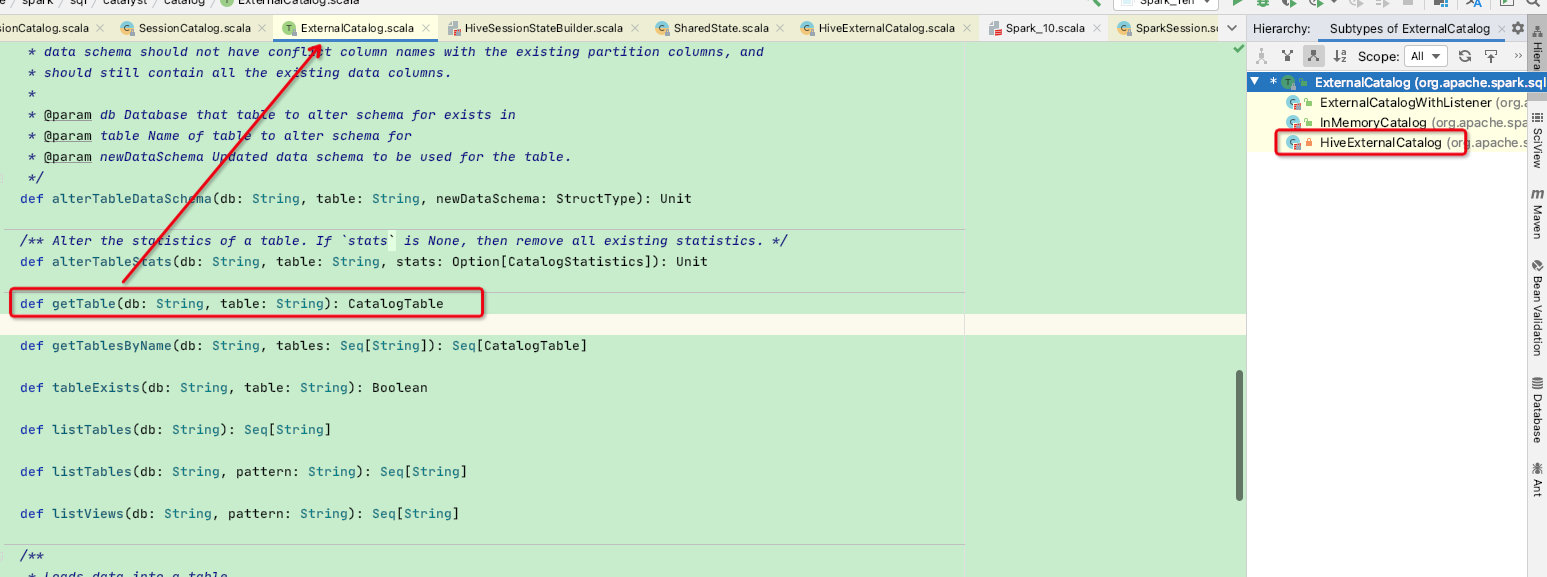
HiveExternalCatalog的getTable调用了restoreTableMetadata函数,此函数将会访问hive的metastore获取此表的元数据信息并构建出CatalogTable实体类返回
我们再回到ResolveTables规则中,如下图
至此spark的catalog的介绍以及Analyzer阶段中的简单使用结束