目录
- 1.线程概念
- 2.windows的线程和linux的线程的区别
- 3虚拟地址到地址空间的转换
- 4.线程优缺点
- 1.优点
- 2.缺点
- 5.进程控制
- 1.创建线程
- 2.线程出现异常了怎么办?进程健壮性问题
- 3.join的第二参数如何理解
- 4.线程终止时
- 6.如果理解pthread_t
- 7.三个概念
- 6.互斥锁
- 1.关于临界区的一点问题
- 1.我们临界资源对应的临界区被锁了,可以被切换吗?
- 2.加锁完后线程被切换会怎么样?
- 2.线程加锁和解锁具有原子性如何实现?
- 1.了解概念
- 2.第一种情况
- 3.第二种情况
- 3.解锁
- 7.简单实现锁
1.线程概念
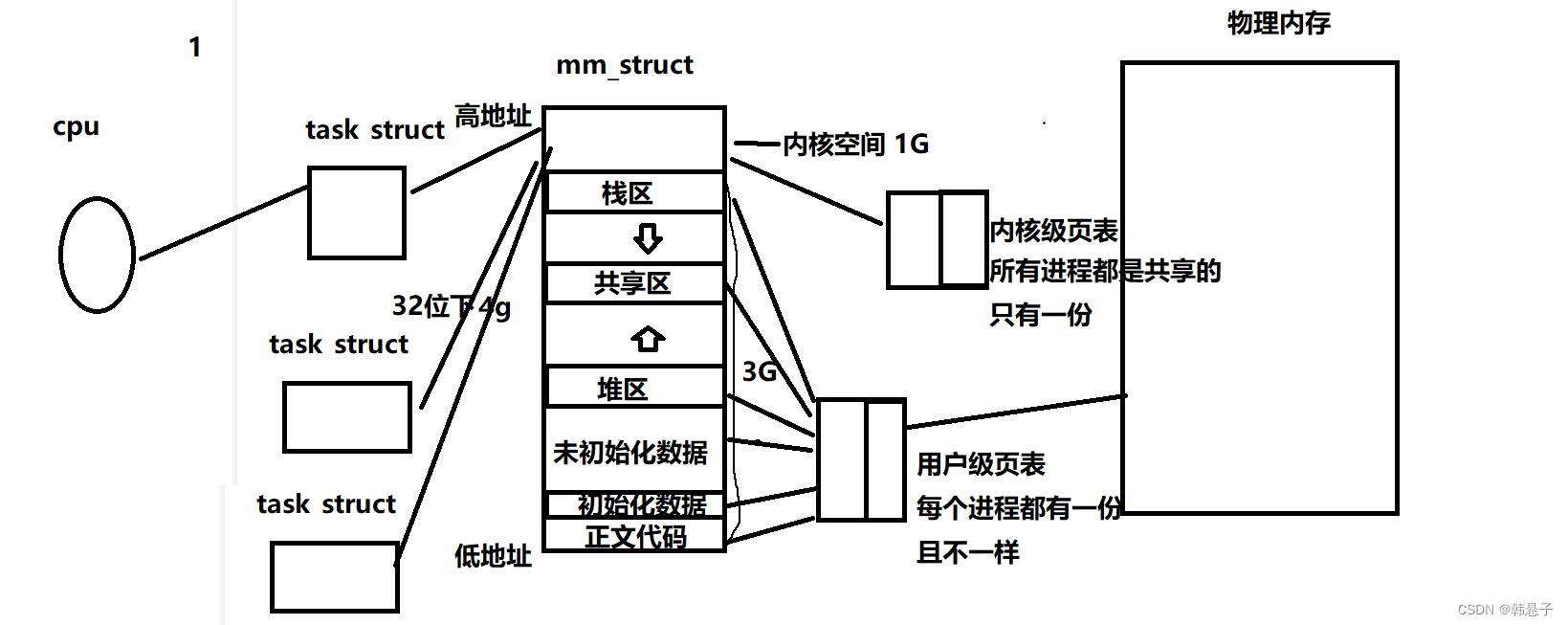
创建了一个进程,他进程的图大概如下
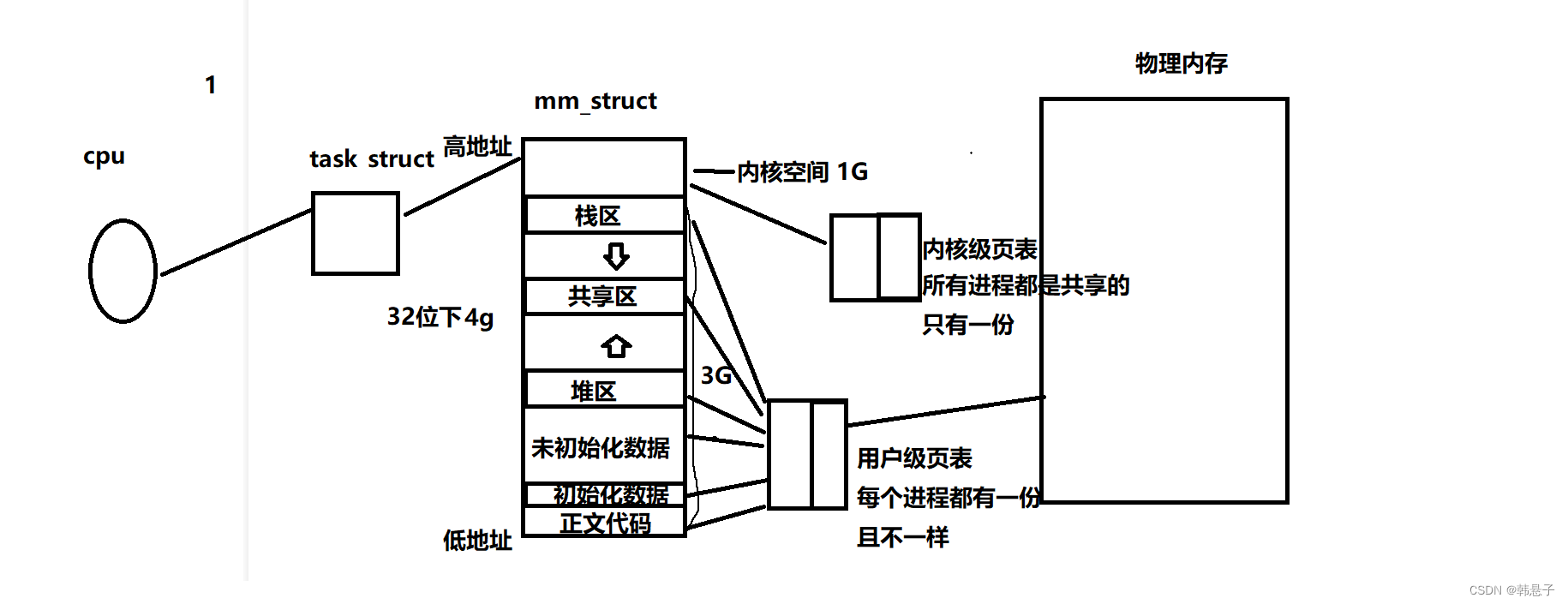
如果我们再创建新的进程
我们出现新的,下面图片的tasks truct(PCB),进程地址空间(PCD),页表等等,如果我们进行了程序替换操作系统还会帮我们把代码look到物理内存,帮我们代码和物理内存的建立映射关系
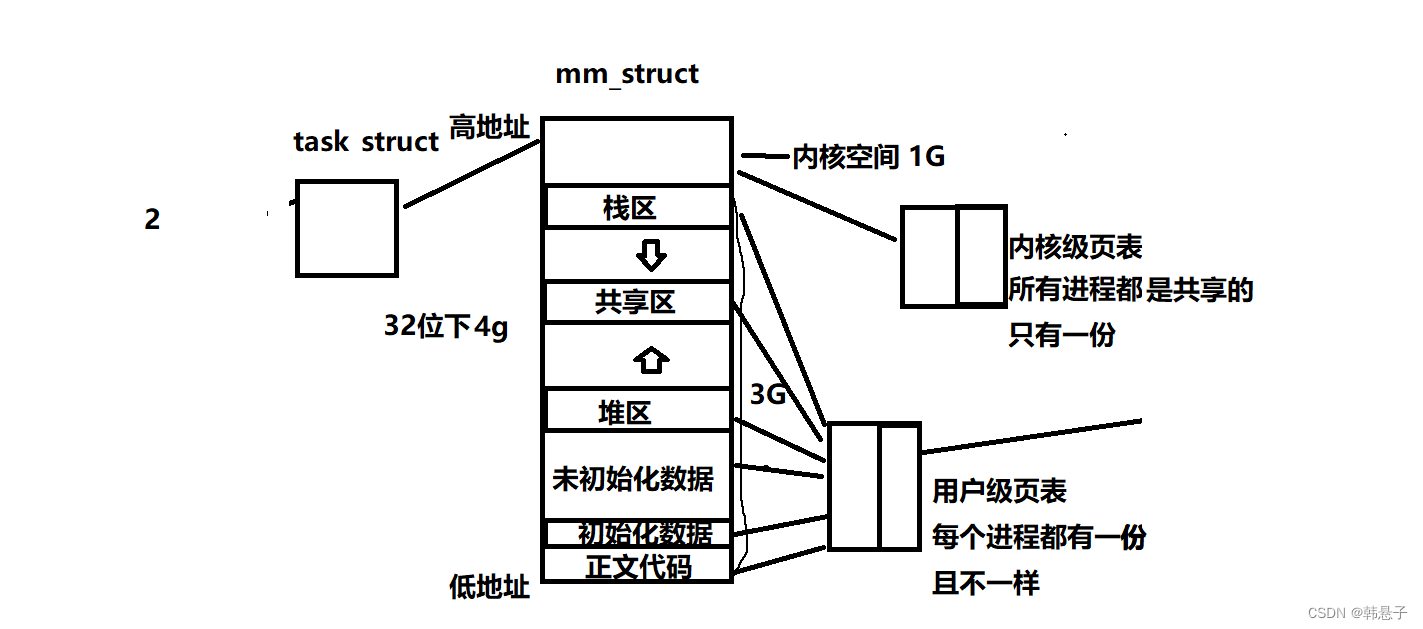
那么fork之后,父子是共享代码打的,可以if else 判断,让父子进程执行不同的代码块,等于不同的执行流,可以做到对特定资源的划分,因为进程具有独立性,所以我把进程2给清除掉,也不会影响到进程1
那么我们可以创建进程,我们创建PCB,但它们不具有单独的进程地址空间和页表,它们指向的是同一个进程地址空间
那么上面三个PCB,分别占用进程低地址空间的一小部分代码和数据,页表也分别有一小部分占用,那么这个执行流就叫线程,所以线程也是进程内部运行的执行流
2.windows的线程和linux的线程的区别
线程和进程的关系是 n比1的,所以操作系统要管理线程,先描述在组织,所以就有了TCB,这里TCB和PCB有一个理念的问题,如果他是真正实现了真线程的平台,比如Windows,那么他就要设计进程和线程的结构体,并且很多线程在进程内部,你还要维护它们之间的关系,这会导致它们的耦合性变得特别高,会对于维护之间变得成本特别高,为什么他要这么设计,因为设计他的人,他认为进程和线程在执行流之间是不一样的,而设计linux的人他认为没有进程没有线程,他认为只有一个叫做执行流,因为他认为进程只是比线程的代码和数据多一些,线程只是比进程的代码和数据少一些,所以觉得没有区别,linux的线程使用PCB模拟的,这里有个问题,linux有没有TCB,答案是有的,因为他就是PCB,就是说TCB和PCB就是一回事,只是他没有专门设计TCB,他只是复用了PCB,用它来表示执行流的概念
那么从cpu的来看到的所有的task_struct 都是一个进程
那么从cpu的来看到的所有的task_struct 都是一个执行流(线程)
以前我们以为进程只是task_strruct,那么我们重新来了解下进程
进程 = 内核数据结构 + 进程对应的代码和数据
进程 = 内核视角 + 承担分配系统资源的基本实体
进程 = 向系统申请资源的基本单位
内部只有一个进程 = 单执行流进程
内部有多个进程 = 多执行流进程
3虚拟地址到地址空间的转换
cpu通过查找物理内存的代码的地址是虚拟地址如果是32位系统下,他的虚拟地址数是32位的,虚拟地址到物理内存不是直接转换,而是划分为 10 10 12
虚拟地址的前十位,存在页目录(页目录只有一个)
虚拟地址中间十位 存在1级页表
虚拟地址的后十二位 做页内偏移量,能覆盖页内的所有地址
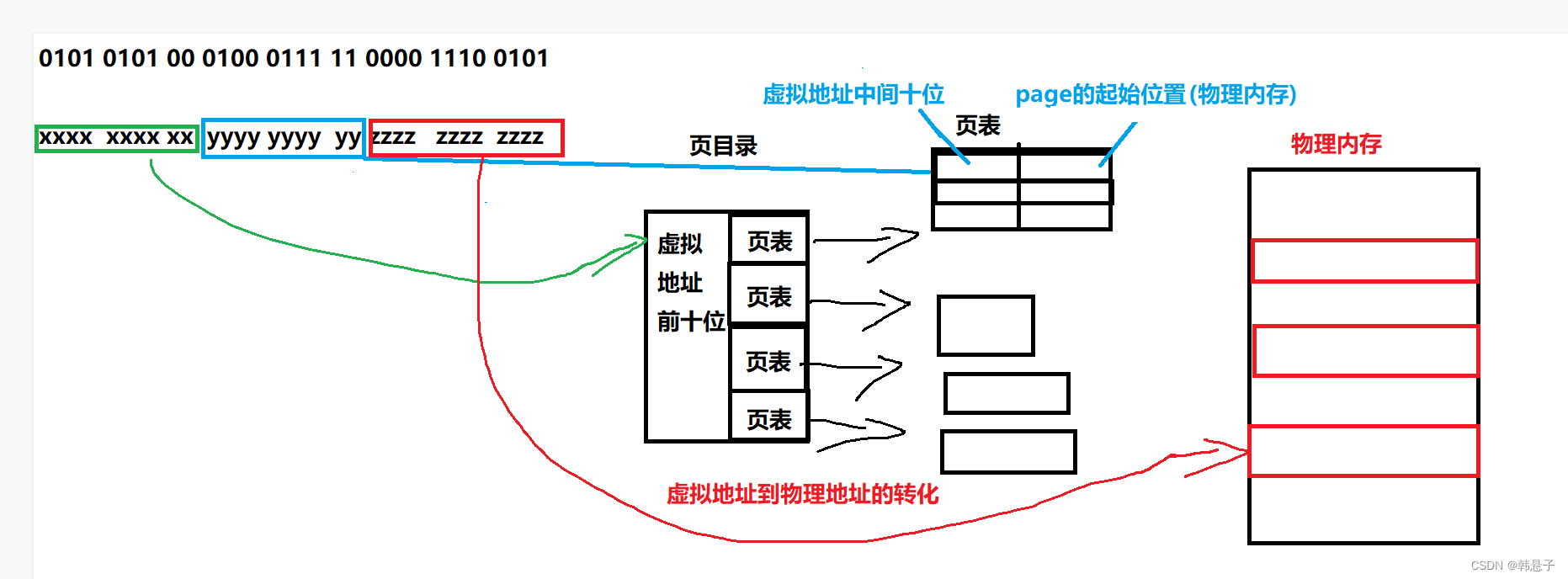
根据虚拟地址前十位在页目录做映射找到1级页表,再根据虚拟地址中间十位,搜索页表,再二级页表找到相对应的物理内存,再通过虚拟地址的后十位位,做偏移量,找到你想要的数据,进行读取
这样做有什么好处?
1.进程虚拟地址空间管理和内存管理,通过页表+page进程解耦,也就是说不关心页内的细节,只关心page在不在
2.页表分离了,可以实现页表的按序获取,比如页目录有的条目他是暂时不用的,那么我们等用的时候再创建这个页表,不用的时候不创建,用的时候再创建,所以等于节省空间
4.线程优缺点
1.优点
创建一个新线程的代价要比创建一个新进程小得多
与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多线程占用的资源要比进程少很多
能充分利用多处理器的可并行数量
在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作
2.缺点
1.性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型
线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的
同步和调度开销,而可用的资源不变。
2.健壮性降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了
不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
3.缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
4.编程难度提高
编写与调试一个多线程程序比单线程程序困难得多
5.进程控制
1.创建线程
代码
makefile
mythread:mythread.cc
g++ -o $@ $^ -lpthread -std=c++11
.PHONY:
clean:
rm -f mythread
mythread.cc
#include<iostream>
#include <cstdio>
#include <unistd.h>
#include<pthread.h>
using namespace std;
static void printTid(const char*name,const pthread_t &tid)
{
printf("%s 正在运行,thread id: 0x%x\n", name ,tid);
}
void* startRoutine(void *args)
{
const char* name = static_cast<const char*>(args);
int cnt = 5;
while(true)
{
printTid(name, pthread_self());//主线程
sleep(1);
if(!(cnt--))
{
break;
}
}
cout << "线程退出了"<<endl;
return nullptr;
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid,nullptr,startRoutine,(void*)"thread1");
sleep(10);
// 线程退出的时候,一般必须要进行join,如果不进行join,就会
// 造成类似于进程那样的内存泄露问题
pthread_join(tid,nullptr);
while(true)
{
printTid("main thread", pthread_self());//主线程
sleep(1);
}
return 0;
}
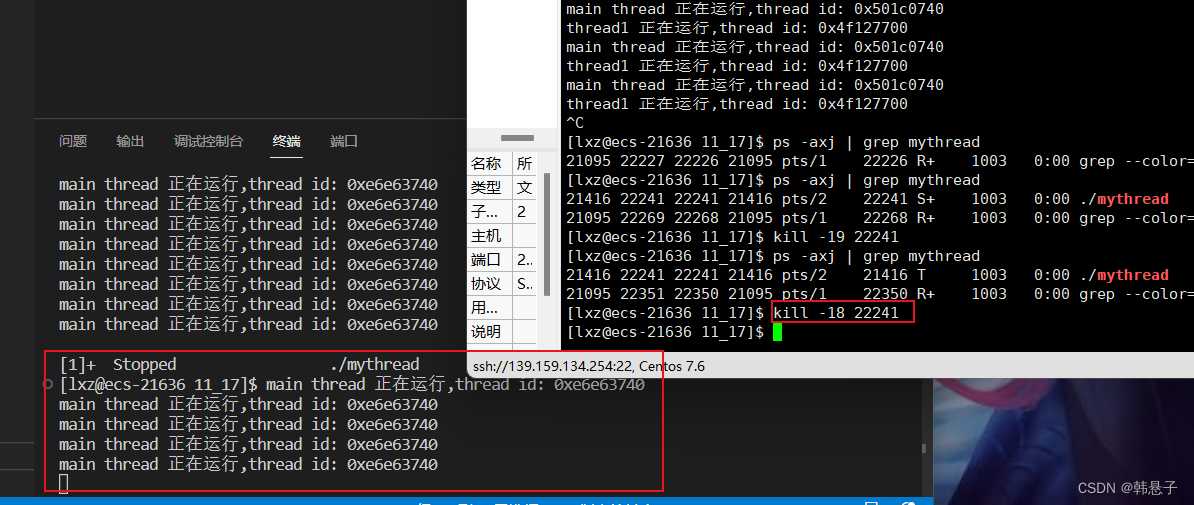
上面代码是是创建线程,下面图片是输入命令kill -19退出进程,可以看到进程退出了二个线程也退出了
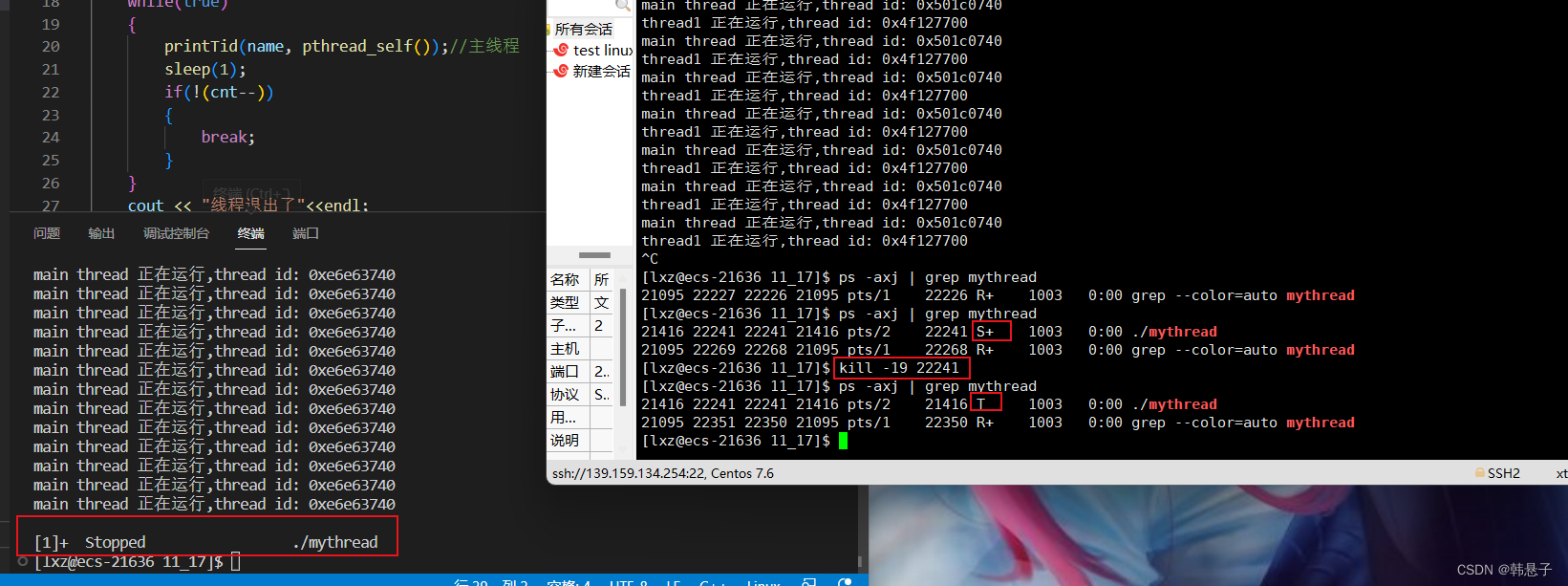
如果运行kill -18命令他也会跑
2.线程出现异常了怎么办?进程健壮性问题
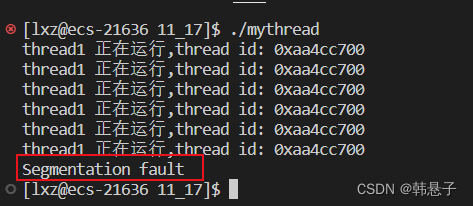
我在代码cnt–的里面加了个野指针,看到下面的图可以看到线程出现异常,整个进程退出,
所以线程异常等于进程异常
3.join的第二参数如何理解
是一个输出型参数,获取新线程退出时的退出码
分为三种情况
1.代码跑完,结果正确
2.代码跑完,结果不正确
3.异常
主线程为什么没有获取新线程的退出时的信号,因为线程异常等于进程异常
4.线程终止时
#include<iostream>
#include <cstdio>
#include <unistd.h>
#include<pthread.h>
using namespace std;
static void printTid(const char*name,const pthread_t &tid)
{
printf("%s 正在运行,thread id: 0x%x\n", name ,tid);
}
void* startRoutine(void *args)
{
const char* name = static_cast<const char*>(args);
int cnt = 5;
while(true)
{
printTid(name, pthread_self());//主线程
sleep(1);
if(!(cnt--))
{
// int *p = nullptr;
// *p = 100; //野指针问题
break;
}
}
cout << "线程退出了"<<endl;
// 1. 线程退出的方式,return
// return (void*)111;
// 2. 线程退出的方式,pthread_exit
pthread_exit((void*)1111);
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid,nullptr,startRoutine,(void*)"thread1");
(void)n;
void *ret = nullptr; // void* -> 64 -> 8byte -> 空间
pthread_join(tid, &ret); // void **retval是一个输出型参数
cout<<"main thread join success" <<(long long)(ret)<<endl;
while(true)
{
printTid("main thread", pthread_self());//主线程
sleep(1);
}
return 0;
}
通过join获得线程的返回的参数并打印
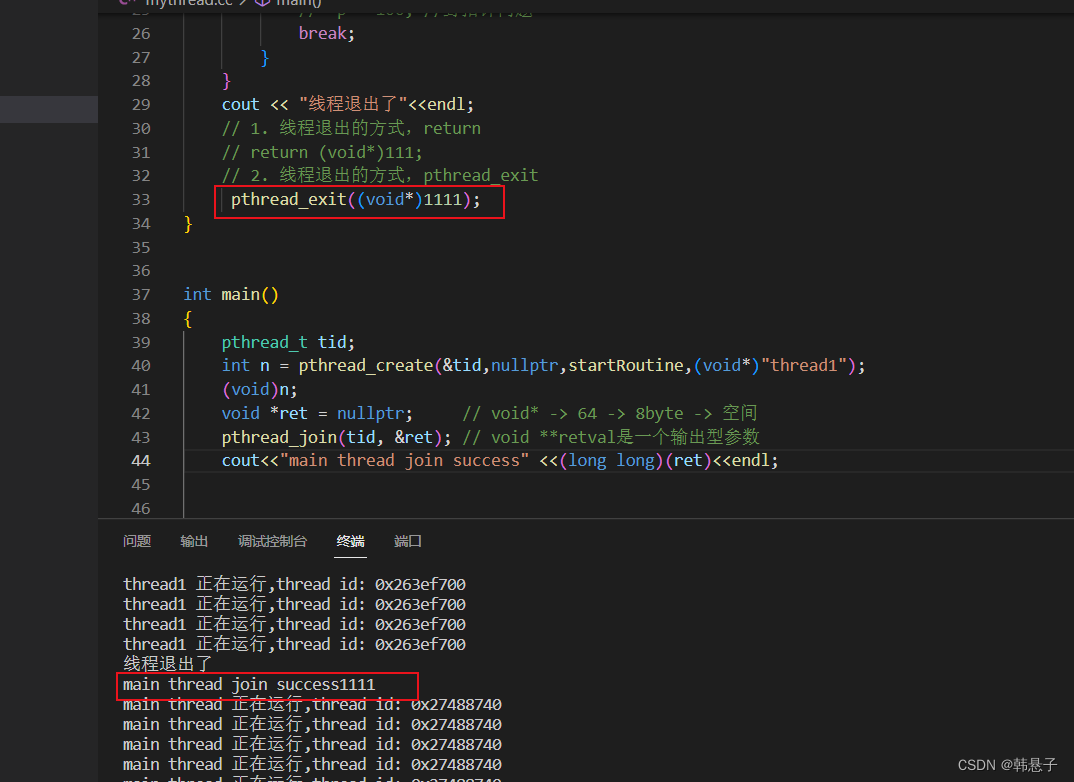
6.如果理解pthread_t
pthread_t是一个地址
1.线程是一个独立的执行流
2.线程一定会在自己的运行过程中,产生临时数据(调用函数,定义局部变量等)
3.线程一定需要有自己独立的栈结构
线程的全部实现,并没有全部体现在os内,而是os提供执行力,具体的线程结构由库管理,库可以创建多个线程,那么就要管理,先描述再组织
库是在共享区里的,下面的意思是,创建线程库里面不只是只有代码,还有数据
struct thread_info是线程的基本信息,pthread_t是我们对应的用户级线程的控制结构体起始的虚拟地址,用来找到控制结构体struct thread_info
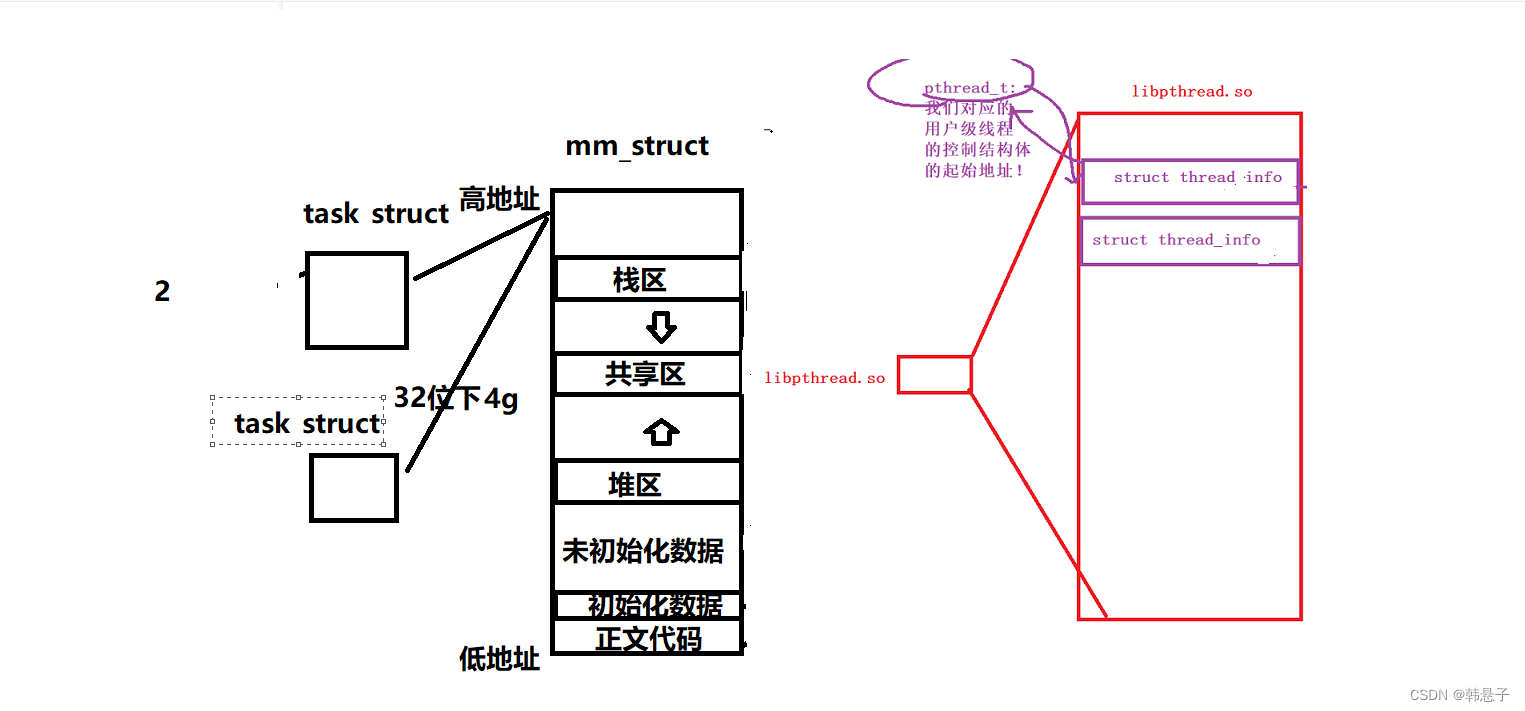
所以我们知道,主线程的独立栈结构,用的就是地址空间中的栈区
新线程用的栈结构,用的是库中提供的栈结构
7.三个概念
1.临界资源:多个执行流都能看到并能访问的资源,临界资源
2.临界区:多个执行流,代码中,有不同的代码,但访问临界资源的代码,我们称之为临界区
3.互斥:当我们访问某种资源的时候,任何时刻都只有一个执行流在进行访问,这个就叫做:互斥特性
下面的是买票的简略代码,用下面的代码来理解上面的三个概念并加深我们对线程的理解
#include <iostream>
#include <cstring>
#include <unistd.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/syscall.h>
using namespace std;
int tickets = 10000; // 临界资源,可能会因为共同访问,可能会造成数据不一致问题。
void *getTickets(void *args)
{
const char *name = static_cast<const char *>(args);
while (true)
{
if (tickets > 0)
{
usleep(1000);
cout << name << " 抢到了票, 票的编号: " << tickets << endl;
tickets--;
}
else
{
// 票抢到几张,就算没有了呢?0
cout << name << "已经放弃抢票了,因为没有了..." << endl;
break;
}
}
return nullptr;
}
int main()
{
pthread_t tid1;
pthread_t tid2;
pthread_t tid3;
pthread_t tid4;
pthread_create(&tid1, nullptr, getTickets, (void *)"thread 1");
pthread_create(&tid2, nullptr, getTickets, (void *)"thread 2");
pthread_create(&tid3, nullptr, getTickets, (void *)"thread 3");
pthread_create(&tid4, nullptr, getTickets, (void *)"thread 4");
int n = pthread_join(tid1, nullptr);
cout << n << ":" << strerror(n) << endl;
n = pthread_join(tid2, nullptr);
cout << n << ":" << strerror(n) << endl;
n = pthread_join(tid3, nullptr);
cout << n << ":" << strerror(n) << endl;
n = pthread_join(tid4, nullptr);
cout << n << ":" << strerror(n) << endl;
return 0;
}
里面的票数–也就是tickets–;是由一条语句完成的吗?
答案不是的
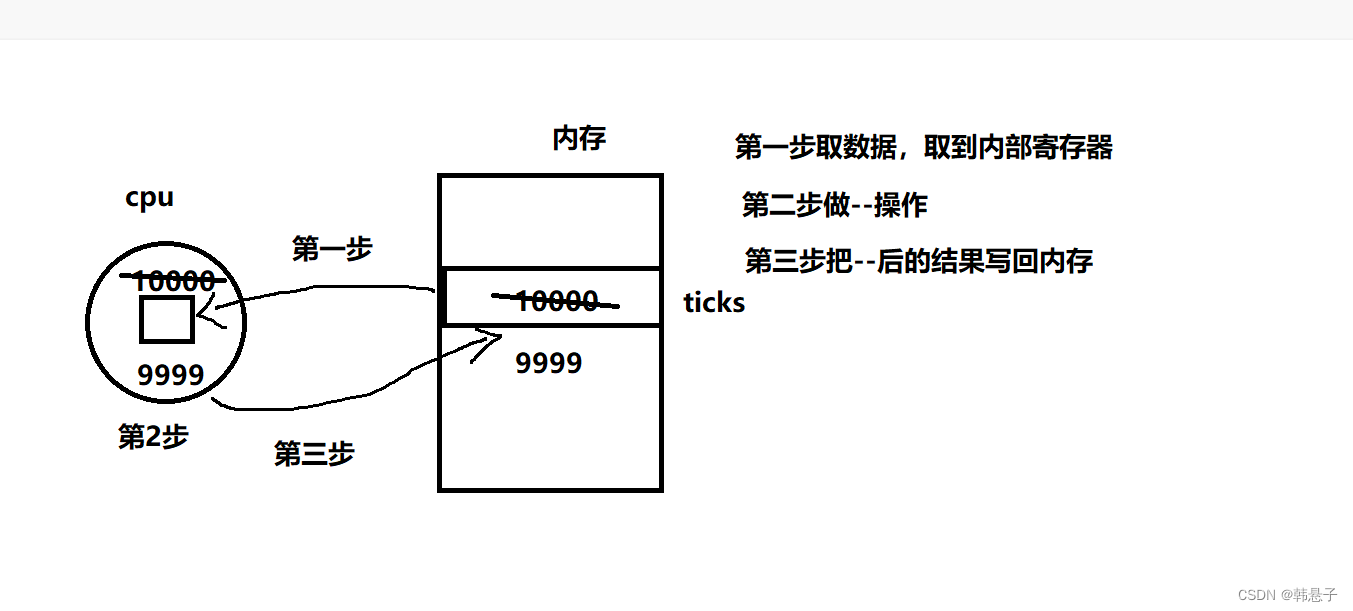
我们再来2点
1.在执行语句的任何地方,线程都有可能会被切换
2.cpu内的寄存器是被所有的执行流共享的,但是寄存器里面的数据是属于当前执行流的上下问数据
线程被切换的时候,需要保存上下文
线程被换回的时候,需要恢复上下文
现在还是买票,有个线程a买票买1张把从内存里面票的个数10000读在寄存器里面,减1张票,再把这个数据给放在线程A自己的上下文中,准备把这个数据9999写回内存,这个时候有个线程b也来买票它的优先级等等比较高,也没人来阻难它,他把票买剩下50张,他打算把数据写回内存的时它被切走了,他把自己的上下给保存下来,这个时候切回到了线程a,他把自己的上下文给写进寄存器,变成了9999,并把他写回了内存,这个时候票数就出问题了,多出了好多张票,而这种问题叫做数据不一致的问题
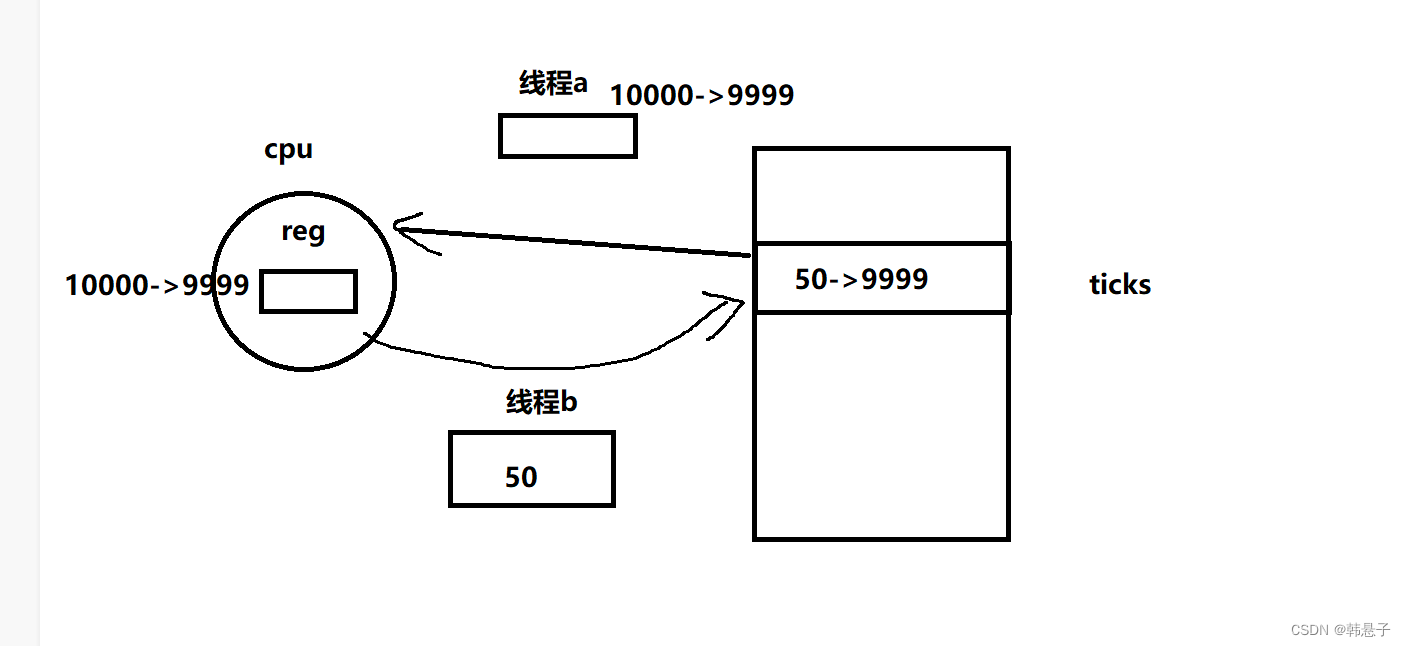
而上面这些问题,我们需要加锁,让他有原子性,一件事要么不做,要么就直接做完,所以也等于,当我们访问某种资源的时候,任何时刻都只有一个执行流在进行访问,这个就叫做:互斥特性
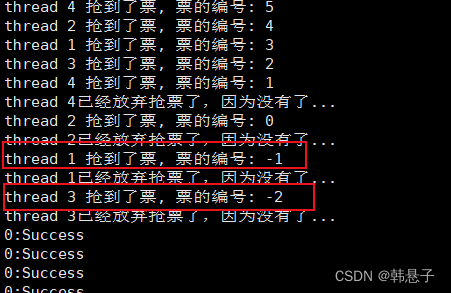
看到上面讲了那么多,我们来运行一下代码,可以看到确实出现了数据不一致的问题,当然这种是随机性,想增加概率,只能创造更多的让线程堵塞的场景,因为线程切换的创景是因为时间片到了
6.互斥锁
定义锁
pthread_mutex_t mutex;
给锁初始化
pthread_mutex_init(&mutex, nullptr);
释放锁
pthread_mutex_destroy(&mutex);
加锁
pthread_mutex_lock(&mutex);
解锁
pthread_mutex_ulock(&mutex);
mythrread.cc
#include <iostream>
#include <cstring>
#include <unistd.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/syscall.h>
using namespace std;
int tickets = 1000; // 临界资源,可能会因为共同访问,可能会造成数据不一致问题。
pthread_mutex_t mutex;
void *getTickets(void *args)
{
const char *name = static_cast<const char *>(args);
pthread_mutex_lock(&mutex);
while (true)
{
if (tickets > 0)
{
usleep(1000);
cout << name << " 抢到了票, 票的编号: " << tickets << endl;
tickets--;
}
else
{
// 票抢到几张,就算没有了呢?0
cout << name << "已经放弃抢票了,因为没有了..." << endl;
break;
}
pthread_mutex_unlock(&mutex);
}
return nullptr;
}
int main()
{
pthread_mutex_init(&mutex, nullptr);
pthread_t tid1;
pthread_t tid2;
pthread_t tid3;
pthread_t tid4;
pthread_create(&tid1, nullptr, getTickets, (void *)"thread 1");
pthread_create(&tid2, nullptr, getTickets, (void *)"thread 2");
pthread_create(&tid3, nullptr, getTickets, (void *)"thread 3");
pthread_create(&tid4, nullptr, getTickets, (void *)"thread 4");
int n = pthread_join(tid1, nullptr);
cout << n << ":" << strerror(n) << endl;
n = pthread_join(tid2, nullptr);
cout << n << ":" << strerror(n) << endl;
n = pthread_join(tid3, nullptr);
cout << n << ":" << strerror(n) << endl;
n = pthread_join(tid4, nullptr);
cout << n << ":" << strerror(n) << endl;
pthread_mutex_destroy(&mutex);
return 0;
}
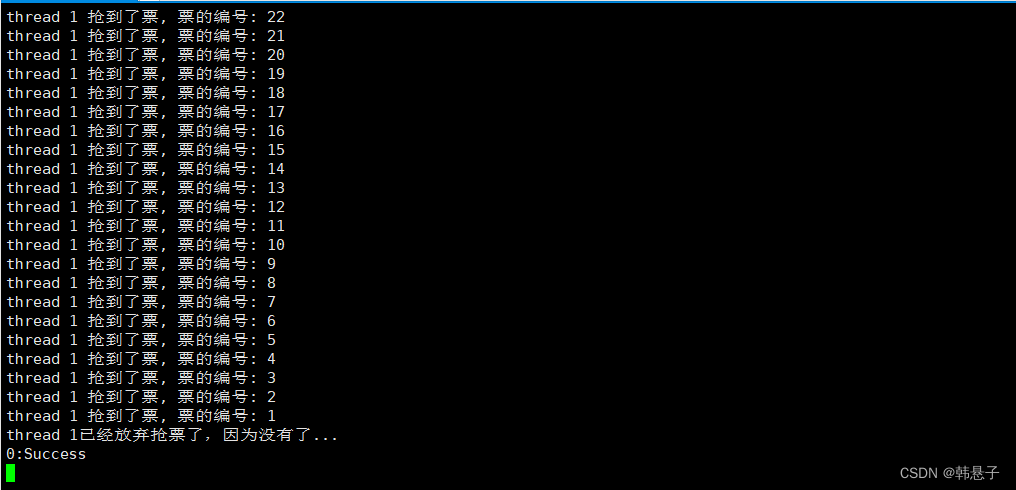
可以看到加了锁后没有发现数据不一致的问题,但是代码为什么一直死循环呢?
这是因为抢完票了break出去了没有执行解锁,所以给解锁就行了
1.关于临界区的一点问题
1.我们临界资源对应的临界区被锁了,可以被切换吗?
比如这块临界区
pthread_mutex_lock(&mutex);
if (tickets > 0)
{
usleep(1000);
cout << name << " 抢到了票, 票的编号: " << tickets << endl;
tickets--;
pthread_mutex_unlock(&mutex);
}
是可以切换的,因为线程执行的加锁解锁等对应的也是代码,线程在任意代码都可以被切换,又因为加锁是原子性的,要么拿到了锁,要么没拿到,所以加锁是安全的
2.加锁完后线程被切换会怎么样?
在我们加锁后没解锁的中间部分,是绝对不会有线程进入临界区,因为每个线程进入临界区都必须先申请锁,你要有了锁才能进临界区,比如之前被切走的线程是A,当前的锁,被A申请走了,即使当前的线程A没有被调度,但是因为它是被切走的,他没被释放,它是抱着锁走的,而切换成功的进程会进入堵塞状态,因为它没锁,所以一旦一个线程持有了锁,根本不担心任何的切换问题
而对于其他进程而言,线程A访问临界区也具有一定的原子性,只有没有进入和使用完毕二种状态,才对其他线程有意义
2.线程加锁和解锁具有原子性如何实现?
1.了解概念
根据我们前面知道i++不是原子性,因为他汇编不是一条语句完成的
所以实现互斥锁具有原子性也很简单,只有它汇编是一条语句完成的就行,像常用的x86和x64都会提供swap和xchgb,其作用都是内存和cpu的值做交换,也就是一条汇编
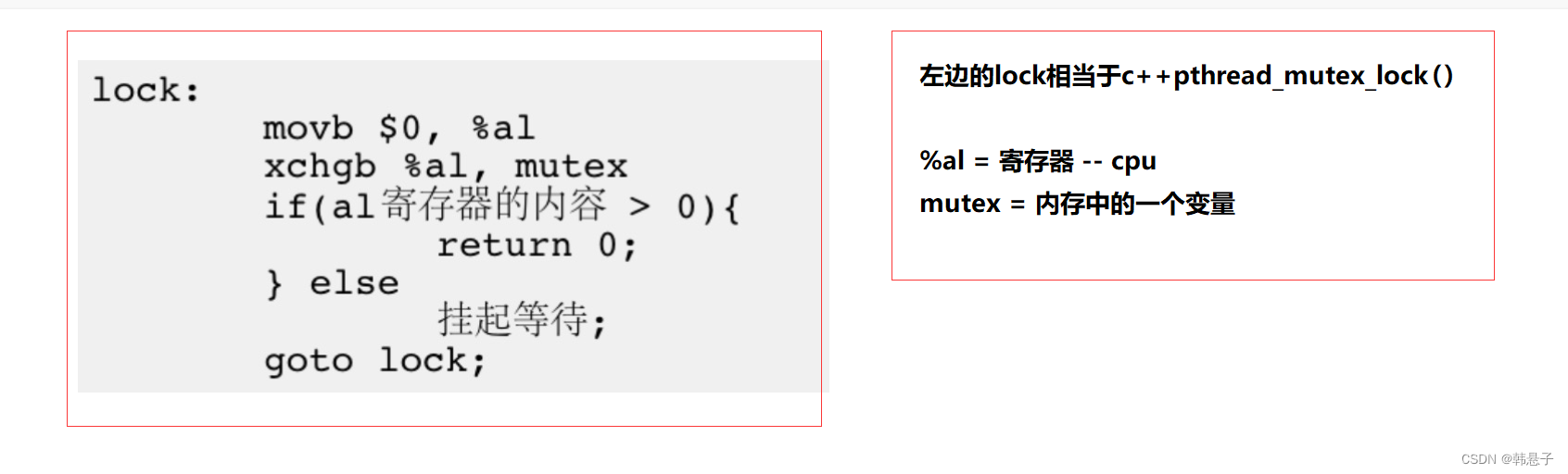
上面汇编代码是把0放进内存里面,也就是说执行完第二行代码,内存里面的值是1,那么进行判断,大于0就退出,其他挂起,
2.第一种情况
现在有二个线程,一个线程A,一个线程B,线程A要把0放进内存里面,内存里面是1也就是说执行完第二行代码,把0写进了cpu,并和内存1进行交换
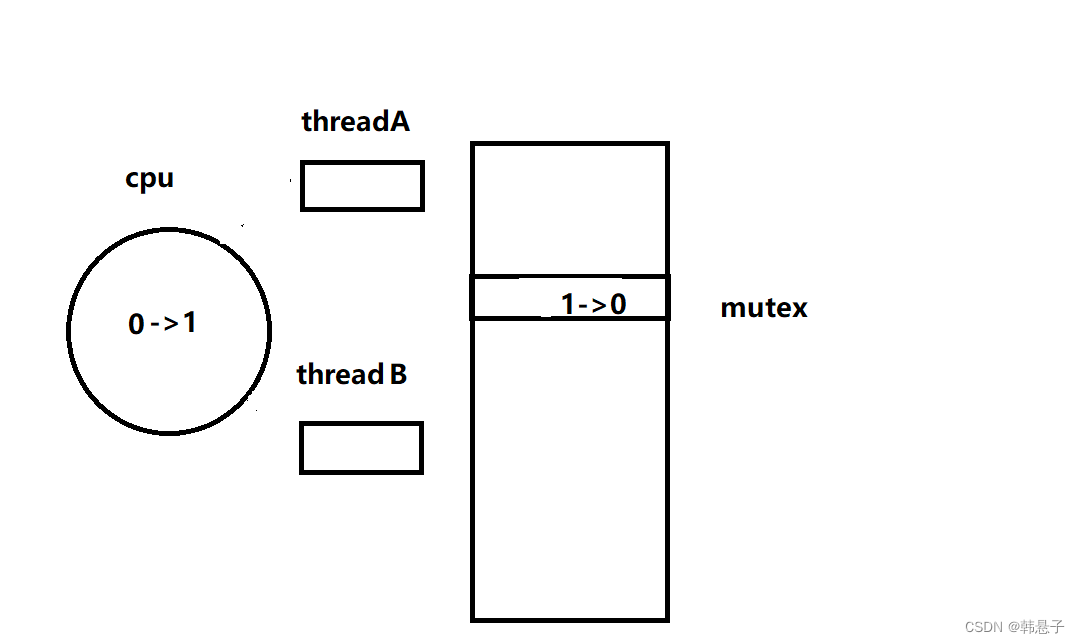
这个时候切换成线程B,那么这个时候线程A是要被剥离下来的,保存他自己的上下文1,这个时候线程B也是要执行加锁,把0放进cpu里面,并写入进内存,而这个时候1已经被线程A拿走了,等于拿0换0,然后执行下面的判断,因为你的值没有大于0,所以挂起等待了
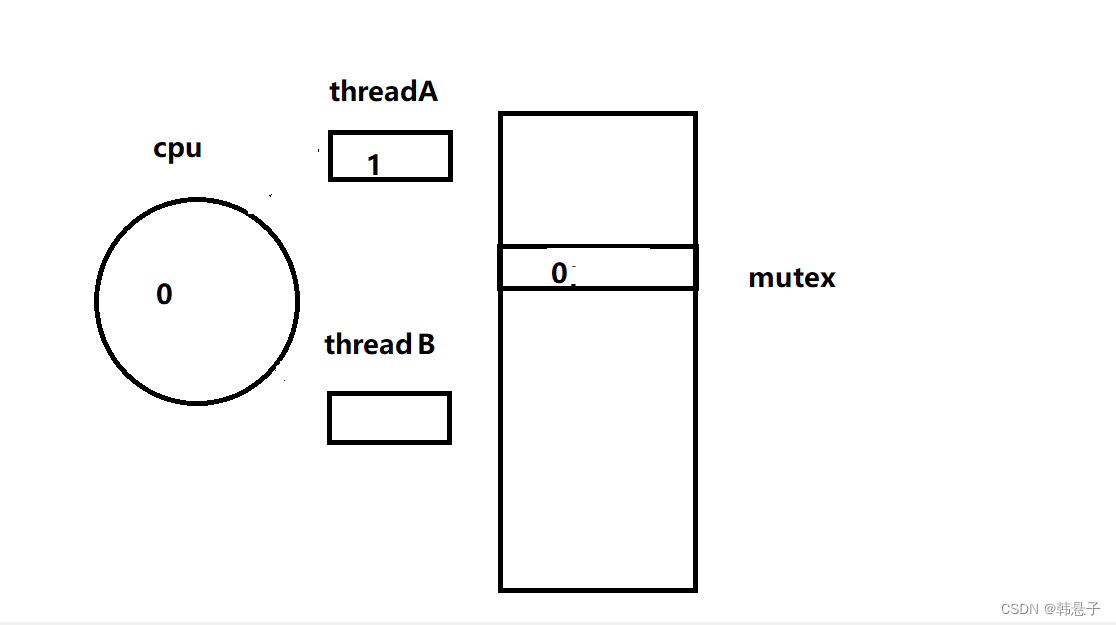
而上面这种情况就是线程A把锁拿走了,所以线程B,访问不了这个临界区,当进程A回来了,恢复了自己的锁,也就是把自己的上下文1放进cpu里面,而这个时候判断就大于0了
3.第二种情况
那么前面说过只要是代码都可以进行切换,那么这次我们不从第2条语句开始切换,从1条语句把0写进cpu的时候后,切换线程
那么线程A刚把0写进了cpu后,就切换成线程B,线程A就保存自己的上下文0
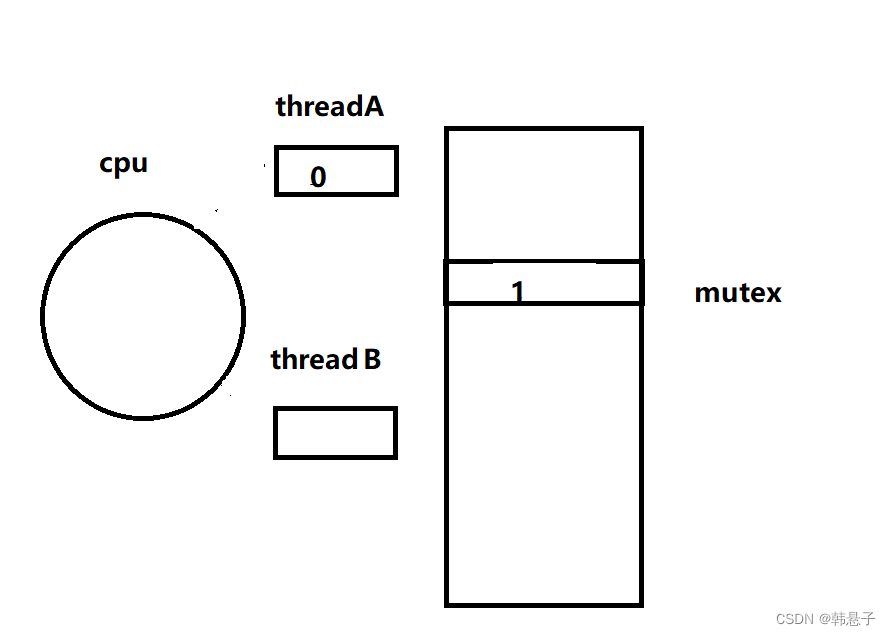
线程B也要加锁,把0写进了cpu,并执行了第二句代码,把cpu的值和内存的值交换,而这个时候准备进行判断的时候,又切换回线程A,那么线程B保存好自己的上下文
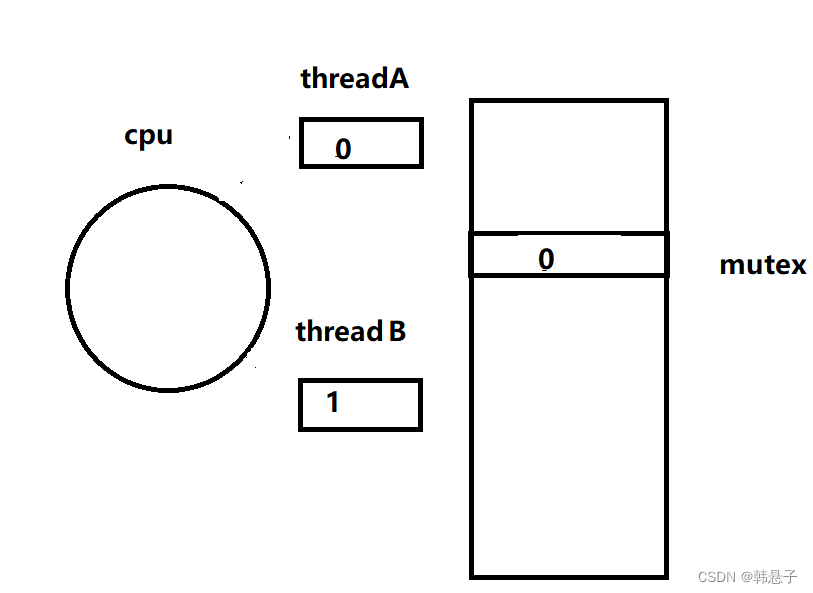
线程A又要开始把0写入进cpu,并交换那么就和第一种情况一样了,因为1被线程B拿走了,所以0换0,到判断语句的时候,要挂起等待,当线程B切回来,恢复自己的锁,把cpu的值变回1,这个时候判断语句就大于0了
所以不管什么情况,互斥锁都能保证互斥特性
加锁其实就是将数据交互到寄存器内部
本质:将数据从内存读入寄存器,本质就是将数据从共享变成了线程私有
3.解锁
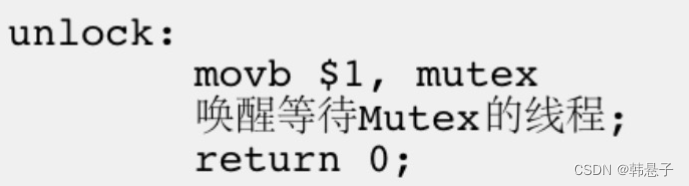
解锁就很简单了,就是把1写进cpu里面
7.简单实现锁
下面的代码其实就是RALL思想了,把他构造成一个类,自动创造自动析构
Lock.hpp
#pragma once
#include <iostream>
#include <pthread.h>
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&lock_, nullptr);
}
void lock()
{
pthread_mutex_lock(&lock_);
}
void unlock()
{
pthread_mutex_unlock(&lock_);
}
~Mutex()
{
pthread_mutex_destroy(&lock_);
}
private:
pthread_mutex_t lock_;
};
class LockGuard
{
public:
LockGuard(Mutex *mutex) : mutex_(mutex)
{
mutex_->lock();
std::cout << "加锁成功..." << std::endl;
}
~LockGuard()
{
mutex_->unlock();
std::cout << "解锁成功...." << std::endl;
}
private:
Mutex *mutex_;
};
mythread.cc
#include <iostream>
#include <cstdio>
#include <cstring>
#include <unistd.h>
#include <pthread.h>
#include "Lock.hpp"
#include <mutex>
using namespace std;
int tickets = 1000;
Mutex mymutex;
// 函数本质是一个代码块, 会被多个线程同时调用执行,该函数被重复进入 - 被重入了
bool getTickets()
{
bool ret = false; // 函数的局部变量,在栈上保存,线程具有独立的栈结构,每个线程各自一份
LockGuard lockGuard(&mymutex); //局部对象的声明周期是随代码块的!
if (tickets > 0)
{
usleep(1001); //线程切换了
cout << "thread: " << pthread_self() << " get a ticket: " << tickets << endl;
tickets--;
ret = true;
}
return ret;
}
void *startRoutine(void *args)
{
const char *name = static_cast<const char *>(args);
while(true)
{
if(!getTickets())
{
break;
}
cout << name << " get tickets success" << endl;
}
}
int main()
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, nullptr, startRoutine, (void *)"thread 1");
pthread_create(&t2, nullptr, startRoutine, (void *)"thread 2");
pthread_create(&t3, nullptr, startRoutine, (void *)"thread 3");
pthread_create(&t4, nullptr, startRoutine, (void *)"thread 4");
pthread_join(t1, nullptr);
pthread_join(t2, nullptr);
pthread_join(t3, nullptr);
pthread_join(t4, nullptr);
}

![[附源码]java毕业设计校园求职与招聘系统](https://img-blog.csdnimg.cn/1e80e1237d2743ca942e6b73f82a5150.png)



![[附源码]java毕业设计心理问题咨询预约系统](https://img-blog.csdnimg.cn/66c932e936db43f2a063cd34d07c9431.png)