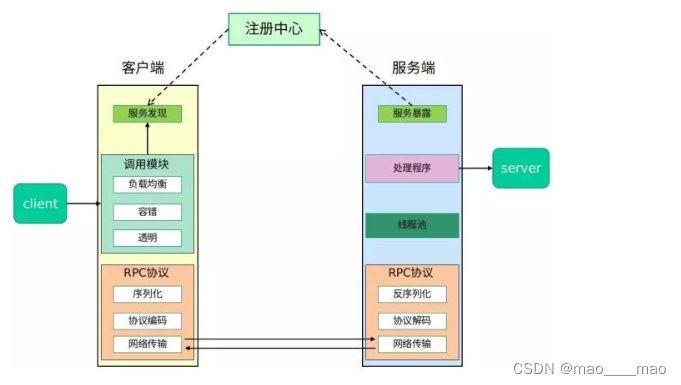
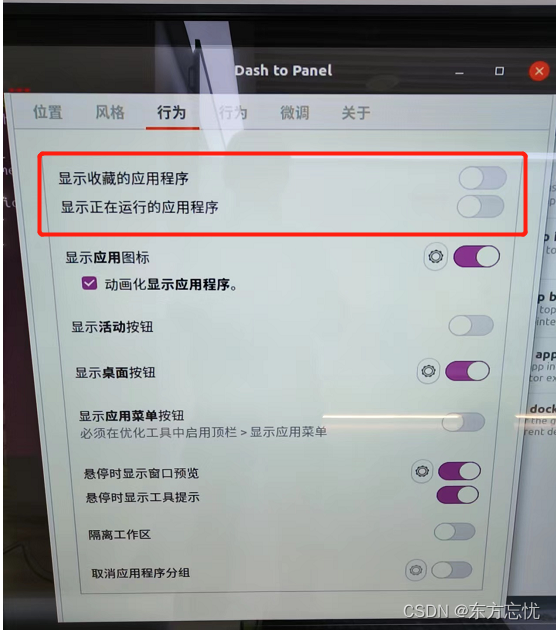
LinkSLA与南京大学合作,将AI算法引入运维平台,将趋势性、周期性强的指标数据通过机器学习,实现异常检测、故障预测等功能。
下面分享一个通过AI算法,对Oracle数据库故障预测的案例。
在3月16日,MOC工程师接到某公司的Oracle数据库dbtime运维指标AI检测异常告警。查看告警详情,发现数据库的db time值与历史相同时间段的db time值区别比较大,并且 dbtime一直持续向上的趋势仍在持续。
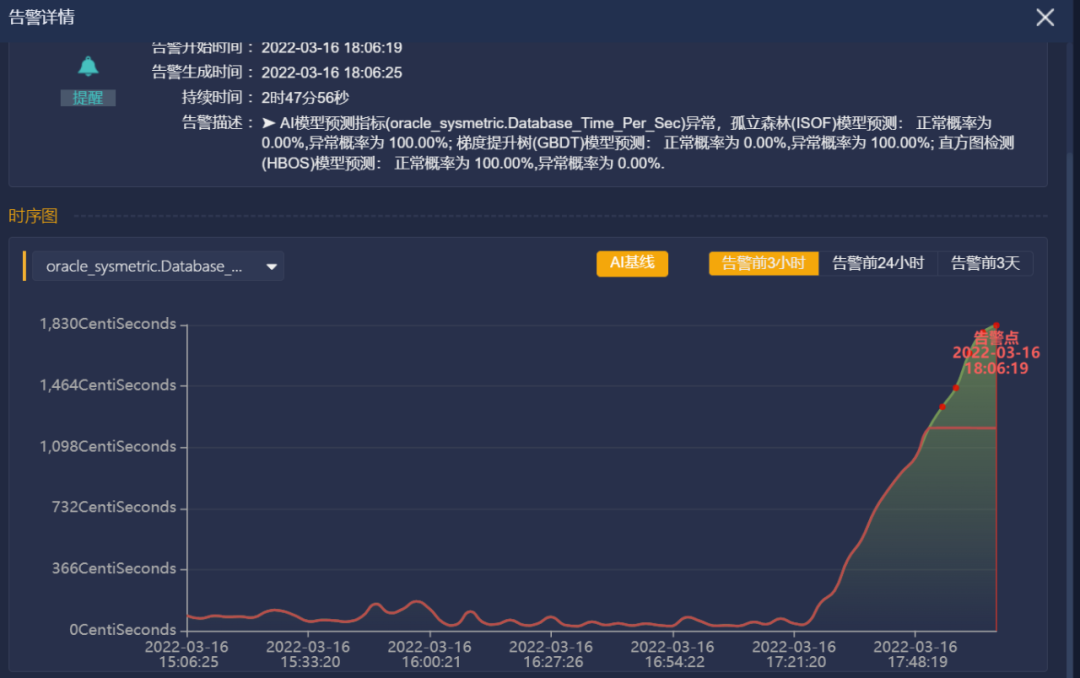
告警详情页面👆
进入指标详情页面,查看运行指标,看到数据库运行时间分配给CPU占比低于10%,而等待时间占比高于90%,和以往指标基线有很大的不同。
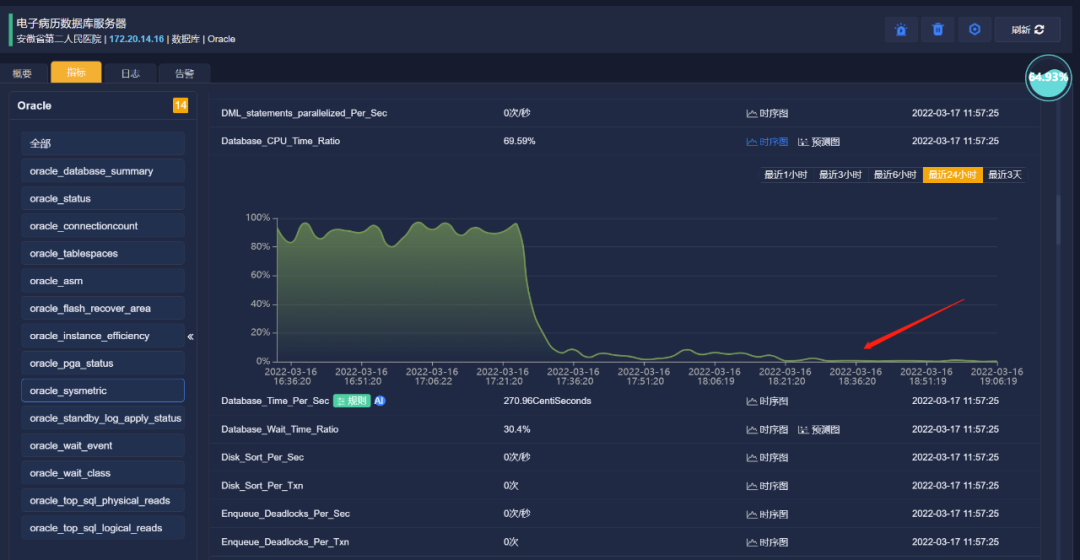
数据库cpu服务时间👆
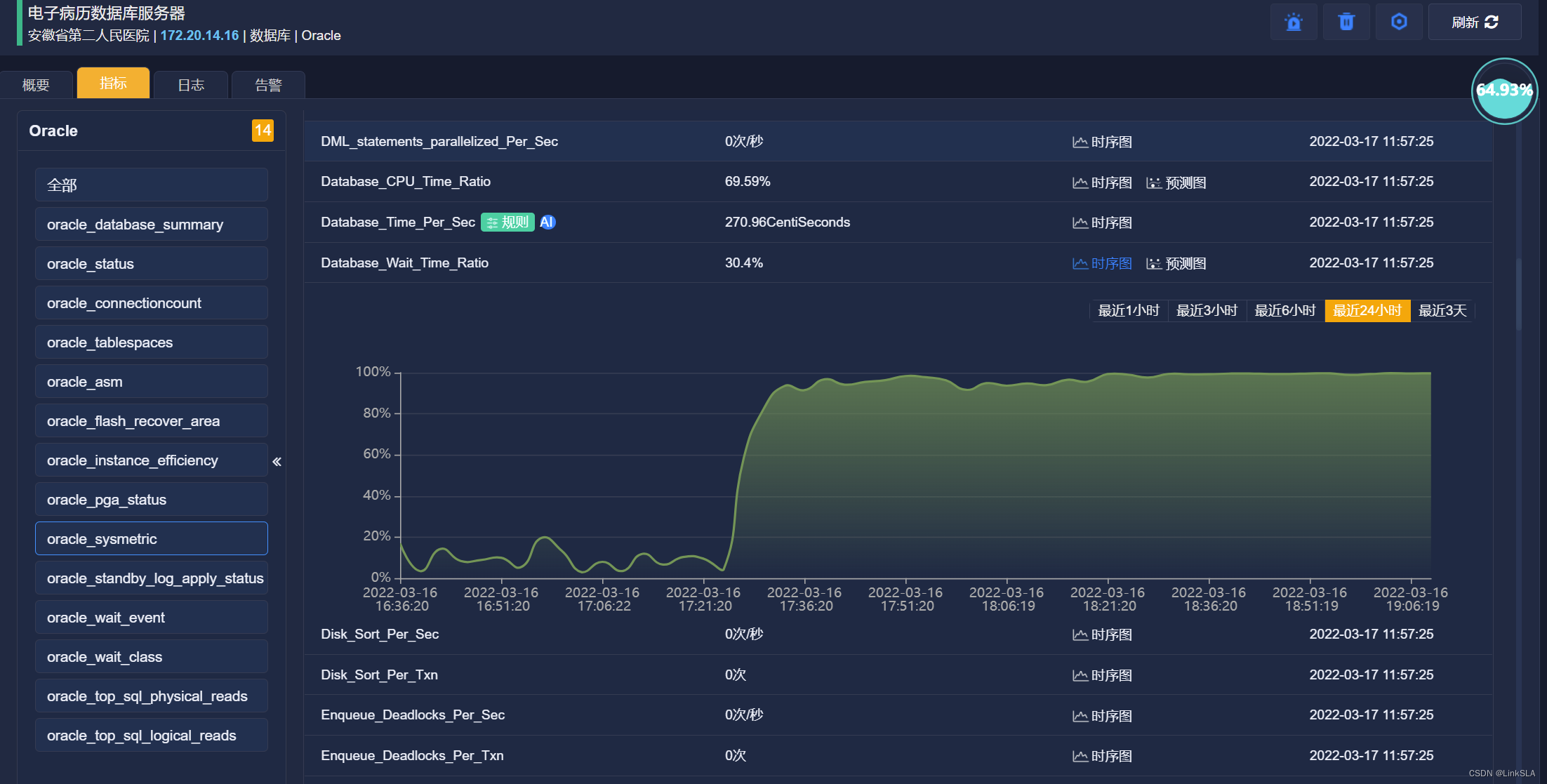 数据库等待时间👆
数据库等待时间👆
一个技术 tips:
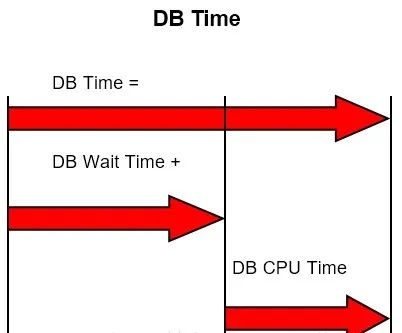
Oracle数据库中DB Time(请求时间)= DB Wait Time(DB等待时间)+ DB CPU Time(DB CPU服务时间)
等待时间的增加表明数据库负载压力大,资源占用非常严重。MOC工程师继续查看相关运行指标时序图,Active_Serial_Sessions(活动串行会话数)、 Current_logons_count(当前登录数);Current_open_Cursors_Count(当前打开的游标数);SQL_Service_Response_Time SQL(服务响应时间)指标参数均显示异常且持续增长。
如图显示👇

Active_Serial_Sessions(活动串行会话数)
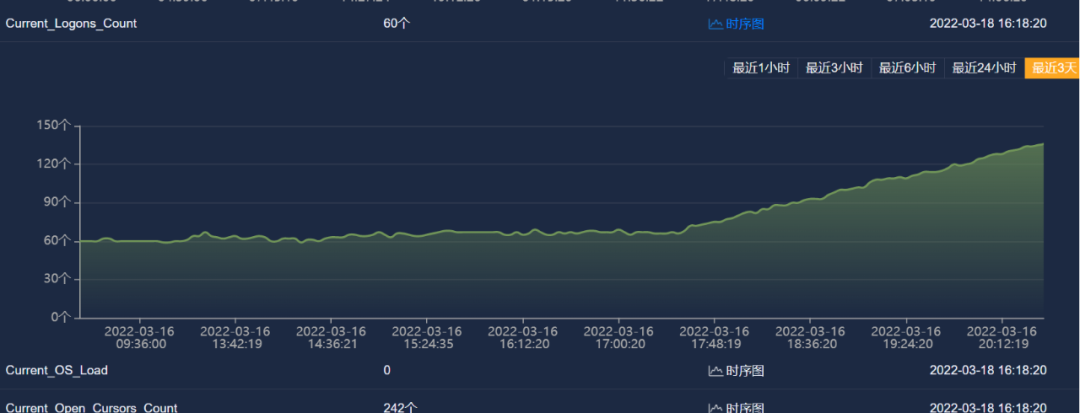
Current_logons_count(当前登录数)
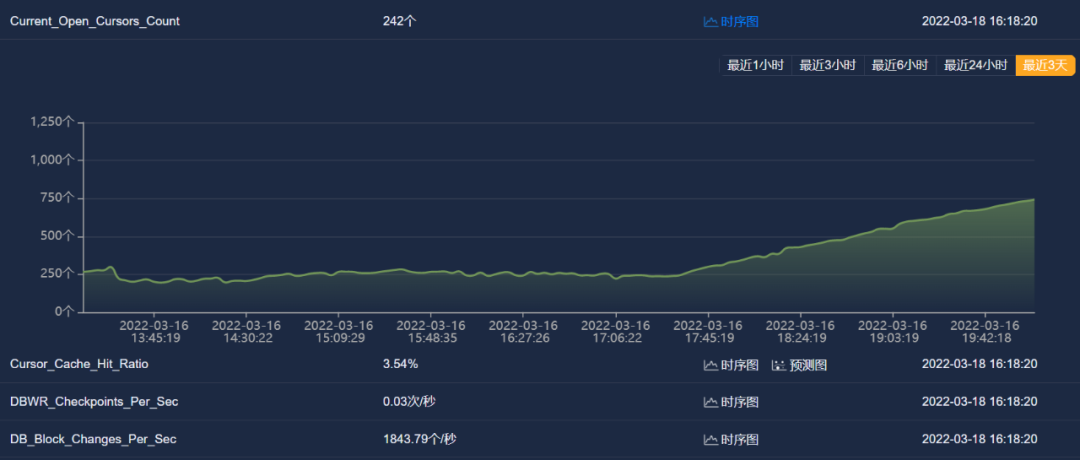
Current_open_Cursors_Count(当前打开的游标数)
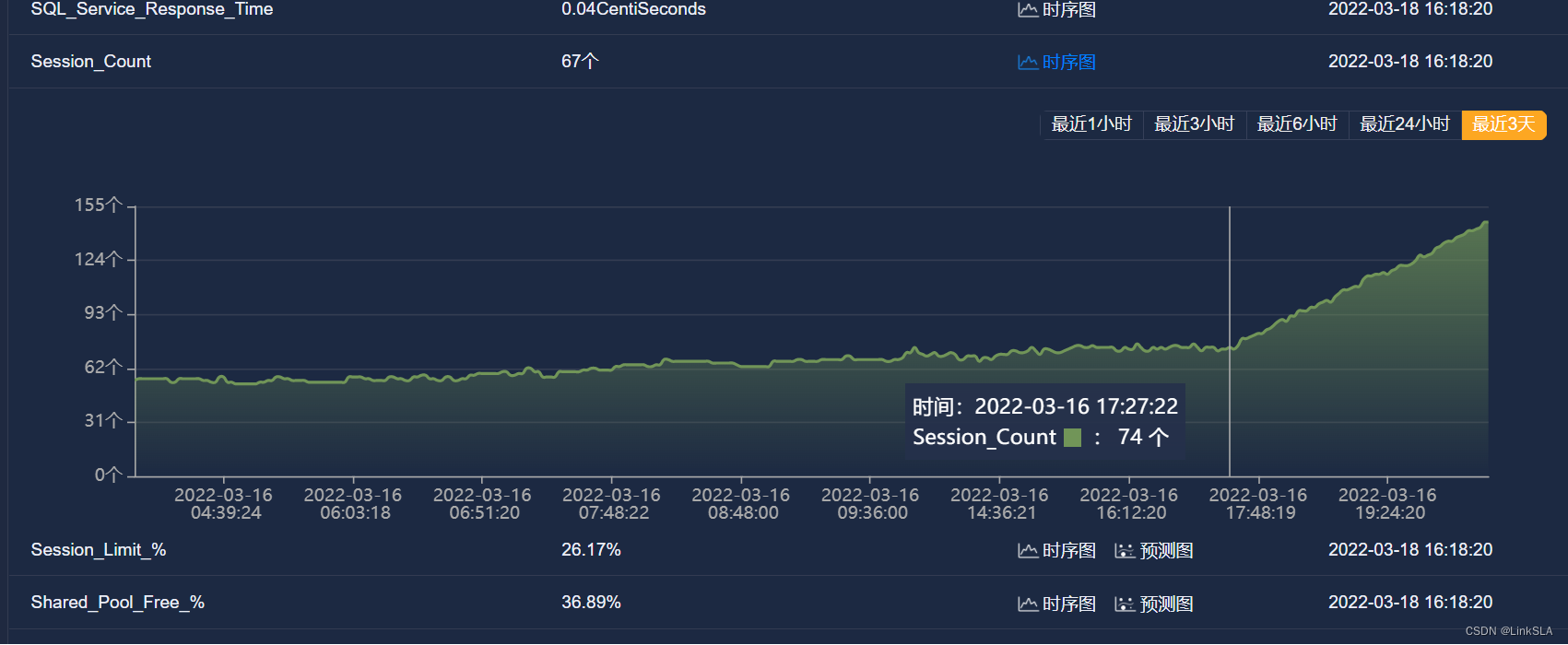
SQL_Service_Response_Time SQL(服务响应时间)
根据AI异常检测告警和相关指标数据时序图分析,这台Oracle数据库负载持续变大,并未任何下降趋势,AI趋势分析,按这个趋势下去,数据库负载将会不断增加,数据库会运行缓慢,最终导致数据库挂死,造成业务中断。
MOC工程师马上将Oracle数据库的AI预警信息,通知用户应用商,检查Oracle数据库运行状态,查找导致dbtime持续增加的原因,将隐患消灭在摇篮里,避免了业务中断现象发生。
案例总结
我们尝试对趋势性、周期性强的指标,进行模型训练,例如我们对oracle的dbtime 等指标进行了模型训练,从实践看还是起到了效果,可以及时发现数据库持续负载压力增大趋势,第一时间通知客户,避免生产事故。后续我们会对监控指标进行分类,不同类型指标按照不同算法进行训练,期望达到更好效果,提高运维效率。