neozng1@hnu.edu.cn
TODO:
1. 添加一键编译+启用ozone调试/一键编译+下载的脚本,使得整个进一步流程自动化
2. 增加更多的背景知识介绍
3. 增加VSCode下RTT viewer的支持和一键下载(不进入调试)的支持
前言
了解过嵌入式开发的你一定接触过Keil,这款20世纪风格UI的IDE伴随很多人度过了学习单片机的岁月。然而由于其缺少代码补全、高亮和静态检查的支持,以及为人诟病的一系列逆天的设置、极慢的编译速度(特别是在开发HAL库时),很多开发者开始转向其他IDE。
IAR、CubeIDE等都是广为使用的“其他”IDE,但是他们也有各自的缺点,不能让笔者满意。作为IDE界的艺术家,JetBrains推出的Clion也在相当程度上完善了对嵌入式开发的支持。不过,在体验过多款IDE后,还是VSCode这款高度定制化的编辑器最让人满意。强大的补全和snippet以及代码高亮、定义跳转甩KEIL十条街。
而Ozone则是SEGGER(做jilnk的)推出的调试应用,支持变量实时更新,变量曲线可视化,SEGGER RTT日志,DBG虚拟串口等功能,大大扩展了调试的功能。很多人习惯使用串口进行可视化调试,如vofa,串口调试助手等。然而通过这些方式进行调试,都是对内核有侵入性的,会占有内核资源并且导致定时器的时间错乱。由于DBG有单独连接到FLASH和CPU寄存器的高速总线(类似于DMA),可以在不影响程序正常运行的情况下以极高的频率直接获取变量值。
下面,将从工具链介绍、环境配置以及调试工作流三个方面介绍以VSCode为编辑器,Ozone为调试接口的开发环境。
开发的大致流程为:

本教程不仅希望教会你如何配置环境,同样会告诉你每一步究竟是在做什么,而不是简单的复制黏贴邯郸学步。
前置知识
- 计算机速成课:Crash Course Computer Science
- 从零到一打造一台计算机:
编程前你最好了解的基本硬件和计算机基础知识(模拟电路)
编程前你最好了解的基本硬件和计算机基础知识(数字电路)
从0到1设计一台计算机 - C语言基础:程序设计入门——C语言
务必学完以上课程再开始本教程的学习。
如果有可能,还应该学习: 哈佛大学公开课:计算机科学cs50。你将会对单片机和计算机有不同的理解。
预备知识
- 软件安装
- C语言从源代码到.bin和.hex等机器代码的编译和链接过程
- C语言的内存模型
- C语言标准,动态链接库和静态编译的区别,一些编译器的常用选项
- STM32F4系列的DBG外设工作原理
- GDB调试器、硬件调试器和DBG的关系
编译全过程
C语言代码由固定的词汇(关键字)按照固定的格式(语法)组织起来,简单直观,程序员容易识别和理解,但是CPU只能识别二进制形式的指令,并且这些指令是和硬件相关的(感兴趣的同学可以搜索指令集相关内容)。这就需要一个工具,将C语言代码转换成CPU能够识别的二进制指令,对于我们的x86平台windows下的程序就是.exe后缀的文件;对于单片机,一般来说是.bin或.hex等格式的文件(调试文件包括axf和elf)。
能够完成这个转化过程的工具是一个特殊的软件,叫做编译器(Compiler)。常见的编译器包括开源的GNU GCC,windows下微软开发的visual C++,以及apple主导的llvm/clang。编译器能够识别代码中的关键字、表达式以及各种特定的格式,并将他们转换成特定的符号,也就是汇编语言(再次注意汇编语言是平台特定的),这个过程称为编译(Compile)。
对于单个.c文件,从C语言开始到单片机可识别的.bin文件,一般要经历以下几步:

不知道图源哪里,侵删
首先是编译预处理Preprocessing,这一步会展开宏并删除注释,将多余的空格去除。预处理之后会生成.i文件。
然后,开始编译Compilation的工作。编译器会将源代码进行语法分析、词法分析、语义分析等,根据编译设置进行性能优化,然后生成汇编代码.s文件。汇编代码仍然是以助记符的形式记录的文本,比如将某个地址的数据加载到CPU寄存器等,还需要进一步翻译成二进制代码。
下一步就是进行汇编Assemble,编译器会根据汇编助记符和机器代码的查找表将所有符号进行替换,生成.o .obj等文件。但请注意,这些文件并不能直接使用(烧录),我们在编写代码的时候,都会包含一些库,因此编译结果应当有多个.o文件。我们还需要一种方法将这些目标文件缝合在一起,使得在遇到函数调用的时候,程序可以正确地跳转到对应的地方执行。
最后一步就由链接器Linker(也称LD)完成,称为链接Linking。比如你编写了一个motor.c文件和.h文件,并在main.c中包含了motor.h,使用了后者提供的MotorControl()函数。那么,链接器会根据编译器生成.obj文件时留下的函数入口地址,将main.o里的调用映射到生成的motor.o中。链接完成后,就生成了单片机可以识别的可执行文件,通过支持的串口或下载器烧录,便可以运行。
另外,上图可以看到左侧的
静态库,包括
.lib .a,比如我们在STM32中使用的DSP运算库就是这种文件。他在本质上和.o文件相同,只要你在你编写的源文件中包含了这些库的头文件,链接器就可以根据映射关系找到头文件中声明的函数在库文件的地址。(直接提供库而不是.c文件,就可以防止源代码泄露,因此一些不开源的程序会提供函数调用的头文件和接口具体实现的库;你也可以编写自己的库,感兴趣自行搜索)
链接之后,实际上还要进行不同代码片段的重组、地址重映射,详细的内容请参看:C/C++语言编译链接过程,这篇教程还提供了以GCC为例的代码编译示例。
C语言内存模型

好像图源CSDN,侵删
以上是C语言常见的内存模型,即C语言的代码块以及运行时使用的内存(包括函数、变量等)的组织方式。
有些平台的图与此相反,栈在最下面(内存低地址),其他区域都倒置,不影响我们理解
代码段即我们编写的代码,也就是前面说的编译和链接之后最终生成的可执行文件占据的空间。一些常量,包括字符串和使用const关键字修饰的变量被放在常量存储区。static修饰的静态变量(包括函数静态变量和文件静态变量)以及全局变量放在常量区上面一点的全局区(也称静态区)。
然后就是最重要的堆和栈。在一个代码块内定义的变量会被放在栈区,一旦离开作用域(出了它被定义的{}的区域),就会立刻被销毁。在调用函数或进入一个用户自定义的{}块,都会在栈上开辟一块新的空间,空间的大小和内存分配由操作系统或C库自动管理。一般来说,直接通过变量访问栈内存,速度最快(对于单片机)。而堆则是存储程序员自行分配的变量的地方,即使用malloc(),realloc() ,new等方法获取的空间,都被分配在这里。
在CubeMX初始化的时候,Project mananger标签页下有一个Linker Setting的选项,这里是设置最小堆内存和栈内存的地方。如果你的程序里写了大规模的数组,或使用
malloc()等分配了大量的空间,可能出现栈溢出或堆挤占栈空间的情况。需要根据MCU的资源大小,设置合适的stack size和heap size。
RTOS创建任务的时候也会为每个任务分配一定的栈空间,它会替代MCU的硬件裸机进行内存的分配。可以在CubeMX中设置。如果一个任务里定义了大量的变量,可能导致实时系统运行异常,请增大栈空间。
开发板C型使用F407IG芯片,片上RAM的大小为1MB。
C language标准和编译器
不同的C语言标准(一般以年份作代号)支持的语法特性和关键字不同,拥有的功能也不同。一般来说语言标准都是向前兼容的,在更新之后仍然会保存前代的基本功能支持(legacy support)。不过,为了程序能够正常运行,我们还需要一些硬件或平台支持的组件。比如malloc()这个函数,在linux平台和windows平台上的具体实现就相去甚远,跟单片机更是差了不止一点。前两者一般和对应的操作系统有关,后者在裸机上则是直接通过硬件或ST公司提供的硬件抽象层代码实现。
然而,不同编译器提供的代码实现也不尽相同,比如使用clang和gcc这两种c语言编译器,他们对于一些标准库(也称C库,包括stdio,stdlib,string等在内的实现)的函数的实现就不太一样。再如__packed是arm-cc提供的一个字节不对齐关键字,在一些其他编译器中就不支持这种实现。
以前大家常用的KEIL使用的是ARM提供的arm-cc工具链(非常蛋疼,甚至不支持uint8_t=0b00001111这种二进制定义法),而该教程选用的是开源的Arm GNU Toolchain。在非目标机且和目标机平台不同的平台上进行开发被成为跨平台开发,进行的编译也被成为交叉编译(在一个平台上生成另一个平台上的 可执行代码)。
工具链包含了编译器,链接器以及调试器等开发常用组件。我们使用的Arm GNU toolchain中,编译器是arm-none-eabi-gcc.exe,链接器是arm-none-eabi-ld.exe,调试器则是arm-none-eabi-gdb.exe。通过跨平台调试器和j-link/st-link/dap-link,我们就可以在自己的电脑上对异构平台(即单片机)的运行进行调试了。
Debug外设工作原理

来自STM32F407IG的datasheet
DBG支持模块(红框标注部分,也可以看作一个外设)通过一条专用的AHB-AP总线和调试接口相连(Jtag或swd),并且有与数据和外设总线直接相连的桥接器。它还同时连接了中断嵌套管理器(因此同样可以捕获中断并进行debug)和ITM、DWT、FPB这些调试支持模块。因此DBG可以直接获取内存或片上外设内的数据而不需要占用CPU的资源,并将这些数据通过专用外设总线发送给调试器,进而在上位机中读取。
FPB是flash patch breakpoint闪存指令断点的缩写,用于提供代码断点插入的支持,当CPU的指令寄存器读取到某一条指令时,FPB会监测到它的动作,并通知TPIU暂停CPU进行现场保护。
DWT是data watch trace数据观察与追踪单元的缩写,用于比较debug变量的大小,并追踪变量值的变化。当你设定了比较断点规则(当某个数据大于/小于某个值时暂停程序)或将变量加入watch进行查看,DWT就会开始工作。DWT还提供了一个额外的计时器,即所有可见的TIM资源之外的另一个硬件计时器(因为调试其他硬件定时器的计时由于时钟变化可能定时不准,而DWT定时器是始终正常运行的)。它用于给自身和其他调试器模块产生的信息打上时间戳。我们的bsp中也封装了dwt计时器,你可以使用它来计时。
ITM是instrument trace macrocell指令追踪宏单元的缩写,它用于提供非阻塞式的日志发送支持(相当于大家常用的串口调试),SEGGER RTT就可以利用这个模块,向上位机发送日志和信息。这个硬件还可以追踪CPU执行的所有指令,这也被称作trace(跟踪),并将执行过的指令全部通过调试器发送给上位机。当debug无法定位bug所在的时候,逐条查看cpu执行的指令是一个绝佳的办法,特别是你有大量的中断或开启了实时系统时。
以上三个模块都需要通过TPIU(trace port interface unit)和外部调试器(j-link等)进行连接,TPIU会将三个模块发来的数据进行封装并通过DWT记录时间,发送给上位机。
GDB调试MCU原理
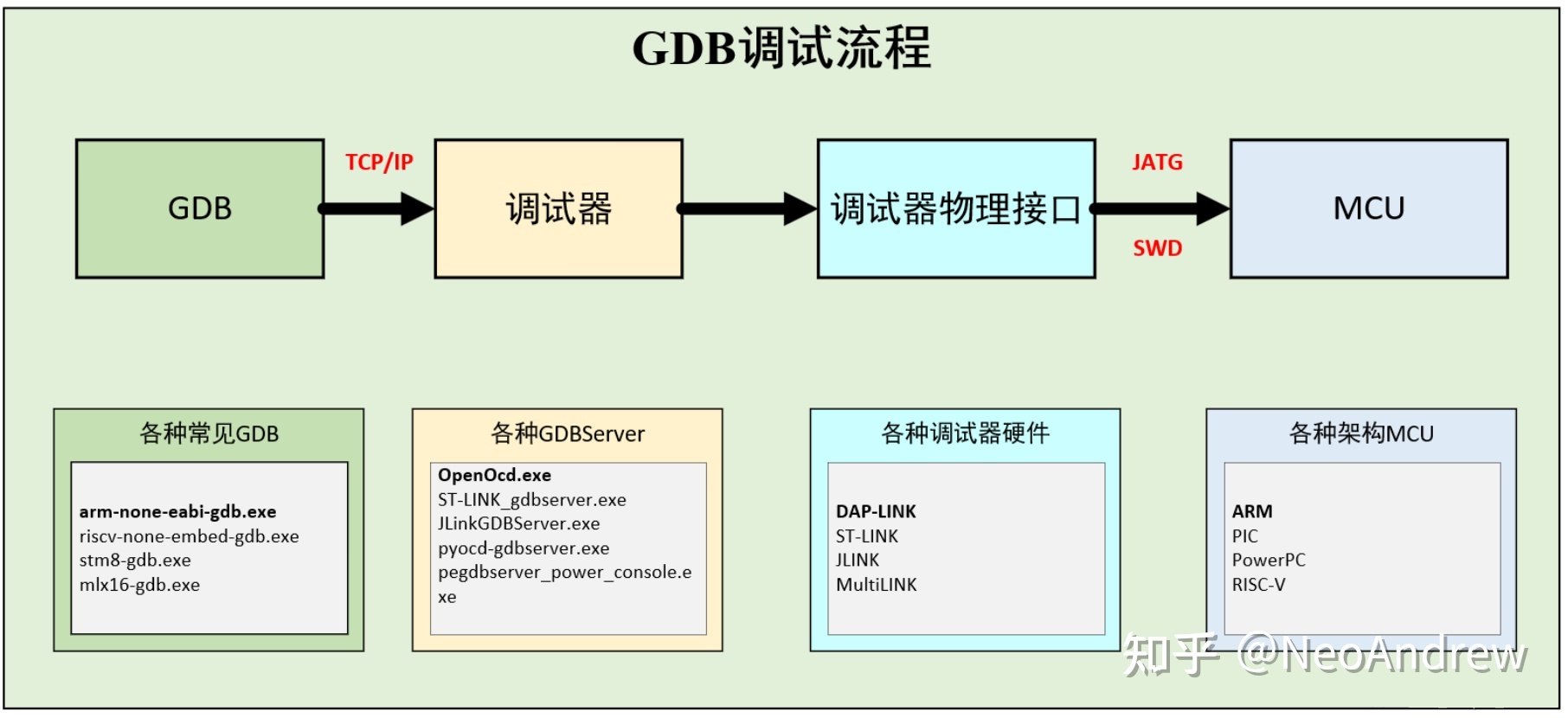
图源博客园某博客,找不到具体出处了,侵删
不论使用MDK(KEIL)还是VSCode还是Ozone,实际上背后的流程相同。首先GDB会建立TCP/IP端口并提供接口,调试服务器(Server)作为硬件调试器和GDB软件的桥梁,将硬件调试器的相关功能(也就是DBG外设支持的那些功能)映射到GDB的接口上(通过连接到GDB建立的端口)。之后启动调试,将可执行文件下载到目标MCU上,然后从main开始执行
当然你也可以选择从其他启动点开始执行,调试器开始执行的位置叫做 entry point。同样,在MCU已经正在运行程序的时候,可以 attach到程序上开始监控(attach=附加,贴上;很形象了)。
而对于直接运行在电脑上的程序(.exe),就不需要GDBserver和物理调试器,GDB程序可以直接访问电脑上运行的程序和CPU的寄存器等。
![[附源码]java毕业设计校园求职与招聘系统](https://img-blog.csdnimg.cn/1e80e1237d2743ca942e6b73f82a5150.png)



![[附源码]java毕业设计心理问题咨询预约系统](https://img-blog.csdnimg.cn/66c932e936db43f2a063cd34d07c9431.png)