139.1 Spark MLllib
- MLlib(Machine Learnig lib) 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。
- MLlib是MLBase一部分,其中MLBase分为四部分:MLlib、MLI、ML Optimizer和MLRuntime。
- ML Optimizer会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数,来处理用户输入的数据,并返回模型或别的帮助分析的结果;
- MLI 是一个进行特征抽取和高级ML编程抽象的算法实现的API或平台;
- MLlib是Spark实现一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化,该算法可以进行可扩充; MLRuntime 基于Spark计算框架,将Spark的分布式计算应用到机器学习领域。
- MLlib主要包含三个部分:
- 底层基础:包括Spark的运行库、矩阵库和向量库
- 算法库:包含广义线性模型、推荐系统、聚类、决策树和评估的算法
- 实用程序:包括测试数据的生成、外部数据的读入等功能
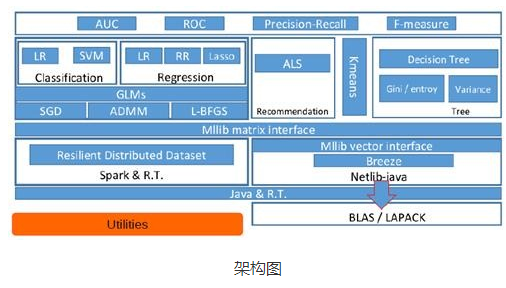
- MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤,MLlib在Spark整个生态系统中的位置如图下图所示。
139.2 Ray
- Ray是加州大学伯克利分校实时智能安全执行实验室(RISELab)的研究人员针对机器学习领域开发的一种新的分布式计算框架,该框架旨在让基于Python的机器学习和深度学习工作负载能够实时执行,并具有类似消息传递接口(MPI)的性能和细粒度。
- 增强学习的场景,按照原理定义,因为没有预先可用的静态标签信息,所以通常需要引入实际的目标系统(为了加快训练,往往是目标系统的模拟环境)来获取反馈信息,用做损失/收益判断,进而完成整个训练过程的闭环反馈。典型的步骤是通过观察特定目标系统的状态,收集反馈信息,判断收益,用这些信息来调整参数,训练模型,并根据新的训练结果产出可用于调整目标系统的行为Action,输出到目标系统,进而影响目标系统状态变化,完成闭环,如此反复迭代,最终目标是追求某种收益的最大化(比如对AlphoGo来说,收益是赢得一盘围棋的比赛)。
- 在这个过程中,一方面,模拟目标系统,收集状态和反馈信息,判断收益,训练参数,生成Action等等行为可能涉及大量的任务和计算(为了选择最佳Action,可能要并发模拟众多可能的行为)。而这些行为本身可能也是千差万别的异构的任务,任务执行的时间也可能长短不一,执行过程有些可能要求同步,也有些可能更适合异步。
- 另一方面,整个任务流程的DAG图也可能是动态变化的,系统往往可能需要根据前一个环节的结果,调整下一个环节的行为参数或者流程。这种调整,可能是目标系统的需要(比如在自动驾驶过程中遇到行人了,那么我们可能需要模拟计算刹车的距离来判断该采取的行动是刹车还是拐弯,而平时可能不需要这个环节),也可能是增强学习特定训练算法的需要(比如根据多个并行训练的模型的当前收益,调整模型超参数,替换模型等等)。
- 此外,由于所涉及到的目标系统可能是具体的,现实物理世界中的系统,所以对时效性也可能是有强要求的。举个例子,比如你想要实现的系统是用来控制机器人行走,或者是用来打视频游戏的。那么整个闭环反馈流程就需要在特定的时间限制内完成(比如毫秒级别)。
- 总结来说,就是增强学习的场景,对分布式计算框架的任务调度延迟,吞吐量和动态修改DAG图的能力都可能有很高的要求。按照官方的设计目标,Ray需要支持异构计算任务,动态计算链路,毫秒级别延迟和每秒调度百万级别任务的能力。
- Ray的目标问题,主要是在类似增强学习这样的场景中所遇到的工程问题。那么增强学习的场景和普通的机器学习,深度学习的场景又有什么不同呢?简单来说,就是对整个处理链路流程的时效性和灵活性有更高的要求。
- Ray框架优点
- 海量任务调度能力
- 毫秒级别的延迟
- 异构任务的支持
- 任务拓扑图动态修改的能力
- Ray没有采用中心任务调度的方案,而是采用了类似层级(hierarchy)调度的方案,除了一个全局的中心调度服务节点(实际上这个中心调度节点也是可以水平拓展的),任务的调度也可以在具体的执行任务的工作节点上,由本地调度服务来管理和执行。
- 与传统的层级调度方案,至上而下分配调度任务的方式不同的是,Ray采用了至下而上的调度策略。也就是说,任务调度的发起,并不是先提交给全局的中心调度器统筹规划以后再分发给次级调度器的。而是由任务执行节点直接提交给本地的调度器,本地的调度器如果能满足该任务的调度需求就直接完成调度请求,在无法满足的情况下,才会提交给全局调度器,由全局调度器协调转发给有能力满足需求的另外一个节点上的本地调度器去调度执行。
- 架构设计一方面减少了跨节点的RPC开销,另一方面也能规避中心节点的瓶颈问题。当然缺点也不是没有,由于缺乏全局的任务视图,无法进行全局规划,因此任务的拓扑逻辑结构也就未必是最优的了。
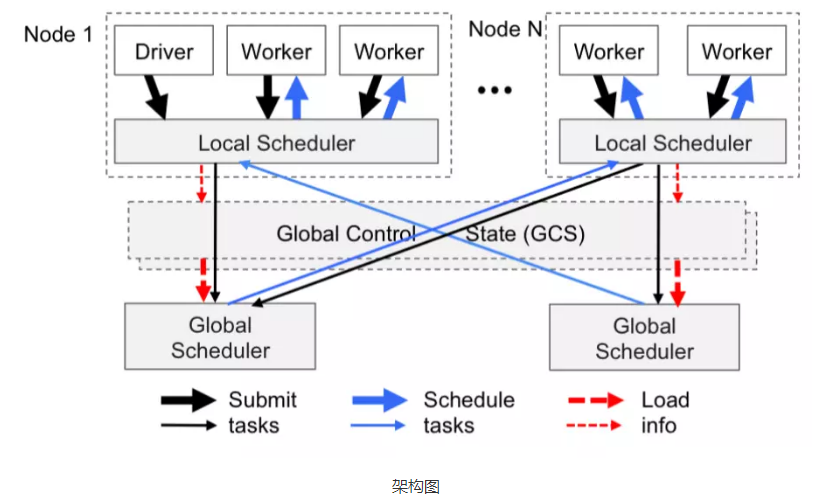
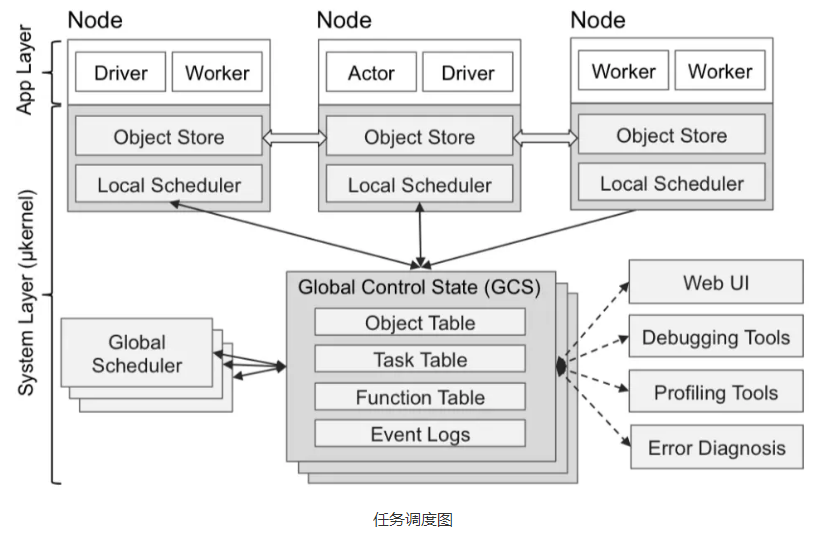
- Ray架构现状:
- API层以上 的部分还比较薄弱,Core模块核心逻辑估需要时间打磨。
- 国内目前除了蚂蚁金服和RISELab有针对性的合作以外,关注程度还很低,没有实际的应用实例看到,整体来说还处于比较早期的框架构建阶段。
139.3 Spark stream
- 随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐、用户行为分析等。 Spark Streaming是建立在Spark上的实时计算框架,通过它提供的丰富的API、基于内存的高速执行引擎,用户可以结合流式、批处理和交互试查询应用。
- Spark是一个类似于MapReduce的分布式计算框架,其核心是弹性分布式数据集,提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
- emsp; Spark Streaming的优势在于:
- 能运行在100+的结点上,并达到秒级延迟。
- 使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
- 能集成Spark的批处理和交互查询。
- 为实现复杂的算法提供和批处理类似的简单接口。
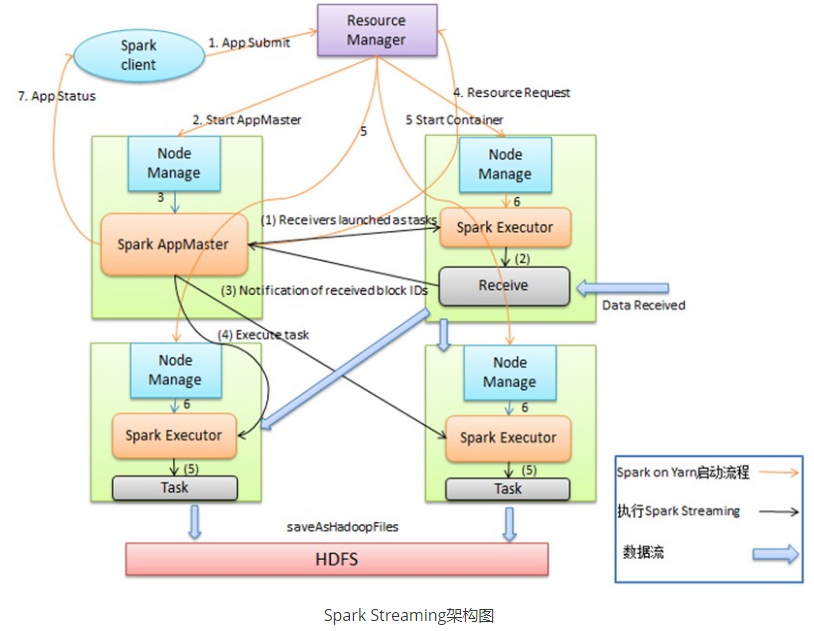
- Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。每个块都会生成一个Spark Job处理,最终结果也返回多块。
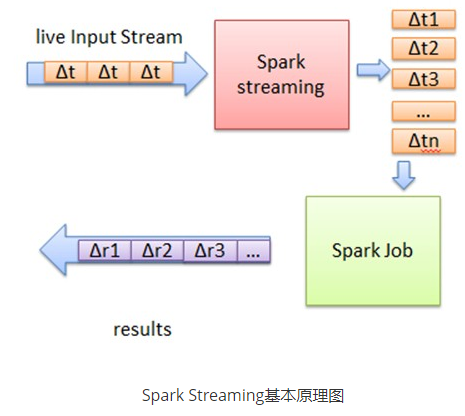
- 正如Spark Streaming最初的目标一样,它通过丰富的API和基于内存的高速计算引擎让用户可以结合流式处理,批处理和交互查询等应用。因此Spark Streaming适合一些需要历史数据和实时数据结合分析的应用场合。当然,对于实时性要求不是特别高的应用也能完全胜任。另外通过RDD的数据重用机制可以得到更高效的容错处理。
大数据视频推荐:
网易云课堂
CSDN
人工智能算法竞赛实战
AIops智能运维机器学习算法实战
ELK7 stack开发运维实战
PySpark机器学习从入门到精通
AIOps智能运维实战
腾讯课堂
大数据语音推荐:
ELK7 stack开发运维
企业级大数据技术应用
大数据机器学习案例之推荐系统
自然语言处理
大数据基础
人工智能:深度学习入门到精通