【实践】CV领域的Transformer模型TimeSformer实现视频理解 - 飞桨AI Studio本项目选取CV中的transformer模型TimeSformer进行项目开发,在UCF101数据集上训练、验证、评估 - 飞桨AI Studio https://aistudio.baidu.com/aistudio/projectdetail/3413254?contributionType=1
https://aistudio.baidu.com/aistudio/projectdetail/3413254?contributionType=1
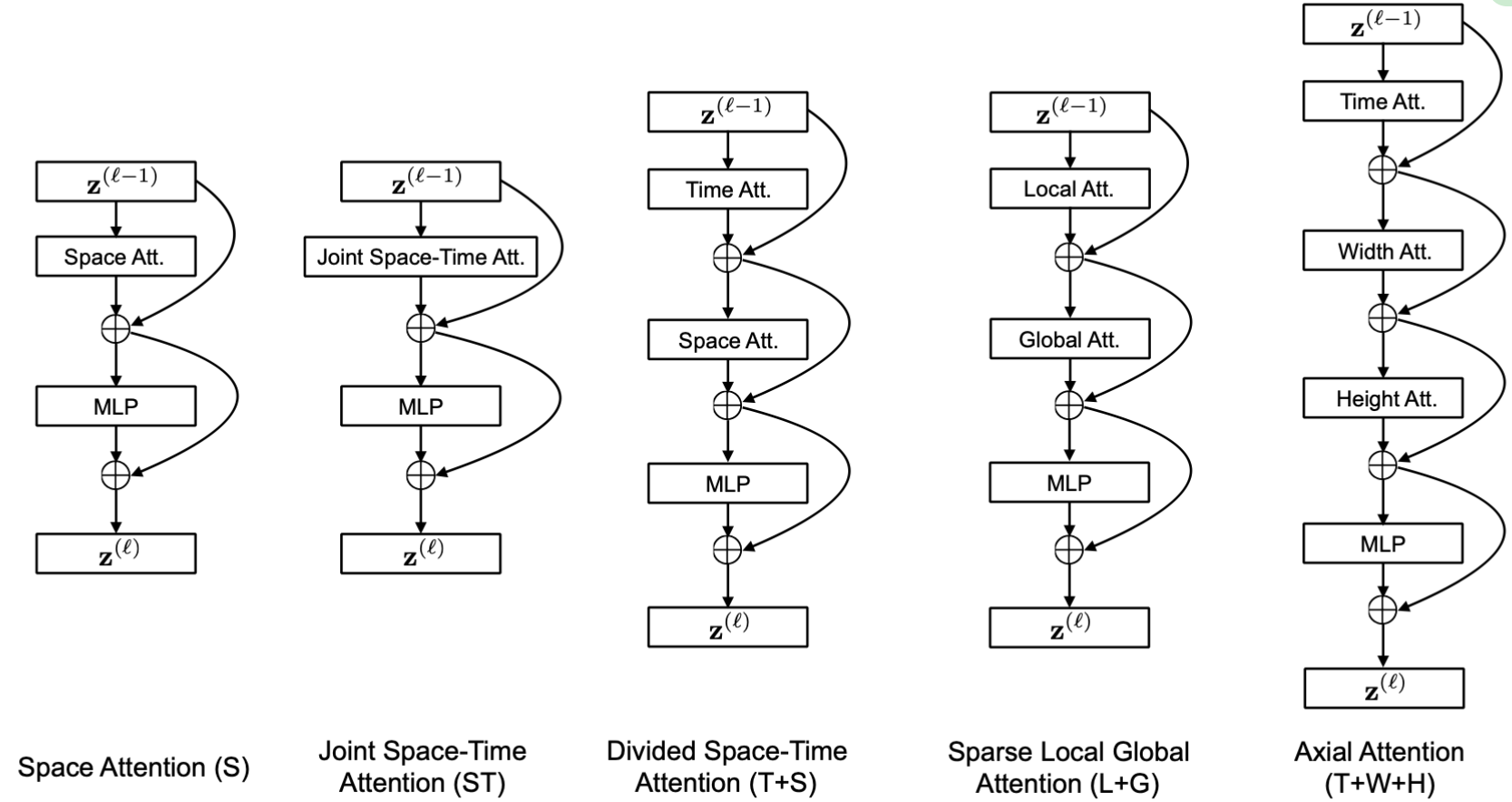
VideoTransformer系列(一):TimeSformer - 知乎TimeSformer: Is Space-Time Attention All You Need for Video Understanding?paper: https://arxiv.org/abs/2102.05095 accept: ICML2021 author: Facebook AI code(offical): https://github.com/facebookresea…![]() https://zhuanlan.zhihu.com/p/449323671timesformer这篇动作识别的文章是基于transformer的,上述的paddle的材料讲的很细,可以直接看材料。以vit作为backbone,提出时空自注意力机制,讨论了空间,时间以及时空组合的注意力机制在视频上的应用。目前的视频识别网络设计上一般是基于2d,3d,transformer以及lstm等。
https://zhuanlan.zhihu.com/p/449323671timesformer这篇动作识别的文章是基于transformer的,上述的paddle的材料讲的很细,可以直接看材料。以vit作为backbone,提出时空自注意力机制,讨论了空间,时间以及时空组合的注意力机制在视频上的应用。目前的视频识别网络设计上一般是基于2d,3d,transformer以及lstm等。
1.输入视频片段
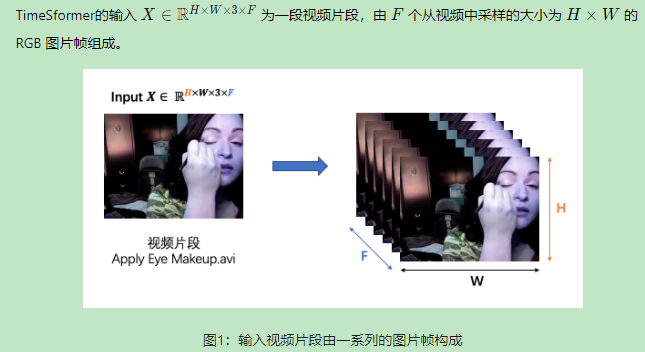
F是抽帧的个数,也就是一段视频被分解为F张图片。
2.图像块拆分

这里是将一个视频中的所有帧全都处理成了patch,其中p表示其在一帧中的位置,t表示帧的索引,通过这两个值就建立了二维的一个体系。
3.线性嵌入
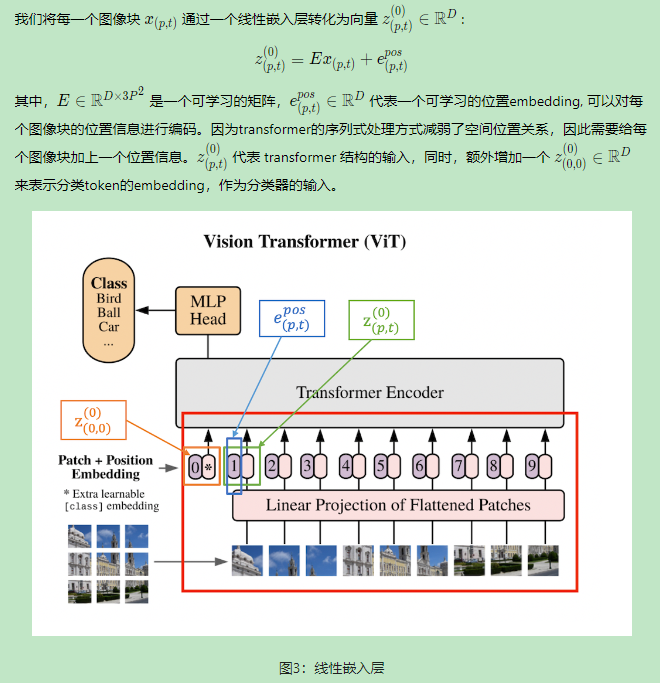
每个像素块通过p,t进行索引,这里是transformer输入的常规操作,将patch转成向量,这里的向量z中还需要位置信息,transformer的序列式处理弱化了空间位置关系。这一步是在做patch的embedding化。
4.qkv计算
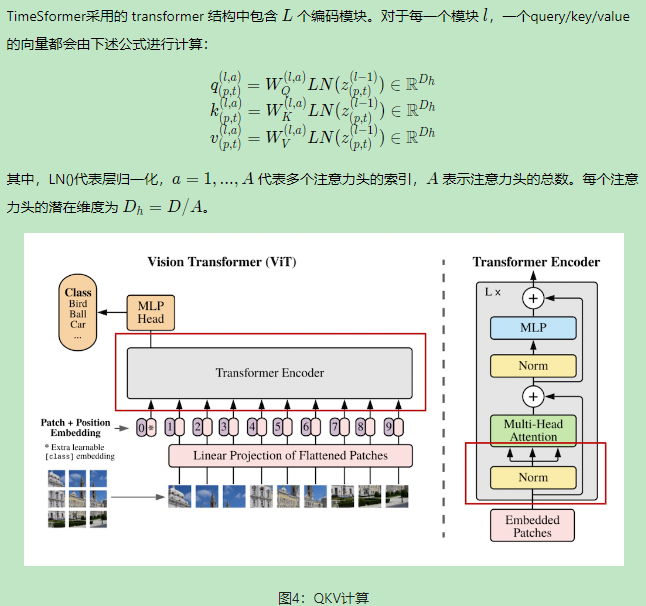
这里是标准的transformer架构,可以看到右侧是encoder模块,timesformer包括了L个encoder,每个z经过LN之后产生了三个维度的qkv,w是学习的。往后是一个多头的自注意力模块,自注意力就是q和每个k计算相似度再和v计算softmax,就是该q的self-attention。
5.自注意力
这块是timesformer的核心,核心就在于attention如何计算。